Ferramenta de Análise de Power/Desempenho de Power/Desempenho (OPPAT)
Índice
- Introdução
- Tipos de dados suportados
- Visualização oppat
- Recursos do gráfico
- Tipos de gráficos
- Coleção de dados para oppat
- Suporte de dados PCM
- Construindo Oppat
- Correndo oppat
- Eventos derivados
- Usando a interface GUI Browswer
- Limitações
Introdução
A Ferramenta de Análise de Potência/Desempenho Open (OPPAT) é uma ferramenta Cross-OS, Cross-Architecture Power and Performance Analysis.
- Cross-OS: suporta arquivos de rastreamento do Windows ETW e arquivos Linux/Android Perf/Trace-CMD Trace
- Arquitetura cruzada: suporta eventos de hardware Intel e Arm Chips (usando perf e/ou PCM)
A página da web do projeto é https://patinnc.github.io
O repo de código -fonte é https://github.com/patinnc/oppat
Adicionei um sistema operacional (OS_View) ao recurso de diagrama de blocos da CPU. Isso baseado nas páginas de Brendan Gregg, como http://www.brendangregg.com/linuxperf.html. Aqui estão alguns dados de exemplo para executar uma versão antiga do Geekbench v2.4.2 (código de 32 bits) no braço 64bit ubuntu mate v18.04.2 Raspberry Pi 3 B+, 4 córtex A53 CPUS:
- Um vídeo das alterações no diagrama de blocos OS_VIEW e ARM A53 CPU em execução de geekbench:
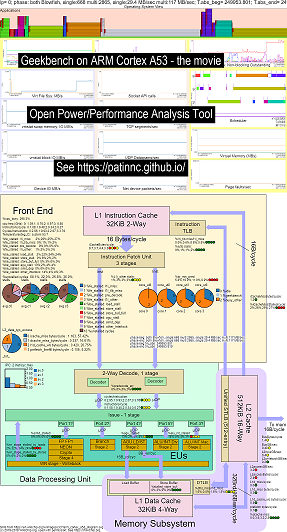
- Existem alguns slides introdutórios para tentar explicar o layout OS_VIEW e CPU_DIAGRAM e, em seguida, 1 slide mostrando os resultados de cada um dos 30 subtestes
- Um arquivo do Excel dos dados no filme: Excel File de Geekbench The Movie
- O HTML dos dados do filme ... consulte Geekbench v2.4.2 no 4 Core Arm Cortext A53 com OS_View, diagrama da CPU.
- O png do painel para todas as 30 fases classificadas aumentando as instruções/s ... consulte o Arm Cortex A53 Raspberry Pi 3 com o painel de chip de lascas de 4 núcleos da CPU, com geekbench.
Aqui estão alguns dados de exemplo para executar meu referência de spin (testes de largura de banda de memória/cache, um teste de keep-busy 'spin') no Raspberry Pi 3 B+ (Cortex A53) CPUS:
- Um vídeo das alterações no diagrama de blocos OS_VIEW e ARM A53 CPU em execução de giro:
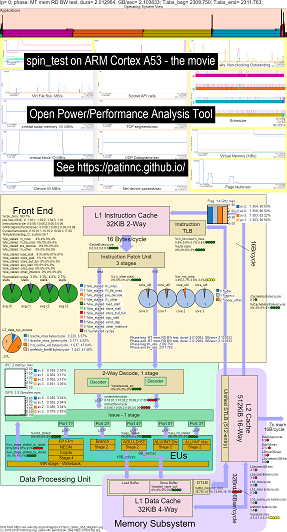
- Existem alguns slides introdutórios para tentar explicar os gráficos OS_VIEW e o layout CPU_DIAGRAM, um slide mostrando em que horário (em segundos) cada subestino está sendo exibido (para que você possa ir para t = x scs para ir diretamente para esse subesto) e, em seguida, um slide para cada um dos 5 subtesteses
- Um arquivo do Excel dos dados no filme: Excel File de Geekbench The Movie
- O HTML dos dados do filme ... consulte o ARM Cortex A53 Raspberry Pi 3 com o diagrama de CPU 4 núcleos com referência de spin.
- O painel PNG para todas as 5 fases classificadas aumentando as instruções/seg ... consulte o Arm Cortex A53 Raspberry Pi 3 com o painel de chips com diagrama de 4 núcleos da CPU executando o referência de spin.
Aqui estão alguns dados de exemplo para executar o Geekbench nas CPUs Haswell:
- Um vídeo das alterações no diagrama de blocos OS_View e Haswell CPU em execução de geekbench:
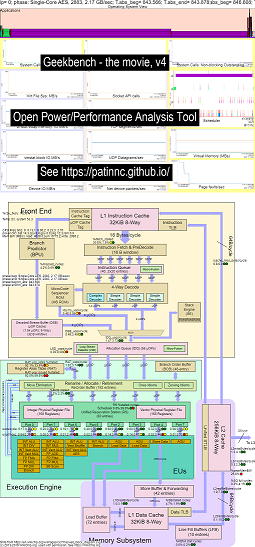
- Existem alguns slides introdutórios para tentar explicar os gráficos OS_VIEW e o layout CPU_DIAGRAM, um slide mostrando em que horário (em segundos) cada subestino está sendo exibido (para que você possa ir para T = X scs para ir diretamente para esse subesto) e, em seguida, um slide para cada um dos 50 subtesteses
- Um arquivo do Excel dos dados no filme: Excel File de Geekbench The Movie
- O HTML dos dados do filme ... veja Intel Haswell com o diagrama de CPU 4 CPU Chip Running Geekbench.
- O png do painel para todas as 50 fases classificadas aumentando o UOPS aposentado/s ... Veja o painel Intel Haswell com o painel de chips de diagrama de 4 núcleos da CPU executando o GeekBench.
Aqui estão alguns dados para executar meu benchmark 'spin' com 4 sub-testes nas CPUs Haswell:
- O 1º Subteste é um teste de largura de banda de memória leitura. O bloco L2/L3/memória é altamente usado e paralisado durante o teste. O rato UOPS/ciclo é baixo, pois o rato é paralisado.
- O segundo subteste é um teste de largura de banda de leitura L3. A memória BW agora está baixa. O bloco L2 & L3 é altamente utilizado e paralisado durante o teste. O rato UOPS/ciclo é maior à medida que o rato é menos paralisado.
- O terceiro subteste é um teste de largura de banda de leitura L2. O L3 e a memória BW agora estão baixos. O bloco L2 é altamente utilizado e paralisado durante o teste. O rato UOPS/ciclo é ainda maior, pois o rato é ainda menos paralisado.
- O 4º subteste é um teste de spin (apenas um loop adicional). O L2, L3 e a memória BW estão perto de zero. O Rat UOPS/Cycle é de cerca de 3,3 UOPS/ciclo, que está se aproximando do 4 UOPS/ciclo máximo possível.
- Um vídeo das alterações no diagrama de blocos da CPU Haswell em execução 'Spin' com a análise. Ver
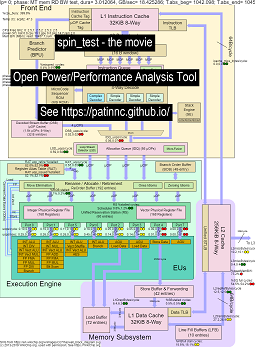
- Um arquivo do Excel dos dados no filme: Excel File from Spin the Movie
- O HTML dos dados do filme ... veja Intel Haswell com o diagrama de CPU 4 CPU Chip executando a referência de spin.
A Intel Haswell com as coleções de dados do diagrama CPU é para um arquivo Intel de 4 CPU, arquivo Linux OS, HTML com mais de 50 eventos HW por meio de amostragem de perf e outros dados coletados. Recursos CPU_DIAGRAM:
- Comece com um diagrama de blocos SVG do wikichip.org (usado com permissão),
- Veja as restrições de recursos (como Max BW, Max bytes/ciclo em vários caminhos, ciclos mínimos/UOP, etc.),
- calcular métricas para o uso de recursos
- Abaixo está uma tabela de um teste de largura de banda de leitura de memória que exibe as informações de uso de recursos em uma tabela (juntamente com uma estimativa de se a CPU está paralisada devido ao uso). A tabela HTML (mas não o PNG) tem informações pop -up quando você passa o mouse sobre os campos. A tabela mostra que:
- O núcleo é paralisado na largura de banda da memória com 55% do máximo possível de 25,9 GB/s. É um teste de memória BW
- O Superqueue (Sq) está cheio (54,5% para Core0 e 62,3% Core1) dos ciclos (para que mais solicitações L2 não possam ser tratadas)
- O buffer de preenchimento de linha FB está cheio (30% e 51%) para que as linhas não possam ser movidas para L1D de L2
- O resultado é que o back -end é paralisado (88% e 87%) dos ciclos que nenhum UOPS é aposentado.
- Os UOPs parecem estar provenientes do detector de fluxo de loop (já que os ciclos LSD/UOP são aproximadamente os mesmos que o rato UOPS/Cycle.
- Uma captura de tela da tabela de memória do diagrama da CPU Haswell
- Abaixo está uma tabela de um teste de largura de banda de leitura L3.
- Agora, a memória BW e o L3 Miss Bytes/Cycle são cerca de zero.
- O SQ é menos paralisado (já que não estamos esperando pela memória).
- L2 Bytes/ciclos de transações são cerca de 2x mais altos e cerca de 67% do máximo possível 64 bytes/ciclo.
- O UOPS_RETIRIEND_STALLS/CYCLE caiu para 66% da barraca de teste do MEM BW de 88%.
- As barracas de buffer de preenchimento agora são mais de 2x mais altas. Os UOPs ainda vêm do LSD.
- Uma captura de tela do diagrama da CPU Haswell L3 BW Table
- Abaixo está uma tabela de um teste de largura de banda de leitura L2.
- O L2 erra bytes/ciclo é muito menor que o teste L3.
- O% de% do UOPS_RETIREDIDED está agora cerca de metade do teste L3 a 34% e as barracas do FB também são de cerca de 17%.
- Os UOPs ainda vêm do LSD.
- Uma captura de tela do diagrama da CPU Haswell L2 BW Table
- Abaixo está uma tabela de um teste de rotação (sem cargas, basta adicionar um loop).
- Agora, existem apenas zero barracas de subsistema de memória.
- Os UOPs estão provenientes do buffer de fluxo de decodes (DSB).
- RAT APRIED_UOPS/CICLO A 3,31 CICLOS/UOP está perto do máximo possível de 4,0 UOPS/ciclo.
- O rato aposentado_uops %paralisado é bastante baixo em %8.
- Uma captura de tela da mesa de rotação do diagrama de Haswell CPU
Atualmente, só tenho filmes CPU_DIAGRAM para Haswell e ARM A53 (já que não tenho outros sistemas para testar), mas não deve ser difícil adicionar outros diagramas de bloco. Você ainda recebe todos os gráficos, mas não o CPU_DIAGRAM.
Abaixo está um dos gráficos oppat. O gráfico 'cpu_busy' mostra o que está sendo executado em cada CPU e os eventos que acontecem em cada CPU. Por exemplo, o círculo verde mostra um fio spin.x em execução na CPU 1. O círculo vermelho mostra alguns dos eventos que ocorrem no CPU1. Este gráfico é modelado após o gráfico Kernelshark do Trace-CMD. Mais informações sobre o gráfico CPU_BUSY estão na seção Tipo de gráfico. A caixa de envio mostra os dados do evento (incluindo callstack (se houver)) para o evento sob o cursor. Infelizmente, a captura de tela do Windows não captura o cursor. 
Aqui estão alguns arquivos HTML de amostra. A maioria dos arquivos é para um intervalo mais curto de ~ 2, mas alguns são 'completos' de 8 segundos. Os arquivos não serão carregados diretamente do repositório, mas serão carregados na página da web do projeto: https://patinnc.github.io
- Intel Haswell com diagrama de CPU Chip 4-CPU Chip, Linux OS, arquivo HTML com mais de 50 eventos HW via amostragem de perf ou
- Intel 4-CPU Chip, Windows OS, arquivo HTML com 1 HW eventos via amostragem XPERF ou
- Full ~ 8 segundos Intel 4-CPU Chip, Windows OS, arquivo HTML com amostragem PCM e XPERF ou
- Intel 4-CPU Chip, Linux OS, arquivo HTML com 10 eventos HW em 2 grupos multiplexados.
- Chip ARM (Broadcom A53), arquivo HTML Linux Raspberry PI3 com 14 eventos HW (para CPI, L2 Miss, Mem BW etc em 2 grupos multiplexados).
- 11 MB, versão completa do chip acima do ARM (Broadcom A53), arquivo html linux Raspberry PI3 com 14 eventos HW (para CPI, L2 Miss, Mem BW etc em 2 grupos multiplexados).
Alguns dos arquivos acima são intervalos de ~ 2 segundos extraídos de ~ 8 segundos de longa execução. Aqui está a corrida completa de 8 segundos:
- A amostra completa de 8 segundos Linux Run HTML comprimido aqui para um arquivo mais completo. O arquivo faz um JavaScript Zlib descompacte os dados do gráfico para que você veja mensagens pedindo que você espere (cerca de 20 segundos) durante o descompacte.
Dados oppat suportados
- Linux Perf e/ou Arquivos de desempenho de Trace-CMD (arquivos binários e de texto),
- Percepção de status de perf que também aceito
- Dados Intel PCM,
- Outros dados (importados usando scripts Lua),
- Portanto, isso deve funcionar com dados de Linux ou Android regular
- Atualmente para os dados do Perf e Trace-CMD, o OPPAT requer os arquivos de texto binários e pós-processados e existem algumas restrições na linha de comando 'registro' e na linha de comando 'script/trace-cmd' perf.
- Oppat poderia ser feito para usar apenas os arquivos de saída de texto perf/rastreio-cmd, mas atualmente os arquivos binários e de texto são necessários
- Dados do Windows ETW (coletados por XPERF e despejados no texto) ou dados Intel PCM,
- Dados arbitrários de energia ou desempenho suportados usando scripts Lua (para que você não precise recompilar o código C ++ para importar outros dados (a menos que o desempenho da Lua se torne um problema))
- Leia os arquivos de dados no Linux ou Windows, independentemente de onde os arquivos se originaram (então leia os arquivos perf/rastreio-cmd nos arquivos de texto do Windows ou ETW no Linux)
Visualização oppat
Aqui estão alguns arquivos HTML de Visualização de amostra completos: Arquivo HTML do Windows Sample ou este arquivo html de amostra Linux. Se você estiver no repo (não no site do projeto Github.io), precisará baixar o arquivo e carregá -lo no seu navegador. Estes são arquivos da Web independentes criados pelo Oppat, que podem ser, por exemplo, enviados por e -mail a outras pessoas ou (como aqui) publicado em um servidor da Web.
O Oppat Viz funciona melhor no Chrome do que no Firefox principalmente porque o zoom usando rolagem de dedos do Touchpad 2 funciona melhor no Chrome.
Oppat tem 3 modos de visualização:
- O mecanismo de gráfico usual (onde o back -end da Oppat lê os arquivos de dados e envia dados para o navegador)
- Você também pode criar uma página da Web independente, que é o equivalente ao 'mecanismo regular do gráfico', mas pode ser trocado com outros usuários ... A página da Web independente tem todos os scripts e dados embutidos para que possam ser enviados por e-mail a alguém e eles podem carregá-lo no navegador. Consulte os arquivos html em sample_html_files mencionados acima e (para uma versão mais longa de lnx_mem_bw4), consulte o arquivo compactado amostra_html_files/lnx_mem_bw4_full.html
- Você pode '--salvar' um arquivo json de dados e depois-carregar o arquivo posteriormente. O arquivo JSON salvo é os dados que o Oppat precisa enviar para o navegador. Isso evita reler os arquivos de entrada Perf/XPerf, mas não receberá nenhuma alteração feita no gráfico.json. O arquivo HTML completo criado com a opção - -web_file é apenas um pouco maior que o arquivo - -save. O modo--save/-requer a construção de opções. Consulte os arquivos 'salvados' da amostra em Sample_Data_Json_Files Subdir.
Viz informações gerais
- Marcar todos os dados em um navegador (no Linux ou Windows)
- Os gráficos são definidos em um arquivo json para que você possa adicionar eventos e gráficos sem recompilar o Oppat
- A interface do navegador é como o Windows WPA (NavBar à esquerda).
- Abaixo mostra o marinho esquerdo (menu deslizante do lado esquerdo).
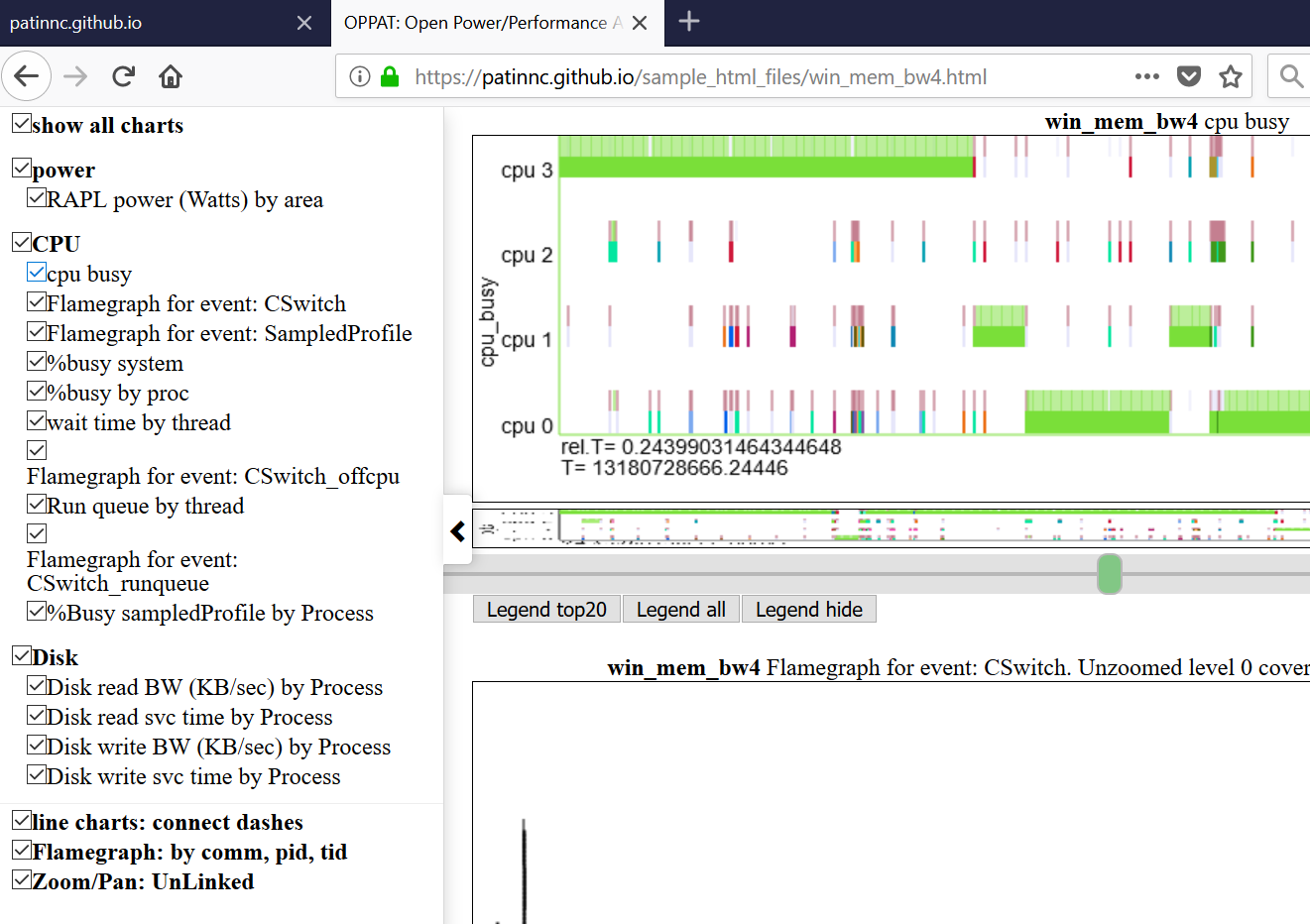
- Os gráficos são agrupados por categoria (GPU, CPU, Power, etc.)
- As categorias são definidas e atribuídas em input_files/gráficos.json
- Os gráficos podem ser todos ocultos ou seletivamente exibidos clicando no gráfico na barra de navegação.
- Passando sobre um título de gráfico no menu de navegação esquerda rolam esse gráfico em exibição
- Dados de um grupo de arquivos podem ser plotados ao lado de um grupo diferente
- Então você pode dizer, compare um desempenho de desempenho do Linux e um Windows ETW Run
- Abaixo do gráfico Mostrar Linux vs Windows Power Uso:
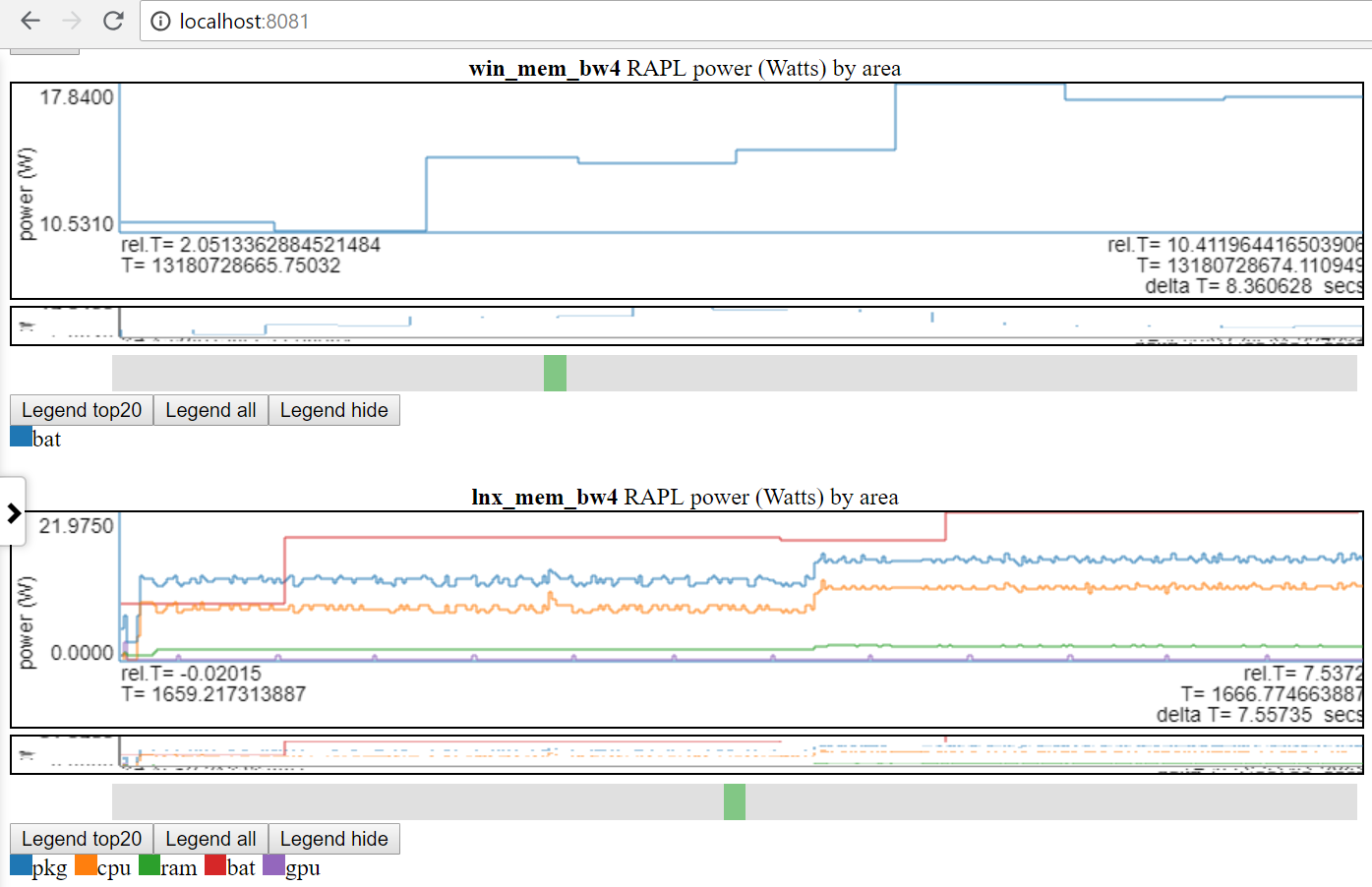
- Eu só tenho acesso à energia da bateria no Linux e no Windows.
- Muitos sites têm dados de energia muito melhores (tensões/correntes/energia na taxa MSEC (ou melhor)). Seria fácil incorporar esses tipos de dados de energia (como Kratos ou MDPs Qualcomm), mas não tenho acesso aos dados.
- ou compare 2 corridas diferentes na mesma plataforma
- Uma tag de grupo de arquivos (file_tag) é prefixada ao título para distinguir gráficos
- Uma 'tag' é definida no arquivo File_List.json do Data Dir e/ou input_files/input_data_files.json
- O input_files/input_data_files.json é uma lista de todos os dados do oppat Data (mas o usuário precisa mantê -lo).
- Os gráficos com o mesmo título são plotados um após o outro para permitir uma comparação fácil
Recursos do gráfico:
Passando sobre uma seção de uma linha do gráfico mostra o ponto de dados dessa linha nesse ponto
- Isso não funciona para as linhas verticais, pois elas estão apenas conectando 2 pontos ... apenas as peças horizontais de cada linha são pesquisadas para o valor dos dados
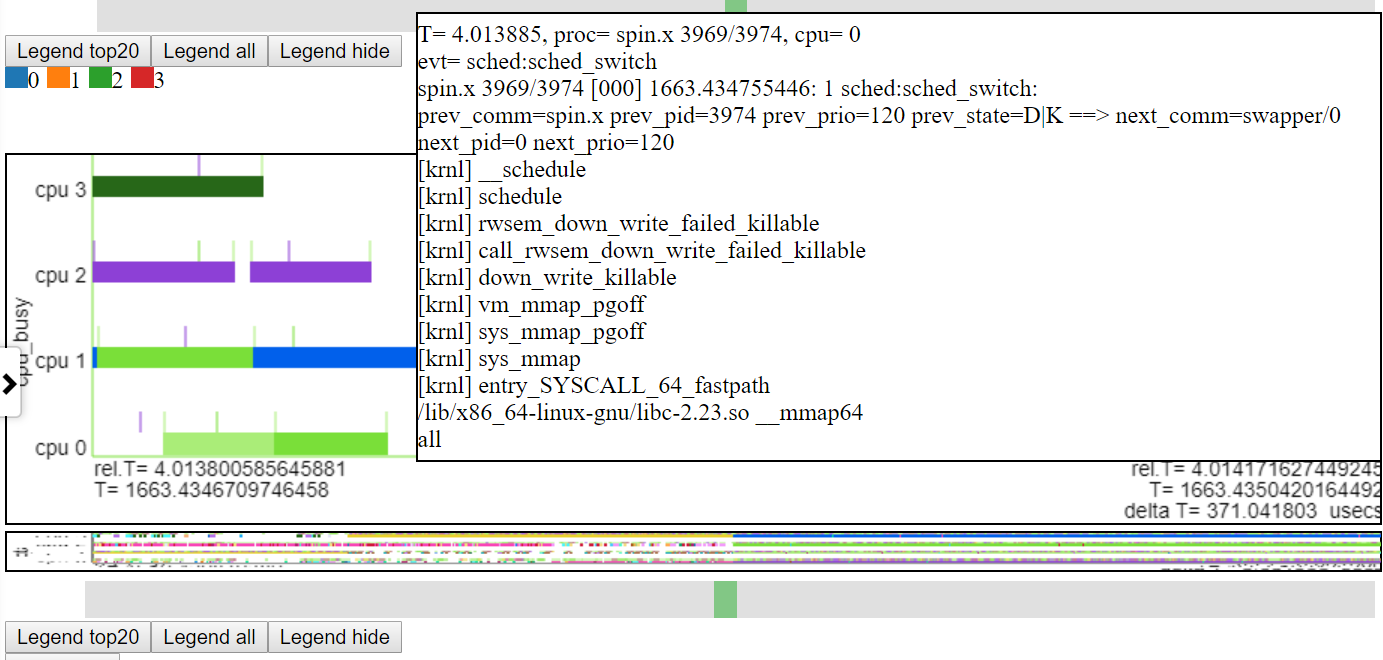
- Abaixo está uma captura de tela de um evento pairando sobre o evento. Isso mostra o tempo relativo do evento (cswtich), algumas informações como processo/pid/tid e o número da linha no arquivo de texto para que você possa obter mais informações.

- Abaixo está uma captura de tela mostrando as informações da história de call (se houver) para eventos.

zoom
- Zoom ilimitado entra no nível Nanosec e diminuindo o zoom.
- Provavelmente, existem ordens de magnitude mais pontos no enredo do que os pixels, para que mais dados sejam exibidos à medida que você aumenta.
- Abaixo está uma captura de tela mostrando o zoom para o nível de microssegundos. Isso mostra o evento CallStack for Sched_Switch, onde o spin.x é bloqueado através da operação de mapeamento de memória e ficando ocioso. O gráfico de 'CPU ocupado' mostra 'Indle' como em branco.
 .
.
- Os gráficos podem ser ampliados individualmente ou gráficos com o mesmo arquivo file_tag podem ser vinculados para que o gráfico de zoom/panning 1 altere o intervalo de todos os gráficos com o mesmo arquivo_tag
- Role até a parte inferior da barra naval esquerda e clique em 'Zoom/Pan: Unbinked'. Isso mudará o item de menu para 'Zoom/Pan: Linked'. Isso zoom/panela todos os gráficos em um grupo de arquivos para o tempo absoluto de zoom/pan mais recente. Isso levará algum tempo para redesenhar todos os gráficos.
- Inicialmente, cada gráfico é desenhado exibindo todos os dados disponíveis. Se seus gráficos forem de fontes diferentes, o T_BEGIN e o T_END (para gráficos de diferentes fontes) provavelmente serão diferentes.
- Depois que uma operação de zoom/pan é feita, tudo está em vigor, todos os gráficos do grupo de arquivos serão ampliados/pan para o mesmo intervalo absoluto.
- É por isso que o 'relógio' usado para cada fonte deve ser o mesmo.
- Oppat poderia traduzir de um relógio para outro (como entre gettime (clock_monotonic) e gettimeofday ()), mas essa lógica
- Quaisquer FlameGraphs para um intervalo são sempre ampliados para o intervalo 'possuindo os gráficos', independentemente do status de vinculação.
- Você pode aumentar o zoom dentro/fora de:
- Aumente o zoom: roda do mouse verticalmente na área do gráfico. O gráfico zoom no tempo no centro do gráfico.
- No meu laptop, isso está rolando 2 dedos verticalmente no touchpad
- Zoom In: Clicando no gráfico e arrastando o mouse para a direita e liberando o mouse (o gráfico aumentará o zoom para o intervalo selecionado)
- Zoom Out: Clique no gráfico e arrastando o mouse para a esquerda e liberando o mouse aumentará o zoom em uma espécie de inversamente proporcional à quantidade de gráfico que você selecionou. Ou seja, se você deixou o arrasto quase toda a área do gráfico, o gráfico voltará de volta ~ 2x. Se você acabou de deixar o arrastar um pequeno intervalo, o gráfico aumentará o zoom do caminho inteiro.
- Zoom fora: no meu laptop, fazendo um rolagem vertical de touchpad de 2 dedos na direção oposta do zoom
- Você deve ter cuidado onde está o cursor ... Você pode zoom inadvertidamente um gráfico quando pretende rolar a lista de gráficos. Por isso, geralmente coloco o cursor na borda esquerda da tela quando quero rolar os gráficos.
Panning
- No meu laptop, isso está fazendo 2 dedos no movimento de rolagem horizontal no touchpad
- Usando a caixa verde na miniatura abaixo do gráfico
- Panning funciona em qualquer nível de zoom
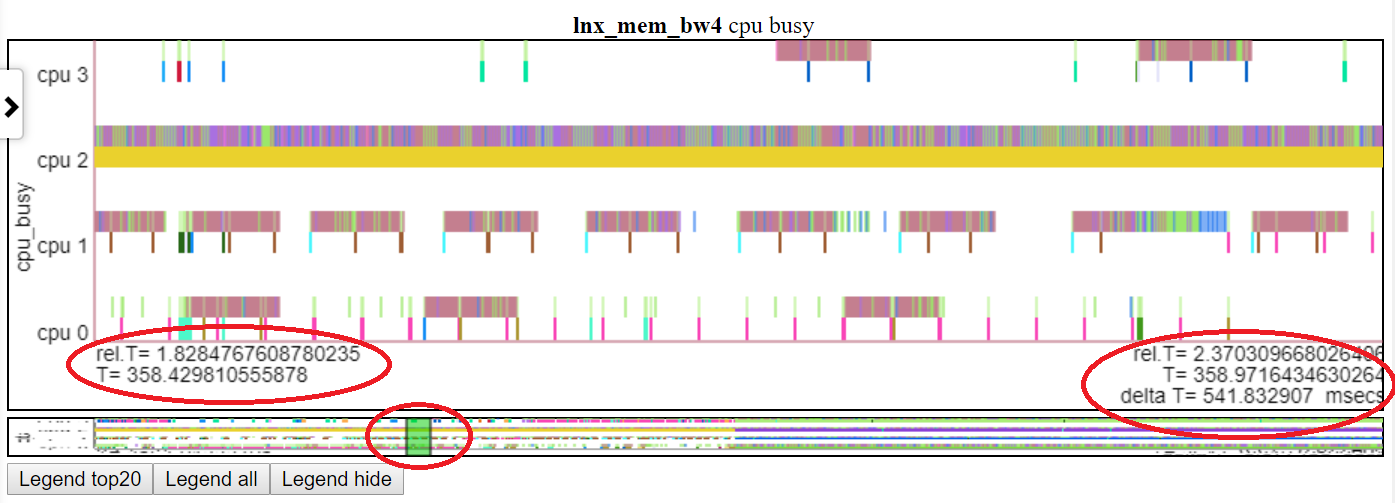
- Uma imagem de 'miniatura' do gráfico completa é colocada abaixo de cada gráfico com um cursor para deslizar ao longo da miniatura para que você possa navegar pelo gráfico quando estiver zoom/panning
- Abaixo mostra a panning do gráfico 'CPU ocupado' para t = 1,8-2,37 segundos. O tempo relativo e o tempo de início absoluto são marcados no oval vermelho esquerdo. O horário final é destacado no oval vermelho do lado direito. A posição relativa na miniatura é mostrada pelo oval vermelho médio.
 .
.
Passando em uma entrada de legenda do gráfico destaca essa linha.
- Abaixo está uma captura de tela onde 'PKG' (Package) Power é destacado
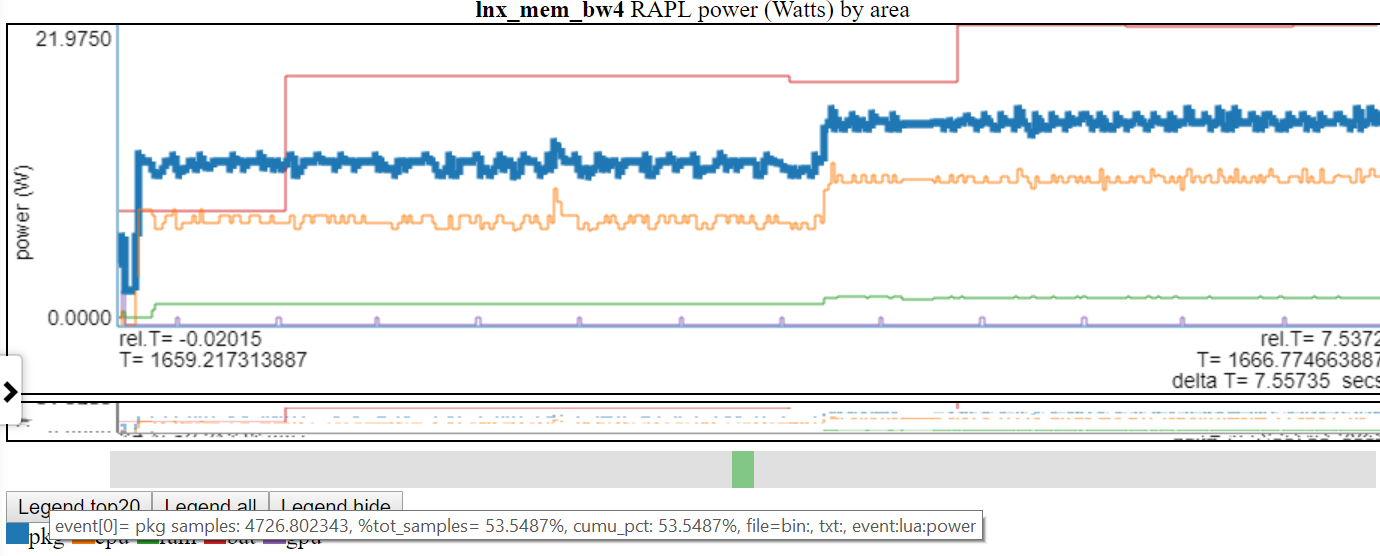
Clicar em uma entrada da legenda do gráfico alterna a visibilidade dessa linha.
Clicar duas vezes em uma entrada de legenda torna apenas essa entrada visível/oculta
- Abaixo está uma captura de tela em que a energia 'PKG' foi clicada duas vezes, então apenas a linha PKG está visível.
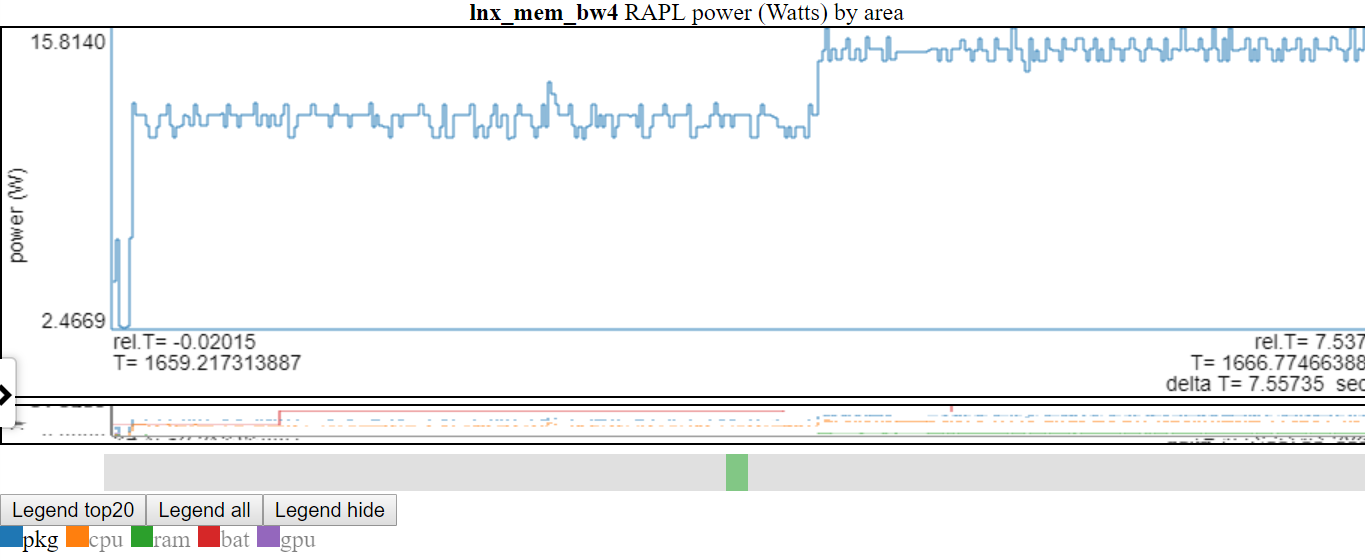
- Acima mostra que o eixo y é ajustado para min/max das variáveis exibidas (s). As linhas 'não mostradas' são acinzentadas na lenda. Se você passar o mouse sobre uma linha 'não mostrada' na lenda, ela será desenhada (enquanto você está pairando no item da legenda). Você pode obter todos os itens para exibir novamente clicando duas vezes em uma entrada de legenda 'não compensada'. Isso mostrará todas as linhas 'não mostradas', mas eliminará a linha que você acabou de clicar ... então clique sozinho no item que você acabou de clicar duas vezes. Eu sei que parece confuso.
Se uma entrada de legenda estiver escondida e você passa por ela, ela será exibida até que você passe o mouse
Tipos de gráficos:
Gráfico 'CPU Busy': um gráfico semelhante ao kernelshark mostrando a ocupação da CPU por PID/Thread. Veja Referência do Kernelshark http://rostedt.homelinux.com/kernelshark/
- Abaixo está uma captura de tela do gráfico ocupado da CPU. O gráfico mostra, para cada CPU, o processo/PID/TID em execução a qualquer momento. O processo ocioso não é desenhado. Para 'CPU 1' na captura de tela, o oval verde está em torno da parte 'Switch de contexto' do gráfico. Acima das informações de troca de contexto de cada CPUS, a CPU Ocuper mostra os eventos que apresentam no mesmo arquivo que o evento Switch de contexto. O oval vermelho na linha CPU 1 mostra a parte do evento do gráfico.
- O gráfico é baseado no evento Switch de contexto e mostra o tópico em execução em cada CPU a qualquer momento
- O evento Switch de contexto é o Scheding Linux: sched_switch ou o evento Windows ETW CSWitch.
- Se houver mais eventos do que a troca de contexto no arquivo de dados, todos os outros eventos serão representados como traços verticais acima da CPU.
- Se os eventos tiverem pilhas de chamadas, a pilha de chamadas também será mostrada no balão pop -up
gráficos de linha
- Os gráficos de linha são provavelmente chamados de gráficos de etapas com mais precisão, pois cada evento (até agora) tem duração e essas 'durações' são representadas por segmentos horizontais e unidas por segmentos verticais.
- A parte vertical do gráfico de etapas pode preencher um gráfico se as linhas do gráfico tiverem muita variação
- Você pode selecionar (na barra de navegação esquerda) para não conectar os segmentos horizontais de cada linha ... para que o gráfico se torne uma espécie de gráfico de 'Dash espalhado'. Os 'traços horizonatais' são os pontos de dados reais. Quando você muda do gráfico de etapas para o gráfico de traço, o gráfico não é redesenhado até que haja alguma solicitação de 'redraw' (como zoom/pan ou destaque (passando o mouse sobre uma entrada de legenda)).
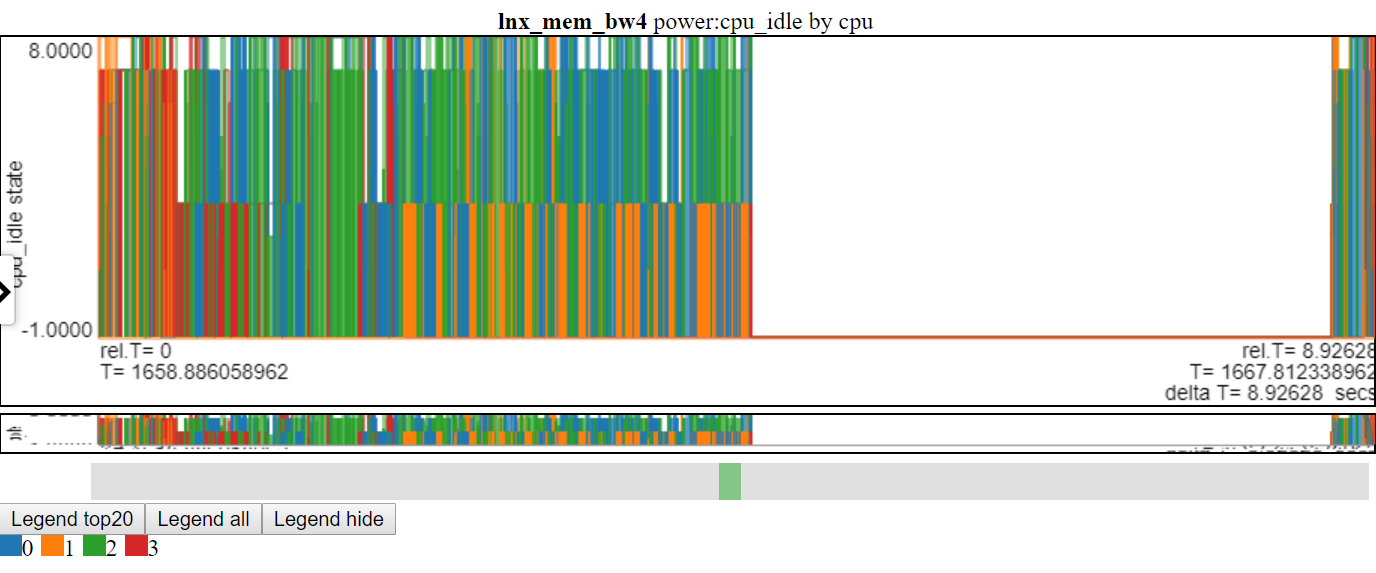
- Abaixo está uma captura de tela de estados de energia cpu_idle usando o gráfico de linha. As linhas de conexão apagam as informações no gráfico.
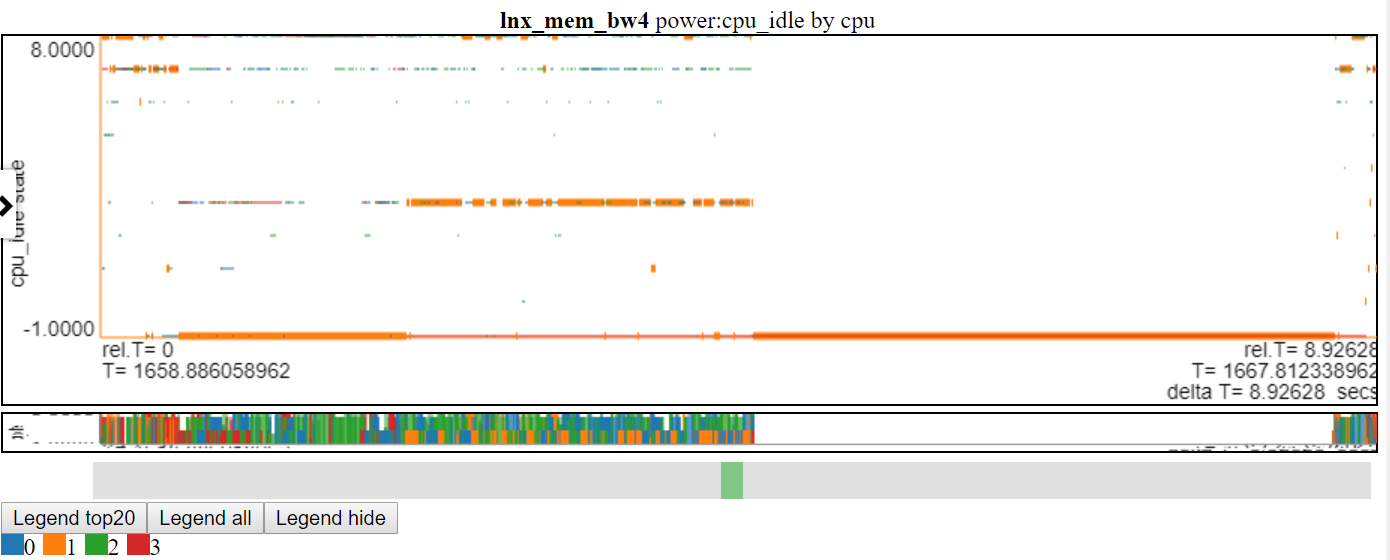
- Abaixo está uma captura de tela de estados de energia CPU_IDLE usando o gráfico de fracasso disperso. O gráfico agora mostra um traço horizontal para o Data Point (a largura do traço é a duração do evento). Agora, podemos ver mais informações, mas esse gráfico também mostra uma desvantagem com minha lógica de gráficos: muitos dos dados estão no valor máximo e no valor mínimo do gráfico e são obscurecidos.
gráficos empilhados
- Os gráficos empilhados podem causar muito mais dados a serem gerados do que gráficos de linha. Por exemplo, desenhar um gráfico de linha de quando um encadeamento específico está em execução depende apenas desse thread. Desenhar um gráfico empilhado para a execução de threads é diferente: um evento de comutação de contexto em qualquer encadeamento alterará todos os outros threads em execução ... então, se você tiver N CPUs, receberá mais N-1 coisas a desenhar por evento para gráficos empilhados.
FlameGraphs. Para cada evento de perfis que possui pilhas de chamadas e está no mesmo arquivo que o evento Sched_Switch/CSWitch, um FlameGraph é criado.
- Abaixo está uma captura de tela de um típico FlameGraph típico. Geralmente, a altura padrão do gráfico FlameGraph não é suficiente para ajustar o texto em cada nível do FlameGraph. Mas você ainda obtém as informações de pilhas de calls 'call'.
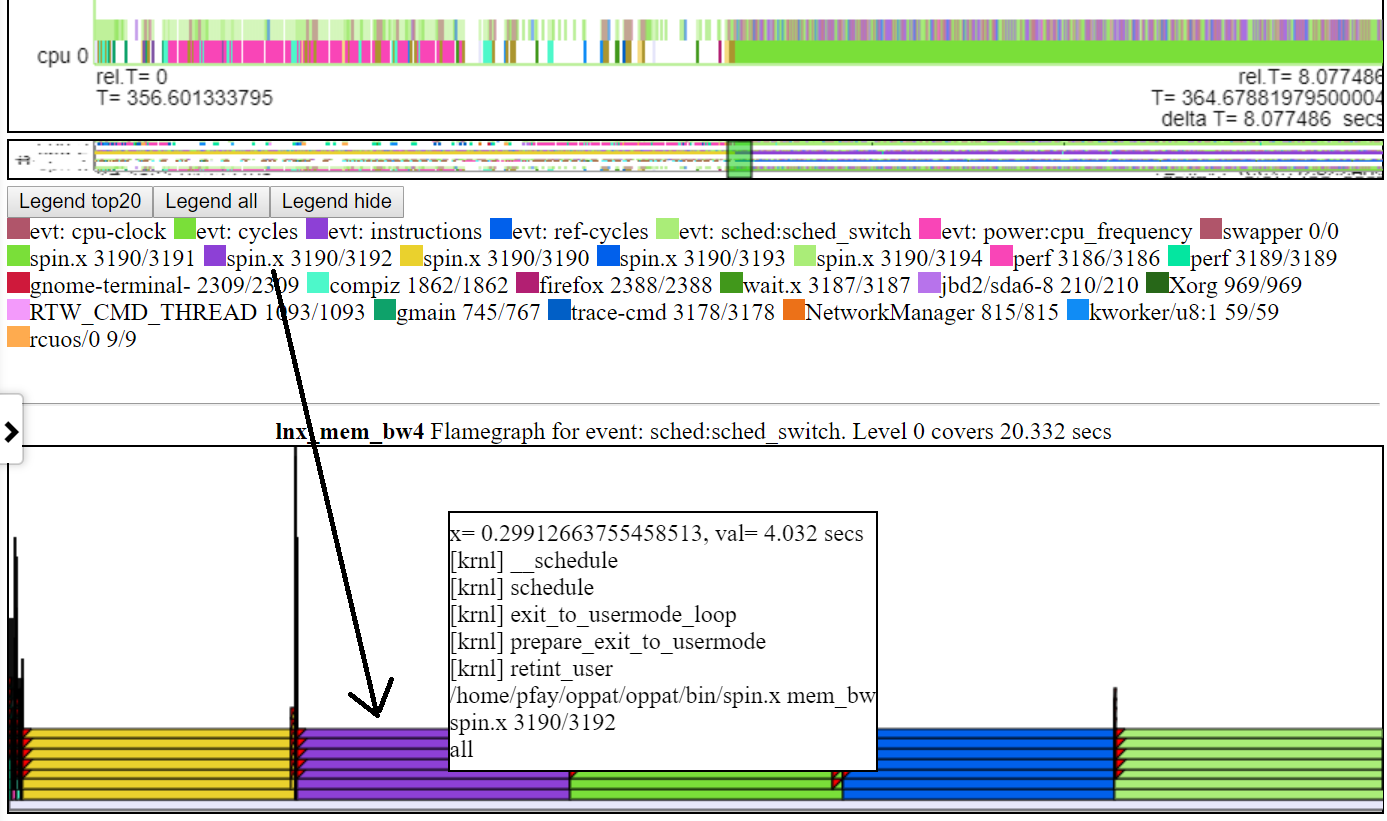 .
.- Se você clicar na camada do gráfico, ele se expande mais de forma que o texto se encaixe. Se você clicar na camada mais baixa, ele cobre todos os dados para o intervalo do 'gráfico de propriedade'.
- Abaixo está uma captura de tela de um FlameGraph em zoom (depois de clicar em uma das camadas de uma chama).
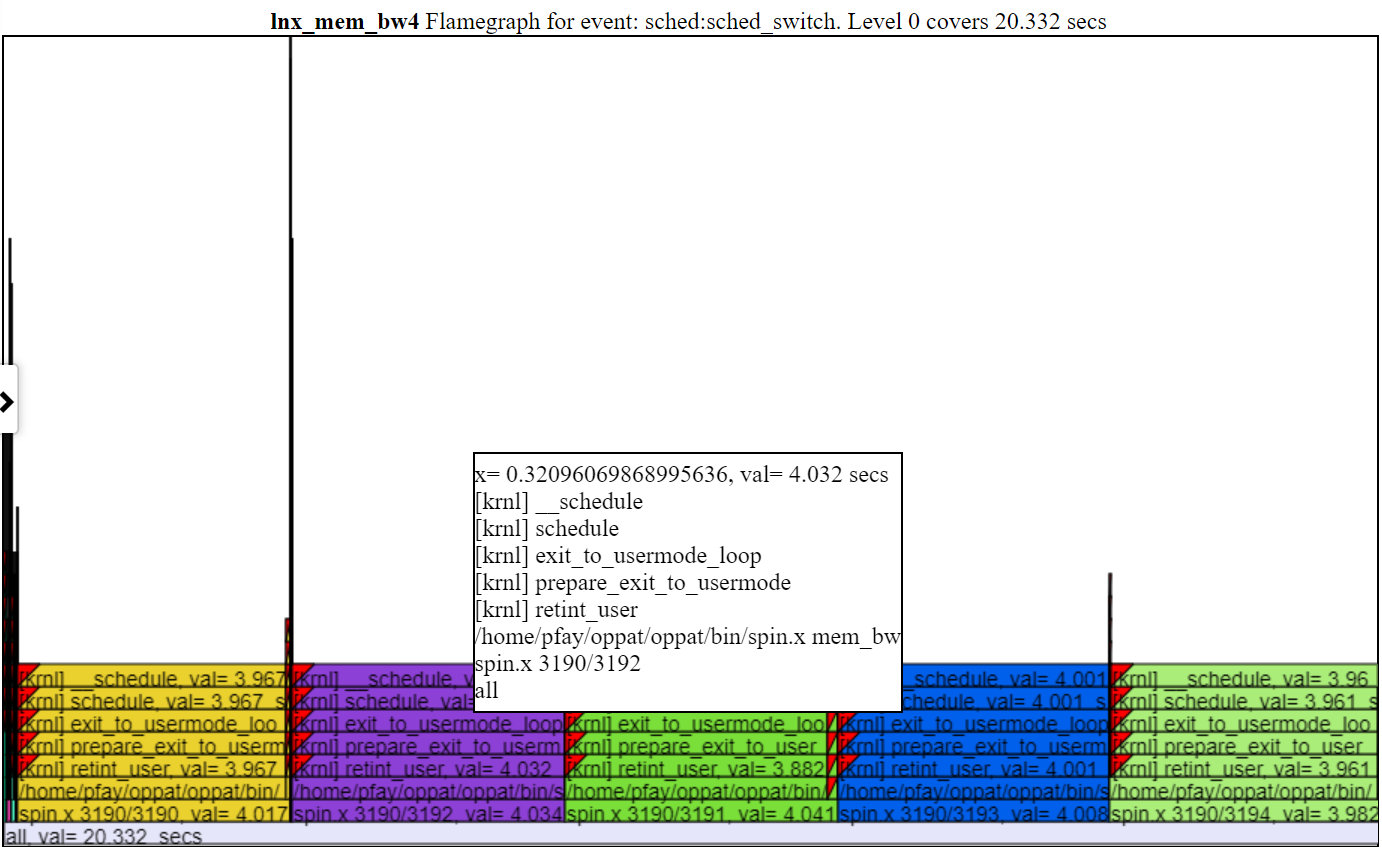 .
.- Geralmente, a altura padrão do gráfico FlameGraph não é suficiente para ajustar o texto em cada nível do FlameGraph. Mas você ainda obtém as informações de pilhas de calls 'call'.
- A cor do FlameGraph corresponde ao processo/PID/TID no gráfico Legend of CPU_BUSY ... então não é tão bonito quanto um FlameGraph, mas agora a cor de uma 'chama' realmente significa algo.
- O CPI (Relógios por instrução) FlameGrapht Colored o processo/PID/TID pelo CPI para essa pilha.
- Abaixo está uma amostra de gráfico de CPI desarrumado. A instância esquerda de spin.x (em laranja claro) possui um CPI = 2,26 ciclos/instruções. O 4 spin.x's à direita em verde claro tem um CPI = 6,465.
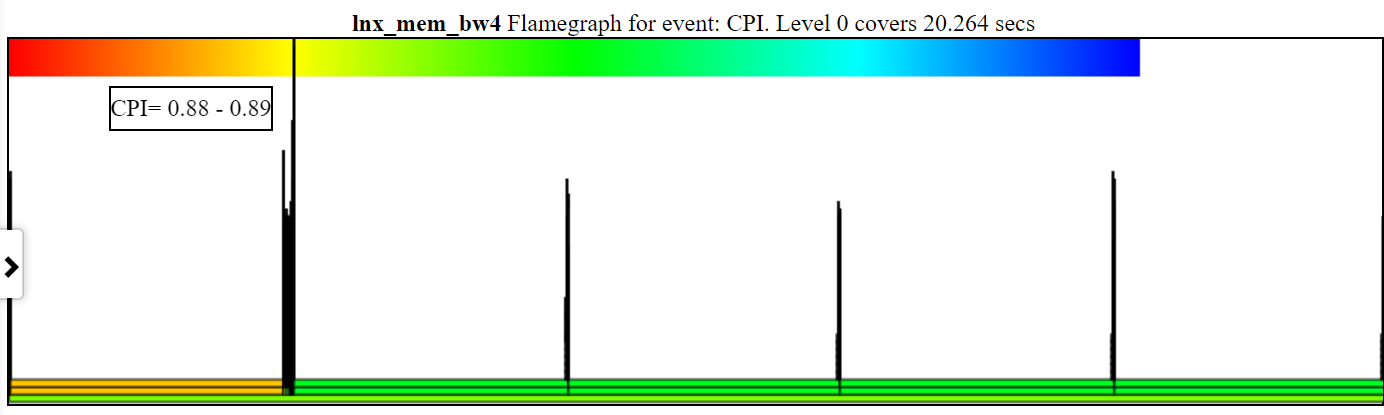
- Você precisa ter ciclos, instruções e cpu-clock (ou sched_switch) callStacks
- A largura da CPI 'Flame' é baseada no tempo de CPU-CLOCK.
- A cor é baseada no CPI. Um gradiente vermelho a verde a azul no canto superior esquerdo do gráfico mostra a coloração.
- O vermelho é um CPI baixo (então muitas instruções por relógio ... eu penso nisso como 'quente')
- Azul é um CPI alto (tão poucas instruções por relógio ... eu penso nisso como 'frio')
- Abaixo está um gráfico de CPI com zoom de amostra mostrando a coloração e o CPI. Os threads 'spin.x' foram desmarcados na lenda cpu_busy para que não apareçam no FlameGraph.
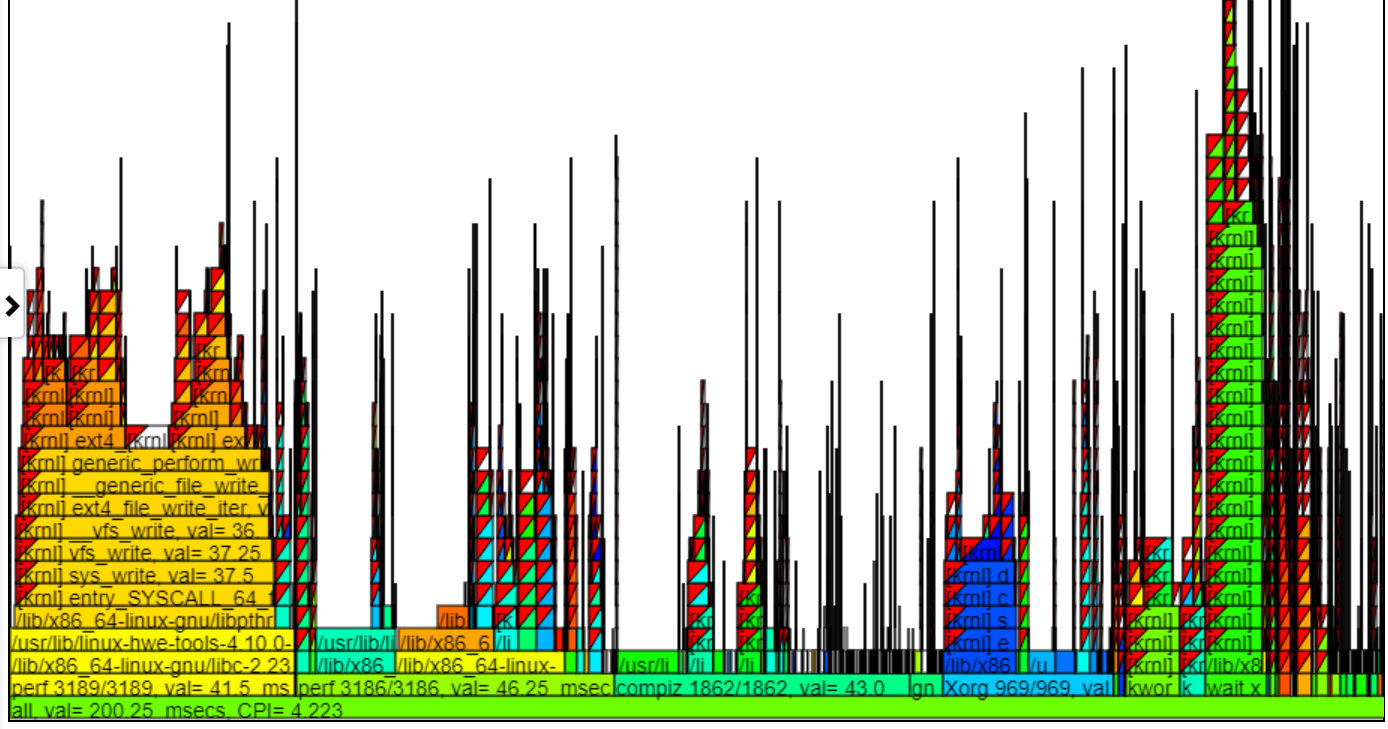
- As instruções GIPS (GIGA (bilhão) por segundo) do gráfico FlameGraph coloram o processo/PID/TID pelos GIPs para essa pilha.
- Abaixo está um gráfico de GIPs desarrumados de amostra (Giga/bilhão de instruções por segundo). A instância esquerda de spin.x (em verde claro) tem um GIPS = 1,13. O 4 spin.x's à direita em verde azul têm um gips = 0,377. A pilha de chamadas no balão é para uma das palhetas à esquerda do balão.

- No gráfico acima, observe que a pilha esquerda (para spin.x) obtém instruções mais altas/s do que as 4 instâncias mais à direita de spin.x. Essas 1º instância do spin.x são executadas por si só (assim, recebe muita memória BW) e a direita 4 spin.x Threads são executados em paralelo e recebem um GIPS mais baixo (já que um thread pode maximizar o máximo da memória BW).
- Você precisa ter instruções e cpu-clock (ou sched_switch) callStacks
- A largura da 'chama' do GIPS é baseada no tempo de CPU-Clock.
- A cor é baseada nos GIPs. Um gradiente vermelho a verde a azul no canto superior esquerdo do gráfico mostra a coloração.
- O vermelho é um gips alto (então muitas instruções por segundo ... eu penso nisso como 'quente' fazendo muito trabalho)
- Blue é um gips baixo (tão poucas instruções por segundo ... eu penso nisso como 'frio')
- Abaixo está um gráfico de GIPs com zoom de amostra mostrando a coloração e os GIPs. Cliquei no 'Perf 3186/3186', então essa chama é mostrada abaixo.
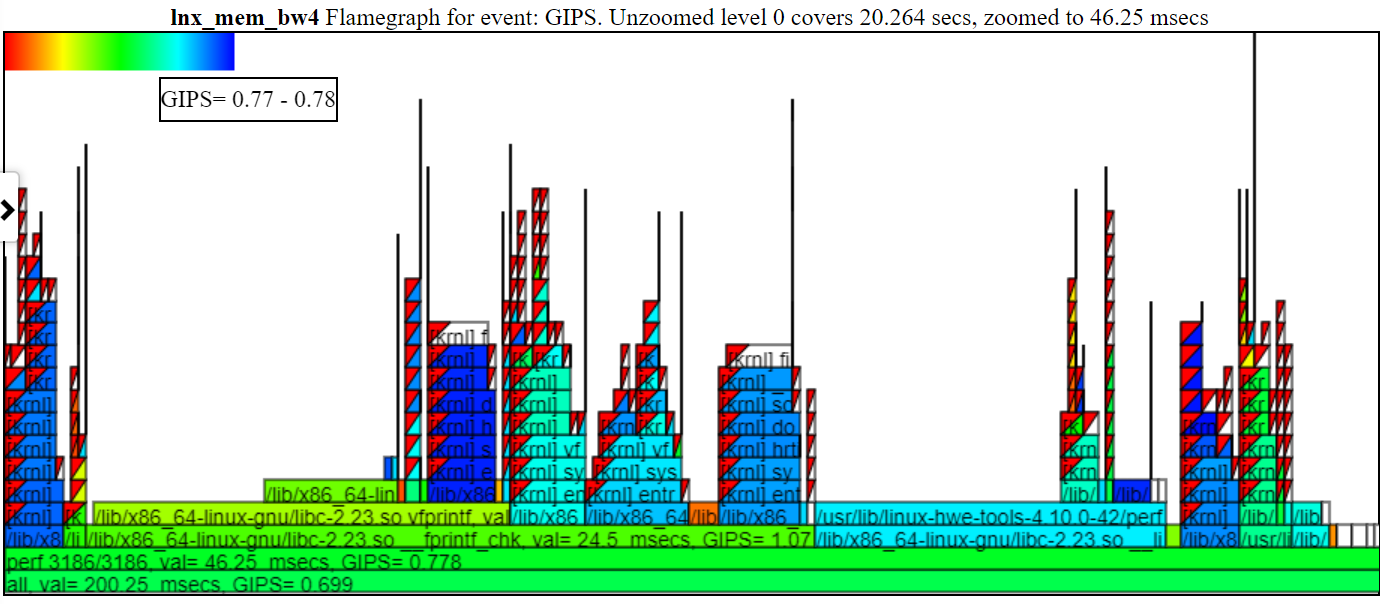
- Se você ocultar um processo na legenda (clique na entrada da legenda ... ela será acinzentada), o processo não será mostrado no FlameGraph.
- Se você arrastar o mouse no FlameGraph, essa seção do FlameGraph será ampliada
- Clicar em um zoom 'chama' para apenas essa chama
- Esquerda arrastando o mouse no FlameGraph irá diminuir o zoom
- Clicando em um nível mais baixo do FlameGraph 'desconfiança' para todos os dados para esse nível
- Se você clicar no nível mais baixo 'All' do FlameGraph, você aumentará o zoom todo o caminho
- Quando você clica no nível do FlameGraph, o gráfico é redimensionado para que cada nível seja alto o suficiente para exibir o texto. Isso faz com que o gráfico seja redimensionado. Para tentar adicionar um pouco de sanidade a esse redimensionamento, posto o último nível do gráfico redimensionado na parte inferior da tela visível.
- Se você voltar para a lenda e passar o mouse sobre uma entrada oculta, essa entrada será mostrada no FlameGraph até você passar o mouse
- Se você clicar em um nível superior 'chama', apenas essa seção será ampliada.
- Se você ampliar/sair no gráfico 'pai', os FlameGraphs serão redesenhados para o intervalo selecionado
- Se você picar para a esquerda/direita no gráfico 'pai', os FlameGraphs serão redesenhados para o intervalo selecionado
- Por padrão, o texto de cada nível do gráfico de chama provavelmente não se encaixará. Se você clicar no FlameGraph, o tamanho será expandido para permitir desenhar o texto também
- Você pode selecionar (na barra de navegação esquerda) se deve agrupar os FlameGraphs por processo/PID/TID ou por processo/PID ou por apenas processo.
- Ambos 'on cpu', 'off cpu' e 'run fila' flamegraphs são desenhados.
- 'On CPU' é a pilha de chamadas para o que o tópico estava fazendo enquanto estava sendo executado na CPU ... Então, as palhetas de chamadas do SampledProfile ou o Perf CPU-CLOCK INDACE INDICE
- 'Off CPU' mostra, para tópicos que não funcionam, quanto tempo eles estavam esperando e a história de call quando foram trocados.
- Abaixo está uma captura de tela do gráfico fora da CPU ou do tempo de espera. O pop -up mostra (no FlameGraph) que 'wait.x' está esperando no Nanosleep.

- O 'estado' de troca (e no ETW a 'razão') é mostrado como um nível acima do processo. Normalmente, a maioria dos tópicos está dormindo ou não, mas isso ajuda a responder à pergunta: "Quando meu tópico não correu ... o que estava esperando?".
- Mostrar o 'estado' para o interruptor de contexto permite ver:
- Por exemplo, se um tópico está esperando um sono não interruptível (estado == D no Linux ... geralmente io)
- sono interrompível (estado = s ... freqüentemente um nanosleep ou futex)
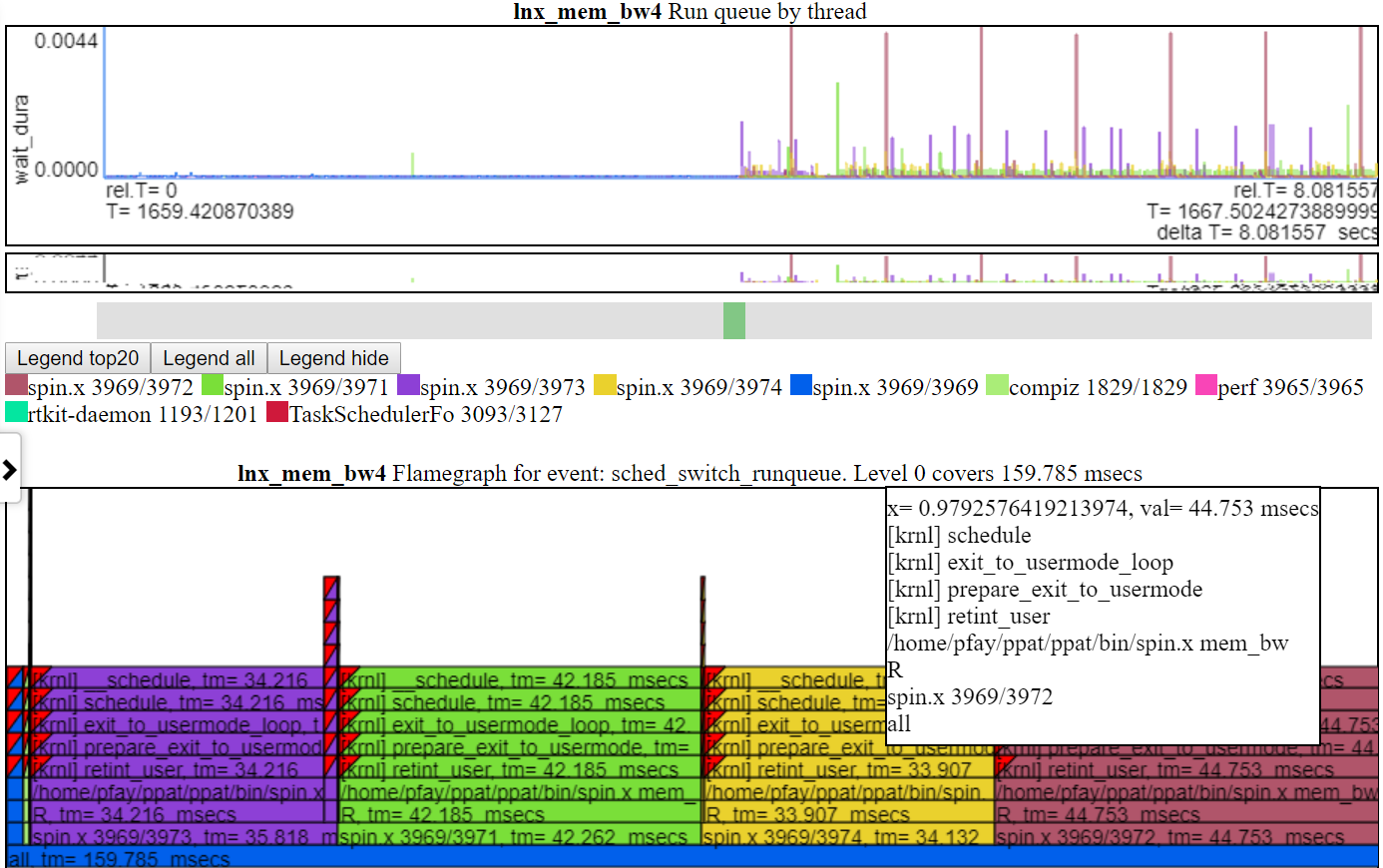
- 'Run fila' mostra os threads que foram trocados e estavam em um estado de corrida ou execução. Portanto, este gráfico mostra a saturação da CPU se houver threads em um estado executável, mas não estiver em execução.
- Abaixo está a captura de tela do gráfico Run_queue. Este gráfico mostra a quantidade de tempo que um encadeamento não foi executado porque não havia CPU suficiente. Ou seja, estava pronto para correr, mas algo mais estava usando a CPU. Cada FlameGraph mostra o total coberto no gráfico. No caso do gráfico Run_queue, ele mostra ~ 159 ms em tempo de espera. Portanto, dado que o spin.x tem cerca de 20 segundos de tempo de execução e 0,159 segundos 'espera' tempo, isso não parece muito ruim.
Eu não tinha uma biblioteca de gráficos baseada em tela para usar, então os gráficos são meio grosseiros ... eu não queria gastar muito tempo criando os gráficos se houver algo melhor por aí. Os gráficos precisam usar a tela HTML (não SVGS, D3.JS etc) devido à quantidade de dados.
Coleção de dados para oppat
A coleta dos dados de desempenho e energia é muito "situacional". Uma pessoa vai querer executar scripts, outra desejará iniciar medições com um botão, iniciar um vídeo e encerrar a coleção com a pressão de um botão. Eu tenho um script para Windows e um script para Linux que demonstra:
- Iniciando coleta de dados,
- executando uma carga de trabalho,
- Stop Data Collection
- Após o processo dos dados (criando um arquivo de texto a partir dos dados binários do perf/xperf/trace-cmd)
- Colocando todos os arquivos de dados em um diretor de saída
- Criando um arquivo file_list.json no diretor de saída (que informa ao OPPAT o nome e o tipo dos arquivos de saída)
As etapas para a coleta de dados usando os scripts:
- Utilidades de construção spin.exe (spin.x) e wait.exe (wait.x)
- Do Dir da raiz oppat:
- no Linux:
./mk_spin.sh - no Windows :
.mk_spin.bat (de uma caixa do Visual Studio CMD) - Os binários serão colocados no ./bin subdir
- Comece com a execução dos scripts fornecidos:
- run_perf_x86_haswell.sh - Para a coleção de dados Haswell CPU_DIAGRAM
- On Linux, Tipo:
sudo bash ./scripts/run_perf.sh - Por padrão, o script coloca os dados em dir ../oppat_data/lnx/mem_bw7
- run_perf.sh - você precisa ter trace -cmd e perfil instalado
- On Linux, Tipo:
sudo bash ./scripts/run_perf.sh - Por padrão, o script coloca os dados em dir ../oppat_data/lnx/mem_bw4
- run_xperf.bat - você precisa ter o xperf.exe instalado.
- No Windows, de uma caixa CMD com privilégios de administrador, tipo:.
.scriptsrun_xperf.sh - Por padrão, o script coloca os dados em dir .. oppat_data win mem_bw4
- Edite o script de corrida se quiser alterar os padrões
- Além dos arquivos de dados, o script de execução cria um arquivo file_list.json no diretor de saída. O Oppat usa o arquivo file_list.json para descobrir os nomes de arquivos e o tipo de arquivos no diretor de saída.
- A 'carga de trabalho' para o script de execução é spin.x (ou spin.exe), que faz um teste de largura de banda de memória em 1 CPU por 4 segundos e depois em todas as CPUs por mais 4 segundos.
- Outro programa wait.x/wait.exe também é iniciado em segundo plano. espera.cpp lê as informações da bateria para o meu laptop. Funciona no meu laptop Ubuntu do Windows 10/Linux de Boot Windows 10/Linux. O arquivo SYSFS pode ter um nome diferente no seu Linux e quase certamente é diferente no Android.
- No Linux, você provavelmente poderia apenas gerar um arquivo prf_trace.data e prf_trace.txt usando a mesma sintaxe que está em run_perf.sh, mas eu não tentei isso.
- Se você estiver executando em um laptop e deseja obter a energia da bateria, lembre -se de desconectar o cabo de alimentação antes de executar o script.
Suporte de dados PCM
- Oppat pode ler e gráfico de arquivos PCM .CSV.
- Abaixo está um instantâneo da lista de gráficos criados.
- Infelizmente, você precisa fazer um patch no PCM para criar um arquivo com um registro de data e hora absoluto para o OPPAT processar.
- Isso ocorre porque o arquivo PCM CSV não possui um registro de data e hora que eu posso usar para correlacionar -se com as outras fontes de dados.
- Eu adicionei o patch aqui PCM Patch
Construindo Oppat
- No Linux, tipo
make in the Oppat Root Dir- Se tudo funcionar, deve haver um arquivo bin/oppat.x
- No Windows, você precisa:
- Instale a versão Windows do GNU Make. Consulte http://gnuwin32.sourceforge.net/packages/make.htm ou, apenas para os binários mínimos necessários, use http://gnuwin32.sourceforge.net/downlinks/make.php
- Coloque este novo binário 'Make' no caminho
- Você precisa de um compilador atual do Visual Studio 2015 ou 2017 C/C ++ (usei o VS 2015 Professional e os VS 2017 Community Compilers)
- Inicie um Windows Visual Studio X64 CMD Native Caixa Prompt
- Tipo
make in the Oppat Root Dir - Se tudo funcionar, deve haver um arquivo bin oppat.exe
- Se você estiver alterando o código -fonte, provavelmente precisará reconstruir o arquivo de dependência de inclusão
- Você precisa ter o Perl instalado
- no Linux, no Dir da raiz oppat do:
./mk_depends.sh . Isso criará um arquivo de dependência_lnx.mk dependência. - on Windows, in the OPPAT root dir do:
.mk_depends.bat . This will create a depends_win.mk dependency file.
- If you are going to run the sample run_perf.sh or run_xperf.bat scripts, then you need to build the spin and wait utilities:
- On Linux:
./mk_spin.sh - On Windows:
.mk_spin.bat
Running OPPAT
- Run the data collection steps above
- now you have data files in a dir (if you ran the default run_* scripts:
- on Windows ..oppat_datawinmem_bw4
- on Linux ../oppat_data/lnx/mem_bw4
- You need to add the created files to the input_filesinput_data_files.json file:
- Starting OPPAT reads all the data files and starts the web server
- on Windows to generate the haswell cpu_diagram (assuming your data dir is ..oppat_datalnxmem_bw7)
binoppat.exe -r ..oppat_datalnxmem_bw7 --cpu_diagram webhaswell_block_diagram.svg > tmp.txt
- on Windows (assuming your data dir is ..oppat_datawinmem_bw4)
binoppat.exe -r ..oppat_datawinmem_bw4 > tmp.txt
- on Linux (assuming your data dir is ../oppat_data/lnx/mem_bw4)
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 > tmp.txt
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 --web_file tst2.html > tmp.txt
- Then you can load the file into the browser with the URL address:
file:///C:/some_path/oppat/tst2.html
Derived Events
'Derived events' are new events created from 1 or more events in a data file.
- Say you want to use the ETW Win32k InputDeviceRead events to track when the user is typing or moving the mouse.
- ETW has 2 events:
- Microsoft-Windows-Win32k/InputDeviceRead/win:Start
- Microsoft-Windows-Win32k/InputDeviceRead/win:Stop
- So with the 2 above events we know when the system started reading input and we know when it stopped reading input
- But OPPAT plots just 1 event per chart (usually... the cpu_busy chart is different)
- We need a new event that marks the end of the InputDeviceRead and the duration of the event
- The derived event needs:
- a new event name (in chart.json... see for example the InputDeviceRead event)
- a LUA file and routine in src_lua subdir
- 1 or more 'used events' from which the new event is derived
- the derived events have to be in the same file
- For the InputDeviceRead example, the 2 Win32k InputDeviceRead Start/Stop events above are used.
- The 'used events' are passed to the LUA file/routine (along with the column headers for the 'used events') as the events are encountered in the input trace file
- In the InputDeviceRead lua script:
- the script records the timestamp and process/pid/tid of a 'start' event
- when the script gets a matching 'Stop' event (matching on process/pid/tid), the script computes a duration for the new event and passes it back to OPPAT
- A 'trigger event' is defined in chart.json and if the current event is the 'trigger event' then (after calling the lua script) the new event is emitted with the new data field(s) from the lua script.
- An alternate to the 'trigger event' method is to have the lua script indicate whether or not it is time to write the new event. For instance, the scr_lua/prf_CPI.lua script writes a '1' to a variable named ' EMIT ' to indicate that the new CPI event should be written.
- The new event will have:
- the name (from the chart.json evt_name field)
- The data from the trigger event (except the event name and the new fields (appended)
- I have tested this on ETW data and for perf/trace-cmd data
Using the browser GUI Interface
TBD
Defining events and charts in charts.json
TBD
Rules for input_data_files.json
- The file 'input_files/input_data_files.json' can be used to maintain a big list of all the data directories you have created.
- You can then select the directory by just specifying the file_tag like:
- bin/oppat.x -u lnx_mem_bw4 > tmp.txt # assuming there is a file_tag 'lnx_mem_bw4' in the json file.
- The big json file requires you to copy the part of the data dir's file_list.json into input_data_files.json
- in the file_list.json file you will see lines like:
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- don't copy the lines like below from the file_list.json file:
- paste the copied lines into input_data_files.json. Pay attention to where you paste the lines. If you are pasting the lines at the top of input_data_files.json (after the
{"root_dir":"/data/ppat/"}, then you need add a ',' after the last pasted line or else JSON will complain. - for Windows data files add an entry like below to the input_filesinput_data_files.json file:
- yes, use forward slashes:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- for Linux data files add an entry like below to the input_filesinput_data_files.json file:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/lnx/mem_bw4 " },
{ "cur_tag" : " lnx_mem_bw4 " },
{ "bin_file" : " prf_energy.txt " , "txt_file" : " prf_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " },
{ "bin_file" : " prf_trace.data " , "txt_file" : " prf_trace.txt " , "tag" : " %cur_tag% " , "type" : " PERF " },
{ "bin_file" : " tc_trace.dat " , "txt_file" : " tc_trace.txt " , "tag" : " %cur_tag% " , "type" : " TRACE_CMD " },- Unfortunately you have to pay attention to proper JSON syntax (such as trailing ','s)
- Here is an explanation of the fields:
- The 'root_dir' field only needs to entered once in the json file.
- It can be overridden on the oppat cmd line line with the
-r root_dir_path option - If you use the
-r root_dir_path option it is as if you had set "root_dir":"root_dir_path" in the json file - the 'root_dir' field has to be on a line by itself.
- The cur_dir field applies to all the files after the cur_dir line (until the next cur_dir line)
- the '%root_dir% string in the cur_dir field is replaced with the current value of 'root_dir'.
- the 'cur_dir' field has to be on a line by itself.
- the 'cur_tag' field is a text string used to group the files together. The cur_tag field will be used to replace the 'tag' field on each subsequent line.
- the 'cur_tag' field has to be on a line by itself.
- For now there are four types of data files indicated by the 'type' field:
- type:PERF These are Linux perf files. OPPAT currently requires both the binary data file (the bin_file field) created by the
perf record cmd and the perf script text file (the txt_file field). - type:TRACE_CMD These are Linux trace-cmd files. OPPAT currently requires both the binary dat file (the bin_file field) created by the
trace-cmd record cmd and the trace-cmd report text file (the txt_file field). - type:ETW These are Windows ETW xperf data files. OPPAT currently requires only the text file (I can't read the binary file). The txt_file is created with
xperf ... -a dumper command. - type:LUA These files are all text files which will be read by the src_lua/test_01.lua script and converted to OPPAT data.
- the 'prf_energy.txt' file is
perf stat output with Intel RAPL energy data and memory bandwidth data. - the 'prf_energy2.txt' file is created by the wait utility and contains battery usage data in the 'perf stat' format.
- the 'wait.txt' file is created by the wait utility and shows the timestamp when the wait utility began
- Unfortunately 'perf stat' doesn't report a high resolution timestamp for the 'perf stat' start time
Limitações
- The data is not reduced on the back-end so every event is sent to the browser... this can be a ton of data and overwhelm the browsers memory
- I probably should have some data reduction logic but I wanted to get feedback first
- You can clip the files to a time range:
oppat.exe -b abs_beg_time -e abs_beg_time to reduce the amout of data- This is a sort of crude mechanism right now. I just check the timestamp of the sample and discard it if the timestamp is outside the interval. If the sample has a duration it might actually have data for the selected interval...
- There are many cases where you want to see each event as opposed to averages of events.
- On my laptop (with 4 CPUs), running for 10 seconds of data collection runs fine.
- Servers with lots of CPUs or running for a long time will probably blow up OPPAT currently.
- The stacked chart can cause lots of data to be sent due to how it each event on one line is now stacked on every other line.
- Limited mechanism for a chart that needs more than 1 event on a chart...
- say for computing CPI (cycles per instruction).
- Or where you have one event that marks the 'start' of some action and another event that marks the 'end' of the action
- There is a 'derived events' logic that lets you create a new event from 1 or more other events
- See the derived event section
- The user has to supply or install the data collection software:
- on Windows xperf
- See https://docs.microsoft.com/en-us/windows-hardware/get-started/adk-install
- You don't need to install the whole ADK... the 'select the parts you want to install' will let you select just the performance tools
- on Linux perf and/or trace-cmd
sudo apt-get install linux-tools-common linux-tools-generic linux-tools- ` uname -r `
- For trace-cmd, see https://github.com/rostedt/trace-cmd
- You can do (AFAIK) everything in 'perf' as you can in 'trace-cmd' but I have found trace-cmd has little overhead... perhaps because trace-cmd only supports tracepoints whereas perf supports tracepoints, sampling, callstacks and more.
- Currently for perf and trace-cmd data, you have to give OPPAT both the binary data file and the post-processed text file.
- Having some of the data come from the binary file speeds things up and is more reliable.
- But I don't want to the symbol handling and I can't really do the post-processing of the binary data. Near as I can tell you have to be part of the kernel to do the post processing.
- OPPAT requires certain clocks and a certain syntax of 'convert to text' for perf and trace-cmd data.
- OPPAT requires clock_monotonic so that different file timestamps can be correlated.
- When converting the binary data to text (trace-cmd report or 'perf script') OPPAT needs the timestamp to be in nanoseconds.
- see scriptsrun_xperf.bat and scriptsrun_perf.sh for the required syntax
- given that there might be so many files to read (for example, run_perf.sh generates 7 input files), it is kind of a pain to add these files to the json file input_filesinput_data_files.json.
- the run_xperf.bat and run_perf.sh generate a file_list.json in the output directory.
- perf has so, so many options... I'm sure it is easy to generate some data which will break OPPAT
- The most obvious way to break OPPAT is to generate too much data (causing browser to run out of memory). I'll probably handle this case better later but for this release (v0.1.0), I just try to not generate too much data.
- For perf I've tested:
- sampling hardware events (like cycles, instructions, ref-cycles) and callstacks for same
- software events (cpu-clock) and callstacks for same
- tracepoints (sched_switch and a bunch of others) with/without callstacks
- Zooming Using touchpad scroll on Firefox seems to not work as well it works on Chrome



