오픈 파워/성능 분석 도구 (OPPAT)
목차
- 소개
- 지원되는 데이터 유형
- OPPAT 시각화
- OPPAT의 데이터 수집
- PCM 데이터 지원
- OPPAT 구축
- OPPAT 실행
- 파생 된 이벤트
- Browswer GUI 인터페이스 사용
- 제한
소개
OPPAT (Open Power/Performance Analysis Tool)는 크로스 OS, 교차 자료 및 성능 분석 도구입니다.
- Cross-OS : Windows ETW 추적 파일 및 Linux/Android Perf/Trace-CMD 추적 파일 지원
- 크로스 아키텍처 : Intel 및 Arm Chips 하드웨어 이벤트를 지원합니다 (Perf 및/또는 PCM 사용)
프로젝트 웹 페이지는 https://patinnc.github.io입니다
소스 코드 리포는 https://github.com/patinnc/oppat입니다
CPU 블록 다이어그램 기능에 운영 체제 (OS_VIEW)를 추가했습니다. 이것은 http://www.brendangregg.com/linuxperf.html과 같은 Brendan Gregg의 페이지를 기반으로합니다. 다음은 ARM 64 비트 Ubuntu Mate V18.04.2 Raspberry Pi 3 B+, 4 Arm Cortex A53 CPU에서 이전 버전의 Geekbench v2.4.2 (32 비트 코드)를 실행하기위한 몇 가지 예입니다.
- Geekbench 실행중인 OS_VIEW 및 ARM A53 CPU 블록 다이어그램 변경에 대한 비디오 :
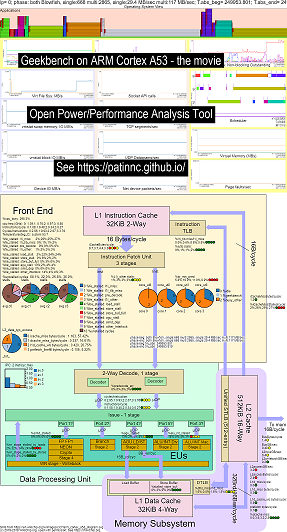
- OS_VIEW 및 CPU_DIAGRAM 레이아웃을 시도하고 설명 할 수있는 소개 슬라이드가 있으며, 1 개의 슬라이드가 30 개의 하위 테스트 각각 당 결과를 보여줍니다.
- 영화에서 데이터의 Excel 파일 : Geekbench The Movie의 Excel 파일
- 영화의 데이터의 HTML ... OS_VIEW, CPU 다이어그램을 사용한 4 코어 암 CORTEXT A53의 GeekBench v2.4.2를 참조하십시오.
- 지침/초를 늘려서 분류 된 30 단계의 대시 보드 PNG ... CPU 다이어그램 4 코어 칩 대시 보드가있는 ARM Cortex A53 Raspberry Pi 3 참조 Geekbench.
다음은 Raspberry Pi 3 B+ (Cortex A53) CPU에서 내 스핀 벤치 마크 (메모리/캐시 대역폭 테스트, A 'Spin'Keep-CPU-Busy Test)를 실행하기위한 몇 가지 예입니다.
- OS_VIEW 및 ARM에 대한 변경 비디오 A53 CPU 블록 다이어그램 실행 스핀 :
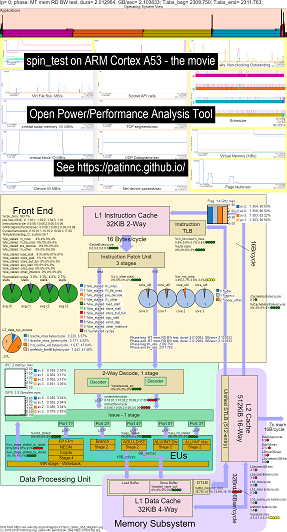
- OS_VIEW 차트와 CPU_DIAGRAM 레이아웃을 설명하고 설명하기위한 소개 슬라이드가 있습니다. 각 하위 테스트가 표시되는 시간 (초)에 표시되는 슬라이드가 표시되고 (따라서 하위 테스트로 직접 이동하여 1 개의 슬라이드에 대해 하나의 슬라이드가 표시됩니다.
- 영화에서 데이터의 Excel 파일 : Geekbench The Movie의 Excel 파일
- 영화의 데이터의 HTML ... CPU 다이어그램 4 코어 칩이 실행되는 스핀 벤치 마크가있는 ARM Cortex A53 Raspberry Pi 3 참조.
- 지침/초를 늘려서 분류 된 5 단계에 대한 대시 보드 PNG ... ARM Cortex A53 Raspberry Pi 3 참조 CPU 다이어그램 4 코어 칩 대시 보드 실행 스핀 벤치 마크.
다음은 Haswell CPU에서 Geekbench를 실행하기위한 몇 가지 예입니다.
- Geekbench 실행중인 OS_VIEW 및 HASWELL CPU 블록 다이어그램 변경에 대한 비디오 :
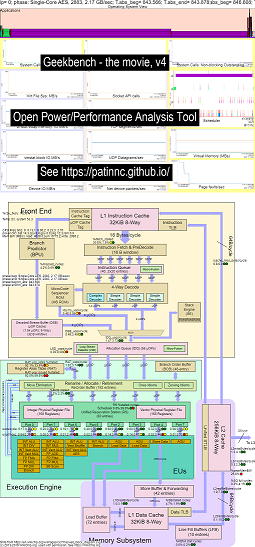
- OS_VIEW 차트와 CPU_DIAGRAM 레이아웃을 설명하고 설명하기위한 소개 슬라이드가 있습니다. 각 하위 테스트가 표시되는 시간 (초)에 표시되는 슬라이드가 표시되고 (따라서 하위 테스트로 직접 이동하여 1 개의 슬라이드에 대해 하나의 슬라이드가 표시됩니다.
- 영화에서 데이터의 Excel 파일 : Geekbench The Movie의 Excel 파일
- 영화의 데이터의 HTML ... Geekbench를 실행하는 CPU 다이어그램 4-CPU 칩이있는 Intel Haswell을 참조하십시오.
- UOPS를 늘려서 분류 한 50 단계의 대시 보드 PNG는 퇴직/초 ... CPU 다이어그램 4 코어 칩 대시 보드를 실행하는 Intel Haswell 대시 보드를 참조하십시오. Geekbench.
다음은 Haswell CPU에서 4 개의 하위 테스트와 함께 '스핀'벤치 마크를 실행하기위한 몇 가지 데이터입니다.
- 첫 번째 하위 테스트는 읽기 메모리 대역폭 테스트입니다. L2/L3/메모리 블록은 테스트 중에 고도로 사용 및 정체됩니다. 쥐가 주로 멈춰서 쥐 UOPS/사이클은 낮습니다.
- 두 번째 하위 테스트는 L3 읽기 대역폭 테스트입니다. 메모리 BW는 이제 낮습니다. L2 & L3 블록은 테스트 중에 고도로 사용 및 정체됩니다. 쥐가 덜 멈추면 쥐 UOPS/사이클이 더 높습니다.
- 세 번째 하위 테스트는 L2 읽기 대역폭 테스트입니다. L3 및 메모리 BW는 이제 낮습니다. L2 블록은 테스트 중에 고도로 사용 및 정체되어 있습니다. 쥐가 덜 멈추기 때문에 쥐 UOPS/사이클은 훨씬 높습니다.
- 네 번째 하위 테스트는 스핀 (ADD 루프) 테스트입니다. L2, L3 및 Memory BW는 거의 0입니다. 쥐 UOPS/사이클은 약 3.3 UOPS/사이클이며 가능한 4 개의 UOPS/사이클 최대에 접근합니다.
- 분석을 통해 '스핀'을 실행하는 Haswell CPU 블록 다이어그램의 변경에 대한 비디오. 보다
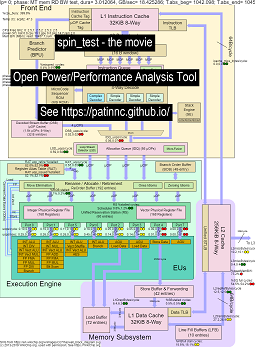
- 영화에서 데이터의 Excel 파일 : 영화에서 Excel 파일
- 영화의 데이터의 HTML ... CPU 다이어그램 4-CPU 칩이있는 Intel Haswell을 참조하십시오.
CPU 다이어그램 데이터 컬렉션이 장착 된 Intel Haswell은 4-CPU Intel Chip, Linux OS, HTML 파일을위한 Perf 샘플링 및 기타 데이터를 통해 50 개 이상의 HW 이벤트가있는 HTML 파일입니다. CPU_DIAGRAM 기능 :
- wikichip.org의 블록 다이어그램 SVG (권한과 함께 사용)로 시작하십시오.
- 리소스 제약 조건 (예 : Max BW, 다양한 경로에서 최대 바이트/사이클, 최소 사이클/UOP 등)을 살펴보십시오.
- 리소스 사용에 대한 메트릭을 계산합니다
- 아래는 메모리 읽기 대역폭 테스트 테이블입니다.이 테이블은 테이블에 리소스 사용 정보를 표시합니다 (사용으로 인해 CPU가 중단되는지 여부에 대한 추정치). HTML 테이블 (PNG는 아님)에는 필드 위로 마우스를 올릴 때 팝업 정보가 있습니다. 표는 다음을 보여줍니다.
- 코어는 메모리 대역폭에서 최대 25.9 GB/S BW의 55%에서 정체됩니다. 메모리 BW 테스트입니다
- Superqueue (SQ)는 사이클의 전체 (Core0의 경우 54.5% 및 62.3% Core1)입니다 (따라서 더 많은 L2 요청을 처리 할 수 없습니다).
- 라인 채우기 버퍼 FB가 가득 찼으므로 (30% 및 51%) 라인은 L2에서 L1D로 이동할 수 없습니다.
- 결과적으로 백엔드가 퇴직되지 않은주기의 백엔드 (88% 및 87%)가 퇴직되지 않습니다.
- UOP는 루프 스트림 검출기에서 나오는 것 같습니다 (LSD 사이클/UOP는 쥐 UOP/사이클과 거의 동일하기 때문입니다.
- Haswell CPU 다이어그램 메모리 BW 테이블의 스크린 샷
- 아래는 L3 읽기 대역폭 테스트 테이블입니다.
- 이제 메모리 BW와 L3 미스 바이트/사이클은 약 0입니다.
- SQ는 덜 정체되어 있습니다 (메모리를 기다리지 않기 때문에).
- L2 트랜잭션 바이트/사이클은 약 2 배 높고 최대 64 바이트/사이클의 약 67%입니다.
- uops_retired_stalls/cycle은 88%의 MEM BW 테스트 스톨에서 66%로 떨어졌습니다.
- 충전 버퍼 스톨이 이제 2 배 이상 높습니다. UOP는 여전히 LSD에서 나옵니다.
- Haswell CPU 다이어그램 L3 BW 테이블의 스크린 샷
- 아래는 L2 읽기 대역폭 테스트 테이블입니다.
- L2 미스 바이트/사이클은 L3 테스트보다 훨씬 낮습니다.
- uops_retired% 정지는 이제 34%에서 L3 테스트의 약 절반이며 FB 스톨도 약 17%입니다.
- UOP는 여전히 LSD에서 나옵니다.
- Haswell CPU 다이어그램 L2 BW 테이블의 스크린 샷
- 아래는 스핀 테스트 테이블입니다 (하중이없고 루프를 추가합니다).
- 이제 메모리 서브 시스템 스톨이 거의 없습니다.
- UOP는 DECODE 스트림 버퍼 (DSB)에서 나옵니다.
- 3.31 사이클/UOP에서 Rat Retired_uops/Cycle은 최대 4.0 UOPS/사이클에 가깝습니다.
- Ratired_uops %정지 된 쥐는 %8에서 상당히 낮습니다.
- Haswell CPU 다이어그램 스핀 테이블의 스크린 샷
현재 Haswell 및 Arm A53 용 CPU_Diagram 영화 만 가지고 있지만 (다른 시스템이 테스트 할 다른 시스템이 없기 때문에) 다른 블록 다이어그램을 추가하는 것은 어렵지 않아야합니다. CPU_DIAGRAM은 여전히 모든 차트를 얻지 못합니다.
아래는 OPPAT 차트 중 하나입니다. 'CPU_BUSY'차트는 각 CPU에서 실행되는 내용과 각 CPU에서 발생하는 이벤트를 보여줍니다. 예를 들어, 녹색 원은 CPU 1에서 실행되는 Spin.x 스레드를 보여줍니다. 빨간색 원은 CPU1에서 발생하는 일부 이벤트를 보여줍니다. 이 차트는 Trace-CMD의 Kernelshark 차트 이후에 모델링됩니다. CPU_BUSY 차트에 대한 자세한 정보는 차트 유형 섹션에 있습니다. 콜 아웃 박스는 커서 아래의 이벤트에 대한 이벤트 데이터 (Callstack 포함 (있는 경우)을 보여줍니다. 불행히도 Windows Screenshot은 커서를 캡처하지 않습니다. 
다음은 샘플 HTML 파일입니다. 대부분의 파일은 짧은 ~ 2 간격이지만 일부는 'Full'8 초 실행입니다. 파일은 repo에서 직접로드되지 않지만 프로젝트 웹 페이지에서로드됩니다 : https://patinnc.github.io
- CPU 다이어그램 4-CPU 칩, Linux OS, HTML 파일이 포함 된 Intel HASWELL 50 개 이상의 HW 이벤트가있는 HTML 파일
- Intel 4-CPU 칩, Windows OS, Xperf 샘플링을 통해 1 HW 이벤트가있는 HTML 파일 또는
- 전체 ~ 8 초 인텔 4-CPU 칩, Windows OS, PCM 및 XPERF 샘플링이있는 HTML 파일 또는
- 인텔 4-CPU 칩, Linux OS, 2 개의 다중화 된 그룹에서 10 개의 HW 이벤트가있는 HTML 파일.
- ARM (Broadcom A53) Chip, 14 개의 HW 이벤트가있는 Raspberry Pi3 Linux HTML 파일 (CPI, L2 Misses, Mem BW 등 2 개의 다중 그룹).
- 11 MB, 위의 ARM (Broadcom A53) 칩의 정식 버전, 14 개의 HW 이벤트가있는 Raspberry PI3 Linux HTML 파일 (CPI, L2 Misses, MEM BW 등 2 개의 다중 그룹).
위의 파일 중 일부는 ~ 8 초 장기 실행에서 추출 된 ~ 2 초 간격입니다. 다음은 전체 8 초 실행입니다.
- 보다 완전한 파일을 위해 전체 8 초 Linux 실행 샘플 HTML 압축 파일. 이 파일은 차트 데이터의 javaScript Zlib 압축 압력을 수행하므로 압축 압력 중에 대기하도록 요청하는 메시지가 표시됩니다 (약 20 초).
OPPAT 데이터가 지원됩니다
- Linux Perf 및/또는 Trace-CMD 성능 파일 (바이너리 및 텍스트 파일),
- Perf STAT 출력도 허용됩니다
- 인텔 PCM 데이터,
- 기타 데이터 (LUA 스크립트를 사용하여 가져온),
- 따라서 이것은 일반 Linux 또는 Android의 데이터와 함께 작동해야합니다.
- 현재 Perf 및 Trace-CMD 데이터를 위해 OPPAT에는 이진 및 후 처리 된 텍스트 파일이 모두 필요하며 '레코드'명령 줄과 'Perf Script/Trace-CMD Report'명령 줄에 몇 가지 제한이 있습니다.
- OPPAT는 Perf/Trace-CMD 텍스트 출력 파일 만 사용하도록 만들 수 있지만 현재 바이너리 및 텍스트 파일이 모두 필요합니다.
- Windows ETW 데이터 (Xperf에 의해 수집되어 텍스트에 덤프) 또는 인텔 PCM 데이터,
- LUA 스크립트를 사용하여 지원되는 임의의 전력 또는 성능 데이터 (따라서 다른 데이터를 가져 오기 위해 C ++ 코드를 다시 컴파일 할 필요가 없습니다 (LUA 성능이 문제가되지 않는 한).
- 파일이 시작된 위치에 관계없이 Linux 또는 Windows의 데이터 파일을 읽으십시오 (따라서 Windows에서 Perf/Trace-CMD 파일 또는 Linux의 ETW 텍스트 파일을 읽으십시오).
OPPAT 시각화
다음은 몇 가지 전체 샘플 visualzation html 파일입니다. Windows 샘플 HTML 파일 또는이 Linux 샘플 HTML 파일. repo에있는 경우 (Github.io Project 웹 사이트가 아님) 파일을 다운로드 한 다음 브라우저에로드해야합니다. 이들은 OPPAT에서 만든 독립형 웹 파일로, 예를 들어 다른 사람에게 이메일을 보내거나 웹 서버에 게시 될 수 있습니다.
TouchPad 2 핑거 스크롤링을 사용하는 줌은 Chrome에서 더 잘 작동하기 때문에 Oppat viz는 주로 Firefox보다 크롬에서 더 잘 작동합니다.
OPPAT에는 3 가지 시각화 모드가 있습니다.
- 일반적인 차트 메커니즘 (OPPAT 백엔드가 데이터 파일을 읽고 브라우저로 데이터를 보냅니다)
- 또한 '일반 차트 메커니즘'과 동일하지만 다른 사용자와 교환 할 수있는 독립형 웹 페이지를 만들 수 있습니다. 독립형 웹 페이지에는 모든 스크립트와 데이터가 내장되어있어 누군가에게 이메일을 보내고 브라우저에로드 할 수 있습니다. 위에서 참조 된 Sample_HTML_FILES에서 HTML 파일을 참조하십시오 (LNX_MEM_BW4의 더 긴 버전의 경우 압축 파일 샘플 _html_files/lnx_mem_bw4_full.html 참조
- 데이터 json 파일을 '-사시'하고 나중에 파일을로드 할 수 있습니다. 저장된 JSON 파일은 OPPAT가 브라우저로 보내야하는 데이터입니다. 이렇게하면 입력 perf/xperf 파일을 다시 읽지 않지만 Charts.json에서 변경된 변경 사항을 선택하지 않습니다. -web_file 옵션으로 생성 된 전체 HTML 파일은 -save 파일보다 약간 큽니다. -save/-로드 모드에는 OPPAT를 구축해야합니다. sample_data_json_files subdir의 샘플 '저장된'파일을 참조하십시오.
viz 일반 정보
- 브라우저의 모든 데이터를 차트 (Linux 또는 Windows)
- 차트는 JSON 파일로 정의되어 OPPAT를 다시 컴파일하지 않고 이벤트 및 차트를 추가 할 수 있습니다.
- 브라우저 인터페이스는 일종의 Windows WPA (왼쪽의 Navbar)입니다.
- 아래는 왼쪽 Navbar (왼쪽 슬라이딩 메뉴)를 보여줍니다.
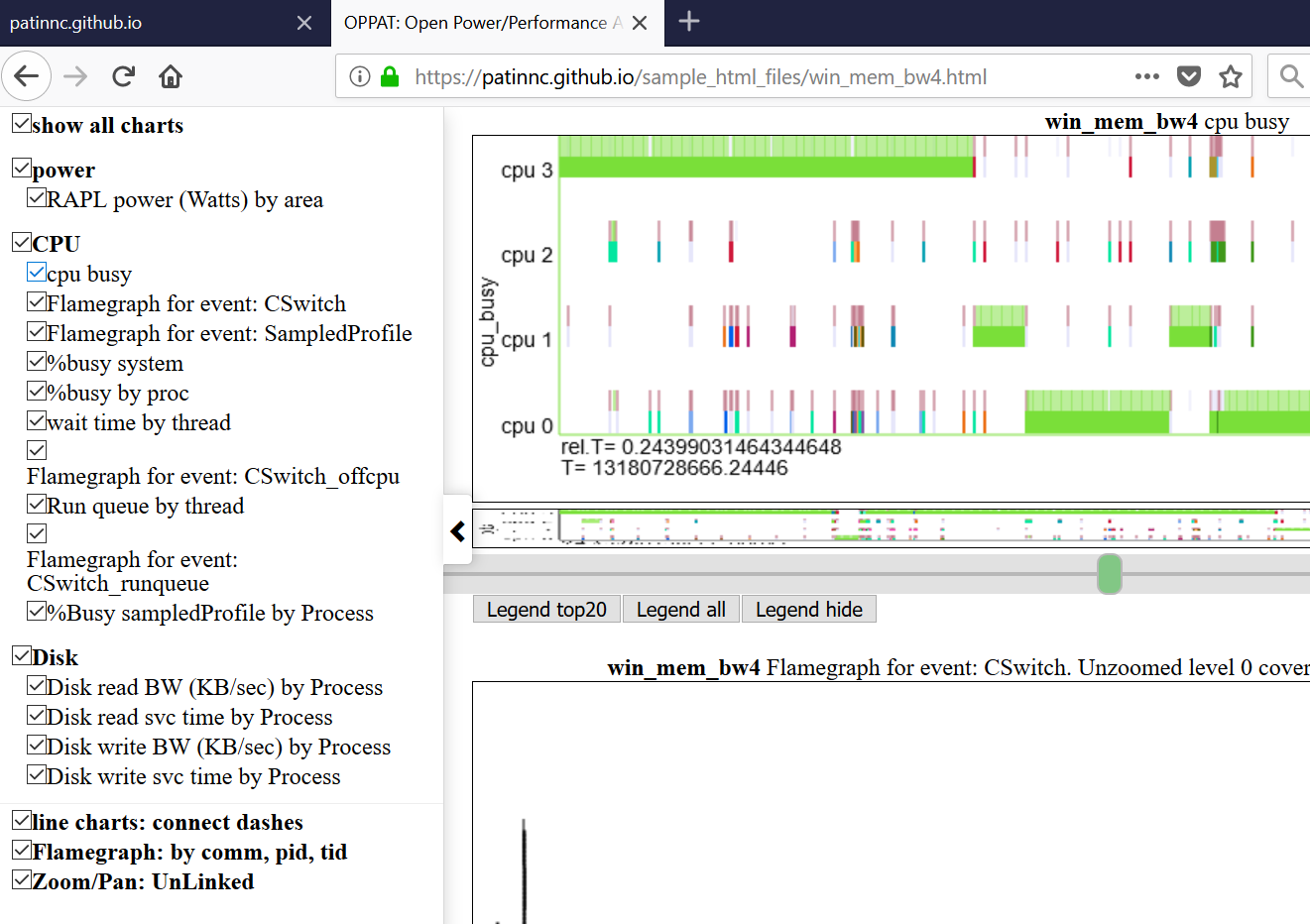
- 차트는 카테고리 (GPU, CPU, 전력 등)별로 그룹화됩니다.
- 카테고리는 input_files/Charts.json에 정의되고 할당됩니다
- 차트는 Navbar의 차트를 클릭하여 모두 숨겨 지거나 선택적으로 표시 될 수 있습니다.
- 왼쪽 NAV 메뉴에서 차트 제목 위에 호버링하여 차트가 보이는 스크롤
- 한 그룹의 파일 그룹의 데이터는 다른 그룹과 함께 표시 될 수 있습니다.
- 그래서 당신은 말할 수 있습니다. Linux Perf 성능과 Windows ETW 실행을 비교하십시오.
- 아래 차트 표시 Linux vs Windows 전원 사용 :
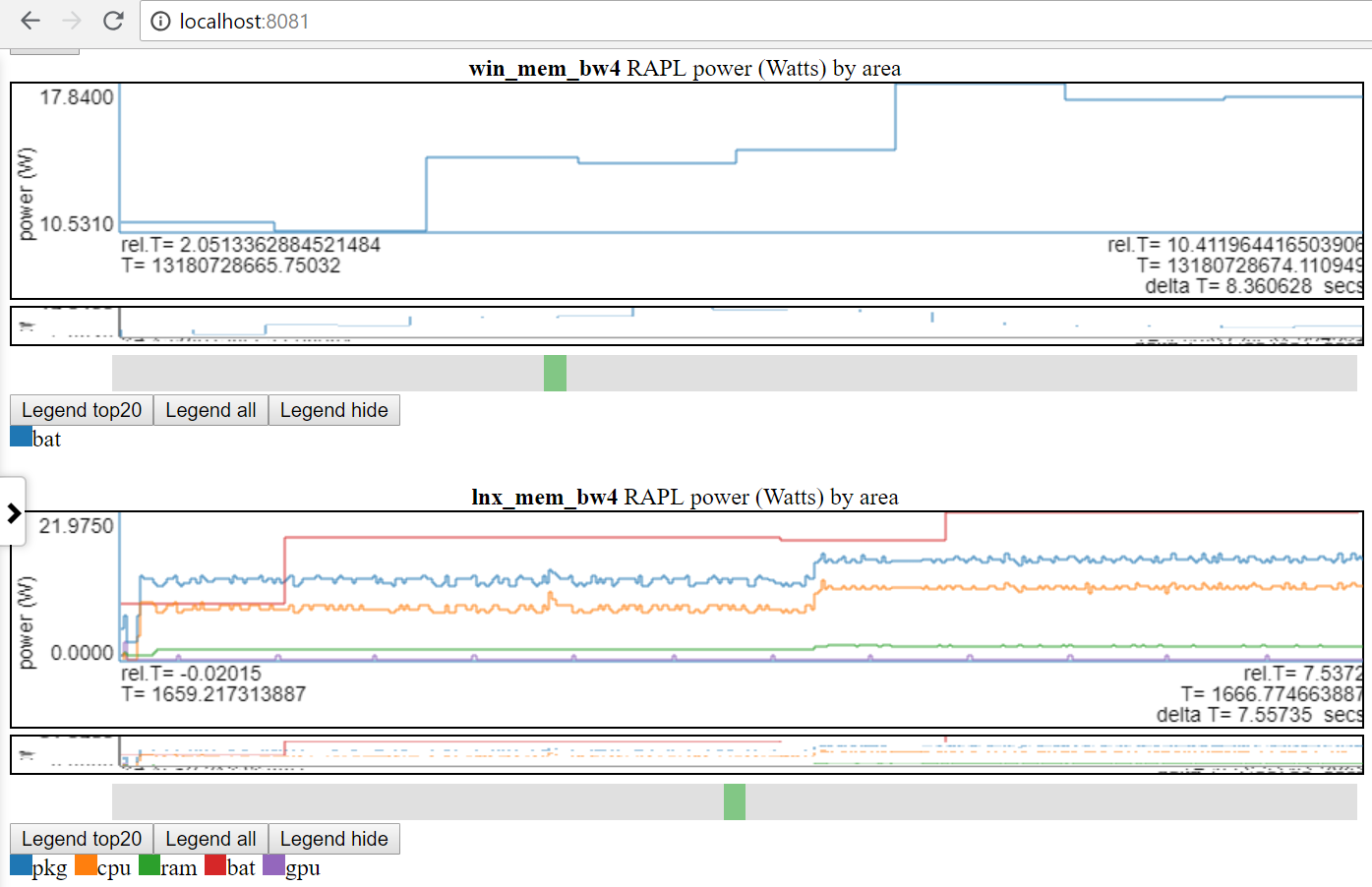
- Linux와 Windows의 배터리 전원에만 액세스 할 수 있습니다.
- 많은 사이트에서 훨씬 더 나은 전력 데이터 (MSEC (또는 더 나은) 속도의 전압/전류/전력)가 있습니다. 이러한 유형의 전력 데이터 (예 : Kratos 또는 Qualcomm MDP)를 쉽게 통합 할 수 있지만 데이터에 액세스 할 수 없습니다.
- 또는 동일한 플랫폼에서 2 개의 다른 실행을 비교하십시오
- 파일 그룹 태그 (file_tag)가 차트를 구별하기 위해 제목에 접두사로 표시됩니다.
- '태그'는 데이터 dir의 file_list.json 파일 및/또는 input_files/input_data_files.json에 정의됩니다.
- input_files/input_data_files.json은 모든 OPPAT 데이터 듀스의 목록입니다 (그러나 사용자는 유지해야합니다).
- 동일한 제목을 가진 차트는 쉽게 비교할 수 있도록 다른 사람 이후에 표시됩니다.
차트 기능 :
차트 라인의 섹션 위에 호버링하면 해당 지점에서 해당 라인의 데이터 포인트가 표시됩니다.
- 이것은 2 점을 연결하기 때문에 수직선에 대해서는 작동하지 않습니다 ... 각 라인의 수평 조각 만 데이터 값을 검색합니다.
- 아래는 호버링 오버 이벤트의 스크린 샷입니다. 이것은 (CSWTICH) 이벤트의 상대 시간, 프로세스/PID/TID와 같은 일부 정보 및 텍스트 파일의 줄 번호를 보여 주므로 더 많은 정보를 얻을 수 있습니다.

- 아래는 이벤트에 대한 CallStack 정보 (있는 경우)를 보여주는 스크린 샷입니다.

축소
- 무제한 확대 / 나노 세 레벨로 확대되고 축소됩니다.
- 픽셀보다 플로팅하는 데 더 많은 포인트가있을 수 있으므로 확대 할 때 더 많은 데이터가 표시됩니다.
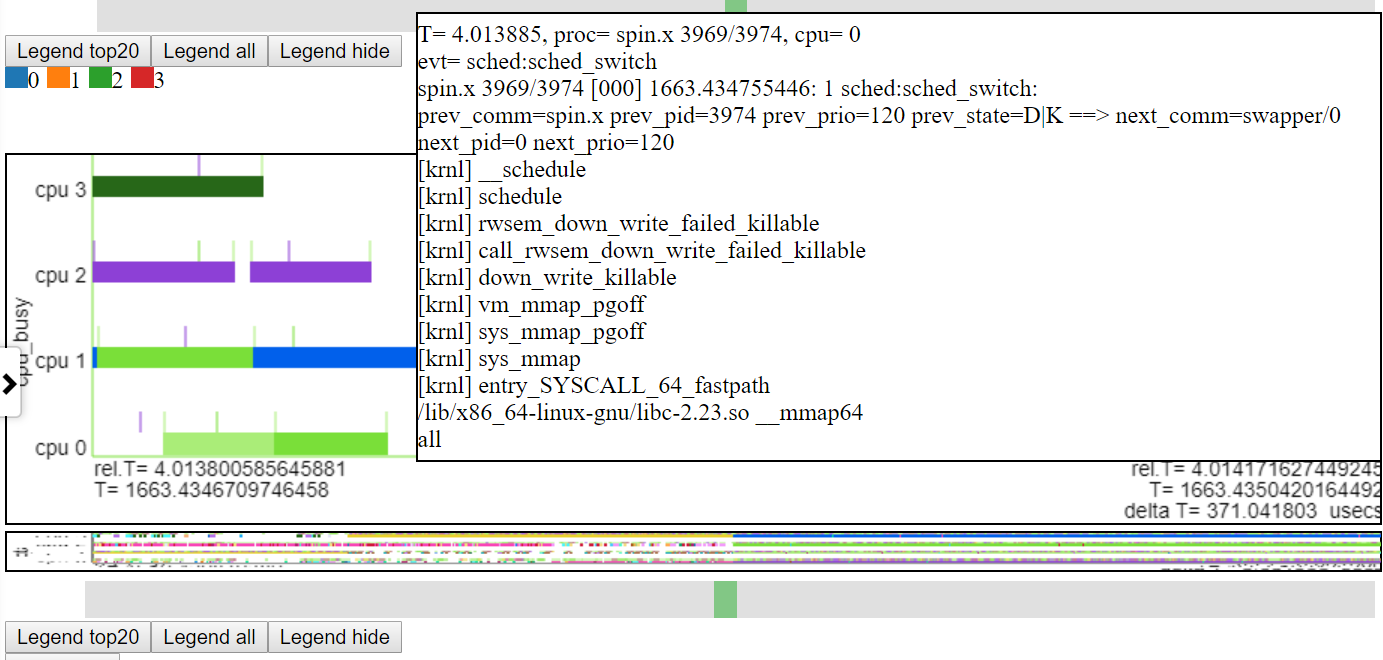
- 아래는 마이크로 초 수준으로 축소하는 스크린 샷입니다. 메모리 매핑 작업을 수행하고 유휴 상태로 진행하여 Spin.x가 차단되는 Sched_Switch 이벤트의 CallStack을 보여줍니다. 'CPU Busy'차트는 '유휴 상태'가 공백으로 표시됩니다.
 .
.
- 차트는 개별적으로 확대되거나 동일한 file_tag를 사용하여 차트를 연결하여 확대/패닝 1 차트가 동일한 file_tag로 모든 차트의 간격을 변경하도록 연결할 수 있습니다.
- 왼쪽 Navbar의 하단으로 스크롤하여 'Zoom/Pan : Unlinked'를 클릭하십시오. 메뉴 항목을 'Zoom/Pan : Linked'로 변경합니다. 이렇게하면 파일 그룹의 모든 차트를 가장 최근의 줌/팬 절대 시간으로 확대/축소합니다. 모든 차트를 다시 그리는 데 시간이 걸립니다.
- 처음에 각 차트는 사용 가능한 모든 데이터를 표시하여 그려집니다. 차트가 다른 소스에서 나온 경우 t_begin 및 t_end (다른 소스의 차트 용)는 아마도 다를 수 있습니다.
- 줌/팬 작동이 모두 완료되고 연결이 적용되면 파일 그룹의 모든 차트가 동일한 절대 간격으로 축소/팬이됩니다.
- 이것이 각 소스에 사용 된 '시계'가 동일 해야하는 이유입니다.
- OPPAT는 한 시계에서 다른 시계로 번역 할 수 있습니다 (예 : gettime (clock_monotonic)과 gettimeofday ()).
- 간격에 대한 FlameGraph는 링크 상태에 관계없이 항상 '소유 차트'간격으로 확대됩니다.
- 다음과 같이 확대/축소 할 수 있습니다.
- 축소 : 차트 영역에서 마우스 휠. 차트는 차트 중앙에서 시간을 확대합니다.
- 내 노트북에서 이것은 터치 패드에서 수직으로 2 개의 손가락 스크롤을하고 있습니다.
- 축소 : 차트를 클릭하고 마우스를 오른쪽으로 드래그하고 마우스를 공개합니다 (차트는 선택한 간격으로 확대됩니다)
- 축소 : 차트를 클릭하고 마우스를 왼쪽으로 드래그하고 마우스를 공개하면 선택한 차트의 양에 반비례 적으로 확대됩니다. 즉, 거의 전체 차트 영역을 드래그하면 차트가 ~ 2x를 축소합니다. 방금 작은 간격을 드래그하면 차트가 ~ 전체 방식을 확대합니다.
- 축소 : 내 노트북에서 터치 패드 2 손가락 수직 스크롤 반대 방향으로 줌의 반대 방향
- 커서의 위치를 조심해야합니다 ... 차트 목록을 스크롤하려는 경우 부주의하게 차트를 확대 할 수 있습니다. 그래서 차트를 스크롤하려면 보통 화면의 왼쪽 가장자리에 커서를 넣습니다.
패닝
- 내 노트북에서 이것은 터치 패드에서 수평 스크롤 동작에서 2 개의 손가락을 수행하고 있습니다.
- 차트 아래의 축소판에서 녹색 상자 사용
- 패닝은 줌 수준에서 작동합니다
- 전체 차트의 '썸네일'사진은 썸네일을 따라 밀어서 커서를 따라 미끄러지므로 각 차트 아래에 배치되므로 확대/파닝/패닝 할 때 차트 주위를 탐색 할 수 있습니다.
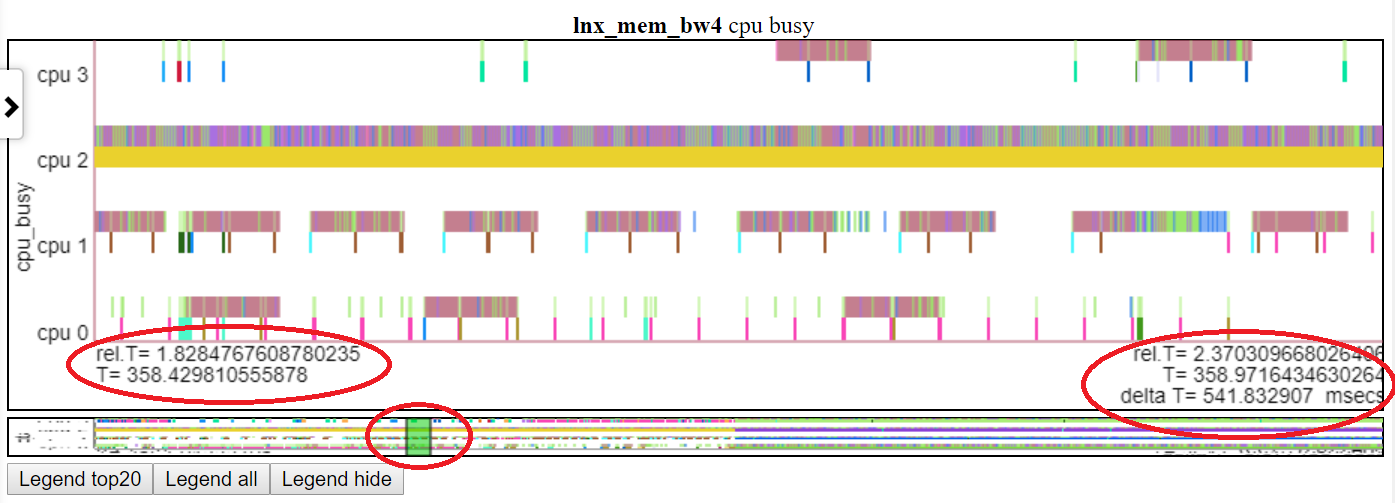
- 아래는 'CPU Busy'차트를 t = 1.8-2.37 초로 패닝합니다. 상대 시간과 절대 시작 시간은 왼쪽 빨간 타원형에서 높이 고정됩니다. 종료 시간은 오른쪽 빨간 타원형에서 강조됩니다. 썸네일의 상대 위치는 중간 빨간 타원형으로 표시됩니다.
 .
.
차트 범례 항목에 호버링하면 해당 라인이 강조됩니다.
- 아래는 'PKG'(패키지) 전원이 강조 표시되는 스크린 샷입니다.
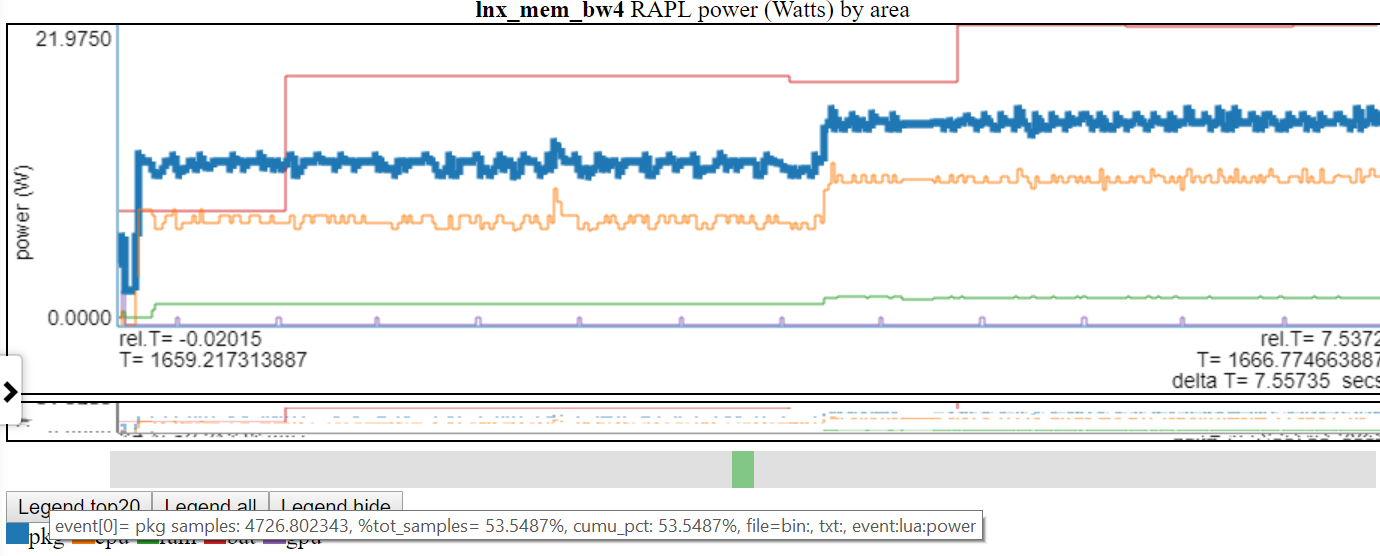
차트 범례 항목을 클릭하면 해당 라인의 가시성이 전환됩니다.
전설 항목을 두 배로 클릭하면 그 항목 만 가시적/숨겨져 있습니다.
- 아래는 'PKG'파워가 두 번 클릭 한 스크린 샷이므로 PKG 라인 만 볼 수 있습니다.
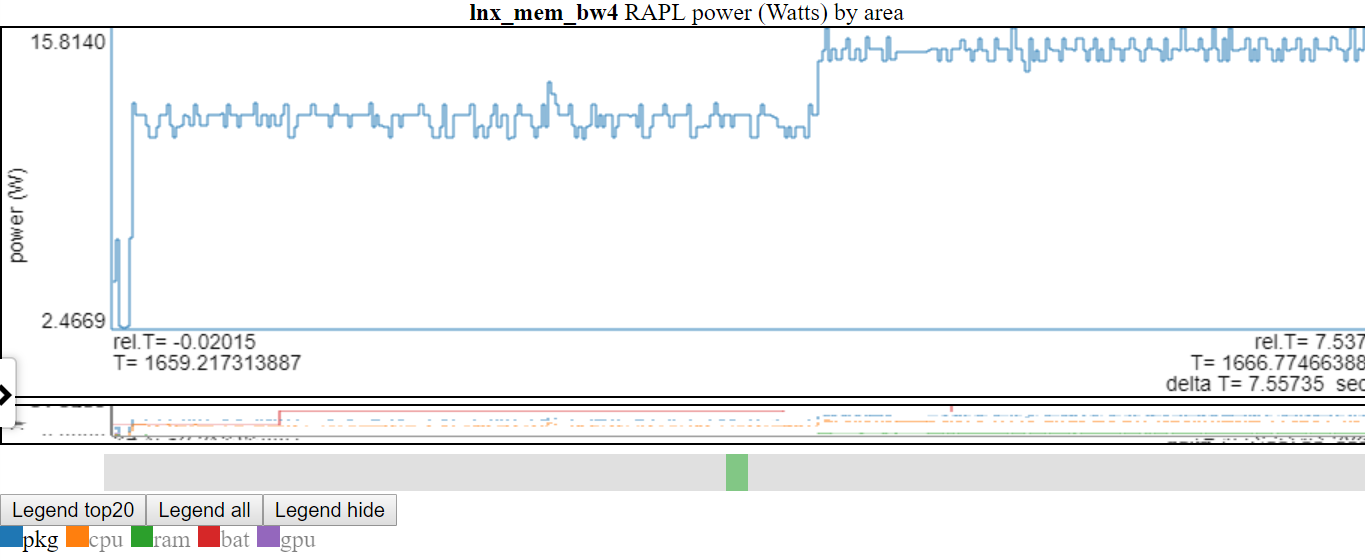
- 위의 Y 축은 표시된 변수의 최소/최대로 조정된다는 것을 보여줍니다. '표시되지 않은'라인은 전설에서 회색입니다. 범례에서 '표시되지 않음'라인 위로 마우스를 가져 가면 전설 항목에 호버링하는 동안). 'Not-Shown'범례 항목을 두 번 클릭하여 모든 항목을 다시 표시 할 수 있습니다. 이렇게하면 모든 '표시되지 않은'라인이 표시되지만 방금 클릭 한 줄을 전환합니다. 방금 두 번 클릭 한 항목을 한 번 클릭하십시오. 나는 그것이 혼란스러워 보인다는 것을 안다.
전설 항목이 숨겨져 있고 당신이 그것을 가리면, 당신이 떠날 때까지 표시됩니다.
차트 유형 :
'CPU Busy'차트 : PID/Thread에 의한 CPU 점유를 보여주는 커널 샤크와 같은 차트. Kernelshark 참조 http://rostedt.homelinux.com/kernelshark/를 참조하십시오.
- 아래는 CPU 바쁜 차트의 스크린 샷입니다. 차트는 각 CPU에 대해 언제든지 실행되는 프로세스/PID/TID를 보여줍니다. 유휴 과정은 그려지지 않습니다. 스크린 샷의 'CPU 1'의 경우 녹색 타원형은 차트의 '컨텍스트 스위치'부분 주변에 있습니다. 각 CPU의 컨텍스트 스위치 정보 위에 CPU Busy는 컨텍스트 스위치 이벤트와 동일한 파일로 표시되는 이벤트를 보여줍니다. CPU 1 라인의 빨간 타원형은 차트의 이벤트 부분을 보여줍니다.
- 차트는 컨텍스트 스위치 이벤트를 기반으로하며 주어진 시간에 각 CPU에서 실행되는 스레드를 보여줍니다.
- Context Switch 이벤트는 Linux Scheds : Sched_Switch 또는 Windows ETW CSWITH 이벤트입니다.
- 데이터 파일의 컨텍스트 스위치보다 더 많은 이벤트가있는 경우 다른 모든 이벤트는 CPU 위의 수직 대시로 표시됩니다.
- 이벤트에 통화 스택이있는 경우 팝업 풍선에도 콜 스택도 표시됩니다.
라인 차트
- 라인 차트는 각 이벤트 (지금까지)가 기간이 있고 이러한 '기구'는 수평 세그먼트로 표시되며 수직 세그먼트로 연결되기 때문에 더 정확하게 단계 차트라고 불릴 것입니다.
- 차트 라인이 많은 변형이있는 경우 단계 차트의 수직 부분이 차트를 채울 수 있습니다.
- 각 줄의 수평 세그먼트를 연결하지 않도록 왼쪽 NAV 막대에서 선택할 수 있습니다. 따라서 차트는 일종의 '산란 대시'차트가됩니다. '수평 대시'는 실제 데이터 포인트입니다. 단계 차트에서 대시 차트로 전환하면 'Zoom/Pan 또는 하이라이트 (범례 항목 위에 호버링하여)' 'Redraw'요청이있을 때까지 차트가 다시 그려지지 않습니다.
- 아래는 라인 차트를 사용하는 CPU_IDLE 전원 상태의 스크린 샷입니다. 연결 라인은 차트의 정보를 알 수 있습니다.
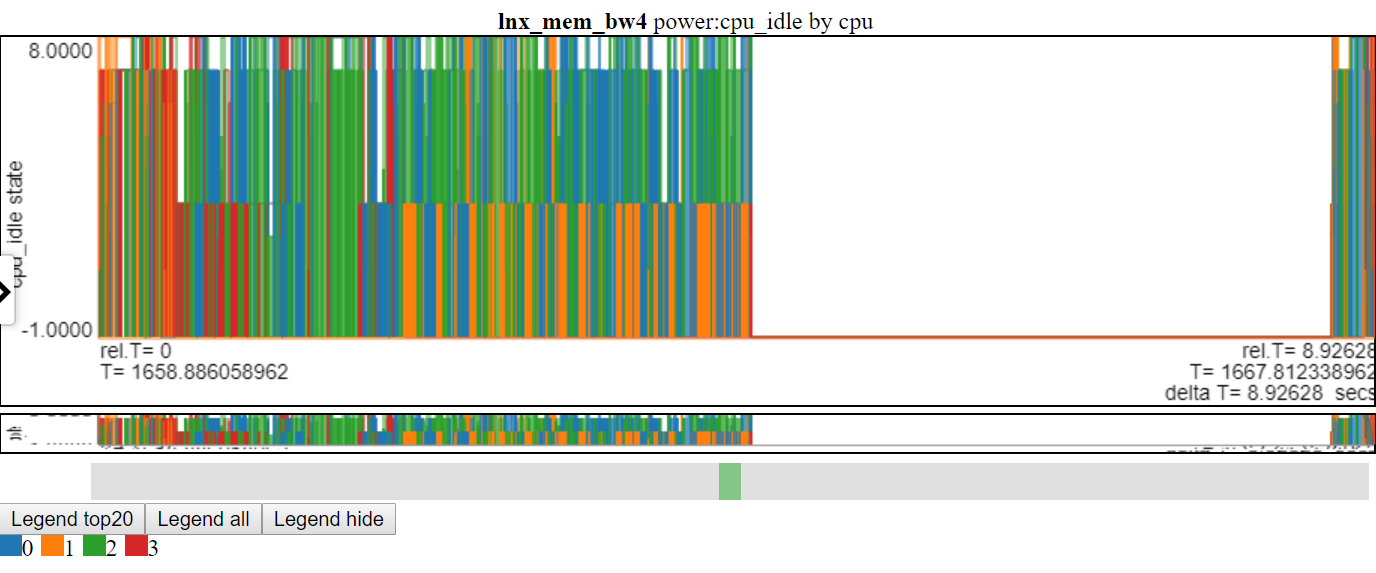
- 아래는 산란 된 대시 차트를 사용하는 CPU_IDLE POWER 상태의 스크린 샷입니다. 차트는 이제 데이터 포인트의 수평 대시를 보여줍니다 (대시의 너비는 이벤트의 지속 시간). 이제 우리는 더 많은 정보를 볼 수 있지만이 차트는 차트 로그로 인한 단점을 보여줍니다. 많은 데이터가 최대 값이며 차트의 최소 값에 있으며 가려집니다.
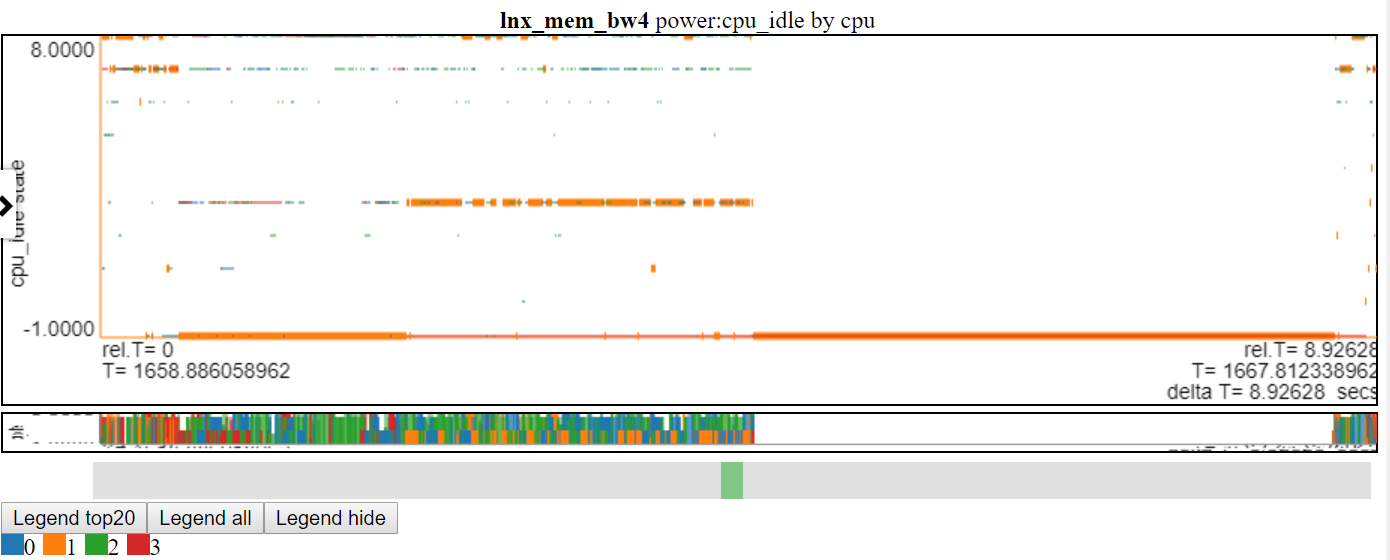
쌓인 차트
- 스택 차트는 라인 차트보다 더 많은 데이터를 생성 할 수 있습니다. 예를 들어, 특정 스레드가 실행중인 경우 라인 차트를 그리는 것은 해당 스레드에만 의존합니다. 실행 스레드에 대한 스택 차트 그리기는 다릅니다. 스레드의 컨텍스트 스위치 이벤트는 다른 실행 스레드를 모두 변경합니다. 따라서 N CPU가 있으면 스택 차트에 대해 이벤트 당 N-1 더 많이 얻을 수 있습니다.
화염 그래프. CallStack이 있고 Sched_Switch/Cswitch 이벤트와 동일한 파일에있는 각 Perf 이벤트에 대해 FlameGraph가 생성됩니다.
- 아래는 일반적인 기본 불꽃의 스크린 샷입니다. 일반적으로 Flamegraph 차트의 기본 높이는 Flamegraph의 각 레벨에 텍스트를 맞추기에 충분하지 않습니다. 그러나 여전히 '호버'콜 스택 정보를 얻습니다.
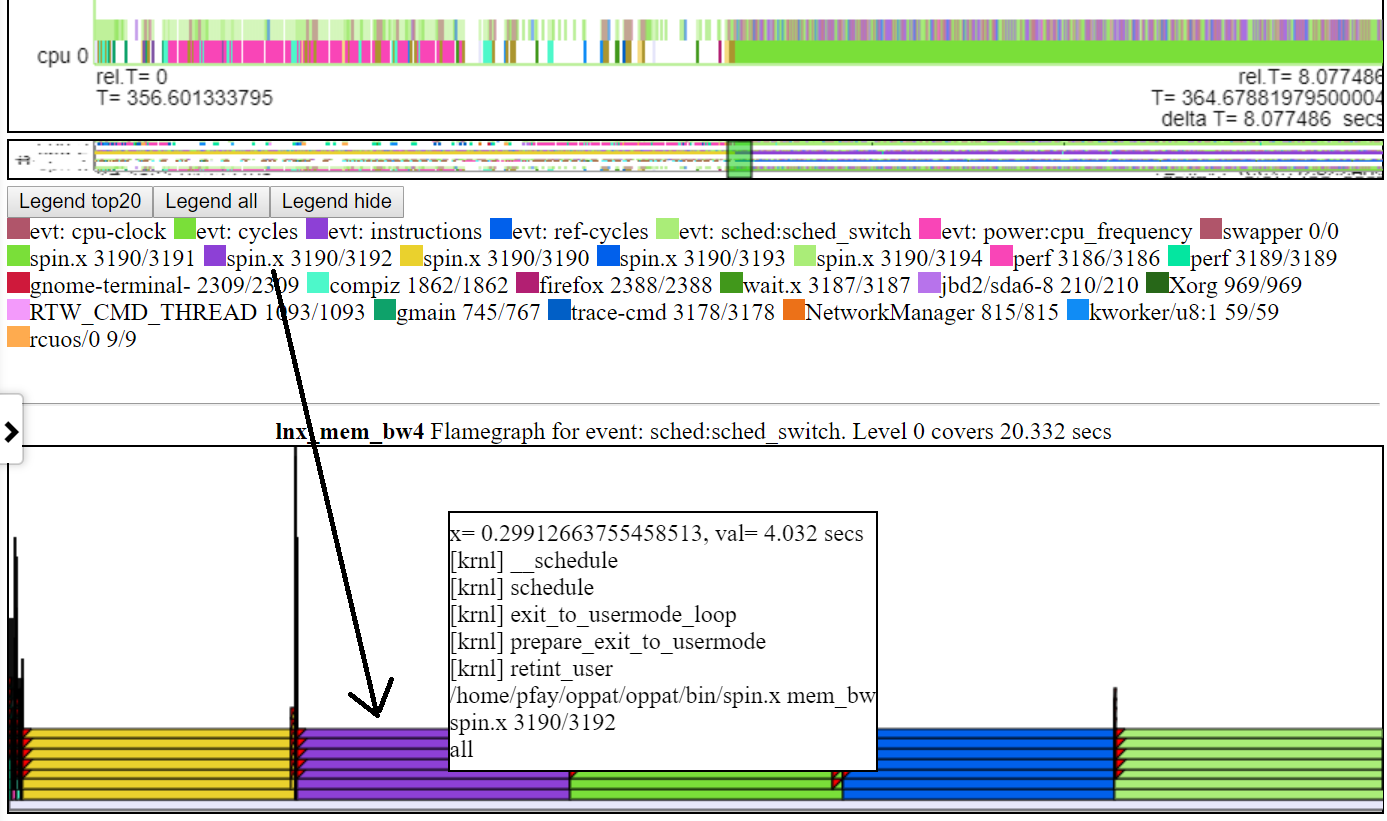 .
.- 차트의 레이어를 클릭하면 텍스트가 맞도록 더 높아집니다. 가장 낮은 계층을 클릭하면 '소유 차트'간격에 대한 모든 데이터를 다룹니다.
- 아래는 확대 된 불꽃의 스크린 샷입니다 (화염의 레이어 중 하나를 클릭 한 후).
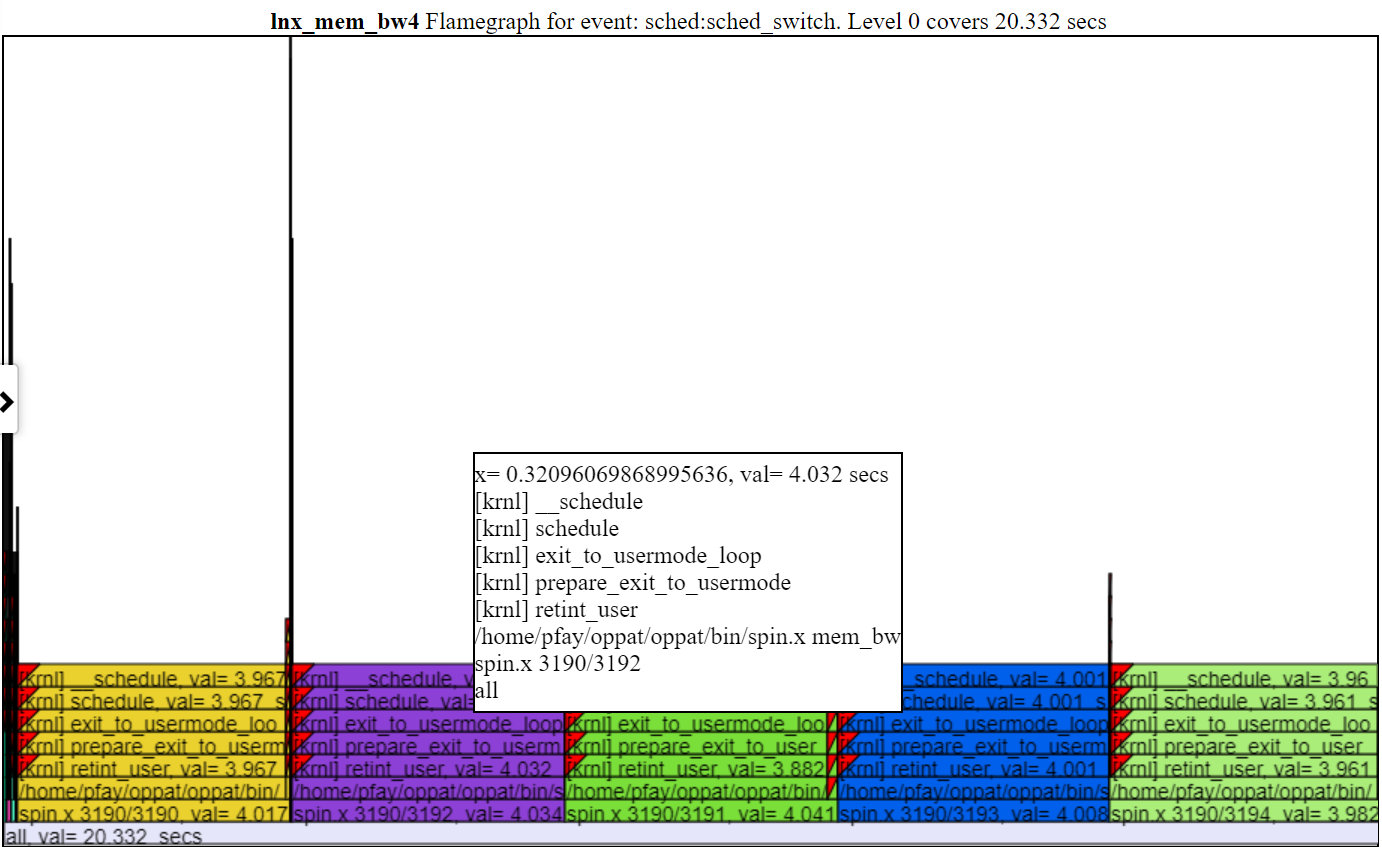 .
.- 일반적으로 Flamegraph 차트의 기본 높이는 Flamegraph의 각 레벨에 텍스트를 맞추기에 충분하지 않습니다. 그러나 여전히 '호버'콜 스택 정보를 얻습니다.
- 불꽃의 색상은 CPU_BUSY 차트의 전설에서 프로세스/PID/TID와 일치합니다.
- CPI (명령 당 시계) FlameGraph 차트는 해당 스택의 CPI의 프로세스/PID/TID를 색상합니다.
- 아래는 샘플 zoomed CPI 차트입니다. Spin.x (연한 주황색)의 왼쪽 인스턴스에는 CPI = 2.26 사이클/지침이 있습니다. 가벼운 녹색의 오른쪽에있는 4 개의 spin.x는 CPI = 6.465입니다.
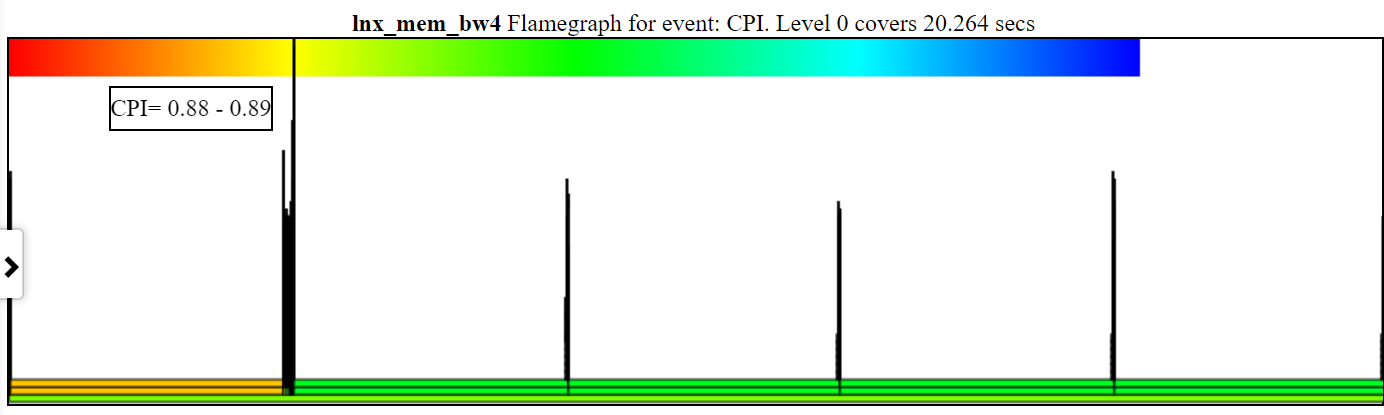
- 주기, 지침 및 CPU-Clock (또는 Sched_Switch) Callstacks가 있어야합니다.
- CPI '불꽃'의 너비는 CPU 클록 시간을 기준으로합니다.
- 색상은 CPI를 기반으로합니다. 차트의 왼쪽 상단에 빨간색에서 녹색에서 파란색 구배가 채색을 보여줍니다.
- 빨간색은 낮은 CPI입니다 (시계 당 많은 지침이 있습니다 ... 나는 그것을 '뜨거운'것으로 생각합니다)
- Blue는 높은 CPI입니다 (시계 당 지침은 거의 없습니다 ... 나는 그것을 'Cold'라고 생각합니다)
- 아래는 채색과 CPI를 보여주는 샘플 확대 CPI 차트입니다. 'spin.x'스레드는 CPU_BUSY 전설에서 선택 해제되었으므로 FlameGraph에는 나타나지 않습니다.
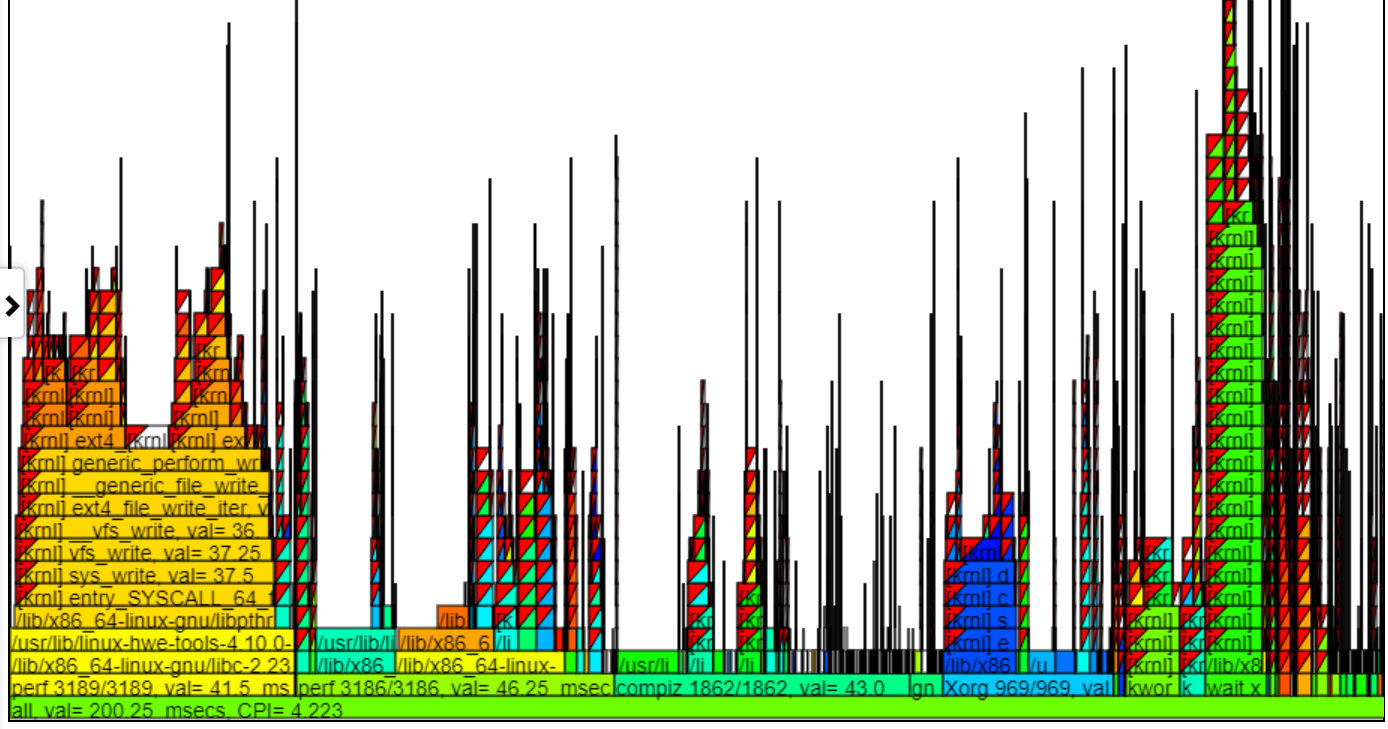
- GIPS (Giga (10 억) 초당 지침) FlameGraph 차트는 해당 스택의 GIPS의 프로세스/PID/TID를 색칠합니다.
- 아래는 샘플 zoomed GIP (초당 Giga/Billion 지침) 차트입니다. Spin.x (연한 녹색)의 왼쪽 인스턴스에는 GIPS = 1.13이 있습니다. 푸른 녹색의 오른쪽에있는 4 개의 spin.x는 gips = 0.377입니다. 풍선의 콜 스택은 풍선의 왼쪽에있는 스파이크 콜 스택을위한 것입니다.

- 위의 차트에서 왼손 스택 (Spin.x의 경우)은 Spin.x의 가장 오른쪽 4 인스턴스보다 높은 지침/Sec를 얻습니다. 이 첫 번째 Spin.x 인스턴스는 자체적으로 실행됩니다 (따라서 많은 메모리 BW를 얻습니다)과 오른쪽 4 Spin.x 스레드는 병렬로 실행되며 더 낮은 GIP를 얻습니다 (한 스레드가 메모리 BW를 최대 할 수 있기 때문에).
- 지시 사항과 CPU-Clock (또는 Sched_Switch) Callstacks가 있어야합니다.
- GIPS '불꽃'의 너비는 CPU 클록 시간을 기준으로합니다.
- 색상은 GIP를 기반으로합니다. 차트의 왼쪽 상단에 빨간색에서 녹색에서 파란색 구배가 채색을 보여줍니다.
- Red는 높은 GIP입니다 (초당 많은 지시 사항 ... 많은 작업을 수행하는 'Hot'이라고 생각합니다)
- Blue는 낮은 GIP입니다 (초당 지침은 거의 없습니다 ... 나는 그것을 'Cold'라고 생각합니다)
- 아래는 채색과 GIP를 보여주는 샘플 확대 GIPS 차트입니다. 'Perf 3186/3186'을 클릭 했으므로 그 불꽃 만 아래에 표시됩니다.
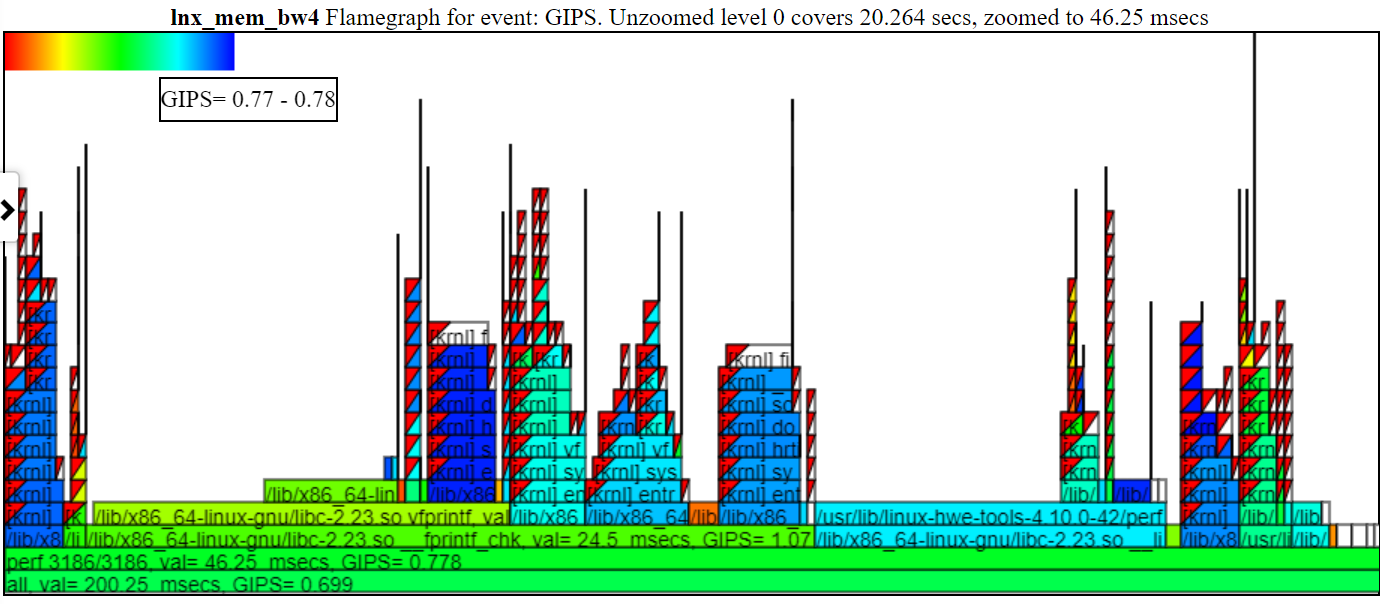
- 전설에서 프로세스를 숨기면 (전설 항목을 클릭하십시오 ... 회색이 발생합니다) 프로세스는 Flamegraph에 표시되지 않습니다.
- Flamegraph에서 마우스를 오른쪽으로 끌면 Flamegraph의 섹션이 확대됩니다.
- '불꽃'을 클릭하면 불꽃이 줌을냅니다
- Flamegraph에서 마우스를 드래그하면 왼쪽으로 축소됩니다.
- 해당 레벨의 모든 데이터에 대해 불꽃의 'Unzooms'의 하위 레벨을 클릭하십시오.
- Flamegraph의 'All'최저 수준을 클릭하면 다시 축소됩니다.
- Flamegraph 레벨을 클릭하면 각 레벨이 텍스트를 표시 할 수 있도록 각 레벨이 높아 지도록 차트가 크기가 커집니다. 이로 인해 차트가 크기를 조정합니다. 이 크기 조정에 대한 정신을 추가하려고 시도하고, 크기가 큰 차트의 마지막 레벨을 보이는 화면의 바닥에 배치합니다.
- 당신이 전설로 돌아가서 숨겨진 항목 위로 마우스를 가리면, 당신이 떠날 때까지 그 항목이 불꽃에 표시됩니다.
- '불꽃'상위 레벨을 클릭하면 해당 섹션 만 확대됩니다.
- '부모'차트를 확대/축소하면 선택한 간격에 대해 불꽃 그래프가 다시 그려집니다.
- '부모'차트에서 왼쪽/오른쪽으로 팬을 팬하면 선택한 간격으로 불꽃을 다시 그립니다.
- 기본적으로 불꽃 그래프의 각 레벨의 텍스트는 아마도 맞지 않을 것입니다. flamegraph를 클릭하면 크기가 확장되어 텍스트도 그리기를 활성화합니다.
- 프로세스/PID/TID 또는 프로세스/PID 또는 프로세스로 FlameGraphs를 그룹화할지 여부를 선택할 수 있습니다.
- 'CPU', 'Off CPU'및 'Run Queue'Flamegraphs가 모두 그려집니다.
- 'On CPU'는 CPU에서 실행 중에 스레드가 수행 한 작업에 대한 콜 스택입니다 ... 따라서 SampledProfile Callstacks 또는 Perf CPU-Clock Callstack은 CPU에서 실행 중일 때 스레드가 무엇을했는지 표시합니다.
- 'Off CPU'는 실행되지 않은 스레드, 대기 중 얼마나 오래 대기했는지, 그리고 콜 스택을 교환했을 때의 경우를 보여줍니다.
- 아래는 OFF-CPU 또는 대기 시간 차트의 스크린 샷입니다. 팝업은 (Flamegraph에서) 'Wait.x'가 Nanosleep에서 기다리고 있음을 보여줍니다.

- 스왑 '상태'(및 '이유'에서는 프로세스 위의 레벨로 표시됩니다. 일반적으로 대부분의 스레드는 수면이거나 달리지 않지만 "내 스레드가 실행되지 않았을 때 ... 무엇을 기다리고 있었습니까?"라는 질문에 대답하는 데 도움이됩니다.
- 컨텍스트 스위치에 '상태'를 표시하면 다음을 볼 수 있습니다.
- 예를 들어, 스레드가 무분별 수면에서 기다리고 있는지 여부 (Linux의 State == D ... 일반적으로 IO)
- 인터럽트 수면 (State = S ... 자주 나노 수면 또는 futex)
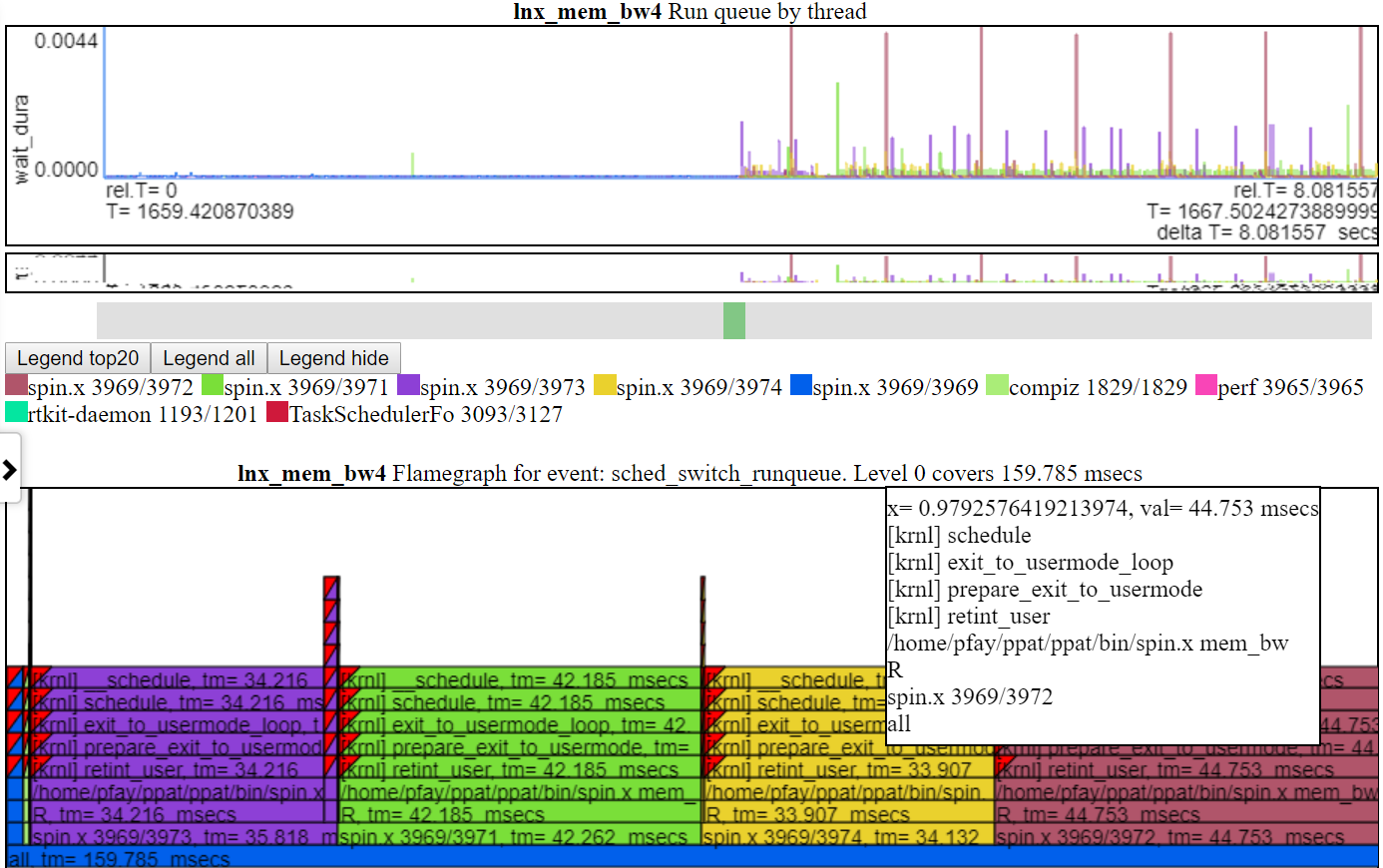
- 'run queue'는 교환되어 달리기 또는 달리기 상태에있는 스레드를 보여줍니다. 따라서이 차트는 실행 가능한 상태에 스레드가 있지만 실행되지 않은 경우 CPU의 채도를 보여줍니다.
- 아래는 run_queue 차트의 스크린 샷입니다. 이 차트는 CPU가 충분하지 않아 스레드가 실행되지 않은 시간을 보여줍니다. 즉, 실행할 준비가되었지만 다른 것이 CPU를 사용하고있었습니다. 각 flamegraph는 그래프에서 다루는 총계를 보여줍니다. run_queue 차트의 경우 대기 시간에 ~ 159msecs가 표시됩니다. 따라서 Spin.x는 약 20 초의 런 타임과 0.159 초의 '대기'시간이 있기 때문에 그렇게 나쁘지 않은 것 같습니다.
나는 캔버스 기반 차트 라이브러리가 없었기 때문에 차트는 일종의 원유입니다 ... 더 나은 것이 있다면 차트를 만드는 데 너무 많은 시간을 소비하고 싶지 않았습니다. 차트는 데이터 양으로 인해 HTML 캔버스 (SVG, D3.JS 등)를 사용해야합니다.
OPPAT의 데이터 수집
성능 및 전원 데이터를 수집하는 것은 매우 '상황 적'입니다. 한 사람은 스크립트를 실행하고 싶고 다른 사람은 버튼으로 측정을 시작한 다음 비디오를 시작한 다음 버튼을 누르면 컬렉션을 종료하려고합니다. Windows 용 스크립트와 Linux 용 스크립트가 있습니다.
- 데이터 수집 시작,
- 작업량 실행,
- 데이터 수집을 중지하십시오
- 데이터 후 처리 (Perf/Xperf/Trace-CMD 이진 데이터에서 텍스트 파일 생성)
- 모든 데이터 파일을 출력 딥에 넣습니다
- 출력 dir에서 file_list.json 파일 생성 (OpPat에게 출력 파일의 이름과 유형을 알려줍니다)
스크립트를 사용한 데이터 수집 단계 :
- spin.exe (spin.x)를 빌드하고 WAIT.EXE (WAIT.X) 유틸리티를 작성하십시오
- OpPat 루트 DIR에서 :
- Linux :
./mk_spin.sh - Windows :
.mk_spin.bat (Visual Studio CMD Box에서) - 바이너리는 ./bin subdir에 배치됩니다
- 제공된 스크립트를 실행하는 것으로 시작하십시오.
- run_perf_x86_haswell.sh- Haswell cpu_diagram 데이터 수집 용
- Linux에서 :
sudo bash ./scripts/run_perf.sh 를 입력하십시오 - 기본적으로 스크립트는 데이터를 dir ../oppat_data/lnx/mem_bw7에 넣습니다.
- run_perf.sh- 트레이스 -cmd와 perf가 설치되어 있어야합니다.
- Linux에서 :
sudo bash ./scripts/run_perf.sh 를 입력하십시오 - 기본적으로 스크립트는 데이터를 dir ../oppat_data/lnx/mem_bw4에 넣습니다.
- run_xperf.bat- xperf.exe를 설치해야합니다.
- admin 권한이있는 CMD 상자에서 Windows에서 :
.scriptsrun_xperf.sh - 기본적으로 스크립트는 데이터를 dir .. oppat_data win mem_bw4에 넣습니다.
- 기본값을 변경하려면 실행 스크립트 편집
- 데이터 파일 외에도 실행 스크립트는 출력 dir에서 file_list.json 파일을 만듭니다. oppat은 file_list.json 파일을 사용하여 출력 DIR의 파일 이름과 파일 유형을 파악합니다.
- 실행 스크립트의 '워크로드'는 Spin.x (또는 spin.exe)이며, 4 초 동안 1 CPU에서 메모리 대역폭 테스트를 한 다음 모든 CPU에서 4 초 동안 모든 CPU를 수행합니다.
- 또 다른 프로그램 Wait.x/Wait.exe도 백그라운드에서 시작됩니다. 대기 .cpp는 내 노트북의 배터리 정보를 읽습니다. 내 듀얼 부팅 Windows 10/Linux Ubuntu 노트북에서 작동합니다. SYSFS 파일은 Linux의 이름이 다를 수 있으며 Android에서는 거의 확실합니다.
- Linux에서는 아마도 run_perf.sh와 동일한 구문을 사용하여 prf_trace.data 및 prf_trace.txt 파일을 생성 할 수 있지만 이것을 시도하지 않았습니다.
- 랩톱에서 실행 중이고 배터리 전원을 획득하려면 스크립트를 실행하기 전에 전원 케이블을 분리하십시오.
PCM 데이터 지원
- OPPAT는 PCM .CSV 파일을 읽고 차트 할 수 있습니다.
- 아래는 생성 된 차트 목록의 스냅 샷입니다.
- 불행히도 OPPAT가 처리 할 절대 타임 스탬프가있는 파일을 만들려면 PCM에 패치를 수행해야합니다.
- PCM CSV 파일에는 다른 데이터 소스와 관련이있는 타임 스탬프가 없기 때문입니다.
- PCM 패치에 패치를 추가했습니다
OPPAT 구축
- Linux에서는 Oppat 루트 디어를
make 하십시오- 모든 것이 작동하면 빈/oppat.x 파일이 있어야합니다
- Windows에서는 다음을 필요로합니다.
- GNU Make의 Windows 버전을 설치하십시오. http://gnuwin32.sourceforge.net/packages/make.htm을 참조하십시오. 또는 최소 필수 바이너리에 대해서는 http://gnuwin32.sourceforge.net/downlinks/make.php를 사용하십시오.
- 이 새로운 '만들기'바이너리를 경로에 넣으십시오
- 현재 Visual Studio 2015 또는 2017 C/C ++ 컴파일러가 필요합니다 (VS 2015 Professional 및 VS 2017 커뮤니티 컴파일러를 모두 사용했습니다).
- Windows 시작 비주얼 스튜디오 X64 기본 CMD 프롬프트 상자
- OpPat 루트 DIR에서
make 입력하십시오 - 모든 것이 작동하면 bin oppat.exe 파일이 있어야합니다
- 소스 코드를 변경하는 경우 종속성 포함 파일을 재건해야 할 것입니다.
- Perl을 설치해야합니다
- Linux에서 Oppat 루트 DIR :
./mk_depends.sh . 이렇게하면 종속 _lnx.mk 종속성 파일이 생성됩니다. - on Windows, in the OPPAT root dir do:
.mk_depends.bat . This will create a depends_win.mk dependency file.
- If you are going to run the sample run_perf.sh or run_xperf.bat scripts, then you need to build the spin and wait utilities:
- On Linux:
./mk_spin.sh - On Windows:
.mk_spin.bat
Running OPPAT
- Run the data collection steps above
- now you have data files in a dir (if you ran the default run_* scripts:
- on Windows ..oppat_datawinmem_bw4
- on Linux ../oppat_data/lnx/mem_bw4
- You need to add the created files to the input_filesinput_data_files.json file:
- Starting OPPAT reads all the data files and starts the web server
- on Windows to generate the haswell cpu_diagram (assuming your data dir is ..oppat_datalnxmem_bw7)
binoppat.exe -r ..oppat_datalnxmem_bw7 --cpu_diagram webhaswell_block_diagram.svg > tmp.txt
- on Windows (assuming your data dir is ..oppat_datawinmem_bw4)
binoppat.exe -r ..oppat_datawinmem_bw4 > tmp.txt
- on Linux (assuming your data dir is ../oppat_data/lnx/mem_bw4)
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 > tmp.txt
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 --web_file tst2.html > tmp.txt
- Then you can load the file into the browser with the URL address:
file:///C:/some_path/oppat/tst2.html
Derived Events
'Derived events' are new events created from 1 or more events in a data file.
- Say you want to use the ETW Win32k InputDeviceRead events to track when the user is typing or moving the mouse.
- ETW has 2 events:
- Microsoft-Windows-Win32k/InputDeviceRead/win:Start
- Microsoft-Windows-Win32k/InputDeviceRead/win:Stop
- So with the 2 above events we know when the system started reading input and we know when it stopped reading input
- But OPPAT plots just 1 event per chart (usually... the cpu_busy chart is different)
- We need a new event that marks the end of the InputDeviceRead and the duration of the event
- The derived event needs:
- a new event name (in chart.json... see for example the InputDeviceRead event)
- a LUA file and routine in src_lua subdir
- 1 or more 'used events' from which the new event is derived
- the derived events have to be in the same file
- For the InputDeviceRead example, the 2 Win32k InputDeviceRead Start/Stop events above are used.
- The 'used events' are passed to the LUA file/routine (along with the column headers for the 'used events') as the events are encountered in the input trace file
- In the InputDeviceRead lua script:
- the script records the timestamp and process/pid/tid of a 'start' event
- when the script gets a matching 'Stop' event (matching on process/pid/tid), the script computes a duration for the new event and passes it back to OPPAT
- A 'trigger event' is defined in chart.json and if the current event is the 'trigger event' then (after calling the lua script) the new event is emitted with the new data field(s) from the lua script.
- An alternate to the 'trigger event' method is to have the lua script indicate whether or not it is time to write the new event. For instance, the scr_lua/prf_CPI.lua script writes a '1' to a variable named ' EMIT ' to indicate that the new CPI event should be written.
- The new event will have:
- the name (from the chart.json evt_name field)
- The data from the trigger event (except the event name and the new fields (appended)
- I have tested this on ETW data and for perf/trace-cmd data
Using the browser GUI Interface
TBD
Defining events and charts in charts.json
TBD
Rules for input_data_files.json
- The file 'input_files/input_data_files.json' can be used to maintain a big list of all the data directories you have created.
- You can then select the directory by just specifying the file_tag like:
- bin/oppat.x -u lnx_mem_bw4 > tmp.txt # assuming there is a file_tag 'lnx_mem_bw4' in the json file.
- The big json file requires you to copy the part of the data dir's file_list.json into input_data_files.json
- in the file_list.json file you will see lines like:
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- don't copy the lines like below from the file_list.json file:
- paste the copied lines into input_data_files.json. Pay attention to where you paste the lines. If you are pasting the lines at the top of input_data_files.json (after the
{"root_dir":"/data/ppat/"}, then you need add a ',' after the last pasted line or else JSON will complain. - for Windows data files add an entry like below to the input_filesinput_data_files.json file:
- yes, use forward slashes:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- for Linux data files add an entry like below to the input_filesinput_data_files.json file:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/lnx/mem_bw4 " },
{ "cur_tag" : " lnx_mem_bw4 " },
{ "bin_file" : " prf_energy.txt " , "txt_file" : " prf_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " },
{ "bin_file" : " prf_trace.data " , "txt_file" : " prf_trace.txt " , "tag" : " %cur_tag% " , "type" : " PERF " },
{ "bin_file" : " tc_trace.dat " , "txt_file" : " tc_trace.txt " , "tag" : " %cur_tag% " , "type" : " TRACE_CMD " },- Unfortunately you have to pay attention to proper JSON syntax (such as trailing ','s)
- Here is an explanation of the fields:
- The 'root_dir' field only needs to entered once in the json file.
- It can be overridden on the oppat cmd line line with the
-r root_dir_path option - If you use the
-r root_dir_path option it is as if you had set "root_dir":"root_dir_path" in the json file - the 'root_dir' field has to be on a line by itself.
- The cur_dir field applies to all the files after the cur_dir line (until the next cur_dir line)
- the '%root_dir% string in the cur_dir field is replaced with the current value of 'root_dir'.
- the 'cur_dir' field has to be on a line by itself.
- the 'cur_tag' field is a text string used to group the files together. The cur_tag field will be used to replace the 'tag' field on each subsequent line.
- the 'cur_tag' field has to be on a line by itself.
- For now there are four types of data files indicated by the 'type' field:
- type:PERF These are Linux perf files. OPPAT currently requires both the binary data file (the bin_file field) created by the
perf record cmd and the perf script text file (the txt_file field). - type:TRACE_CMD These are Linux trace-cmd files. OPPAT currently requires both the binary dat file (the bin_file field) created by the
trace-cmd record cmd and the trace-cmd report text file (the txt_file field). - type:ETW These are Windows ETW xperf data files. OPPAT currently requires only the text file (I can't read the binary file). The txt_file is created with
xperf ... -a dumper command. - type:LUA These files are all text files which will be read by the src_lua/test_01.lua script and converted to OPPAT data.
- the 'prf_energy.txt' file is
perf stat output with Intel RAPL energy data and memory bandwidth data. - the 'prf_energy2.txt' file is created by the wait utility and contains battery usage data in the 'perf stat' format.
- the 'wait.txt' file is created by the wait utility and shows the timestamp when the wait utility began
- Unfortunately 'perf stat' doesn't report a high resolution timestamp for the 'perf stat' start time
제한
- The data is not reduced on the back-end so every event is sent to the browser... this can be a ton of data and overwhelm the browsers memory
- I probably should have some data reduction logic but I wanted to get feedback first
- You can clip the files to a time range:
oppat.exe -b abs_beg_time -e abs_beg_time to reduce the amout of data- This is a sort of crude mechanism right now. I just check the timestamp of the sample and discard it if the timestamp is outside the interval. If the sample has a duration it might actually have data for the selected interval...
- There are many cases where you want to see each event as opposed to averages of events.
- On my laptop (with 4 CPUs), running for 10 seconds of data collection runs fine.
- Servers with lots of CPUs or running for a long time will probably blow up OPPAT currently.
- The stacked chart can cause lots of data to be sent due to how it each event on one line is now stacked on every other line.
- Limited mechanism for a chart that needs more than 1 event on a chart...
- say for computing CPI (cycles per instruction).
- Or where you have one event that marks the 'start' of some action and another event that marks the 'end' of the action
- There is a 'derived events' logic that lets you create a new event from 1 or more other events
- See the derived event section
- The user has to supply or install the data collection software:
- on Windows xperf
- See https://docs.microsoft.com/en-us/windows-hardware/get-started/adk-install
- You don't need to install the whole ADK... the 'select the parts you want to install' will let you select just the performance tools
- on Linux perf and/or trace-cmd
sudo apt-get install linux-tools-common linux-tools-generic linux-tools- ` uname -r `
- For trace-cmd, see https://github.com/rostedt/trace-cmd
- You can do (AFAIK) everything in 'perf' as you can in 'trace-cmd' but I have found trace-cmd has little overhead... perhaps because trace-cmd only supports tracepoints whereas perf supports tracepoints, sampling, callstacks and more.
- Currently for perf and trace-cmd data, you have to give OPPAT both the binary data file and the post-processed text file.
- Having some of the data come from the binary file speeds things up and is more reliable.
- But I don't want to the symbol handling and I can't really do the post-processing of the binary data. Near as I can tell you have to be part of the kernel to do the post processing.
- OPPAT requires certain clocks and a certain syntax of 'convert to text' for perf and trace-cmd data.
- OPPAT requires clock_monotonic so that different file timestamps can be correlated.
- When converting the binary data to text (trace-cmd report or 'perf script') OPPAT needs the timestamp to be in nanoseconds.
- see scriptsrun_xperf.bat and scriptsrun_perf.sh for the required syntax
- given that there might be so many files to read (for example, run_perf.sh generates 7 input files), it is kind of a pain to add these files to the json file input_filesinput_data_files.json.
- the run_xperf.bat and run_perf.sh generate a file_list.json in the output directory.
- perf has so, so many options... I'm sure it is easy to generate some data which will break OPPAT
- The most obvious way to break OPPAT is to generate too much data (causing browser to run out of memory). I'll probably handle this case better later but for this release (v0.1.0), I just try to not generate too much data.
- For perf I've tested:
- sampling hardware events (like cycles, instructions, ref-cycles) and callstacks for same
- software events (cpu-clock) and callstacks for same
- tracepoints (sched_switch and a bunch of others) with/without callstacks
- Zooming Using touchpad scroll on Firefox seems to not work as well it works on Chrome



