オープンパワー/パフォーマンス分析ツール(OPPAT)
目次
- 導入
- サポートされているデータの種類
- Oppatの視覚化
- OPPATのデータ収集
- PCMデータサポート
- オッパットを建設します
- Oppatを実行します
- 派生イベント
- Browswer GUIインターフェイスを使用します
- 制限
導入
オープンパワー/パフォーマンス分析ツール(OPPAT)は、Cross-OS、クロスアーキテクチャパワー、パフォーマンス分析ツールです。
- Cross-OS:WindowsETW TraceファイルとLinux/Android Perf/Trace-CMD Traceファイルをサポート
- クロスアーキテクチャ:IntelおよびARMチップスハードウェアイベントをサポートします(PERFおよび/またはPCMを使用)
プロジェクトWebページはhttps://patinnc.github.ioです
ソースコードレポはhttps://github.com/patinnc/oppatです
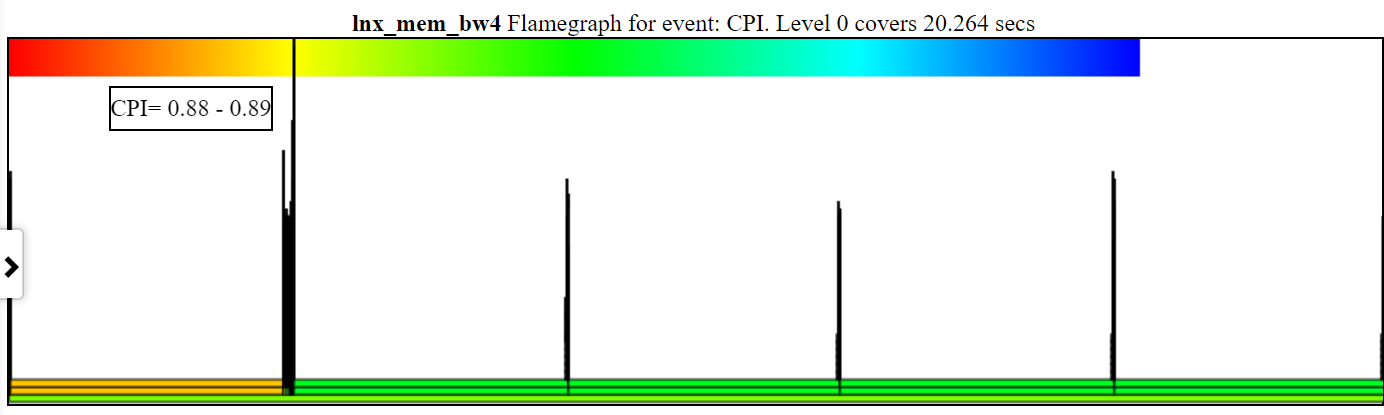
CPUブロック図機能にオペレーティングシステム(OS_VIEW)を追加しました。これは、http://www.brendangregg.com/linuxperf.htmlなどのブレンダングレッグのページに基づいています。 ARM 64bit Ubuntu Mate V18.04.2 Raspberry Pi 3 B+、4 ARM Cortex A53 CPUで古いバージョンのGeekBench v2.4.2(32ビットコード)を実行するためのいくつかの例データを以下に示します。
- OS_VIEWおよびARM A53 CPUブロックの変更のビデオは、GeekBenchを実行しています。
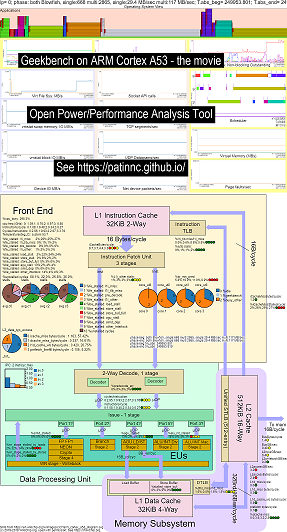
- OS_VIEWとCPU_DIAGRAGグラムのレイアウトを説明しようとするいくつかの入門スライドがあり、30のサブテストのそれぞれに応じた結果を示す1つのスライドがあります
- 映画のデータのExcelファイル:geekbenchからのExcelファイル
- 映画のデータのHTML ... OS_VIEWを備えた4つのCore Arm Cortext A53のGeekbench v2.4.2を参照してください。
- 命令/SECを増やすことでソートされた30のすべてのフェーズのダッシュボードPNG ... CPUダイアグラム4コアチップダッシュボードを使用してGeekbenchを実行しているARM Cortex A53 Raspberry Pi 3を参照してください。
Raspberry PI 3 B+(Cortex A53)CPUで私のスピンベンチマーク(メモリ/キャッシュ帯域幅テスト、「スピン」Keep-CPU-Busyテスト)を実行するためのいくつかの例を示します。
- OS_VIEWおよびARM A53 CPUブロック図を実行しているスピンの変更のビデオ:
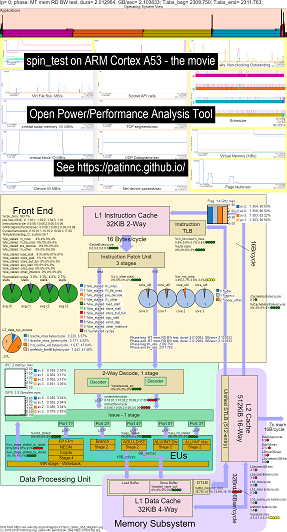
- OS_VIEWチャートとCPU_DIAGRAGAGRAGAGRAGANレイアウトを説明しようとするいくつかの入門スライドがあります。各サブテストが表示されているスライド(秒単位)が表示されています(そのため、T = X秒に移動してそのサブテストに直接移動できます)。
- 映画のデータのExcelファイル:geekbenchからのExcelファイル
- 映画のデータのHTML ... CPU Diagramを使用したARM Cortex A53 Raspberry Pi 3を参照してください。
- 命令/秒を増やすことでソートされた5つのすべてのフェーズのダッシュボードPNG ... CPUダイアグラム4コアチップダッシュボードを実行してスピンベンチマークを実行しているARM Cortex A53 Raspberry Pi 3を参照してください。
Haswell CPUでGeekbenchを実行するためのデータの例を次に示します。
- OS_VIEWおよびHASWELL CPUブロックの変更のビデオを実行しているビデオを実行しています。
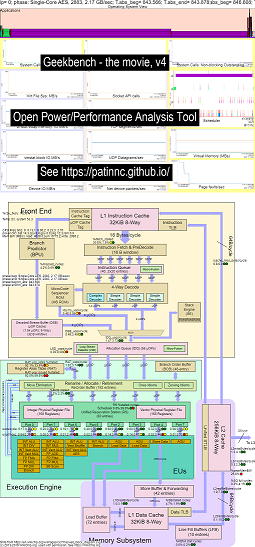
- OS_VIEWチャートとCPU_DIAGRAGAGRAGAGRAGANレイアウトを説明しようとするいくつかの入門スライドがあります。各サブテストが表示されているスライド(秒単位)が表示されています(そのため、T = X SECに移動してそのサブテストに直接移動できます)。
- 映画のデータのExcelファイル:geekbenchからのExcelファイル
- 映画のデータのHTML ... CPU Diagram 4-CPUチップランニングGeekbenchを使用してIntel Haswellを参照してください。
- UOPS Retired/Secを増やすことでソートされた50のすべてのフェーズのダッシュボードPNG ... CPU Diagramを使用したIntel Haswell Dashboardを参照してください。
Haswell CPUで4つのサブテストを使用して、「Spin」ベンチマークを実行するためのデータを次に示します。
- 最初のサブテストは、読み取りメモリ帯域幅テストです。 L2/L3/メモリブロックは、テスト中に高度に使用され、失速します。ネズミのUOPS/サイクルは、ラットがほとんど失速しているため、低くなっています。
- 2番目のサブテストは、L3読み取り帯域幅テストです。メモリBWが低くなっています。 L2およびL3ブロックは、テスト中に高度に使用され、失速します。ラットのUOPS/サイクルは、ラットの停止が少なくなるにつれて高くなります。
- 3番目のサブテストは、L2読み取り帯域幅テストです。 L3とメモリBWは低くなっています。 L2ブロックは、テスト中に高度に使用され、失速します。ラットのUOPS/サイクルは、ラットがさらに停止することが少ないため、さらに高くなっています。
- 4番目のサブテストは、スピン(追加ループ)テストです。 L2、L3、およびメモリBWはゼロに近いです。ラットUOPS/サイクルは約3.3 UOPS/サイクルで、可能な限り4つのUOPS/サイクルに近づいています。
- 分析で「スピン」を実行しているHaswell CPUブロック図の変更のビデオ。見る
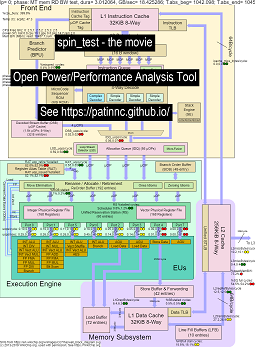
- 映画のデータのExcelファイル:Spin the MovieからのExcelファイル
- 映画のデータのHTML ... CPUダイアグラム4-CPUチップを実行しているIntel Haswellを参照してください。
CPUダイアグラムデータコレクションを備えたIntel Haswellは、パフォーマンスサンプリングやその他のデータを収集した50以上のHWイベントを備えた4-CPU Intelチップ、Linux OS、HTMLファイル用です。 cpu_diagram機能:
- wikichip.orgからのブロック図SVG(許可を得て使用)から始め、
- リソースの制約(さまざまなパスでの最大BW、最大バイト/サイクル、最小サイクル/UOPなど)を見てください。
- リソース使用量のメトリックを計算します
- 以下は、テーブルにリソースの使用情報を表示するメモリ読み取り帯域幅テストの表です(使用状況によりCPUが失速しているかどうかの推定値とともに)。 HTMLテーブル(ただし、PNGではなく)には、フィールド上にホバーするとポップアップ情報があります。表は次のことを示しています。
- コアは、最大25.9 GB/s BWの55%のメモリ帯域幅に停滞しています。メモリBWテストです
- Superqueue(SQ)は、サイクルのフル(Core0で54.5%、Core1の62.3%Core1)です(したがって、より多くのL2リクエストを処理できません)
- ラインフィルバッファーFBはいっぱい(30%および51%)ので、L2からラインをL1Dに移動することはできません
- その結果、バックエンドは、uopsが廃止されていないサイクルの停止(88%および87%)です。
- UOPSはループストリーム検出器から来ているようです(LSDサイクル/UOPはラットUOPS/サイクルとほぼ同じであるためです。
- ハスウェルCPUダイアグラムメモリBWテーブルのスクリーンショット
- 以下は、L3読み取り帯域幅テストの表です。
- これで、メモリBWとL3ミスバイト/サイクルは約ゼロになります。
- SQの停止は少なくなります(メモリを待っていないため)。
- L2トランザクションバイト/サイクルは、最大64バイト/サイクルの最大値の約2倍で、約67%です。
- UOPS_RETIRED_STALLS/CYCLEは、88%のMEM BWテストストールから66%に低下しました。
- 塗りつぶしの屋台は、2倍以上高くなっています。 UOPSはまだLSDから来ています。
- ハスウェルCPU図L3 BWテーブルのスクリーンショット
- 以下は、L2読み取り帯域幅テストの表です。
- L2ミスバイト/サイクルは、L3テストよりもはるかに低いです。
- uops_retired%stalledは現在34%のL3テストの約半分であり、FBストールも約17%です。
- UOPSはまだLSDから来ています。
- ハスウェルCPU図L2 BWテーブルのスクリーンショット
- 以下はスピンテストの表です(負荷なし、ループに追加するだけです)。
- これで、メモリサブシステムストールはゼロになりました。
- UOPSは、デコードストリームバッファー(DSB)から来ています。
- 3.31サイクル/UOPでのラットRetired_uops/Cycleは、最大4.0 UOPS/サイクルに近いものです。
- ラット退職_uops%の失速は、%8でかなり低いです。
- ハスウェルCPUダイアグラムスピンテーブルのスクリーンショット
現在、HaswellとArm A53用のCPU_Diagram映画のみがあります(他のシステムをテストするシステムがないため)が、他のブロック図を追加するのは難しくないはずです。あなたはまだすべてのチャートを取得しますが、CPU_Diagramではありません。
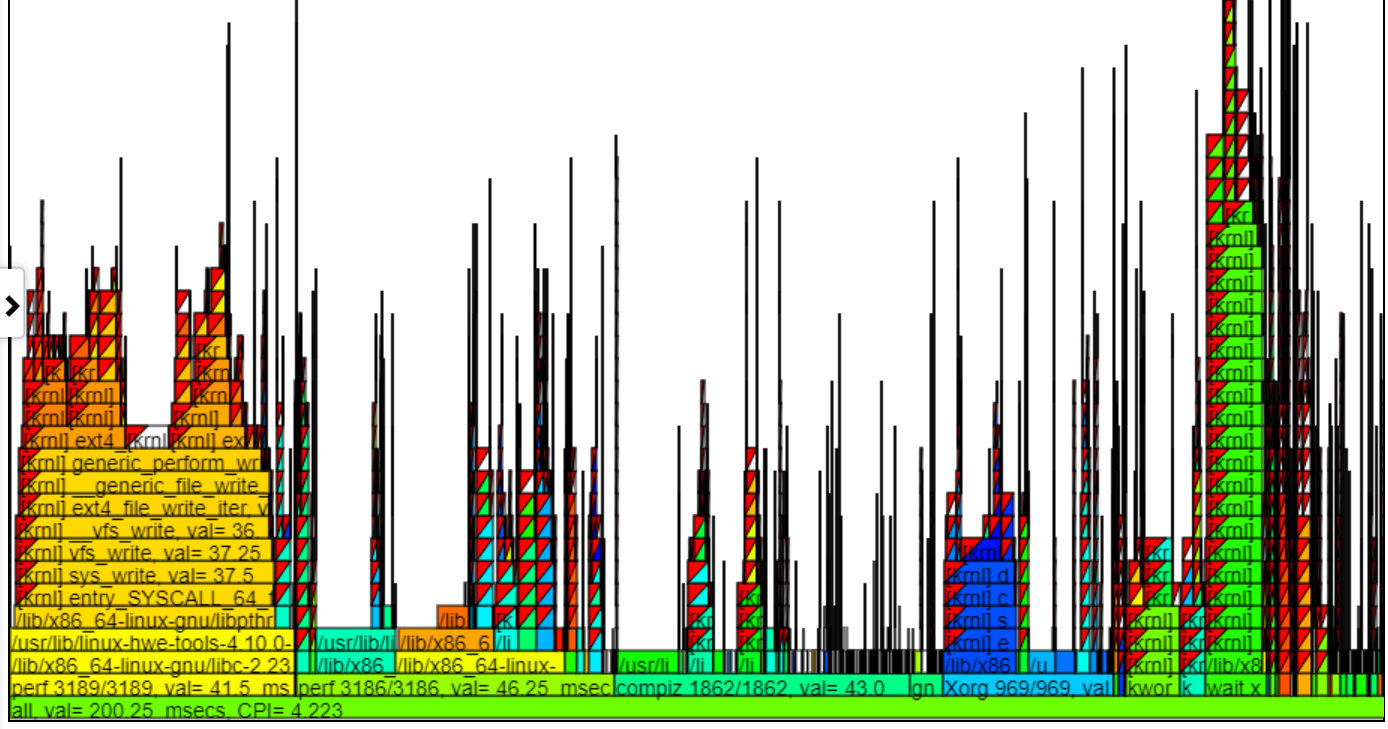
以下はOppatチャートの1つです。 「CPU_BUSY」チャートは、各CPUで実行されているものと各CPUで発生するイベントを示しています。たとえば、緑色の円はCPU 1で実行されているspin.xスレッドを示しています。赤い円は、CPU1で発生するイベントの一部を示しています。このチャートは、Trace-CMDのKernelsharkチャートをモデルにしています。 CPU_BUSYチャートの詳細については、チャートタイプのセクションにあります。 Calloutボックスには、カーソルの下のイベントのイベントデータ(CallStack(もしあれば)を含む)を示しています。残念ながら、Windowsスクリーンショットはカーソルをキャプチャしません。 
サンプルHTMLファイルを次に示します。ほとんどのファイルはより短い2インターバルですが、一部は「フル」8秒の実行です。ファイルはリポジトリから直接読み込まれませんが、プロジェクトWebページhttps://patinnc.github.ioからロードされます。
- CPUダイアグラム4-CPUチップ、Linux OS、PERFサンプリングまたは
- Intel 4-CPUチップ、Windows OS、Xperfサンプリングまたは
- フル〜8秒のIntel 4-CPUチップ、Windows OS、PCMおよびXPERFサンプリングを備えたHTMLファイルまたは
- Intel 4-CPUチップ、Linux OS、2つの多重化グループに10のHWイベントを備えたHTMLファイル。
- ARM(Broadcom A53)チップ、Raspberry PI3 Linux HTMLファイル14のHWイベント(CPI、L2 MISSES、MEM BWなど、2つの多重化グループ)。
- 11 MB、上記のフルバージョン(Broadcom A53)チップ、14のHWイベントを備えたRaspberry PI3 Linux HTMLファイル(CPI、L2 MISS、MEM BWなど、2つの多重化グループで)。
上記のファイルの一部は、〜8秒の長い走行から抽出された〜2秒間隔です。これが完全な8秒の実行です:
- より完全なファイルのために、ここで8秒間のLinux RunサンプルHTML圧縮ファイルを圧縮します。このファイルは、チャートデータのJavaScript Zlibが解凍されるため、減圧中に(約20秒)待機するように依頼するメッセージが表示されます。
サポートされているOPPATデータ
- Linuxパフォーマンスおよび/またはTrace-CMDパフォーマンスファイル(バイナリファイルとテキストファイルの両方)、
- PERF STAT出力も受け入れられました
- Intel PCMデータ、
- その他のデータ(LUAスクリプトを使用してインポート)、
- したがって、これは通常のLinuxまたはAndroidのデータで動作するはずです
- 現在、PERFおよびTRACE-CMDデータの場合、OPPATはバイナリとポストプロセスの両方のテキストファイルを必要とし、「レコード」コマンドラインと「Perf Script/Trace-CMDレポート」コマンドラインにいくつかの制限があります。
- OPPATは、Perf/Trace-CMDテキスト出力ファイルを使用するだけですが、現在はバイナリファイルとテキストファイルの両方が必要です
- Windows ETWデータ(Xperfによって収集され、テキストにダンプされた)またはIntel PCMデータ、
- LUAスクリプトを使用してサポートされている任意のパワーまたはパフォーマンスデータ(そのため、他のデータをインポートするためにC ++コードを再コンパイルする必要はありません(LUAパフォーマンスが問題になっていない限り))
- ファイルが発生した場所に関係なく、LinuxまたはWindowsのデータファイルを読み取ります(WindowsでPerf/Trace-CMDファイルを読み取り、LinuxのETWテキストファイルを読み取ります)
Oppatの視覚化
以下は、いくつかの完全なサンプル視覚ゼーションHTMLファイル:WindowsサンプルHTMLファイルまたはこのLinuxサンプルHTMLファイルです。リポジトリ(github.ioプロジェクトWebサイトではなく)を使用している場合は、ファイルをダウンロードしてからブラウザにロードする必要があります。これらは、たとえば、他の人にメールで送信される可能性のあるOppatによって作成されたスタンドアロンWebファイルまたは(ここにあるように)Webサーバーに投稿される可能性があります。
Oppat vizは、FirefoxよりもChromeでより良い動作をします。主にTouchPad 2フィンガースクロールを使用してズームがChromeでより適切に機能するためです。
OPPATには3つの視覚化モードがあります。
- 通常のチャートメカニズム(Oppatバックエンドがデータファイルを読み取り、ブラウザにデータを送信する場所)
- また、「通常のチャートメカニズム」に相当するが、他のユーザーと交換できるスタンドアロンWebページを作成することもできます。スタンドアロンのWebページには、すべてのスクリプトとデータが組み込まれているため、誰かにメールで送信でき、ブラウザにロードできます。上記のsample_html_filesのhtmlファイルを参照してください(lnx_mem_bw4の長いバージョンについては)圧縮ファイルsample_html_files/lnx_mem_bw4_full.htmlを参照してください
- データJSONファイルを「ゼロ」してから、後でファイルをロードできます。保存されたJSONファイルには、OPPATがブラウザに送信する必要があるデータがあります。これにより、入力PERF/XPERFファイルの再読み取りが回避されますが、Charts.jsonで行われた変更は取り上げられません。 -WEB_FILEオプションで作成された完全なHTMLファイルは、-saveファイルよりもわずかに大きいだけです。 -save/ - ロードモードには、oppatを構築する必要があります。 sample_data_json_files subdirのサンプル「保存」ファイルを参照してください。
viz一般情報
- ブラウザ内のすべてのデータをチャートします(LinuxまたはWindowsで)
- チャートはJSONファイルで定義されているため、Oppatを再コンパイルせずにイベントやチャートを追加できます
- ブラウザインターフェイスは、Windows WPA(左側のNavbar)のようなものです。
- 以下は、左navbar(左側のスライドメニュー)を示しています。
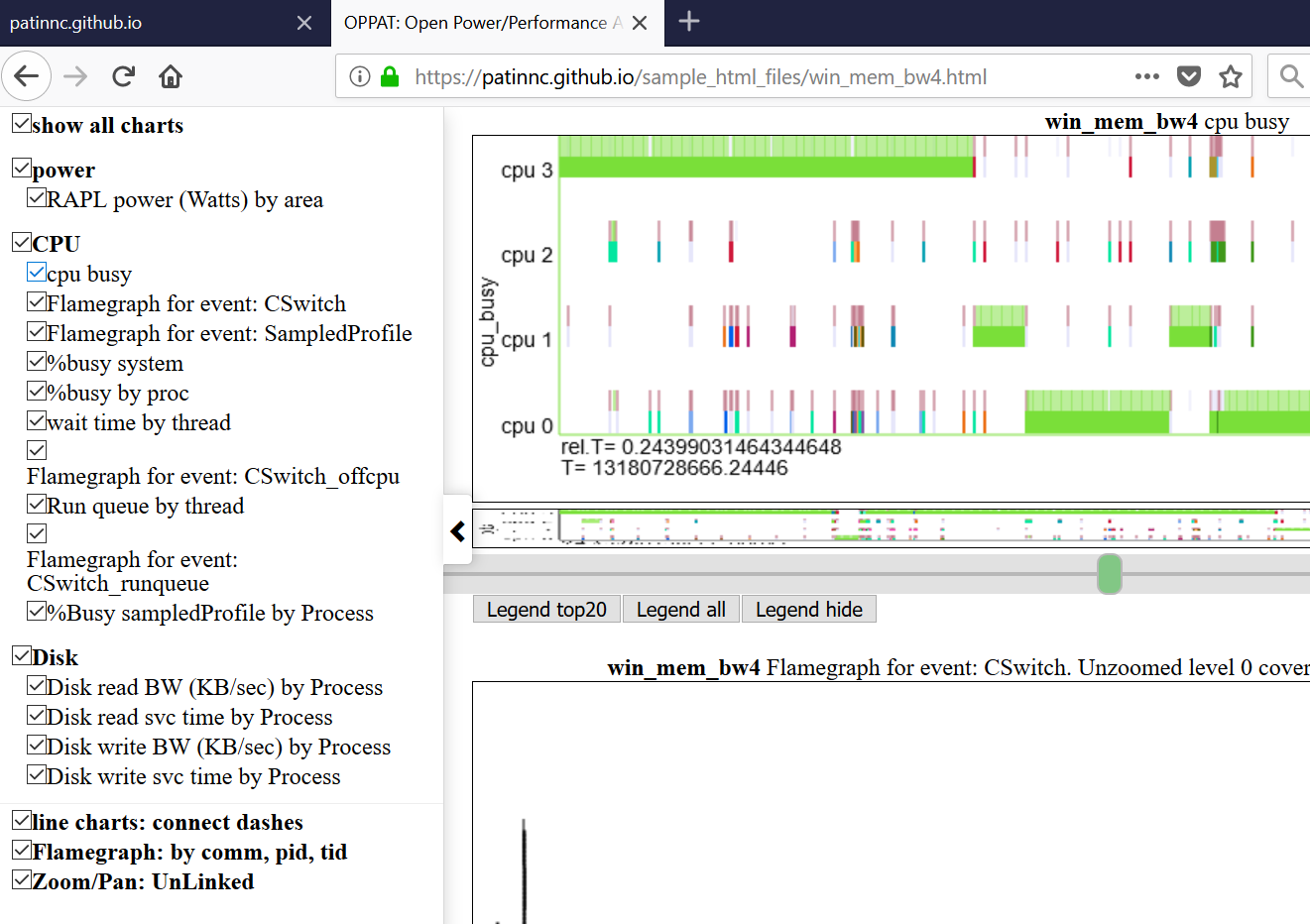
- チャートはカテゴリ(GPU、CPU、電力など)によってグループ化されています
- カテゴリは、input_files/charts.jsonで定義および割り当てられます
- チャートはすべて、Navbarのチャートをクリックして、すべて非表示または選択的に表示できます。
- 左のナビゲーションメニューのチャートタイトルをホバリングすると、そのチャートが表示されます
- ファイルの1つのグループからのデータは、別のグループと一緒にプロットできます
- だから、あなたが言うことができます、Linux Perfer PerformanceとWindowsETW実行を比較する
- チャート以下では、LinuxとWindowsの電源使用量を示しています。
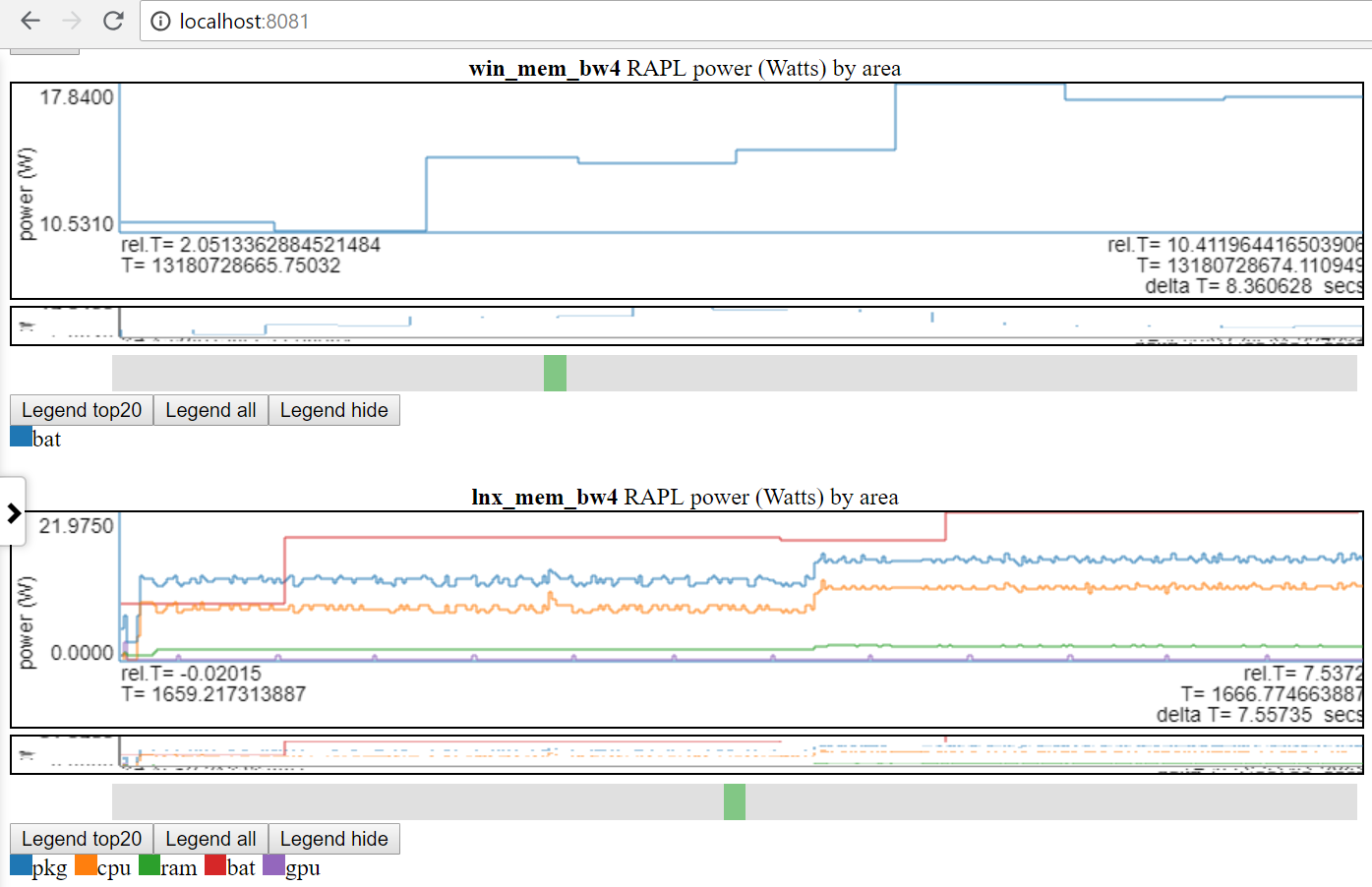
- LinuxとWindowsの両方でバッテリー電源のみにアクセスできます。
- 多くのサイトには、はるかに優れた電力データ(MSEC(またはより良い)レートでの電圧/電流/電源)があります。これらのタイプのパワーデータ(KratosやQualcomm MDPSなど)を組み込むのは簡単ですが、データにはアクセスできません。
- または、同じプラットフォームで2つの異なる実行を比較します
- ファイルグループタグ(file_tag)は、チャートを区別するためにタイトルに付けられています
- 「タグ」は、データdirのfile_list.jsonファイルおよび/またはinput_files/input_data_files.jsonで定義されています
- input_files/input_data_files.jsonは、すべてのOPPATデータ監督のリストです(ただし、ユーザーはそれを維持する必要があります)。
- 同じタイトルのチャートは、簡単な比較を可能にするために次々とプロットされます
チャート機能:
チャートの線のセクションの上にホバリングすると、その点でのその線のデータポイントが表示されます
- これは、2ポイントを接続しているだけなので、垂直線では機能しません...各ラインの水平ピースのみがデータ値を検索します
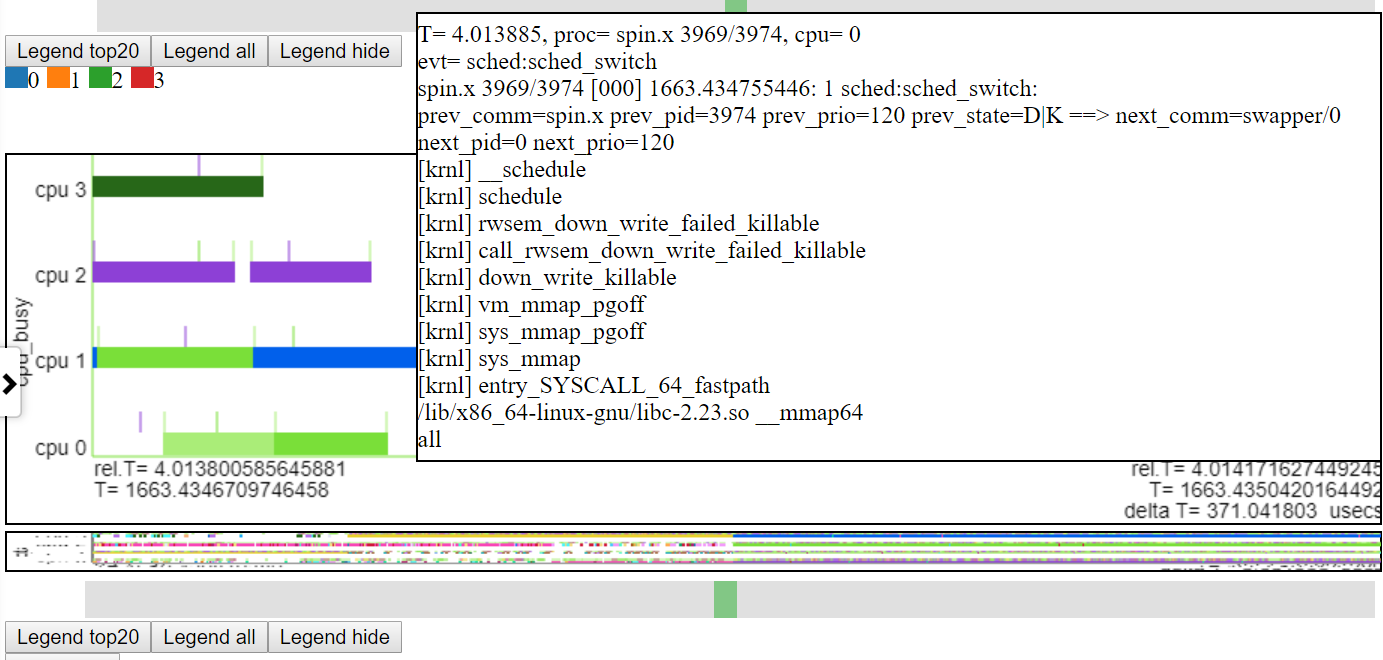
- 以下は、ホバリングオーバーイベントのスクリーンショットです。これは、(cswtich)イベントの相対的な時間、プロセス/pid/tidなどの情報、およびテキストファイルの行番号を示しているため、詳細情報を入手できます。

- 以下は、イベントのコールスタック情報(ある場合)を示すスクリーンショットです。

ズーミング
- NanoSecレベルにズームインしてズームインし、ズームアウトします。
- おそらく、ピクセルよりも多くの桁違いのプロットポイントがあるため、ズームインするとより多くのデータが表示されます。
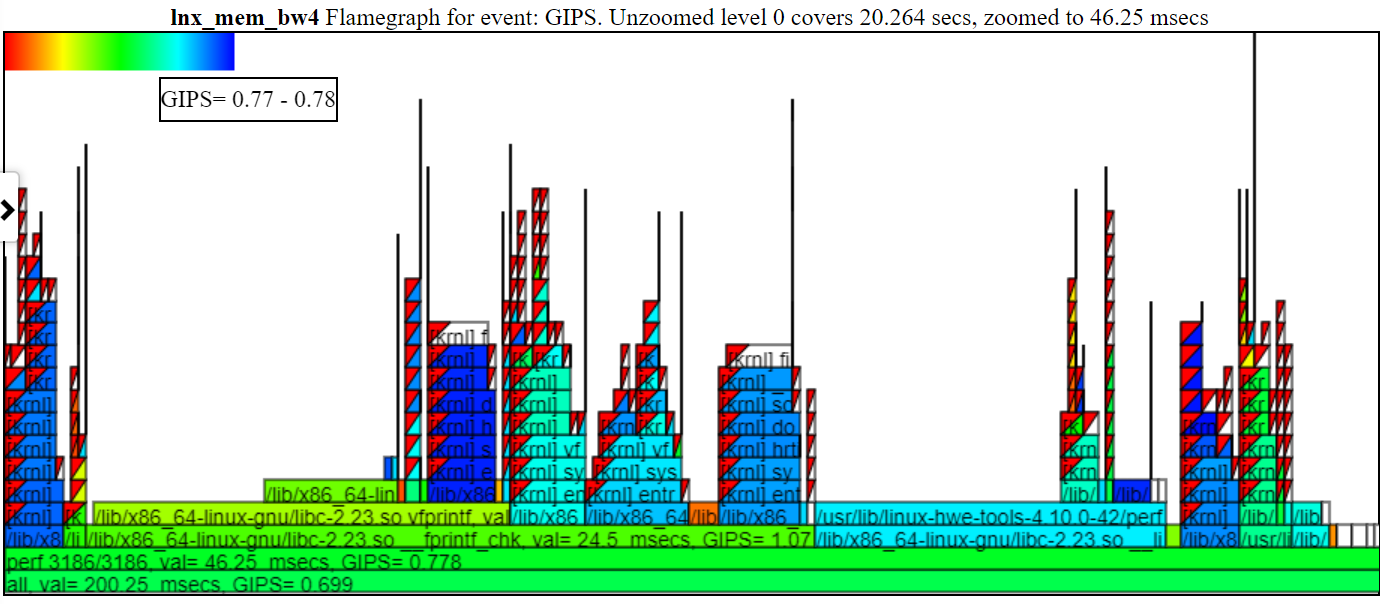
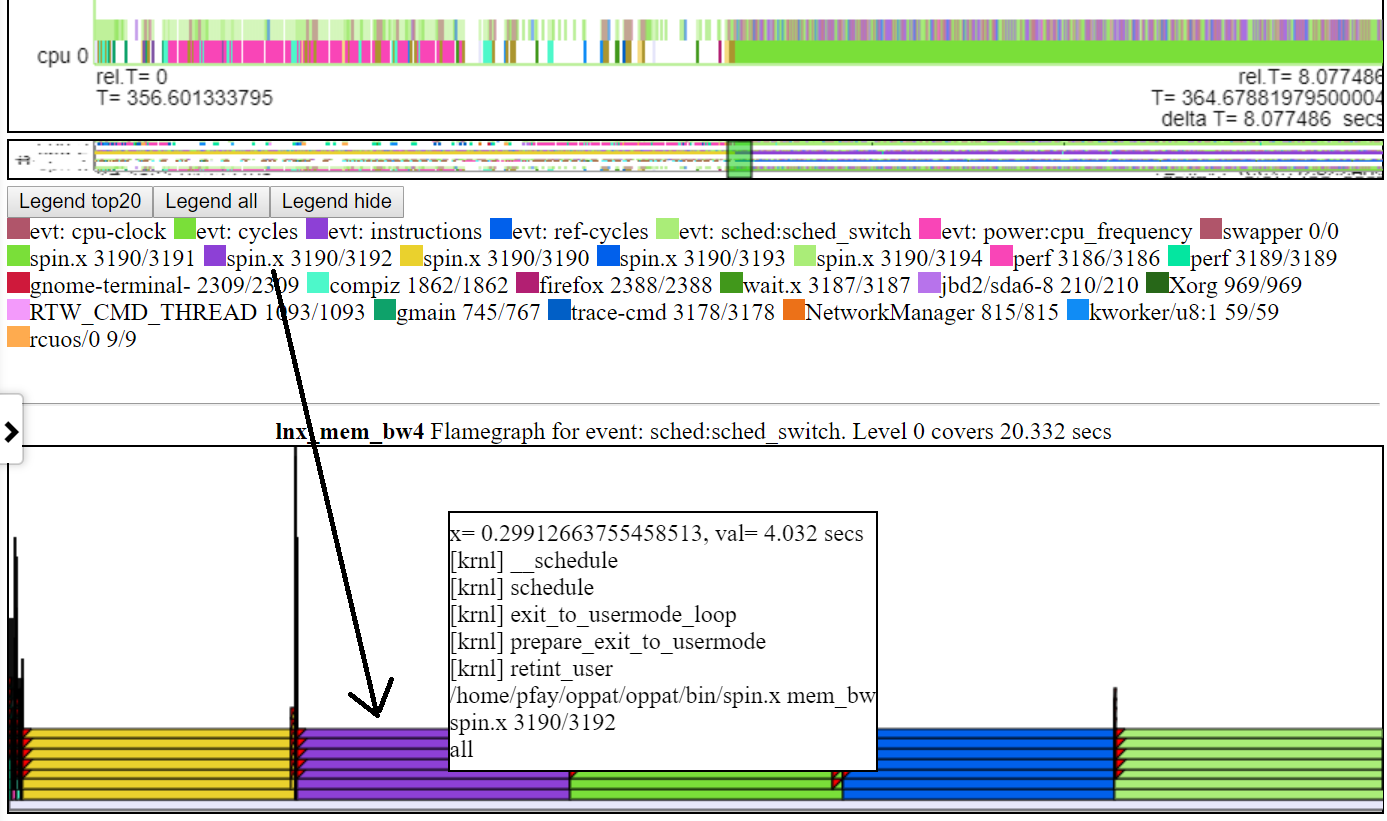
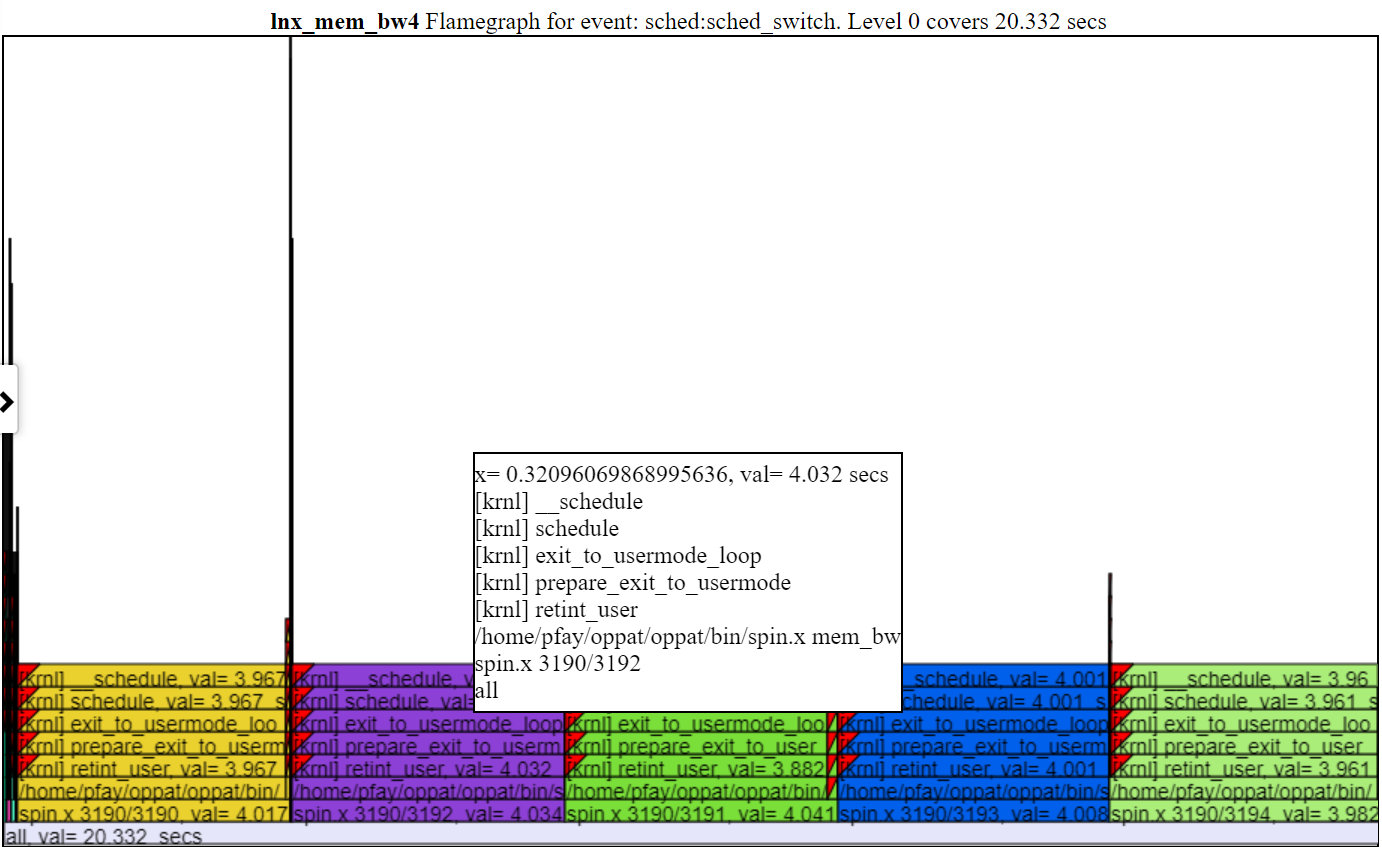
- 以下は、マイクロ秒レベルまでのズームを示すスクリーンショットです。これは、メモリマッピング操作を実行してアイドル状態にすることにより、Spin.XがブロックされるSched_Switchイベントのコールスタックを示しています。 「CPUビジー」チャートは、「アイドル状態」を空白として示しています。
 。
。
- チャートは個別にズームしたり、同じfile_tagでチャートをリンクして、ズーム/パン1チャートを同じfile_tagですべてのチャートの間隔を変更することができます
- 左navbarの底までスクロールし、「ズーム/パン:リンクされていない」をクリックします。これにより、メニュー項目が「ズーム/パン:リンク」に変更されます。これにより、ファイルグループ内のすべてのチャートが最新のズーム/パンの絶対時間にズーム/パンします。これには、すべてのチャートを再描画するのに時間がかかります。
- 最初に各チャートが描画され、利用可能なすべてのデータが表示されます。チャートが異なるソースからのものである場合、T_BEGINとT_END(さまざまなソースからのチャートの場合)はおそらく異なります。
- ズーム/パン操作がすべて完了し、リンクが有効になると、ファイルグループのすべてのチャートが同じ絶対間隔にズーム/パンになります。
- これが、各ソースに使用される「クロック」が同じでなければならない理由です。
- Oppatは、ある時計から別の時計に翻訳できます(GetTime(clock_monotonic)とgetTimeOf())がそのロジック
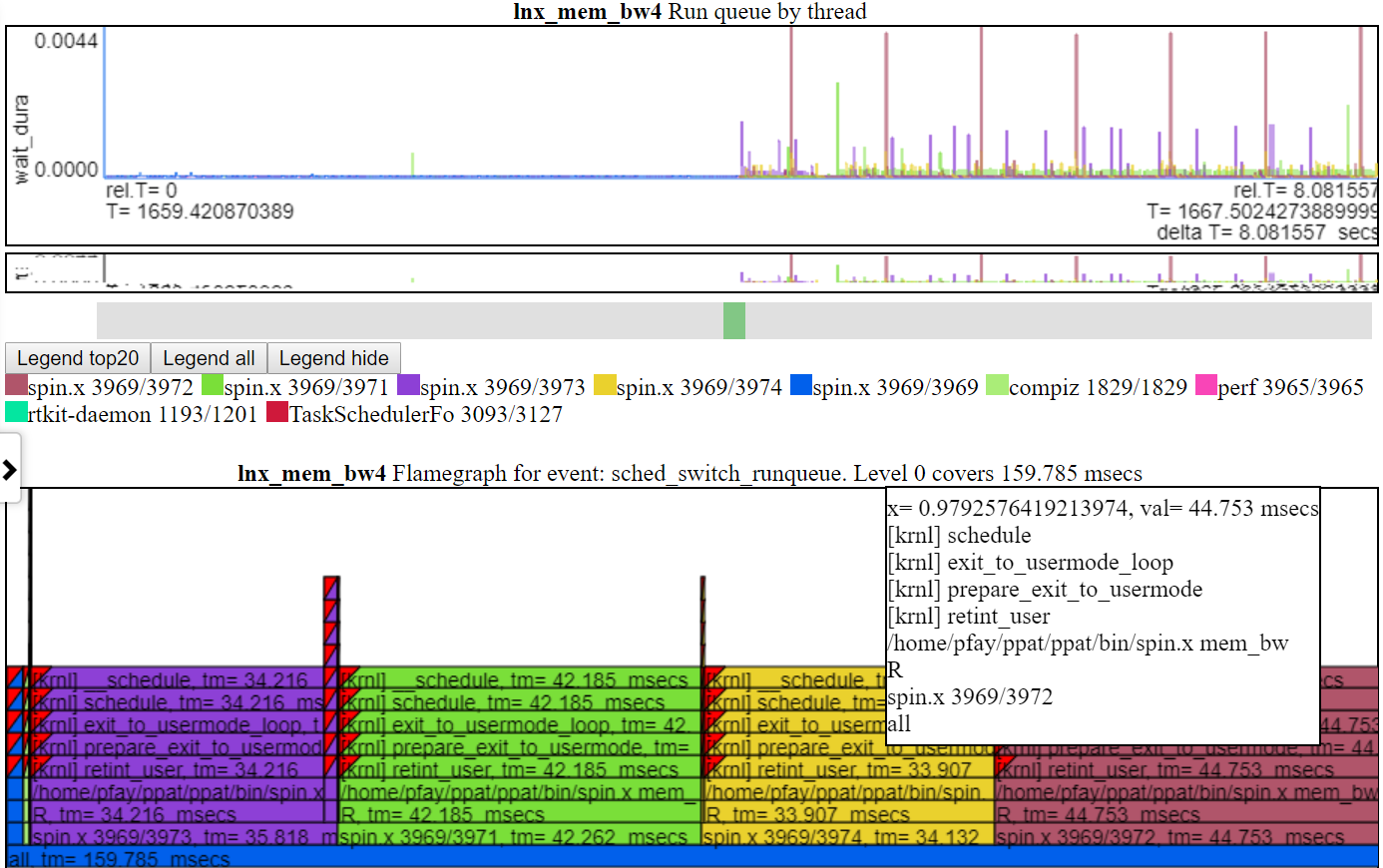
- 間隔のフレームグラフは、リンクステータスに関係なく、常に「所有チャート」間隔にズームされます。
- ズームイン/アウトすることができます:
- ズームイン:チャート領域で垂直にマウスホイール。チャートは、チャートの中央にある時間にズームします。
- 私のラップトップでは、これはタッチパッドで2本の指を垂直にスクロールしています
- ズームイン:チャートをクリックしてマウスを右にドラッグしてマウスを解放します(チャートは選択した間隔にズームします)
- ズームアウト:チャートをクリックしてマウスを左にドラッグし、マウスを解放すると、選択したチャートの量に反比例してズームアウトします。つまり、チャート領域全体をドラッグしたままにした場合、チャートは2倍にズームアウトします。小さな間隔をドラッグしたままにした場合、チャートは〜からズームアウトします。
- ズームアウト:私のラップトップで、ズームの反対方向にタッチパッド2フィンガーの垂直スクロールをします
- カーソルがどこにあるかに注意する必要があります...チャートのリストをスクロールすることを意味する場合、誤ってチャートをズームすることができます。だから、私は通常、チャートをスクロールしたいときに画面の左端にカーソルを置きます。
パン
- 私のラップトップでは、これはタッチパッドの水平スクロールモーションで2本の指を行っています
- チャートの下のサムネイルに緑色の箱を使用する
- ズームレベルでのパンニングは機能します
- フルチャートの「サムネイル」画像は、各チャートの下にカーソルを使用してサムネイルに沿ってスライドするため、ズーム/パンをしているときにチャートをナビゲートできます。
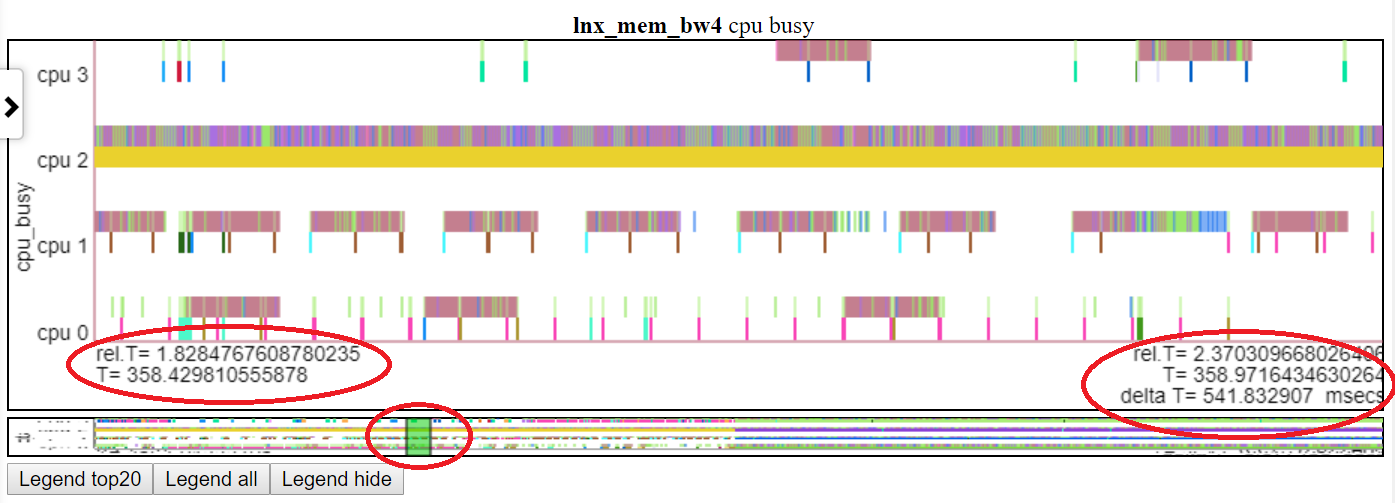
- 以下は、「CPU Busy」チャートをt = 1.8-2.37秒にパンすることを示しています。相対的な時間と絶対開始時間は、左の赤い楕円形で蛍光重要です。終了時間は、右側の赤い楕円形で強調表示されます。サムネイルの相対的な位置は、中央の赤い楕円形によって示されています。
 。
。
チャートの伝説的なエントリにホバリングすると、その線が強調されています。
- 以下は、「PKG」(パッケージ)の電源が強調表示されるスクリーンショットです
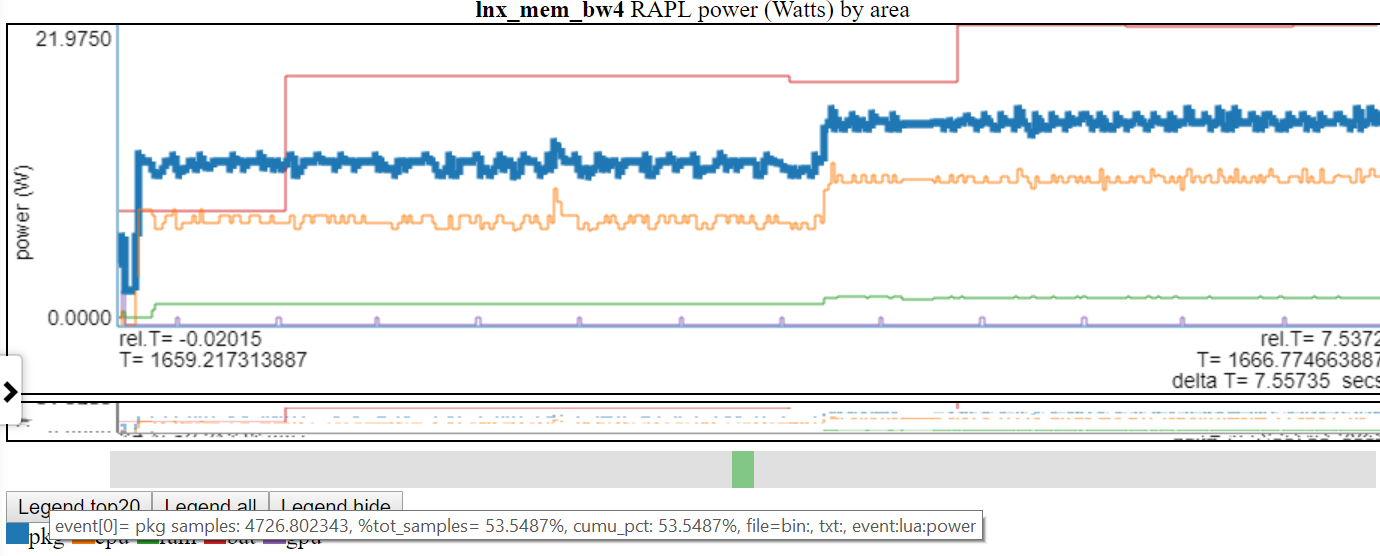
チャートの伝説的なエントリをクリックすると、そのラインの可視性が切り替えられます。
レジェンドエントリをダブルクリックすると、そのエントリのみが表示/非表示になります
- 以下は、「PKG」電源がダブルクリックされたため、PKGラインのみが表示されるスクリーンショットです。
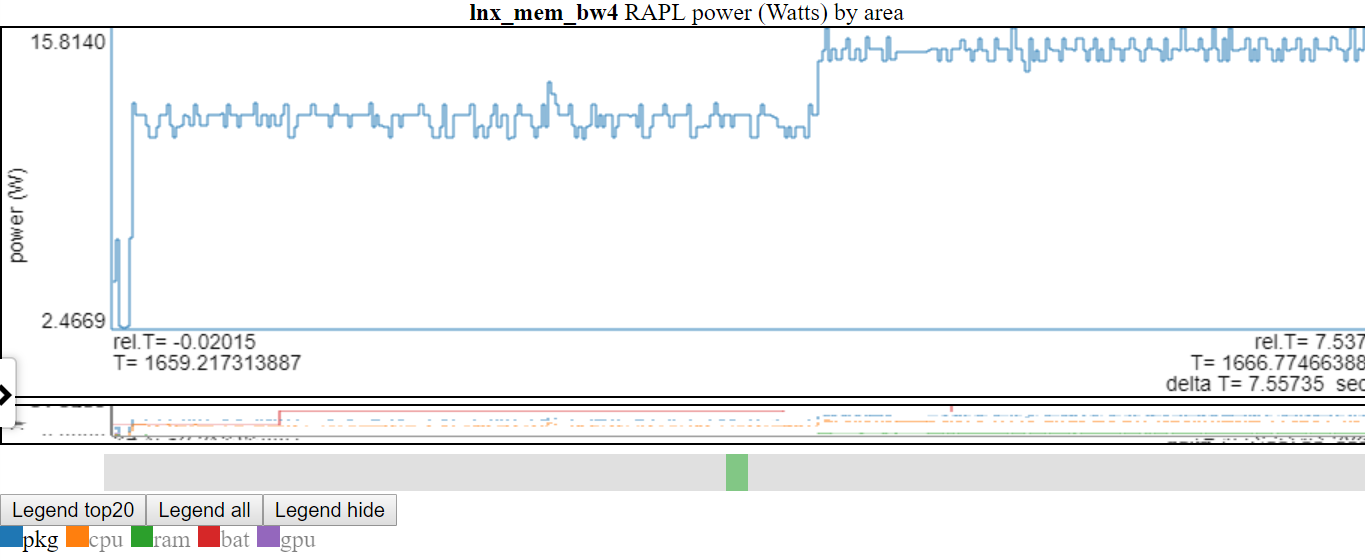
- 上記は、y軸が表示された変数のmin/maxに調整されます。 「表示されていない」行は、伝説では灰色になります。伝説の「表示されていない」行の上にホバリングすると、描かれます(伝説のアイテムにホバリングしている間)。 「非剃られていない」凡例エントリをダブルクリックすることで、すべてのアイテムを再度表示することができます。これにより、すべての「表示されていない」行が表示されますが、クリックしたラインから切り替えます...したがって、ダブルクリックしたアイテムをシングルクリックします。私はそれが混乱しているように聞こえることを知っています。
凡例のエントリが隠されていて、その上に浮かんでいる場合、ホバリングするまで表示されます
チャートタイプ:
OPPATのデータ収集
パフォーマンスとパワーデータの収集は非常に「状況」です。ある人はスクリプトを実行したいと思う人がいます。別の人はボタンで測定を開始し、ビデオを開始してからボタンを押すとコレクションを終了したいと思うでしょう。 Windows用のスクリプトとLinux用のスクリプトがあります。
- データ収集の開始、
- ワークロードを実行し、
- データ収集を停止します
- データを後処理します(PERF/XPERF/TRACE-CMDバイナリデータからテキストファイルの作成)
- すべてのデータファイルを出力監督に配置します
- 出力dirでfile_list.jsonファイルを作成する(出力ファイルの名前とタイプをoppatに伝える)
スクリプトを使用したデータ収集の手順:
- spin.exe(spin.x)とwait.exe(wait.x)ユーティリティをビルドします
- Oppat Root dirから:
- Linuxで:
./mk_spin.sh - windows:
.mk_spin.bat (ビジュアルスタジオCMDボックスから) - バイナリは./bin Subdirに入れられます
- 提供されたスクリプトの実行から始めます:
- run_perf_x86_haswell.sh -Haswell CPU_Diagramデータ収集のため
- Linuxで、タイプ:
sudo bash ./scripts/run_perf.sh - デフォルトでは、スクリプトはデータをdir ../oppat_data/lnx/mem_bw7に配置します
- run_perf.sh-トレースCMDとパフォーマンスをインストールする必要があります
- Linuxで、タイプ:
sudo bash ./scripts/run_perf.sh - デフォルトでは、スクリプトはデータをdir ../oppat_data/lnx/mem_bw4に配置します
- run_xperf.bat- xperf.exeをインストールする必要があります。
- Windowsで、管理者特権を備えたCMDボックスから、タイプ:
.scriptsrun_xperf.sh - デフォルトでは、スクリプトはデータをdirにします。 oppat_data win mem_bw4
- デフォルトを変更する場合は、実行スクリプトを編集します
- データファイルに加えて、実行スクリプトは出力dirにfile_list.jsonファイルを作成します。 OPPATは、file_list.jsonファイルを使用して、出力dir内のファイルとファイルのタイプを把握します。
- 実行スクリプトの「ワークロード」はSpin.x(またはSpin.exe)で、1 CPUで4秒間、すべてのCPUでさらに4秒間メモリ帯域幅テストを行います。
- 別のプログラムwait.x/wait.exeもバックグラウンドで開始されます。 wait.cpp私のラップトップのバッテリー情報を読み取ります。デュアルブートWindows 10/Linux Ubuntuラップトップで動作します。 SYSFSファイルはLinuxに異なる名前が付いている可能性があり、Androidではほぼ確実に異なります。
- Linuxでは、おそらくrun_perf.shと同じ構文を使用してprf_trace.dataおよびprf_trace.txtファイルを生成するだけですが、これを試していません。
- ラップトップで実行していて、バッテリーの電源を取得したい場合は、スクリプトを実行する前に電源ケーブルを切断することを忘れないでください。
PCMデータサポート
- OPPATは、PCM .CSVファイルを読み取り、チャートできます。
- 以下は、作成されたチャートのリストのスナップショットです。
- 残念ながら、PCMにパッチを実行して、OPPATを処理するための絶対的なタイムスタンプを備えたファイルを作成する必要があります。
- これは、PCM CSVファイルに他のデータソースと相関するために使用できるタイムスタンプがないためです。
- ここにパッチを追加しましたPCMパッチを追加しました
オッパットを建設します
- Linuxでは、Oppat Root dirを入力
make- すべてが機能する場合は、bin/oppat.xファイルがあるはずです
- Windowsでは、次のことが必要です。
- GNU MakeのWindowsバージョンをインストールします。 http://gnuwin32.sourceforge.net/packages/make.htmをご覧
- この新しい「make」バイナリをパスに入れます
- 現在のVisual Studio 2015または2017 C/C ++コンパイラが必要です(VS 2015 ProfessionalとVS 2017コミュニティコンパイラの両方を使用しました)
- Windows Visual Studio X64ネイティブCMDプロンプトボックスを開始する
- oppatルート監督を
make - すべてが機能する場合は、bin oppat.exeファイルがあるはずです
- ソースコードを変更している場合は、おそらくインクルード依存関係ファイルを再構築する必要があります
- Perlをインストールする必要があります
- Linuxでは、Oppat root dir:
./mk_depends.sh 。これにより、Depend_lnx.mk依存関係ファイルが作成されます。 - on Windows, in the OPPAT root dir do:
.mk_depends.bat . This will create a depends_win.mk dependency file.
- If you are going to run the sample run_perf.sh or run_xperf.bat scripts, then you need to build the spin and wait utilities:
- On Linux:
./mk_spin.sh - On Windows:
.mk_spin.bat
Running OPPAT
- Run the data collection steps above
- now you have data files in a dir (if you ran the default run_* scripts:
- on Windows ..oppat_datawinmem_bw4
- on Linux ../oppat_data/lnx/mem_bw4
- You need to add the created files to the input_filesinput_data_files.json file:
- Starting OPPAT reads all the data files and starts the web server
- on Windows to generate the haswell cpu_diagram (assuming your data dir is ..oppat_datalnxmem_bw7)
binoppat.exe -r ..oppat_datalnxmem_bw7 --cpu_diagram webhaswell_block_diagram.svg > tmp.txt
- on Windows (assuming your data dir is ..oppat_datawinmem_bw4)
binoppat.exe -r ..oppat_datawinmem_bw4 > tmp.txt
- on Linux (assuming your data dir is ../oppat_data/lnx/mem_bw4)
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 > tmp.txt
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 --web_file tst2.html > tmp.txt
- Then you can load the file into the browser with the URL address:
file:///C:/some_path/oppat/tst2.html
Derived Events
'Derived events' are new events created from 1 or more events in a data file.
- Say you want to use the ETW Win32k InputDeviceRead events to track when the user is typing or moving the mouse.
- ETW has 2 events:
- Microsoft-Windows-Win32k/InputDeviceRead/win:Start
- Microsoft-Windows-Win32k/InputDeviceRead/win:Stop
- So with the 2 above events we know when the system started reading input and we know when it stopped reading input
- But OPPAT plots just 1 event per chart (usually... the cpu_busy chart is different)
- We need a new event that marks the end of the InputDeviceRead and the duration of the event
- The derived event needs:
- a new event name (in chart.json... see for example the InputDeviceRead event)
- a LUA file and routine in src_lua subdir
- 1 or more 'used events' from which the new event is derived
- the derived events have to be in the same file
- For the InputDeviceRead example, the 2 Win32k InputDeviceRead Start/Stop events above are used.
- The 'used events' are passed to the LUA file/routine (along with the column headers for the 'used events') as the events are encountered in the input trace file
- In the InputDeviceRead lua script:
- the script records the timestamp and process/pid/tid of a 'start' event
- when the script gets a matching 'Stop' event (matching on process/pid/tid), the script computes a duration for the new event and passes it back to OPPAT
- A 'trigger event' is defined in chart.json and if the current event is the 'trigger event' then (after calling the lua script) the new event is emitted with the new data field(s) from the lua script.
- An alternate to the 'trigger event' method is to have the lua script indicate whether or not it is time to write the new event. For instance, the scr_lua/prf_CPI.lua script writes a '1' to a variable named ' EMIT ' to indicate that the new CPI event should be written.
- The new event will have:
- the name (from the chart.json evt_name field)
- The data from the trigger event (except the event name and the new fields (appended)
- I have tested this on ETW data and for perf/trace-cmd data
Using the browser GUI Interface
TBD
Defining events and charts in charts.json
TBD
Rules for input_data_files.json
- The file 'input_files/input_data_files.json' can be used to maintain a big list of all the data directories you have created.
- You can then select the directory by just specifying the file_tag like:
- bin/oppat.x -u lnx_mem_bw4 > tmp.txt # assuming there is a file_tag 'lnx_mem_bw4' in the json file.
- The big json file requires you to copy the part of the data dir's file_list.json into input_data_files.json
- in the file_list.json file you will see lines like:
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- don't copy the lines like below from the file_list.json file:
- paste the copied lines into input_data_files.json. Pay attention to where you paste the lines. If you are pasting the lines at the top of input_data_files.json (after the
{"root_dir":"/data/ppat/"}, then you need add a ',' after the last pasted line or else JSON will complain. - for Windows data files add an entry like below to the input_filesinput_data_files.json file:
- yes, use forward slashes:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- for Linux data files add an entry like below to the input_filesinput_data_files.json file:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/lnx/mem_bw4 " },
{ "cur_tag" : " lnx_mem_bw4 " },
{ "bin_file" : " prf_energy.txt " , "txt_file" : " prf_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " },
{ "bin_file" : " prf_trace.data " , "txt_file" : " prf_trace.txt " , "tag" : " %cur_tag% " , "type" : " PERF " },
{ "bin_file" : " tc_trace.dat " , "txt_file" : " tc_trace.txt " , "tag" : " %cur_tag% " , "type" : " TRACE_CMD " },- Unfortunately you have to pay attention to proper JSON syntax (such as trailing ','s)
- Here is an explanation of the fields:
- The 'root_dir' field only needs to entered once in the json file.
- It can be overridden on the oppat cmd line line with the
-r root_dir_path option - If you use the
-r root_dir_path option it is as if you had set "root_dir":"root_dir_path" in the json file - the 'root_dir' field has to be on a line by itself.
- The cur_dir field applies to all the files after the cur_dir line (until the next cur_dir line)
- the '%root_dir% string in the cur_dir field is replaced with the current value of 'root_dir'.
- the 'cur_dir' field has to be on a line by itself.
- the 'cur_tag' field is a text string used to group the files together. The cur_tag field will be used to replace the 'tag' field on each subsequent line.
- the 'cur_tag' field has to be on a line by itself.
- For now there are four types of data files indicated by the 'type' field:
- type:PERF These are Linux perf files. OPPAT currently requires both the binary data file (the bin_file field) created by the
perf record cmd and the perf script text file (the txt_file field). - type:TRACE_CMD These are Linux trace-cmd files. OPPAT currently requires both the binary dat file (the bin_file field) created by the
trace-cmd record cmd and the trace-cmd report text file (the txt_file field). - type:ETW These are Windows ETW xperf data files. OPPAT currently requires only the text file (I can't read the binary file). The txt_file is created with
xperf ... -a dumper command. - type:LUA These files are all text files which will be read by the src_lua/test_01.lua script and converted to OPPAT data.
- the 'prf_energy.txt' file is
perf stat output with Intel RAPL energy data and memory bandwidth data. - the 'prf_energy2.txt' file is created by the wait utility and contains battery usage data in the 'perf stat' format.
- the 'wait.txt' file is created by the wait utility and shows the timestamp when the wait utility began
- Unfortunately 'perf stat' doesn't report a high resolution timestamp for the 'perf stat' start time
制限
- The data is not reduced on the back-end so every event is sent to the browser... this can be a ton of data and overwhelm the browsers memory
- I probably should have some data reduction logic but I wanted to get feedback first
- You can clip the files to a time range:
oppat.exe -b abs_beg_time -e abs_beg_time to reduce the amout of data- This is a sort of crude mechanism right now. I just check the timestamp of the sample and discard it if the timestamp is outside the interval. If the sample has a duration it might actually have data for the selected interval...
- There are many cases where you want to see each event as opposed to averages of events.
- On my laptop (with 4 CPUs), running for 10 seconds of data collection runs fine.
- Servers with lots of CPUs or running for a long time will probably blow up OPPAT currently.
- The stacked chart can cause lots of data to be sent due to how it each event on one line is now stacked on every other line.
- Limited mechanism for a chart that needs more than 1 event on a chart...
- say for computing CPI (cycles per instruction).
- Or where you have one event that marks the 'start' of some action and another event that marks the 'end' of the action
- There is a 'derived events' logic that lets you create a new event from 1 or more other events
- See the derived event section
- The user has to supply or install the data collection software:
- on Windows xperf
- See https://docs.microsoft.com/en-us/windows-hardware/get-started/adk-install
- You don't need to install the whole ADK... the 'select the parts you want to install' will let you select just the performance tools
- on Linux perf and/or trace-cmd
sudo apt-get install linux-tools-common linux-tools-generic linux-tools- ` uname -r `
- For trace-cmd, see https://github.com/rostedt/trace-cmd
- You can do (AFAIK) everything in 'perf' as you can in 'trace-cmd' but I have found trace-cmd has little overhead... perhaps because trace-cmd only supports tracepoints whereas perf supports tracepoints, sampling, callstacks and more.
- Currently for perf and trace-cmd data, you have to give OPPAT both the binary data file and the post-processed text file.
- Having some of the data come from the binary file speeds things up and is more reliable.
- But I don't want to the symbol handling and I can't really do the post-processing of the binary data. Near as I can tell you have to be part of the kernel to do the post processing.
- OPPAT requires certain clocks and a certain syntax of 'convert to text' for perf and trace-cmd data.
- OPPAT requires clock_monotonic so that different file timestamps can be correlated.
- When converting the binary data to text (trace-cmd report or 'perf script') OPPAT needs the timestamp to be in nanoseconds.
- see scriptsrun_xperf.bat and scriptsrun_perf.sh for the required syntax
- given that there might be so many files to read (for example, run_perf.sh generates 7 input files), it is kind of a pain to add these files to the json file input_filesinput_data_files.json.
- the run_xperf.bat and run_perf.sh generate a file_list.json in the output directory.
- perf has so, so many options... I'm sure it is easy to generate some data which will break OPPAT
- The most obvious way to break OPPAT is to generate too much data (causing browser to run out of memory). I'll probably handle this case better later but for this release (v0.1.0), I just try to not generate too much data.
- For perf I've tested:
- sampling hardware events (like cycles, instructions, ref-cycles) and callstacks for same
- software events (cpu-clock) and callstacks for same
- tracepoints (sched_switch and a bunch of others) with/without callstacks
- Zooming Using touchpad scroll on Firefox seems to not work as well it works on Chrome
 。
。 。
。