Инструмент открытой мощности/анализа производительности (OPPAT)
Оглавление
- Введение
- Типы поддерживаемых данных
- Оппотса визуализация
- График функции
- Типы диаграмм
- Сбор данных для OPPAT
- Поддержка данных PCM
- Строительство Oppat
- Бег Oppat
- Полученные события
- Использование графического интерфейса Browswer
- Ограничения
Введение
Инструмент открытого анализа мощности/производительности (OPPAT)-это кросс-OS, кросс-архитектура мощность и инструмент анализа производительности.
- Cross-OS: поддерживает файлы трассировки Windows ETW и Files Linux/Android perf/trace-cmd
- Крестная архитектура: поддерживает аппаратные события Intel и Arm Cips (используя Perf и/или PCM)
Веб -страница проекта - https://patinnc.github.io
Репошерб -исходный код - https://github.com/patinnc/oppat
Я добавил операционную систему (OS_VIEW) в функцию блочной диаграммы ЦП. Это основано на страницах Брендана Грегга, таких как http://www.brendangregg.com/linuxperf.html. Вот несколько примеров данных для запуска старой версии Geekbench v2.4.2 (32 -битный код) на ARM 64Bit Ubuntu Mate v18.04.2 Raspberry Pi 3 B+, 4 ЦПР ARM A53:
- Видео об изменениях в диаграмме процессоров OS_VIEW и ARM A53 под управлением GeekBench:
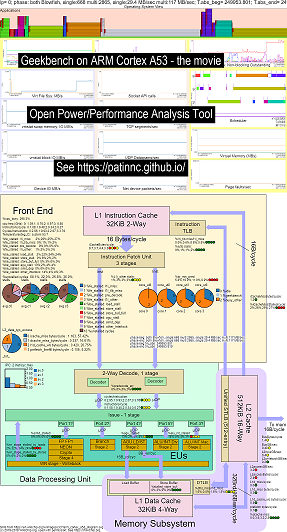
- Есть некоторые вводные слайды, чтобы попытаться объяснить макет OS_VIEW и CPU_DIAGRAM, а затем 1 слайд, показывающий результаты на каждый из 30 подтестов
- Файл Excel данных в фильме: File Excel от Geekbench The Movie
- HTML данных в фильме ... см. Geekbench v2.4.2 на 4 Core Arm Cortext A53 с OS_VIEW, диаграмма ЦП.
- Dashboard PNG для всех 30 фаз, отсортированных по увеличению инструкций/с ... см. Arm Cortex A53 Raspberry Pi 3 с диаграммой процессора с 4-ядерной приборной панелью с помощью Geekbench.
Вот несколько примеров данных для запуска моего контрольного эталона (тесты полосы пропускания памяти/кэша, тест «Spin» Keep-CPU-Busy) на CPU Raspberry Pi 3 B+ (Cortex A53):
- Видео об изменениях в схеме за блокировки CPU OS_VIEW и ARM A53.
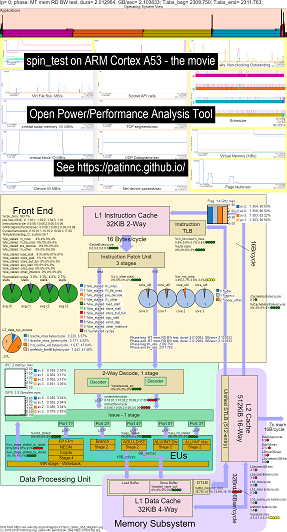
- Есть некоторые вводные слайды, чтобы попытаться объяснить диаграммы OS_VIEW и компоновку CPU_DIAGRAM, показывает слайд, показывающий в этот момент (в секунды) каждый субпрограммы (так что вы можете перейти к T = x Secs, чтобы перейти непосредственно к этому подпроводу), а затем по одному слайду для каждого из 5 поддтестов.
- Файл Excel данных в фильме: File Excel от Geekbench The Movie
- HTML данных в фильме ... см. Arm Cortex A53 Raspberry Pi 3 с диаграммой CPU с 4-ядерным чипом.
- Dashboard PNG для всех 5 фаз, отсортированных по увеличению инструкций/с ... см. Arm Cortex A53 Raspberry Pi 3 с диаграммой процессора с 4-ядерной приборной панелью.
Вот несколько примеров данных для запуска Geekbench на процессорах Haswell:
- Видео с диаграммой изменений в схеме OS_VIEW и HASWELL ЦП -диаграммы под управлением GeekBench:
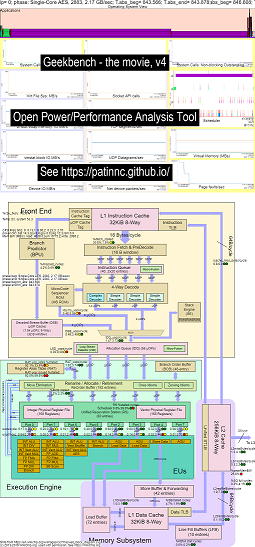
- Есть некоторые вводные слайды, чтобы попытаться объяснить диаграммы OS_VIEW и компоновку CPU_DIAGRAM, показывающий слайд, показывающий в этот момент (в секунды) каждый субпрограммы (так что вы можете перейти к T = X SEC, чтобы перейти к этому подпроводу), а затем один слайд для каждого из 50 поддтестов.
- Файл Excel данных в фильме: File Excel от Geekbench The Movie
- HTML данных в фильме ... См. Intel Haswell с диаграммой процессора 4-CPU, работающий в Geekbench.
- Dashboard PNG для всех 50 фаз, отсортированных по увеличению выхода на пенсию UOPS/SEC ... См. Dashboard Intel Haswell с диаграммой процессора с 4-ядерной приборной панелью с помощью Geekbench.
Вот несколько данных для запуска моего «спин» с 4 подпрограммами на процессорах Haswell:
- 1 -й подтест - это тест пропускной способности считывания памяти. Блок L2/L3/памяти высоко используется и застопорит во время теста. Крысы UOPS/цикл низкий, так как крыса в основном остановилась.
- 2 -й подтест - это тест пропускной способности L3. Память BW теперь низкая. Блок L2 & L3 высоко используется и застопорит во время теста. Крысы UOPS/цикл выше, так как крыса менее остановилась.
- 3 -й подтест - это тест пропускной способности L2. L3 и память BW теперь низко. Блок L2 высоко используется и остановился во время теста. Крысы UOPS/цикл еще выше, так как крыса еще менее остановилась.
- 4 -й подтест - это спин (просто петля ADD). L2, L3 и память BW около нуля. Крысы UOPS/цикл составляет около 3,3 UOPS/цикл, который приближается к 4 UOPS/MAX MAX.
- Видео об изменениях в диаграмме блоков CPU Haswell, используемой «Spin» с анализом. Видеть
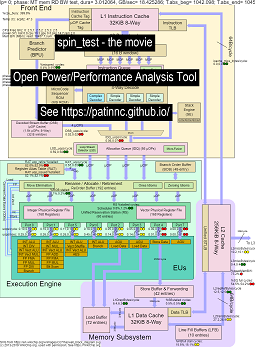
- Файл Excel данных в фильме: файл Excel из Spin The Foilm
- HTML данных в фильме ... см. Intel Haswell с диаграммой CPU 4-CPU CHIP CHIP CHIP SPINGMARK.
Intel Haswell с коллекциями данных диаграммы процессора предназначена для чипа Intel 4-CPU, Linux OS, HTML-файла с 50+ событиями HW через выборку PRF и другие собранные данные. Функции CPU_DIAGRAM:
- Начните с блок -схемы SVG от wikichip.org (используется с разрешения),
- Посмотрите на ограничения ресурсов (такие как Max BW, максимальные байты/цикл по различным путям, минимальные циклы/UOP и т. Д.),
- Вычислить метрики для использования ресурсов
- Ниже приведена таблица теста пропускной способности считывания памяти, которая отображает информацию об использовании ресурса в таблице (наряду с оценкой того, остановился ли ЦП из -за использования). В таблице HTML (но не в PNG) есть всплывающая информация, когда вы падаете над полями. Таблица показывает, что:
- Ядро застопорится на пропускной способности памяти на 55% от максимального момента 25,9 ГБ/с. Это тест на память BW
- Superqueue (SQ) заполнена (54,5% для Core0 и 62,3% Core1) циклов (так что нельзя обработать больше запросов L2)
- Линейный буфер FB FB заполнен (30% и 51%), поэтому линии не могут быть перемещены в L1D от L2
- Результатом является то, что бэкэнд остановился (88% и 87%) циклов, которые не выходят на пенсию.
- UOP, кажется, поступают от детектора потока петли (поскольку циклы LSD/UOP примерно так же, как у крыс UOPS/Cycle.
- Снимок экрана схемы памятью диаграммы процессора Haswell BW
- Ниже приведена таблица теста пропускной способности L3.
- Теперь память BW и L3 Miss Bytes/Cycle - это около нуля.
- SQ менее остановился (так как мы не ждем памяти).
- Транзакции L2 Байты/циклы примерно в 2 раза выше и примерно на 67% от максимума возможного 64 байта/цикла.
- Цикл UOPS_RETIRETIRE_STALLS/упал до 66% от испытательного стойла MEM BW 88%.
- Заливные буферные киоски теперь более чем в 2 раза выше. UOP все еще исходят от LSD.
- Снимок экрана диаграммы процессора Haswell L3 BW Table
- Ниже приведена таблица теста пропускной способности L2.
- L2 пропускает байты/цикл намного ниже, чем тест L3.
- Употребление UOPS_RETITIRET% в настоящее время составляет около половины теста L3 в 34%, а киоски FB также составляют около 17%.
- Уопы все еще исходят от ЛСД.
- Снимок экрана диаграммы процессора Haswell L2 BW Table
- Ниже приведена таблица спинового теста (без нагрузок, просто добавьте в цикл).
- Теперь есть всего лишь нулевые подсистемы памяти.
- UOP поступают из буфера Decode Stream (DSB).
- Крыса nefite_uops/цикл при 3,31 цикла/UOP находится вблизи максимального возможного 4,0 UOPS/Cycle.
- Крыса на пенсии на пенсии на пенсии %остановилась довольно низкая при %8.
- снимок экрана таблицы спиновой диаграммы Haswell Diagram
В настоящее время у меня есть только фильмы CPU_DIAGRAM для Haswell и ARM A53 (поскольку у меня нет других систем для тестирования), но их не сложно добавить другие блок -схемы. Вы все еще получаете все диаграммы, но не CPU_DIAGRAM.
Ниже приведена одна из карт OPPAT. Диаграмма «CPU_BUSY» показывает, что работает на каждом процессоре, и события, которые происходят в каждом процессоре. Например, зеленый круг показывает нить spin.x, работающую на процессоре 1. Красный круг показывает некоторые события, происходящие на процессоре. Эта диаграмма смоделирована после карты Trace-CMD от Kernelshark. Более подробная информация о диаграмме CPU_BUSY находится в разделе диаграммы. В поле выигрывания показаны данные о событии (включая CallStack (если есть)) для события под курсором. К сожалению, скриншот Windows не захватывает курсор. 
Вот несколько примеров HTML -файлов. Большинство файлов предназначены для более короткого интервала ~ 2, но некоторые из них являются «полными» 8 секунд. Файлы не будут загружаться непосредственно из репо, но они будут загружаться с веб -страницы проекта: https://patinnc.github.io
- Intel Haswell с диаграммой процессора 4-CPU Chip, OS Linux, HTML-файл с 50+ HW событиями через отбор проб PRF или
- Чип 4-CPU Intel, ОС Windows, HTML-файл с 1 HW событиями через выборку XPERF или
- Полный ~ 8 секунд Intel 4-CPU Chip, ОС Windows, HTML-файл с PCM и XPERF-выборкой или
- Intel 4-CPU Chip, Linux OS, HTML-файл с 10 HW событиями в 2 мультиплексных группах.
- Чип ARM (Broadcom A53), Raspberry PI3 Linux HTML -файл с 14 HW событиями (для CPI, L2 MISSES, MEM BW и т. Д. В 2 мультиплексных группах).
- 11 МБ, полная версия чипа выше ARM (Broadcom A53), Raspberry PI3 Linux HTML -файл с 14 HW событиями (для CPI, L2 MISSES, MEM BW и т. Д. В 2 мультиплексных группах).
Некоторые из вышеперечисленных файлов представляют собой ~ 2 секунду интервалы, извлеченные из ~ 8 секунд длинных прогонов. Вот полный 8 секунд:
- Полный 8 -секундной сжатый HTML -сжатый файл Linux для более полного файла. Файл выполняет JavaScript Zlib Decompress данных диаграммы, поэтому вы увидите сообщения с просьбой подождать (около 20 секунд) во время декомпрессации.
Данные OPPAT поддерживаются
- Linux perf и/или файлы производительности TRACE-CMD (как двоичные, так и текстовые файлы),
- Вывод статистики Perf также принимается
- Intel PCM данные,
- Другие данные (импортируются с использованием сценариев LUA),
- Так что это должно работать с данными из обычного Linux или Android
- В настоящее время для данных PERF и TRACE-CMD, OPPAT требует как двоичных, так и пост-обработанных текстовых файлов, и в командной строке «Запись» есть некоторые ограничения и в командной строке «Perf Script/Trace-CMD».
- OPPAT может быть сделан для простого использования выходных файлов текста PRF/TRACE-CMD, но в настоящее время требуются двоичные и текстовые файлы
- Данные Windows ETW (собранные XPERF и сброшены в текст) или данные Intel PCM,
- Произвольные данные о мощности или производительности, поддерживаемые с использованием сценариев LUA (поэтому вам не нужно перекомпилировать код C ++ для импорта других данных (если производительность LUA не станет проблемой))))
- Прочитайте файлы данных на Linux или Windows независимо от того, откуда возникли файлы (так что прочитайте файлы perf/trace-cmd в текстовых файлах Windows или ETW на Linux)
Оппотса визуализация
Вот несколько полных образцов файлов html Visualzation: пример HTML -файла Windows или этот пример HTML -файла Linux. Если вы находитесь в репо (не на веб -сайте проекта github.io), вам придется загрузить файл, а затем загрузить его в свой браузер. Это автономные веб -файлы, созданные OPPAT, которые могут быть, например, отправлены по электронной почте другим или (как здесь), размещенные на веб -сервере.
Oppat Viz работает лучше в Chrome, чем Firefox, в первую очередь потому, что зум с использованием прокрутки пальцев TouchPad 2 работает лучше на хроме.
OPPAT имеет 3 режима визуализации:
- Обычный механизм диаграммы (где бэкэнд Oppat считывает файлы данных и отправляет данные в браузер)
- Вы также можете создать автономную веб-страницу, которая является эквивалентом «регулярного механизма диаграммы», но может быть обменена с другими пользователями ... автономная веб-страница имеет все сценарии и данные, чтобы его можно было отправить по электронной почте, и они могут загрузить ее в свой браузер. См. Файлы HTML в образец_HTML_FILES, ссылаясь выше и (более длинная версия LNX_MEM_BW4) см.
- Вы можете '-сдать файл JSON Data, а затем-загрузить файл позже. Сохраненный файл JSON имеет данные, которые OPPAT должен отправить в браузер. Это избегает перечитывания файлов ввода PERF/XPERF, но не будет привлекать никаких изменений, внесенных в диаграммы. Полный HTML -файл, созданный с помощью параметра -web_file, лишь немного больше, чем файл -save. Режим--сале/-загрузка требует строительства OPPAT. См. Пример «Сохраняемые» файлы в SAMER_DATA_JSON_FILES Subdir.
А именно общая информация
- Наметить все данные в браузере (на Linux или Windows)
- Диаграммы определены в файле JSON, поэтому вы можете добавлять события и диаграммы без перекомпиляции Oppat
- Интерфейс браузера похож на Windows WPA (Navbar слева).
- Ниже показано левое Navbar (меню с левой стороной).
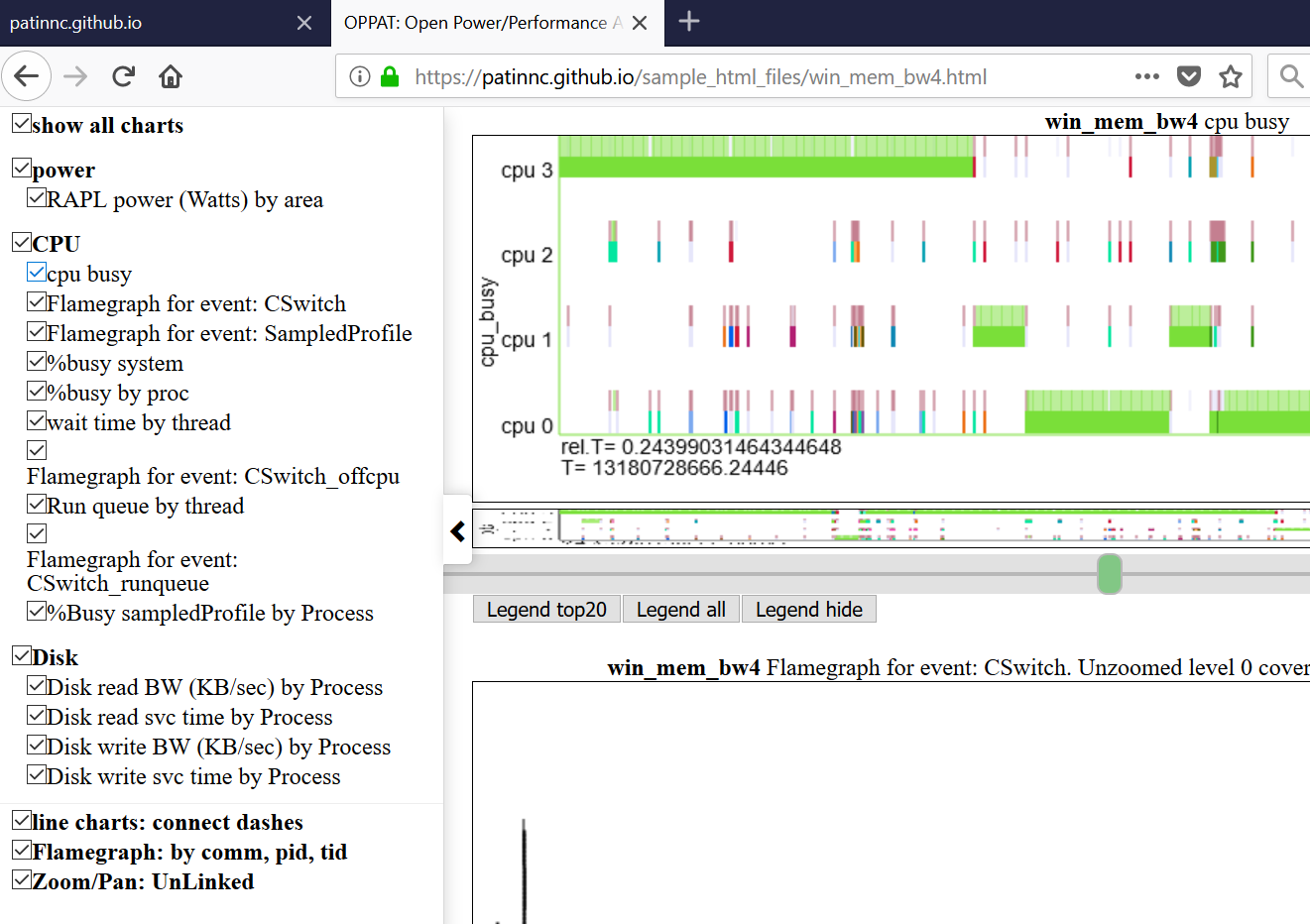
- Диаграммы сгруппированы по категории (графический процессор, процессор, власть и т. Д.)
- Категории определены и назначены в input_files/charts.json
- Диаграммы могут быть скрыты или выборочно отображаться, нажав на диаграмму в Navbar.
- парясь над титулом диаграммы в прокрутках меню «Левая навига
- Данные из одной группы файлов могут быть построены вместе с другой группой
- Итак, вы можете сказать, сравните производительность Linux Perf с пробегом Windows ETW
- Ниже диаграмма Show Linux против использования питания Windows:
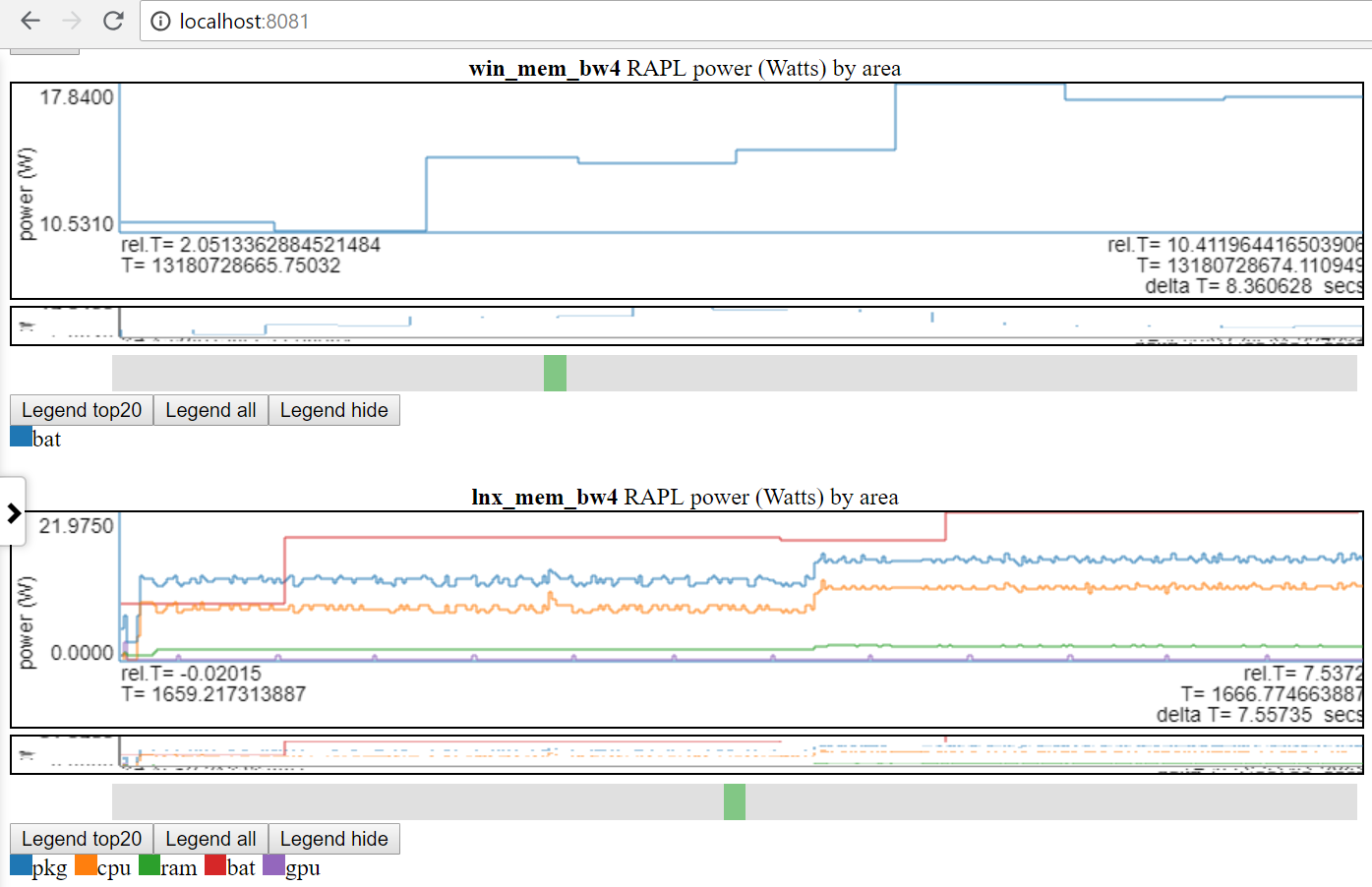
- У меня есть доступ только к питанию батареи как на Linux, так и на Windows.
- Многие сайты имеют гораздо лучшие данные о мощности (напряжения/токи/мощность по скорости MSEC (или лучшему)). Было бы легко включить эти типы данных о мощности (например, из Kratos или Qualcomm MDP), но у меня нет доступа к данным.
- или сравните 2 различных прогона на одной и той же платформе
- Тег группы файлов (file_tag) префиксируется в заголовке, чтобы отличить диаграммы
- «Tag» определяется в файле Data Dir File_list.json и/или input_files/input_data_files.json
- input_files/input_data_files.json - это список всех DIRS DATA OPPAT (но пользователь должен поддерживать его).
- Диаграммы с одним и тем же названием наложены один за другим, чтобы легко сравнивать
Функции диаграммы:
Парив над разделом линии диаграммы показывает точку данных для этой линии на этой точке
- Это не работает для вертикальных линий, поскольку они просто подключают 2 точки ... только горизонтальные части каждой строки ищут значение данных
- Ниже приведен скриншот парящего над событием. Это показывает относительное время события (CSWTICH), некоторую информацию, такую как Process/PID/TID и номер строки в текстовом файле, чтобы вы могли получить больше информации.

- Ниже приводится скриншот, показывающий информацию о вызове (если есть) для событий.

увеличение
- Неограниченное увеличение уровня наносек.
- Вероятно, на график на графике есть больше порядков, чем пиксели, поэтому при масштабировании отображается больше данных.
- Ниже приведен скриншот, показывающий масштаб до уровня микросекунды. Это показывает CallStack для события chard_switch, где Spin.x заблокирован, выполняя операцию отображения памяти и простоя. Диаграмма «Занят процессор» показывает, что «простаивается» как пусто.
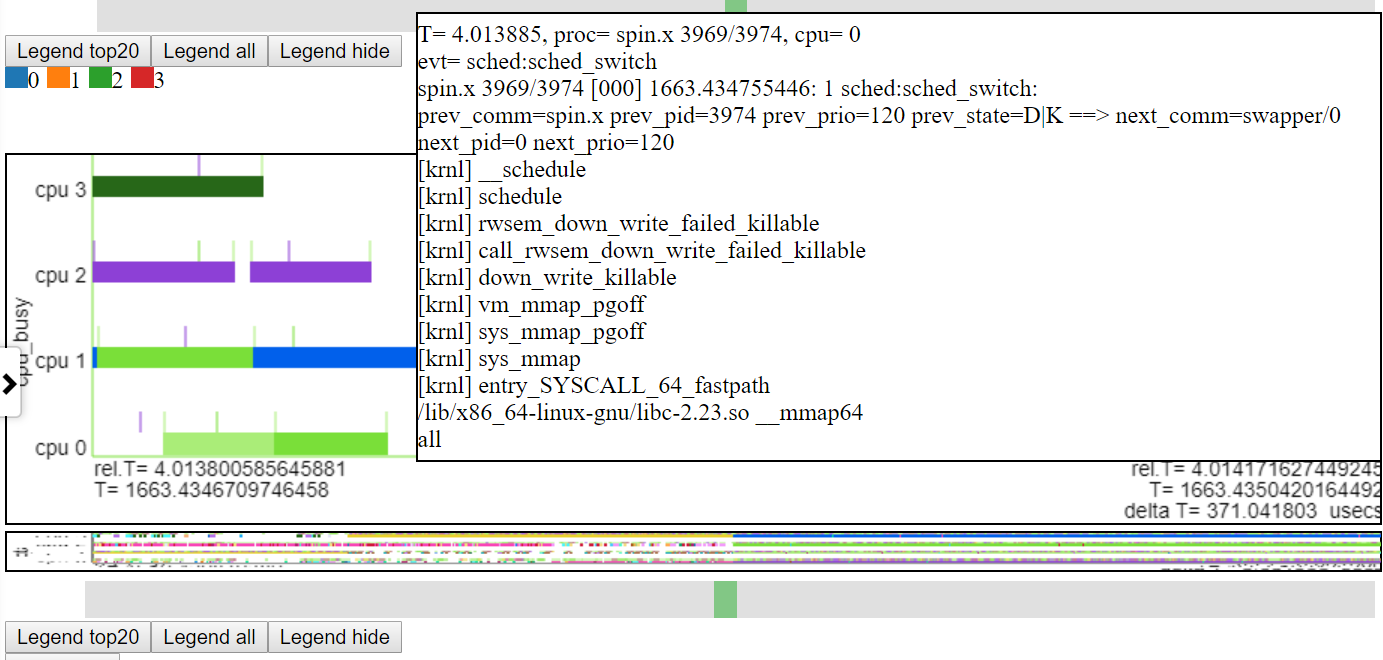 Полем
Полем
- Диаграммы могут быть увеличены индивидуально, или диаграммы с одним и тем же файлом_Таг могут быть связаны, чтобы увеличить/панорамирование 1 диаграммы изменяют интервал всех диаграмм с одним и тем же файлом_tag
- Прокрутите в нижнюю часть левой навигации и нажмите «Зум/кастрюля: не связанный». Это изменит пункт меню на «Zoom/Pan: Linked». Это приведет к увеличению/панированию всех диаграмм в группе файлов до самого последнего абсолютного времени Zoom/Pan. Это займет некоторое время, чтобы перерисовать все диаграммы.
- Первоначально нарисована каждая диаграмма, отображающая все доступные данные. Если ваши диаграммы из разных источников, то T_BEGIN и T_END (для диаграмм из разных источников), вероятно, разные.
- После того, как операция масштабирования/сковороды будет выполнена, и связывание вступает в силу, все диаграммы в группе файлов будут масштабировать/PAN до одного и того же абсолютного интервала.
- Вот почему «часы», используемые для каждого источника, должны быть одинаковыми.
- OPPAT может перевести с одного часа на другое (например, между getTime (clock_monotonic) и getTimeOfday ()), но эта логика
- Любые пламенные графы для интервала всегда увеличиваются до интервала «владения графиками» независимо от статуса связывания.
- Вы можете увеличить/up -out:
- Увеличьте: колесо мыши вертикально на графике. Диаграмма увеличивается на время в центре диаграммы.
- На моем ноутбуке это прокручивает 2 пальца вертикально на сенсорной панели
- Увеличьте увеличение: щелкнуть на график и перетаскивать мышь вправо и выпустить мышь (диаграмма будет увеличиваться до выбранного интервала)
- Увеличение увеличения: щелчок на графике и перетаскивание мыши влево и выпуск мыши будет увеличиваться в виде обратно пропорционально той, сколько выбравшей вами диаграммы. То есть, если вы оставите почти всю область диаграммы, то диаграмма будет увеличиваться ~ 2 раза. Если вы только что оставите, перетащите небольшой интервал, то диаграмма будет увеличивать ~ весь путь.
- Увеличьте увеличение: на моем ноутбуке, выполняя вертикальную свиток с вертикальной панелью 2 пальца в противоположном направлении Zoom
- Вы должны быть осторожны там, где курсор ... вы можете непреднамеренно увеличить диаграмму, когда хотите прокрутить список диаграмм. Поэтому я обычно кладу курсор на левый край экрана, когда хочу прокрутить диаграммы.
панорамирование
- На моем ноутбуке это делает 2 пальца на горизонтальном движении прокрутки на сенсорной панели
- Использование зеленого ящика на миниатюре под диаграммой
- панорамирование работает на любом уровне масштабирования
- «Миниатюра» изображение полной диаграммы помещается под каждой диаграммой с курсором, чтобы скользить по миниатюре, чтобы вы могли перемещаться по графике, когда вы увеличиваете/панорамируют
- Ниже показана панорамирование диаграммы «Занятие процессора» до t = 1,8-2,37 секунды. Относительное время и абсолютное время начала находятся в левом красном овале. Время окончания выделено в правом красном овале. Относительное положение на миниатюре показана средним красным овалом.
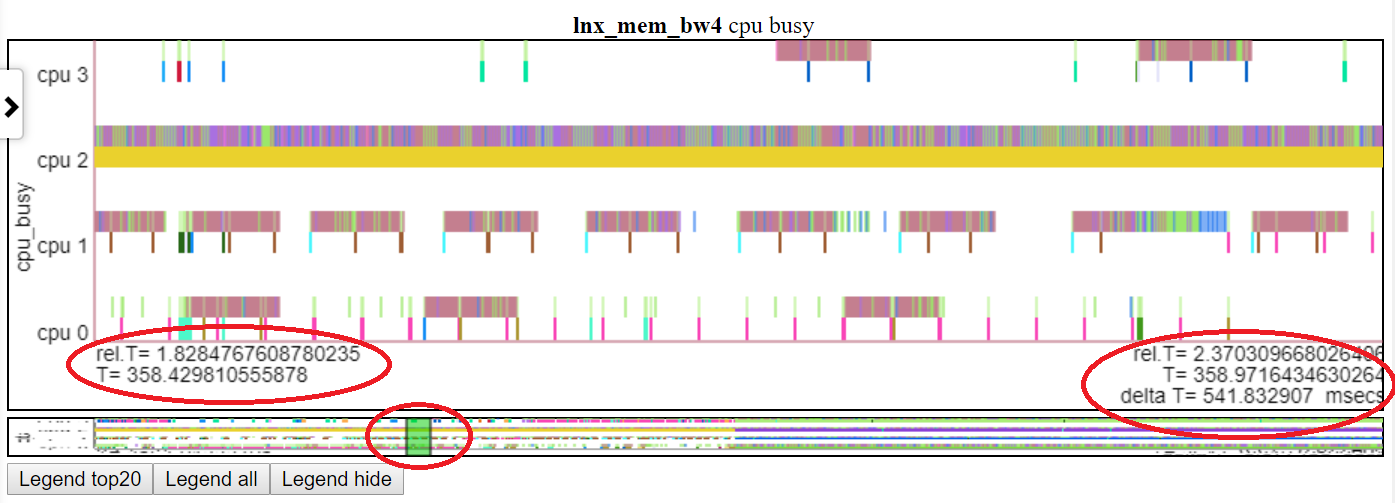 Полем
Полем
Находясь на запись легенды, подчеркивает эту линию.
- Ниже приведен снимка экрана, где выделяется мощность «PKG» (Package)
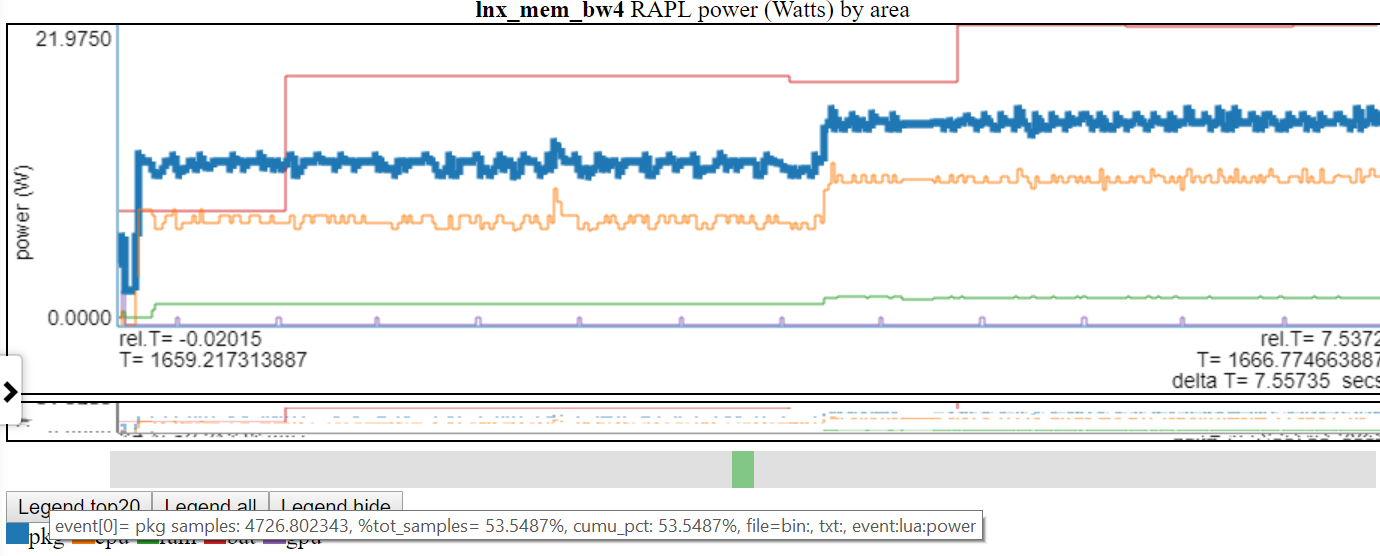
Нажатие на входную входную плату, переключает видимость этой линии.
Двойной щелчок в записи легенды делает только эту запись видимой/скрытой
- Ниже приведен скриншот, где питание «PKG» была дважды щелчена, так что видна только линия PKG.
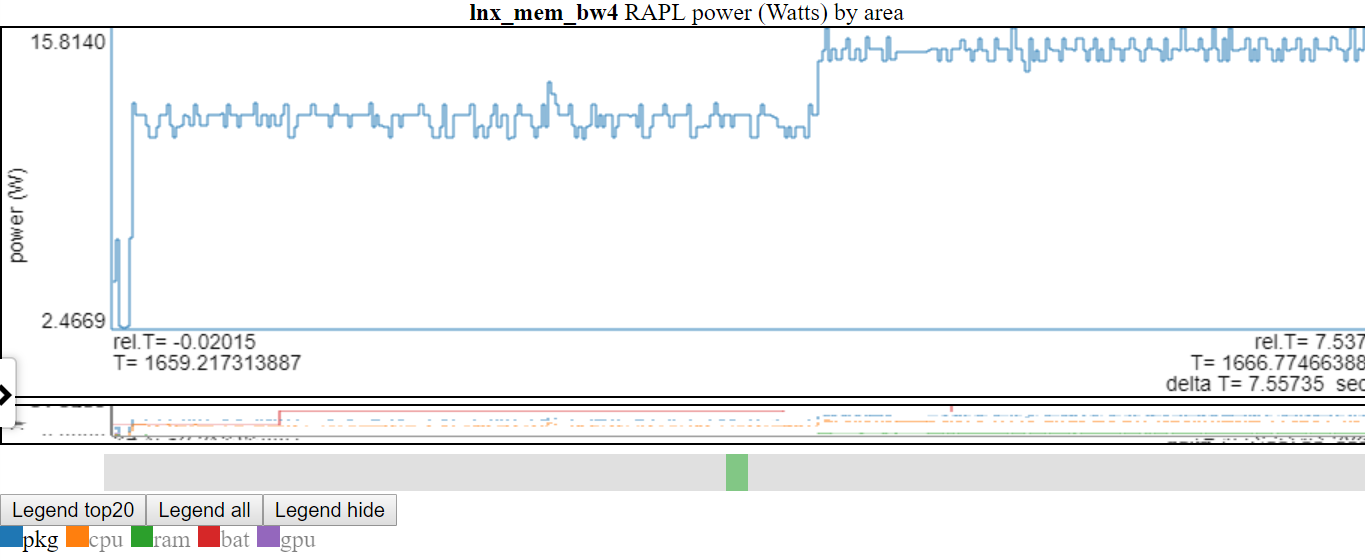
- Выше показано, что ось y регулируется до мин/максимума отображаемой переменной (ов). Линии «не показаны» серого цвета в легенде. Если вы нависаете над линией «не показана» в легенде, она будет нарисована (пока вы падаете на предмете легенды). Вы можете получить все элементы, чтобы отобразить снова, дважды щелкнув «не совместимой» легендарную запись. Это покажет все линии «не показаны», но это вылетит только что нажали на линию ... так что один щелчок на один щелчок, который вы просто дважды щелкнули. Я знаю, это звучит сбивает с толку.
Если запись с скрыты
Типы диаграмм:
Диаграмма CPU занята: таблица, похожая на ядро, показывающая занятость процессора с помощью PID/Thread. См. Ссылка на Kernelshark http://rostedt.homelinux.com/kernelshark/
- Ниже приведен снимка экрана картинга загруженного процессора. Диаграмма показывает для каждого процессора процесса/PID/TID, работающего в любой момент времени. Процесс холостого хода не нарисован. Для «CPU 1» на скриншоте зеленый овал находится вокруг части диаграммы «переключатель контекста». Над каждой информацией о контексте процессоров CPU CPU Занятая события показывают события, представленные в том же файле, что и событие коммутатора контекста. Красный овал на линии CPU 1 показывает часть события.
- Диаграмма основана на событии переключения контекста и показывает поток, работающий на каждом процессоре в любой момент времени.
- Событие Context Switch - это Linux Shade: ched_switch или событие Windows Etw Cswitch.
- Если событий больше, чем контекстный переключатель в файле данных, то все остальные события представлены в виде вертикальных тире над процессором.
- Если в событиях есть стеки вызовов, то стек вызовов также показан на всплывающем воздушном шаре
линейные диаграммы
- Линейные диаграммы, вероятно, более точно называются поэтапными диаграммами, так как каждое событие (до сих пор) имеет продолжительность, и эти «продолжительность» представлены горизонтальными сегментами и соединены вертикальными сегментами.
- Вертикальная часть этап -диаграммы может заполнить диаграмму, если линии диаграмм имеют много вариаций
- Вы можете выбрать (в левой навигационной панели), чтобы не подключать горизонтальные сегменты каждой линии ... так что диаграмма становится своего рода «рассеянной чертой». «Горизонатальные тире» - это фактические точки данных. Когда вы переключаетесь от Step -Hard, на Dash Dick, диаграмма не перерисована до тех пор, пока не появится какой -то запрос «RedRaw» (например, Zoom/Pan или Highling (путем парящего в записи легенды)).
- Ниже приведен скриншот состояний мощности CPU_IDLE с использованием линейной диаграммы. Соединительные линии раздувают информацию на графике.
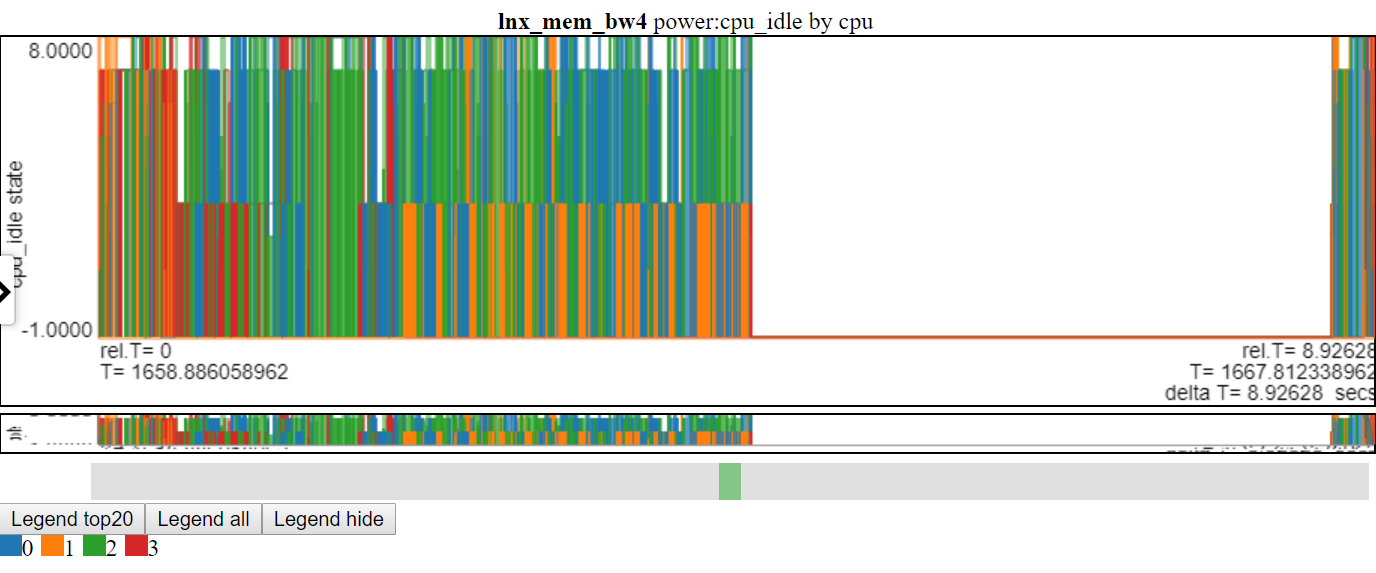
- Ниже приведен скриншот состояний мощности CPU_IDLE с использованием диаграммы рассеянного рисунка. Таблица теперь показывает горизонтальную черту для точки данных (ширина приборной панели - продолжительность события). Теперь мы можем увидеть больше информации, но на этом диаграмме также показан недостаток с моей логикой диаграммы: многие данные находятся на максимальном значении и на значении минимального диаграммы, и он затенен.
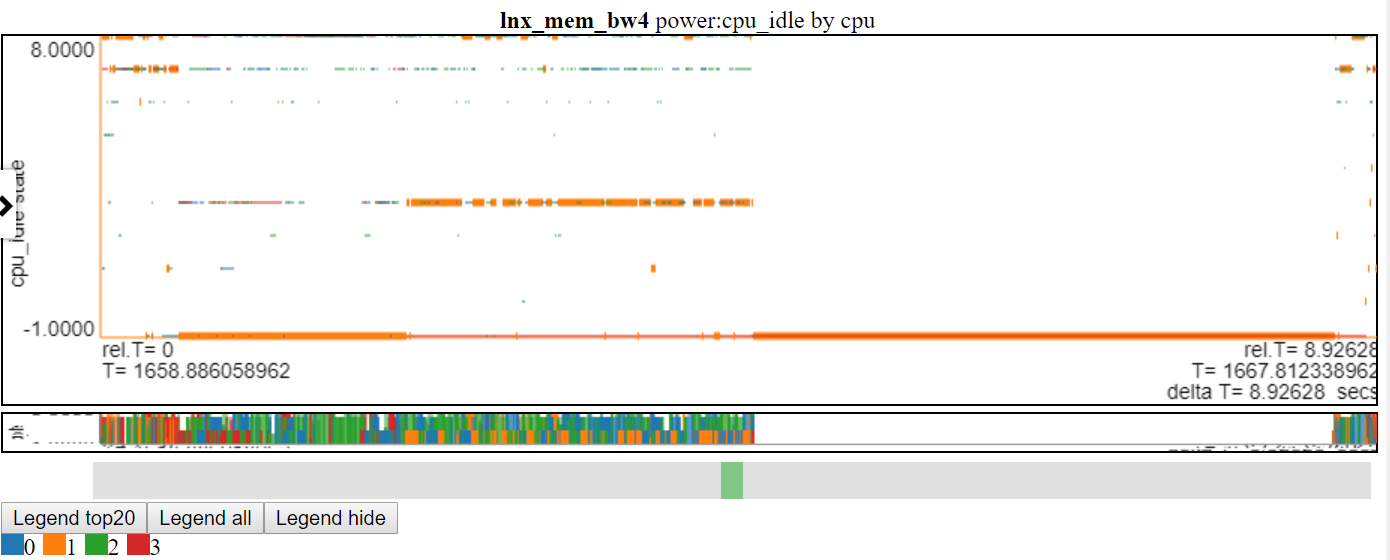
Сложные диаграммы
- Сложные диаграммы могут привести к созданию гораздо большего количества данных, чем линейные диаграммы. Например, рисование линейной диаграммы, когда используется конкретный поток, зависит только от этого потока. Нарисование сложенного диаграммы для запуска потоков отличается: событие переключения контекста в любом потоке изменит все остальные потоки ... поэтому, если у вас есть N-процессоры, вы получите больше N-1, чтобы рисовать на событие для сложенных диаграмм.
Пламениграфы. Для каждого события PERF, которое имеет CallStacks и находится в том же файле, что и событие SHADE_SWITCH/CSWITCH, создается фламиграф.
- Ниже приведен снимка экрана типичного пламенного графа по умолчанию. Обычно высота по умолчанию диаграммы FlameGraph недостаточно для того, чтобы вписать текст на каждый уровень пламени. Но вы все еще получаете информацию о вызове «накачать».
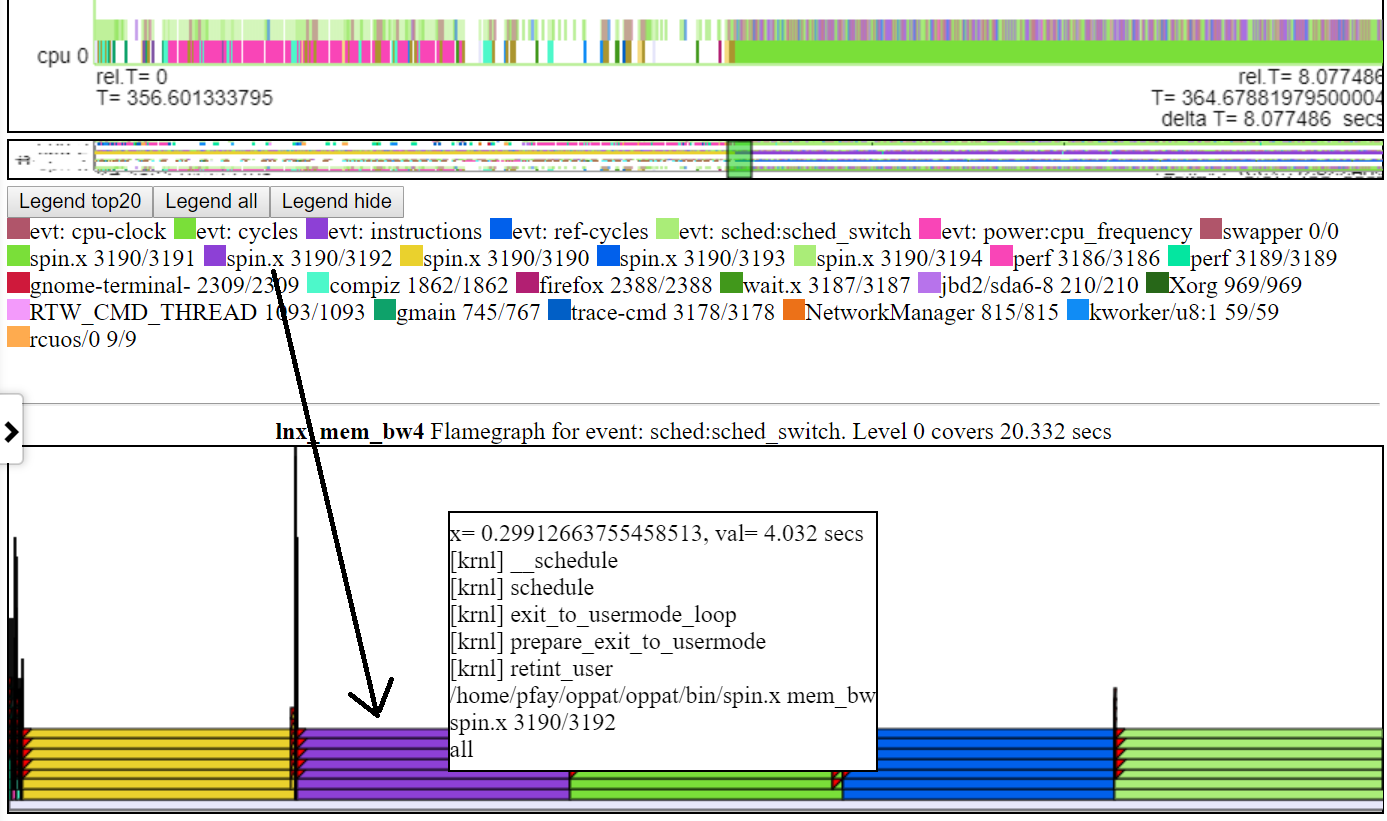 Полем
Полем- Если вы нажимаете на слой диаграммы, он расширяется выше, так что текст подходит. Если вы нажимаете на самый низкий уровень, он охватывает все данные для интервала «владения диаграммой».
- Ниже приведен скриншот увеличенного пламенного графа (после нажатия на один из слоев пламени).
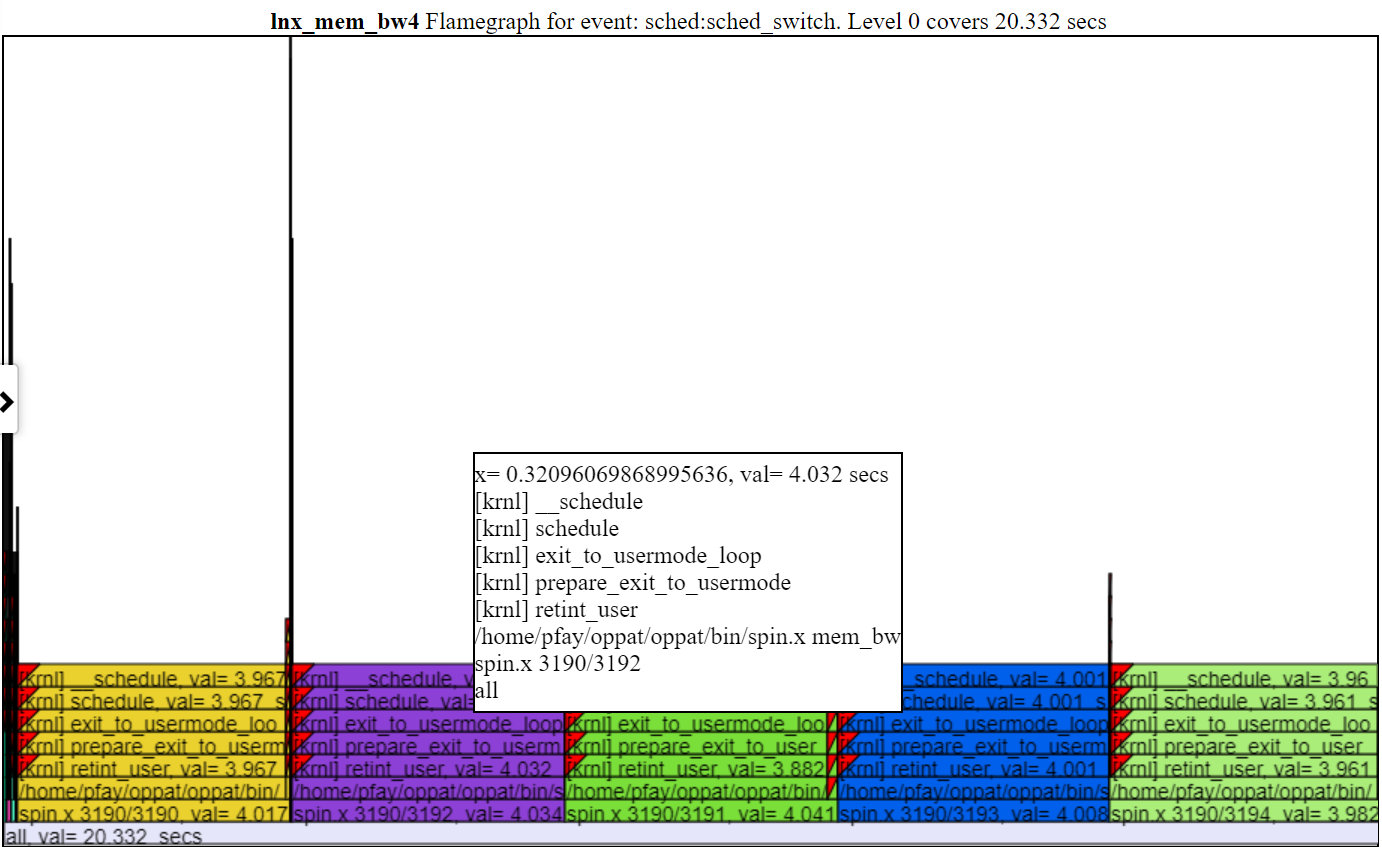 Полем
Полем- Обычно высота по умолчанию диаграммы FlameGraph недостаточно для того, чтобы вписать текст на каждый уровень пламени. Но вы все еще получаете информацию о вызове «накачать».
- Цвет пламениграфа соответствует процессу/PID/TID в диаграмме Legend of CPU_BUSY ... так что он не так красив, как пламенграф, но теперь цвет «пламени» на самом деле что -то значит.
- Диаграмма CPI (часы на инструкцию) расцветает процесс/PID/TID с помощью CPI для этого стека.
- Ниже приведен образец незамеченной диаграммы CPI. Левый экземпляр spin.x (в светло-оранжевом) имеет ИПЦ = 2,26 цикла/инструкция. 4 Spin.x справа в светло -зеленых имеют ИПЦ = 6,465.
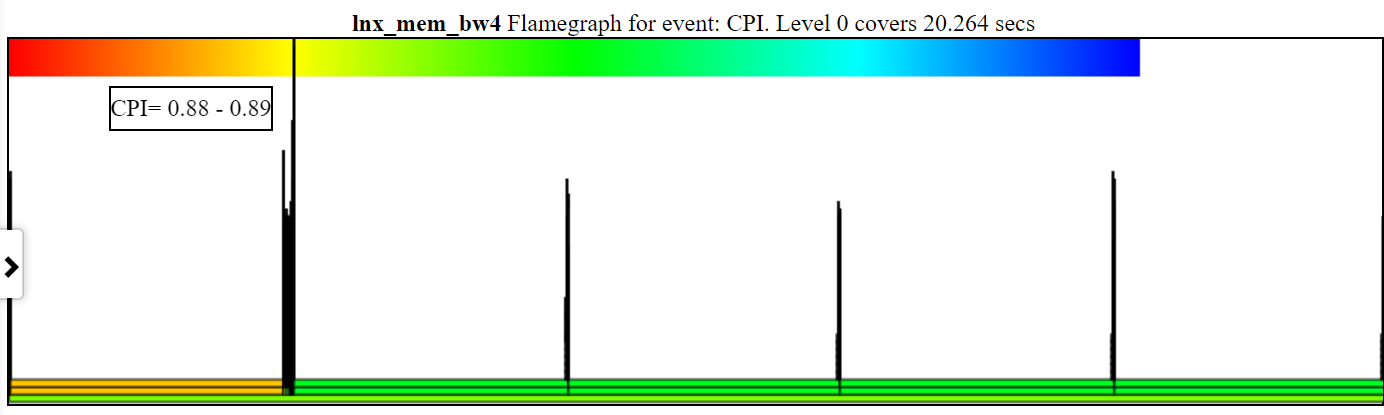
- У вас должны быть циклы, инструкции и CLOCK-CLOCK (или SHADE_SWITCH) CALLSTACKS
- Ширина CPI «пламени» основана на времени зажигания процессора.
- Цвет основан на ИПЦ. От красного до зеленого до синего градиента в левом верхнем левом углу показана окраска.
- Красный - это низкий ИПЦ (так много инструкций за часы ... Я думаю об этом как «горячо»)
- Синий - это высокий ИПЦ (так мало инструкций за часы ... Я думаю об этом как «холодно»)
- Ниже приведена образца увеличенной диаграммы CPI, показывающей окраску и CPI. Потоки «spin.x» были отпущены в легенде CPU_BUSY, поэтому они не появляются в пламени.
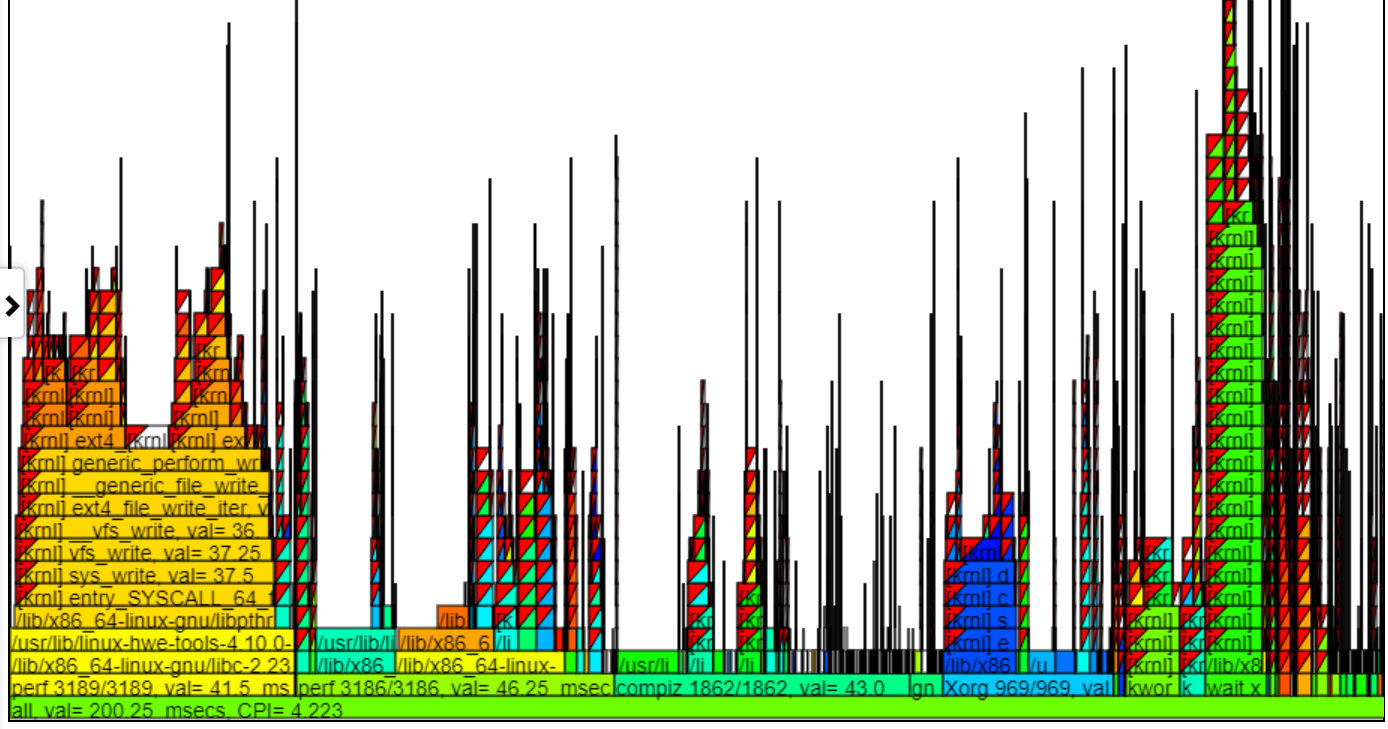
- Инструкции по гип (Гига (миллиард) в секунду) график раскрашивает процесс/пид/тид с помощью GIP для этого стека.
- Ниже приведен образец неоспитанной таблицы (инструкции Giga/миллиард инструкций в секунду). Левый экземпляр spin.x (в светло-зеленых) имеет тачки = 1,13. 4 Spin.x справа в голубом зелене имеют тачки = 0,377. Callstack в воздушном шаре для одного вызовов Spike CallStacks слева от воздушного шара.

- В приведенной выше диаграмме обратите внимание, что левый стек (для spin.x) получают более высокие инструкции/сек, чем самые правые 4 экземпляра Spin.x. Эти 1 -й экземпляр spin.x запускается сама по себе (поэтому получает много памяти BW) и справа 4 резьбы Spin.x запускаются параллельно и получают более низкие талочки (так как один поток может практически максимально вывести память BW).
- У вас должны быть инструкции и CPU-Clock (или SHADE_SWITCH) CALLSTACKS
- Ширина тапов «пламя» основана на времени зажигания процессора.
- Цвет основан на цыганах. От красного до зеленого до синего градиента в левом верхнем левом углу показана окраска.
- Красный - это высокие тачки (так много инструкций в секунду ... Я думаю об этом как о «горячих», выполняя много работы)
- Синие - это низкопочт (так мало инструкций в секунду ... Я думаю об этом как «холодно»)
- Ниже приведена образец увеличенного диаграммы GIP, показывающего окраску и тачки. Я нажал на «PRF PRF 3186/3186», так что только это пламя показано ниже.
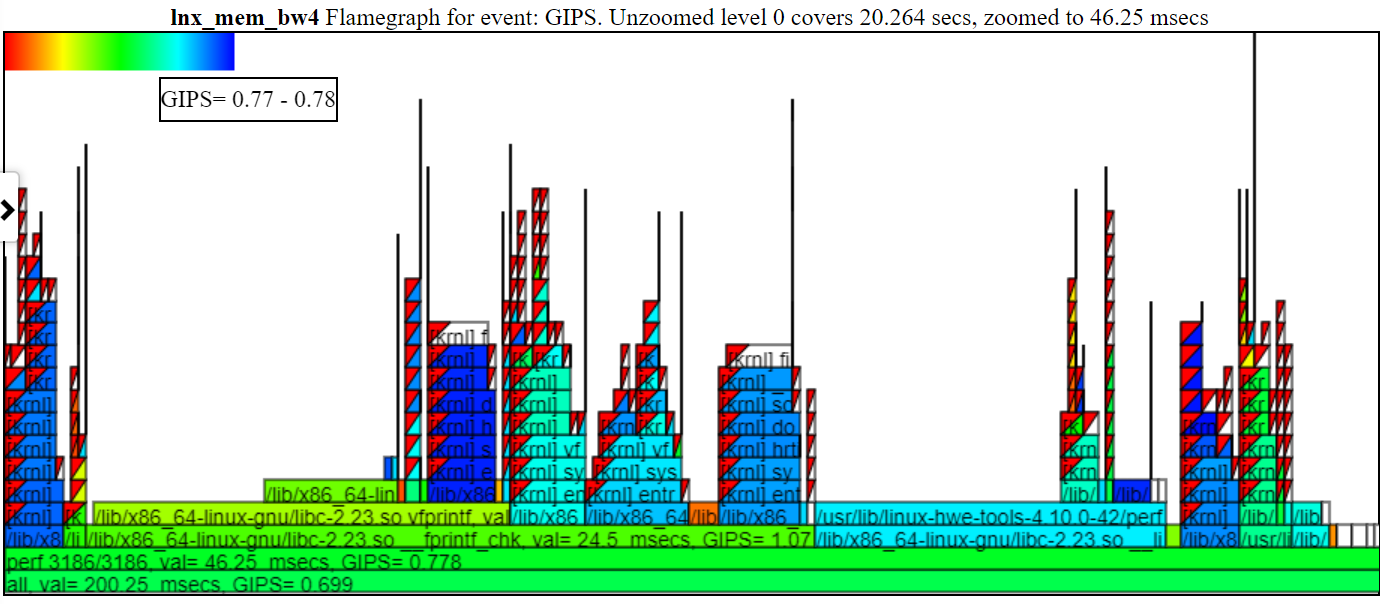
- Если вы скрываете процесс в легенде (нажмите на запись легенды ... он будет серо -выпущен), тогда процесс не будет отображаться в пламене.
- Если вы правы перетащите мышь в пламене, этот раздел FlameGraph будет увеличенным
- щелкнув на «пламени», чтобы увеличить это пламя
- влево перетаскивать мышь в пламениграте будет увеличиваться
- Нажав на более низкий уровень плазкового графа «раззум» ко всем данным для этого уровня
- Если вы нажмете на самый низкий уровень Flamegraph, вы будете увеличивать
- Когда вы нажимаете на уровень FlameGraph, диаграмма изменяется, так что каждый уровень достаточно высок, чтобы отобразить текст. Это приводит к изменению диаграммы. Чтобы попытаться добавить некоторое здравомыслие к этому изменению размера, я позиционирую последний уровень измененного диаграммы в нижней части видимого экрана.
- Если вы вернетесь в легенду и наведите на скрытую запись, то эта запись будет отображаться в пламени.
- Если вы нажмете на верхний уровень «пламени», то только этот раздел будет увеличен.
- Если вы увеличиваете масштабирование/из -за графика «родитель», то FlameGraphs будут перерисованы для выбранного интервала
- Если вы панируете влево/направо на графике «родитель», то пламенныеграфы будут перерисованы для выбранного интервала
- По умолчанию текст каждого уровня графа пламени, вероятно, не подходит. Если вы нажмете на FlameGraph, то размер будет расширен, чтобы включить рисование текста
- Вы можете выбрать (в левой панели навигации), будь то сгруппировать фламграф по процессу/pid/tid или по процессу/PID или справедливым процессом.
- Оба вытягивают планистые диаграммы «на процессоре», «Off CPU» и «Queue -Queue».
- «На процессоре»-это CallStack для того, что делал поток, когда он работал на процессоре ... так что вызовов CallStacks или CPU-Clock Clock-Clock-Caloc
- «Off CPU» показывает, для потоков, которые не работают, как долго они ждали, и Callstack, когда они поменялись.
- Ниже приведен скриншот графика вне CPU или времени ожидания. Всплывающее окно показывает (в фламиграфе), что «wat.x» ждет на наноспи.

- Смена «состояние» (и на ETW «разум») показан как уровень выше процесса. Обычно большинство потоков будут спать или не работать, но это помогает ответить на вопрос: «Когда моя ветка не запустилась ... чего она ждала?».
- Показывая «состояние» для переключателя контекста позволяет увидеть:
- Например, независимо от того, ждет ли поток на непрерывном сна (состояние == D на Linux ... обычно io)
- прерывистый сон (состояние = s ... часто наноспи или футекс)
- «run queue» показывает потоки, которые заменялись и находились в бегу или бегном состоянии. Таким образом, на этой таблице показана насыщение процессора, если в запущенном состоянии есть потоки, но не работает.
- Ниже приведен скриншот диаграммы run_queue. На этом диаграмме показана количество времени, которое нить не запускалась, потому что не хватало процессора. То есть он был готов к бегу, но что -то еще использовало процессор. Каждый фламиграф показывает общее количество, показанное на графике. В случае диаграммы run_queue, он показывает ~ 159 мсек во время ожидания. Таким образом, учитывая, что Spin.x имеет около 20 секунд времени выполнения и 0,159 секунды «ожидание», это не так уж и плохо.
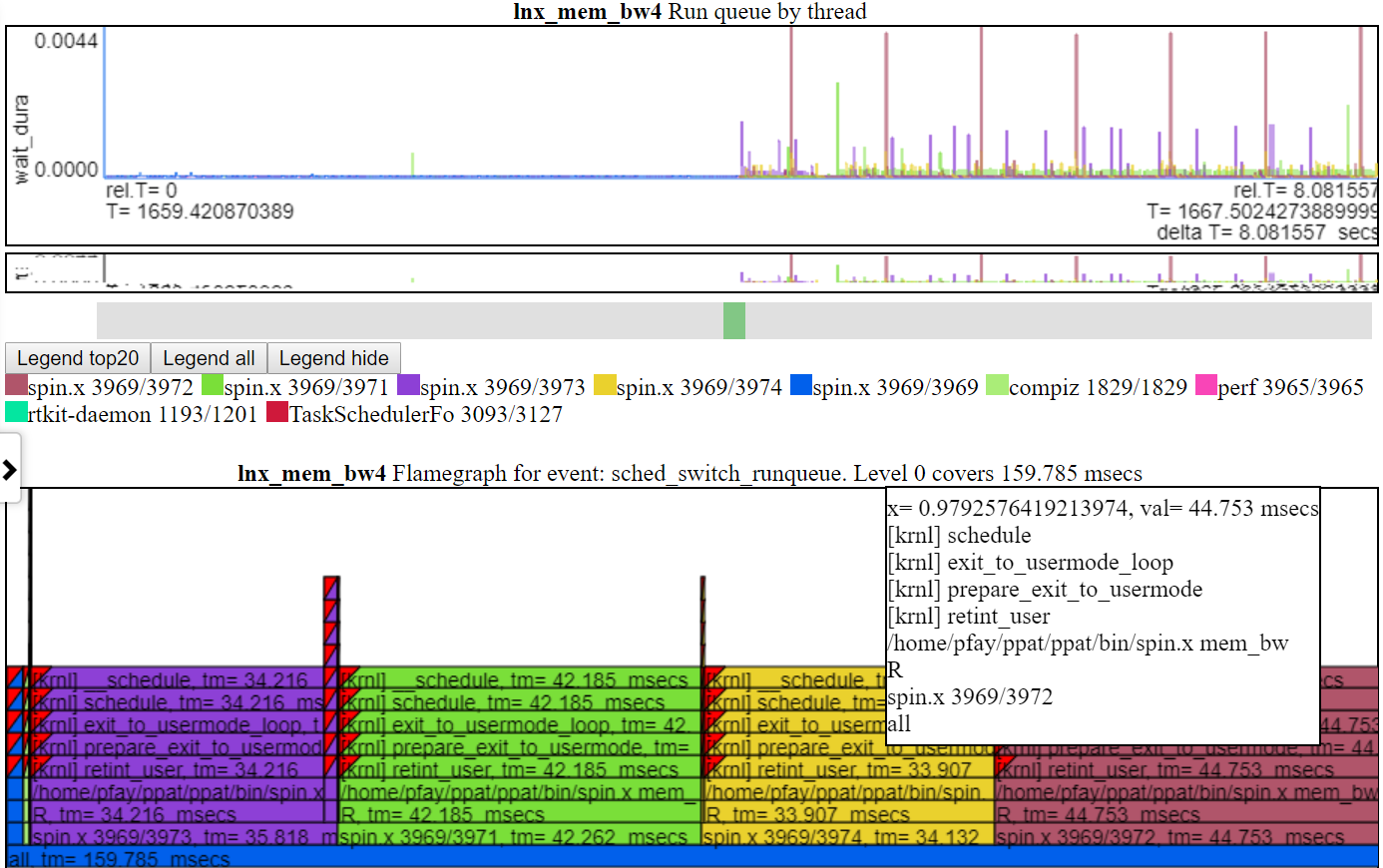
У меня не было библиотеки диаграмм на базе на холсте, поэтому диаграммы немного грубые ... Я не хотел тратить слишком много времени на создание диаграмм, если есть что-то лучшее. Диаграммы должны использовать холст HTML (не SVG, D3.JS и т. Д.) Из -за объема данных.
Сбор данных для OPPAT
Сбор данных производительности и мощности очень «ситуационно». Один человек захочет запустить сценарии, другой захочет запустить измерения с кнопкой, затем запустить видео, а затем закончить коллекцию нажатием кнопки. У меня есть скрипт для Windows и сценарий для Linux, который демонстрирует:
- начальный сбор данных,
- Запуск рабочей нагрузки,
- Остановить сбор данных
- Пост-обработка данных (создание текстового файла из двоичных данных perf/xperf/trace-cmd)
- Установка всех файлов данных в вывод
- Создание файла file_list.json в выводе Dir (который сообщает Oppat имен и тип выходных файлов)
Шаги для сбора данных с помощью сценариев:
- Утилиты Spin.exe (spin.x) и wate.exe (wate.x)
- от Oppat Root Dir Do:
- на Linux:
./mk_spin.sh - В Windows :
.mk_spin.bat (из коробки CMD Visual Studio) - Двоичные файлы будут помещены в поддир ./bin
- Начните с запуска предоставленных сценариев:
- run_perf_x86_haswell.sh - для сбора данных Haswell CPU_DIAGRAM
- На Linux, тип:
sudo bash ./scripts/run_perf.sh - По умолчанию скрипт помещает данные в dir ../oppat_data/lnx/mem_bw7
- run_perf.sh - вам нужно установить трассировку и перфу
- На Linux, тип:
sudo bash ./scripts/run_perf.sh - По умолчанию скрипт помещает данные в dir ../oppat_data/lnx/mem_bw4
- run_xperf.bat - вам нужно установить xperf.exe.
- В Windows, из CMD -поля с привилегиями администратора, введите :
.scriptsrun_xperf.sh - По умолчанию скрипт помещает данные в Dir .. Oppat_data Win mem_bw4
- Отредактируйте сценарий запуска, если хотите изменить значения по умолчанию
- В дополнение к файлам данных, сценарий запуска создает файл file_list.json в выводе Dir. OPPAT использует файл file_list.json, чтобы выяснить имена файлов и тип файлов в выводе.
- «Рабочая нагрузка» для сценария прогона - spin.x (или spin.exe), которая выполняет тест полосы пропускания памяти на 1 ЦП в течение 4 секунд, а затем на всех процессорах в течение еще 4 секунды.
- Другая программа wat.x/wate.exe также начинается в фоновом режиме. Подождите. Он работает на моем ноутбуке с двойной загрузкой Windows 10/Linux Ubuntu. Файл SYSFS может иметь другое имя на вашем Linux и почти наверняка отличается на Android.
- На Linux вы, вероятно, могли бы просто генерировать файл prf_trace.data и prf_trace.txt, используя тот же синтаксис, что и в Run_perf.sh, но я не пробовал это.
- Если вы работаете на ноутбуке и хотите получить питание аккумулятора, не забудьте отключить кабель питания, прежде чем запустить сценарий.
Поддержка данных PCM
- OPPAT может читать и составить диаграмму файлов PCM .CSV.
- Ниже приведен снимок списка созданных диаграмм.
- К сожалению, вам нужно сделать патч в PCM, чтобы создать файл с абсолютной временной меткой для Oppat.
- Это связано с тем, что файл PCM CSV не имеет временной метки, которую я могу использовать для корреляции с другими источниками данных.
- Я добавил патч здесь
Строительство Oppat
- На Linux тип
make в Dir Oppat Root Dir- Если все работает, должен быть файл bin/oppat.x
- В окнах вам нужно:
- Установите версию GNU Windows. См. Http://gnuwin32.sourceforge.net/packages/make.htm или, только для минимальных необходимых двоичных файлов, используйте http://gnuwin32.sourceforge.net/downlinks/make.php
- Поместите этот новый «сделать» бинарной
- Вам нужен текущий компилятор Visual Studio 2015 или 2017 C/C ++ (я использовал как профессиональные компиляторы VS 2015, так и компиляторы VS 2017)
- Запустите Windows Visual Studio x64 Native Cmd Box
- тип
make в режиме Oppat Root - Если все работает, должен быть файл bin oppat.exe
- Если вы меняете исходный код, вам, вероятно, необходимо восстановить файл включения зависимости
- Вам нужно установить Perl
- на Linux, в Oppat Root Dir do:
./mk_depends.sh . Это создаст файл зависимости jepends_lnx.mk. - on Windows, in the OPPAT root dir do:
.mk_depends.bat . This will create a depends_win.mk dependency file.
- If you are going to run the sample run_perf.sh or run_xperf.bat scripts, then you need to build the spin and wait utilities:
- On Linux:
./mk_spin.sh - On Windows:
.mk_spin.bat
Running OPPAT
- Run the data collection steps above
- now you have data files in a dir (if you ran the default run_* scripts:
- on Windows ..oppat_datawinmem_bw4
- on Linux ../oppat_data/lnx/mem_bw4
- You need to add the created files to the input_filesinput_data_files.json file:
- Starting OPPAT reads all the data files and starts the web server
- on Windows to generate the haswell cpu_diagram (assuming your data dir is ..oppat_datalnxmem_bw7)
binoppat.exe -r ..oppat_datalnxmem_bw7 --cpu_diagram webhaswell_block_diagram.svg > tmp.txt
- on Windows (assuming your data dir is ..oppat_datawinmem_bw4)
binoppat.exe -r ..oppat_datawinmem_bw4 > tmp.txt
- on Linux (assuming your data dir is ../oppat_data/lnx/mem_bw4)
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 > tmp.txt
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 --web_file tst2.html > tmp.txt
- Then you can load the file into the browser with the URL address:
file:///C:/some_path/oppat/tst2.html
Derived Events
'Derived events' are new events created from 1 or more events in a data file.
- Say you want to use the ETW Win32k InputDeviceRead events to track when the user is typing or moving the mouse.
- ETW has 2 events:
- Microsoft-Windows-Win32k/InputDeviceRead/win:Start
- Microsoft-Windows-Win32k/InputDeviceRead/win:Stop
- So with the 2 above events we know when the system started reading input and we know when it stopped reading input
- But OPPAT plots just 1 event per chart (usually... the cpu_busy chart is different)
- We need a new event that marks the end of the InputDeviceRead and the duration of the event
- The derived event needs:
- a new event name (in chart.json... see for example the InputDeviceRead event)
- a LUA file and routine in src_lua subdir
- 1 or more 'used events' from which the new event is derived
- the derived events have to be in the same file
- For the InputDeviceRead example, the 2 Win32k InputDeviceRead Start/Stop events above are used.
- The 'used events' are passed to the LUA file/routine (along with the column headers for the 'used events') as the events are encountered in the input trace file
- In the InputDeviceRead lua script:
- the script records the timestamp and process/pid/tid of a 'start' event
- when the script gets a matching 'Stop' event (matching on process/pid/tid), the script computes a duration for the new event and passes it back to OPPAT
- A 'trigger event' is defined in chart.json and if the current event is the 'trigger event' then (after calling the lua script) the new event is emitted with the new data field(s) from the lua script.
- An alternate to the 'trigger event' method is to have the lua script indicate whether or not it is time to write the new event. For instance, the scr_lua/prf_CPI.lua script writes a '1' to a variable named ' EMIT ' to indicate that the new CPI event should be written.
- The new event will have:
- the name (from the chart.json evt_name field)
- The data from the trigger event (except the event name and the new fields (appended)
- I have tested this on ETW data and for perf/trace-cmd data
Using the browser GUI Interface
TBD
Defining events and charts in charts.json
TBD
Rules for input_data_files.json
- The file 'input_files/input_data_files.json' can be used to maintain a big list of all the data directories you have created.
- You can then select the directory by just specifying the file_tag like:
- bin/oppat.x -u lnx_mem_bw4 > tmp.txt # assuming there is a file_tag 'lnx_mem_bw4' in the json file.
- The big json file requires you to copy the part of the data dir's file_list.json into input_data_files.json
- in the file_list.json file you will see lines like:
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- don't copy the lines like below from the file_list.json file:
- paste the copied lines into input_data_files.json. Pay attention to where you paste the lines. If you are pasting the lines at the top of input_data_files.json (after the
{"root_dir":"/data/ppat/"}, then you need add a ',' after the last pasted line or else JSON will complain. - for Windows data files add an entry like below to the input_filesinput_data_files.json file:
- yes, use forward slashes:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- for Linux data files add an entry like below to the input_filesinput_data_files.json file:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/lnx/mem_bw4 " },
{ "cur_tag" : " lnx_mem_bw4 " },
{ "bin_file" : " prf_energy.txt " , "txt_file" : " prf_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " },
{ "bin_file" : " prf_trace.data " , "txt_file" : " prf_trace.txt " , "tag" : " %cur_tag% " , "type" : " PERF " },
{ "bin_file" : " tc_trace.dat " , "txt_file" : " tc_trace.txt " , "tag" : " %cur_tag% " , "type" : " TRACE_CMD " },- Unfortunately you have to pay attention to proper JSON syntax (such as trailing ','s)
- Here is an explanation of the fields:
- The 'root_dir' field only needs to entered once in the json file.
- It can be overridden on the oppat cmd line line with the
-r root_dir_path option - If you use the
-r root_dir_path option it is as if you had set "root_dir":"root_dir_path" in the json file - the 'root_dir' field has to be on a line by itself.
- The cur_dir field applies to all the files after the cur_dir line (until the next cur_dir line)
- the '%root_dir% string in the cur_dir field is replaced with the current value of 'root_dir'.
- the 'cur_dir' field has to be on a line by itself.
- the 'cur_tag' field is a text string used to group the files together. The cur_tag field will be used to replace the 'tag' field on each subsequent line.
- the 'cur_tag' field has to be on a line by itself.
- For now there are four types of data files indicated by the 'type' field:
- type:PERF These are Linux perf files. OPPAT currently requires both the binary data file (the bin_file field) created by the
perf record cmd and the perf script text file (the txt_file field). - type:TRACE_CMD These are Linux trace-cmd files. OPPAT currently requires both the binary dat file (the bin_file field) created by the
trace-cmd record cmd and the trace-cmd report text file (the txt_file field). - type:ETW These are Windows ETW xperf data files. OPPAT currently requires only the text file (I can't read the binary file). The txt_file is created with
xperf ... -a dumper command. - type:LUA These files are all text files which will be read by the src_lua/test_01.lua script and converted to OPPAT data.
- the 'prf_energy.txt' file is
perf stat output with Intel RAPL energy data and memory bandwidth data. - the 'prf_energy2.txt' file is created by the wait utility and contains battery usage data in the 'perf stat' format.
- the 'wait.txt' file is created by the wait utility and shows the timestamp when the wait utility began
- Unfortunately 'perf stat' doesn't report a high resolution timestamp for the 'perf stat' start time
Ограничения
- The data is not reduced on the back-end so every event is sent to the browser... this can be a ton of data and overwhelm the browsers memory
- I probably should have some data reduction logic but I wanted to get feedback first
- You can clip the files to a time range:
oppat.exe -b abs_beg_time -e abs_beg_time to reduce the amout of data- This is a sort of crude mechanism right now. I just check the timestamp of the sample and discard it if the timestamp is outside the interval. If the sample has a duration it might actually have data for the selected interval...
- There are many cases where you want to see each event as opposed to averages of events.
- On my laptop (with 4 CPUs), running for 10 seconds of data collection runs fine.
- Servers with lots of CPUs or running for a long time will probably blow up OPPAT currently.
- The stacked chart can cause lots of data to be sent due to how it each event on one line is now stacked on every other line.
- Limited mechanism for a chart that needs more than 1 event on a chart...
- say for computing CPI (cycles per instruction).
- Or where you have one event that marks the 'start' of some action and another event that marks the 'end' of the action
- There is a 'derived events' logic that lets you create a new event from 1 or more other events
- See the derived event section
- The user has to supply or install the data collection software:
- on Windows xperf
- See https://docs.microsoft.com/en-us/windows-hardware/get-started/adk-install
- You don't need to install the whole ADK... the 'select the parts you want to install' will let you select just the performance tools
- on Linux perf and/or trace-cmd
sudo apt-get install linux-tools-common linux-tools-generic linux-tools- ` uname -r `
- For trace-cmd, see https://github.com/rostedt/trace-cmd
- You can do (AFAIK) everything in 'perf' as you can in 'trace-cmd' but I have found trace-cmd has little overhead... perhaps because trace-cmd only supports tracepoints whereas perf supports tracepoints, sampling, callstacks and more.
- Currently for perf and trace-cmd data, you have to give OPPAT both the binary data file and the post-processed text file.
- Having some of the data come from the binary file speeds things up and is more reliable.
- But I don't want to the symbol handling and I can't really do the post-processing of the binary data. Near as I can tell you have to be part of the kernel to do the post processing.
- OPPAT requires certain clocks and a certain syntax of 'convert to text' for perf and trace-cmd data.
- OPPAT requires clock_monotonic so that different file timestamps can be correlated.
- When converting the binary data to text (trace-cmd report or 'perf script') OPPAT needs the timestamp to be in nanoseconds.
- see scriptsrun_xperf.bat and scriptsrun_perf.sh for the required syntax
- given that there might be so many files to read (for example, run_perf.sh generates 7 input files), it is kind of a pain to add these files to the json file input_filesinput_data_files.json.
- the run_xperf.bat and run_perf.sh generate a file_list.json in the output directory.
- perf has so, so many options... I'm sure it is easy to generate some data which will break OPPAT
- The most obvious way to break OPPAT is to generate too much data (causing browser to run out of memory). I'll probably handle this case better later but for this release (v0.1.0), I just try to not generate too much data.
- For perf I've tested:
- sampling hardware events (like cycles, instructions, ref-cycles) and callstacks for same
- software events (cpu-clock) and callstacks for same
- tracepoints (sched_switch and a bunch of others) with/without callstacks
- Zooming Using touchpad scroll on Firefox seems to not work as well it works on Chrome



