Herramienta de análisis de potencia abierta/rendimiento (Oppat)
Tabla de contenido
- Introducción
- Tipos de datos compatibles
- Visualización opcat
- Características del gráfico
- tipos de gráficos
- Recopilación de datos para Oppat
- Soporte de datos de PCM
- Edificio Oppat
- Corriendo Oppat
- Eventos derivados
- Usando la interfaz GUI de Browswer
- Limitaciones
Introducción
La herramienta de análisis de potencia abierta/rendimiento (OPPAT) es una herramienta de análisis de rendimiento y potencia transversal de OS.
- Cross-OS: admite archivos de rastreo de Windows ETW y archivos de traza de Linux/Android Perf/Trace-CMD
- Arquitectura cruzada: admite eventos de hardware Intel y Chips (utilizando perf y/o PCM)
La página web del proyecto es https://patinnc.github.io
El repositorio del código fuente es https://github.com/patinnc/oppat
Agregué un sistema operativo (OS_VIEW) a la función del diagrama de bloques de CPU. Esto basado en las páginas de Brendan Gregg, como http://www.brendangregg.com/linuxperf.html. Aquí hay algunos datos de ejemplo para ejecutar una versión antigua de Geekbench v2.4.2 (código de 32 bits) en el brazo de 64 bits Ubuntu Mate V18.04.2 Raspberry Pi 3 B+, 4 brazos Cortex A53 CPU:
- Un video de los cambios en el diagrama de bloque CPU OS_VIEW y ARM A53 que ejecuta GeekBench:
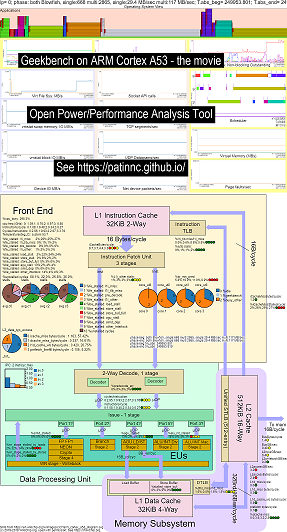
- Hay algunas diapositivas introductorias para tratar de explicar el diseño OS_VIEW y CPU_DIAGRAM y luego 1 diapositiva que muestra los resultados por cada una de las 30 subpruebas
- Un archivo de Excel de los datos en la película: Excel archivo de Geekbench la película
- El HTML de los datos en la película ... vea GeekBench v2.4.2 en 4 núcleo ARM CORTEXT A53 con OS_VIEW, diagrama de CPU.
- El PNG del tablero para las 30 fases ordenadas mediante el aumento de las instrucciones/seg ... Consulte el brazo Cortex A53 Raspberry Pi 3 con Diagrama de CPU Diagrama de 4 núcleos Panel de control de 4 núcleos que ejecuta Geekbench.
Aquí hay algunos datos de ejemplo para ejecutar mi punto de referencia de spin (pruebas de ancho de banda de memoria/caché, una prueba 'spin' Keep-CPU-Busy) en Raspberry Pi 3 B+ (Cortex A53) CPU:
- Un video de los cambios en OS_VIEW y el diagrama de bloque CPU de ARM A53 Running Spin:
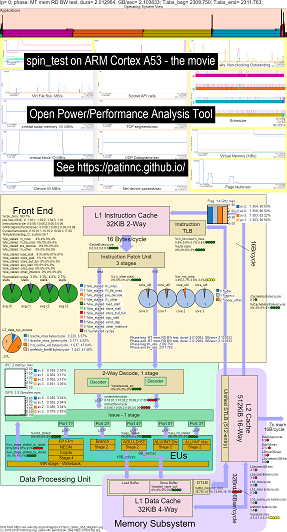
- Hay algunas diapositivas introductorias para tratar de explicar los gráficos OS_VIEW y el diseño CPU_DIAGRAM, una diapositiva que se muestra en la que se muestra una subprobación (en segundos) (por lo que puede ir a t = x secs para ir directamente a esa subpotación) y luego una diapositiva para cada uno de los 5 subtestados
- Un archivo de Excel de los datos en la película: Excel archivo de Geekbench la película
- El HTML de los datos en la película ... Vea el brazo Cortex A53 Raspberry Pi 3 con diagrama de CPU de 4 núcleos que ejecuta Benchmark Spin Benchmark.
- El PNG del tablero para las 5 fases ordenadas al aumentar las instrucciones/seg ... Consulte el brazo Cortex A53 Raspberry Pi 3 con Diagrama de CPU Diagrama de 4 núcleos Running Spin Benchmark.
Aquí hay algunos datos de ejemplo para ejecutar Geekbench en Haswell CPU:
- Un video de los cambios en OS_VIEW y el diagrama de bloques de CPU de Haswell ejecutando GeekBench:
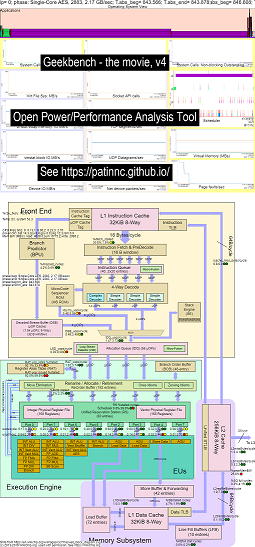
- Hay algunas diapositivas introductorias para tratar de explicar los gráficos OS_VIEW y el diseño CPU_DIAGRAM, una diapositiva que se muestra en la que se muestra una subprobación (en segundos) (por lo que puede ir a t = x secs para ir directamente a esa subpotación) y luego una diapositiva para cada uno de los 50 subtestados
- Un archivo de Excel de los datos en la película: Excel archivo de Geekbench la película
- El HTML de los datos en la película ... ver Intel Haswell con el diagrama de CPU 4-CPU Chip que ejecuta Geekbench.
- El PNG del tablero para las 50 fases ordenadas por el aumento de UOPS retirado/seg ... Vea el tablero Intel Haswell con Diagrama de CPU de 4 núcleos Dashboard que ejecuta Geekbench.
Aquí hay algunos datos para ejecutar mi punto de referencia 'Spin' con 4 sub-pruebas en las CPU de Haswell:
- La primera subprueba es una prueba de ancho de banda de memoria de lectura. El bloque de memoria L2/L3/es altamente utilizado y estancado durante la prueba. La rata Uops/ciclo es bajo ya que la rata se estanca principalmente.
- La segunda subprueba es una prueba de ancho de banda L3 Read. La memoria BW ahora es baja. El bloque L2 y L3 se usa y se detiene durante la prueba. El Uops/ciclo de rata es más alto ya que la rata está menos estancada.
- La tercera subprueba es una prueba de ancho de banda L2 Read. El L3 y la memoria BW ahora son bajas. El bloque L2 es altamente utilizado y estancado durante la prueba. El UOS/ciclo de rata es aún más alto ya que la rata está aún menos estancada.
- La cuarta subprueba es una prueba de giro (solo un bucle ADD). El L2, L3 y la memoria BW están cerca de cero. El Uops/Ciclo de rata es de aproximadamente 3.3 Uops/Cycle, que se acerca a los 4 Uops/Ciclo Max posible.
- Un video de los cambios en el diagrama de bloques de CPU Haswell que ejecuta 'Spin' con análisis. Ver
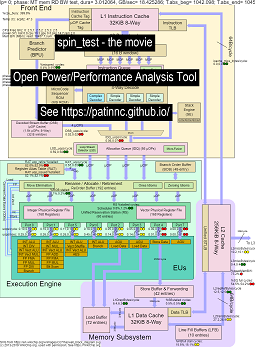
- Un archivo de Excel de los datos en la película: Excel File de Spin the Movie
- El HTML de los datos en la película ... Ver Intel Haswell con el diagrama de CPU 4-CPU Chip que ejecuta Benchmark Spin Benchmark.
El Intel Haswell con las colecciones de datos del diagrama de CPU son para un chip Intel de 4 cpu, un sistema operativo Linux, archivo HTML con más de 50 eventos HW a través de un muestreo de PERF y otros datos recopilados. CPU_DIAGRAM CARACTERÍSTICAS:
- Comience con un diagrama de bloques SVG de wikichip.org (utilizado con permiso),
- Mire las limitaciones de recursos (como Max BW, Max Bytes/Cycle en varias rutas, ciclos mínimos/UOP, etc.), etc.)
- Calcule las métricas para el uso de recursos
- A continuación se muestra una tabla de una prueba de ancho de banda de lectura de memoria que muestra la información de uso de recursos en una tabla (junto con una estimación de si la CPU está estancada debido al uso). La tabla HTML (pero no el PNG) tiene información emergente cuando se desplaza sobre los campos. La tabla muestra que:
- El núcleo se detiene en el ancho de banda de memoria al 55% del máximo posible 25.9 GB/s BW. Es una prueba de memoria BW
- El Superqueue (SQ) está lleno (54.5% para Core0 y 62.3% Core1) de los ciclos (por lo que no se pueden manejar más solicitudes L2)
- El búfer de relleno de línea FB está lleno (30% y 51%), por lo que las líneas no se pueden mover a L1D desde L2
- El resultado es que el backend está estancado (88% y 87%) de los ciclos No se retiran UEPS.
- Los UOP parecen provenir del detector de flujo de bucle (ya que los ciclos LSD/UOP son casi lo mismo que el UOP/ciclo de rata.
- Una captura de pantalla de la tabla BW de la memoria del diagrama de CPU Haswell
- A continuación se muestra una tabla de una prueba de ancho de banda de lectura L3.
- Ahora la memoria BW y el L3 Miss Bytes/Cycle son aproximadamente cero.
- El SQ está menos estancado (ya que no estamos esperando la memoria).
- Bytes/ciclos de transacciones L2 es aproximadamente 2x más alto y aproximadamente el 67% del máximo posible 64 bytes/ciclo.
- El ciclo UOPS_RETIRIRID_STalls/ciclo ha caído al 66% desde el puesto de prueba MEM BW del 88%.
- Los puestos de tampón de relleno ahora son más de 2 veces más altos. Los UPS todavía provienen del LSD.
- Una captura de pantalla de la mesa de Diagrama de CPU L3 de Haswell
- A continuación se muestra una tabla de una prueba de ancho de banda de lectura L2.
- El L2 se pierde los bytes/ciclo es mucho más bajo que la prueba L3.
- El Uops_Retired% estancado ahora es aproximadamente la mitad de la prueba L3 al 34% y los puestos de FB también son de aproximadamente el 17%.
- Los uops todavía provienen del LSD.
- Una captura de pantalla de la mesa de BW Diagrama de CPU de Haswell
- A continuación se muestra una tabla de una prueba de giro (sin cargas, solo do agrega en un bucle).
- Ahora hay casi cero puestos de subsistema de memoria.
- Los UOP provienen del búfer de flujo de decodificación (DSB).
- Rata Retired_uops/ciclo a 3.31 ciclos/UOP está cerca del máximo posible 4.0 UOP/ciclo.
- La rata retirada_uops %estancada es bastante baja en %8.
- una captura de pantalla de la mesa de spinning de la CPU Haswell
Actualmente solo tengo películas CPU_DIAGRAM para Haswell y Arm A53 (ya que no tengo otros sistemas para probar), pero no debería ser difícil agregar otros diagramas de bloques. Todavía obtienes todos los gráficos pero no el CPU_DIAGRAM.
A continuación se muestra uno de los gráficos opatales. La tabla 'CPU_BUSY' muestra lo que se ejecuta en cada CPU y los eventos que ocurren en cada CPU. Por ejemplo, el círculo verde muestra un hilo de spin.x que se ejecuta en la CPU 1. El círculo rojo muestra algunos de los eventos que ocurren en CPU1. Este gráfico se modela después del gráfico Kernelshark de Trace-CMD. Más información sobre la tabla CPU_BUSY está en la sección Types de gráficos. El cuadro de llamada muestra los datos del evento (incluido CallStack (si los hay)) para el evento bajo el cursor. Lamentablemente, la captura de pantalla de Windows no captura el cursor. 
Aquí hay algunos archivos HTML de muestra. La mayoría de los archivos son para un intervalo más corto de ~ 2, pero algunos son corrientes 'llenas' de 8 segundos. Los archivos no se cargarán directamente desde el repositorio, pero se cargarán desde la página web del proyecto: https://patinnc.github.io
- Intel Haswell con diagrama de CPU 4-CPU Chip, Linux OS, archivo HTML con más de 50 eventos HW a través de un muestreo de Perf.
- INTEL 4-CPU Chip, Windows OS, archivo HTML con 1 eventos HW a través de un muestreo XPerf o
- chip Intel 4-CPU completo de ~ 8 segundos, sistema operativo Windows, archivo HTML con muestreo PCM y XPerf o
- INTEL 4-CPU Chip, Linux OS, archivo HTML con 10 eventos HW en 2 grupos multiplexados.
- Arm (Broadcom A53) Chip, Raspberry PI3 Linux HTML File con 14 eventos HW (para CPI, L2 Misses, MEM BW, etc. en 2 grupos multiplexados).
- 11 MB, versión completa del chip del brazo anterior (Broadcom A53), el archivo HTML de Raspberry PI3 Linux con 14 eventos HW (para CPI, L2 Misses, MEM BW, etc. en 2 grupos multiplexados).
Algunos de los archivos anteriores son intervalos de ~ 2 segundos extraídos de ~ 8 segundos de ejecuciones largas. Aquí está la carrera completa de 8 segundos:
- El archivo comprimido HTML de muestra de 8 segundos de 8 segundos completo aquí para un archivo más completo. El archivo hace un JavaScript ZLIB Descompresión de los datos del gráfico para que verá mensajes que le piden que espere (alrededor de 20 segundos) durante el descompresión.
Datos opatitarios compatibles
- Linux Perf y/o archivos de rendimiento Trace-CMD (tanto archivos binarios como de texto),
- La salida de estadística de perfertes también aceptada
- Datos de PCM de Intel,
- Otros datos (importados con los scripts Lua),
- Por lo tanto, esto debería funcionar con datos de Linux o Android regulares
- Actualmente para los datos de PERF y Trace-CMD, OPPAT requiere los archivos de texto binarios y postprocesados y hay algunas restricciones en la línea de comando 'Registro' y la línea de comando 'PERF Script/Trace-CMD Report'.
- Oppat podría hacerse para usar solo los archivos de salida de texto perf/trace-cmd, pero actualmente se requieren archivos binarios y de texto
- Datos de Windows ETW (recopilados por XPerf y arrojados al texto) o datos de Intel PCM,
- Datos arbitrarios de potencia o rendimiento compatibles con los scripts LUA (por lo que no necesita recompilar el código C ++ para importar otros datos (a menos que el rendimiento de LUA se convierta en un problema)))
- Lea los archivos de datos en Linux o Windows, independientemente de dónde se originaron los archivos (lea los archivos Perf/Trace-CMD en los archivos de texto de Windows o ETW en Linux)
Visualización opcat
Aquí hay algunos archivos HTML de visualzation de muestra completa: archivo HTML de muestra de Windows o este archivo HTML de muestra de Linux. Si está en el repositorio (no en el sitio web del proyecto GitHub.io), deberá descargar el archivo y luego cargarlo en su navegador. Estos son archivos web independientes creados por Oppat que podrían ser, por ejemplo, enviados por correo electrónico a otros o (como aquí) publicados en un servidor web.
Oppat Viz funciona mejor en Chrome que en Firefox principalmente porque el zoom que usa el desplazamiento del panel táctil 2 funciona mejor en Chrome.
Oppat tiene 3 modos de visualización:
- El mecanismo de cuadro habitual (donde Oppat Backend lee los archivos de datos y envía datos al navegador)
- También puede crear una página web independiente que sea el equivalente del 'mecanismo de gráfico regular', pero puede intercambiarse con otros usuarios ... La página web independiente tiene todos los scripts y datos incorporados para que se pueda enviar un correo electrónico a alguien y puedan cargarlo en su navegador. Consulte los archivos HTML en sample_html_files referenciado anteriormente y (para una versión más larga de lnx_mem_bw4) consulte el archivo comprimido sample_html_files/lnx_mem_bw4_full.html
- Puede '-Save' un archivo de datos JSON y luego-Cargar el archivo más tarde. El archivo JSON guardado tiene los datos que Oppat necesita enviar al navegador. Esto evita volver a leer los archivos de entrada perf/xperf, pero no recogerá ningún cambio realizado en Charts.json. El archivo HTML completo creado con la opción --web_file es solo un poco más grande que el archivo --save. El modo de carga --save/-requiere construir oppat. Consulte los archivos 'guardados' de la muestra en SUPERS_DATA_JSON_FILES SUBDIR.
A saber información general
- Grabe todos los datos en un navegador (en Linux o Windows)
- Los gráficos se definen en un archivo JSON para que pueda agregar eventos y gráficos sin recompensar Oppat
- La interfaz del navegador es algo así como Windows WPA (Navbar a la izquierda).
- A continuación se muestra la barra de navegación izquierda (menú deslizante del lado izquierdo).
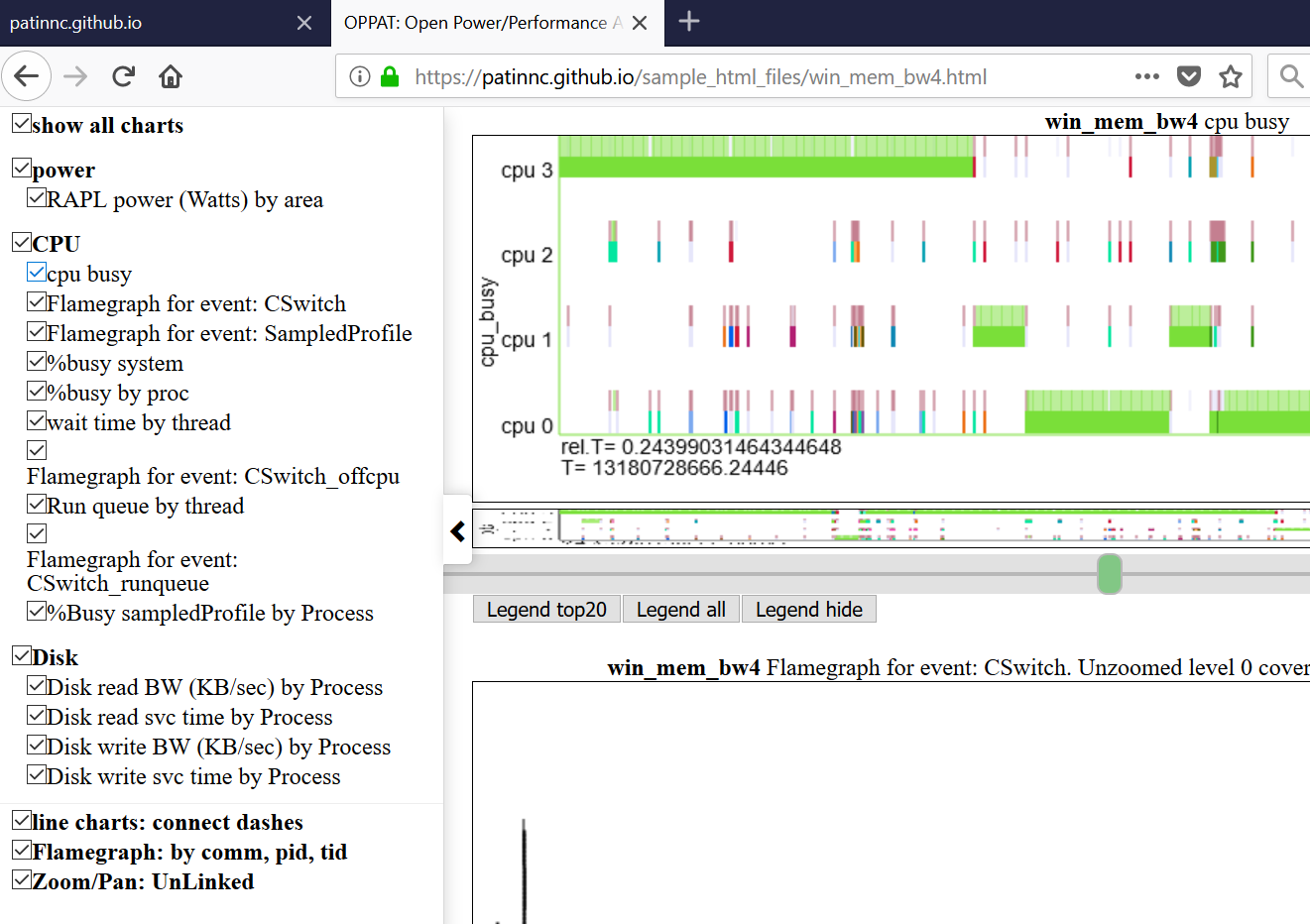
- Los gráficos se agrupan por categoría (GPU, CPU, potencia, etc.)
- Las categorías se definen y se asignan en input_files/charts.json
- Los gráficos pueden estar ocultos o mostrarse selectivamente haciendo clic en la tabla en la barra de navegación.
- Rovering sobre un título de gráfico en el menú de navegación izquierda se desplaza a la vista
- Los datos de un grupo de archivos se pueden trazar junto con un grupo diferente
- Entonces puede decir, compare un rendimiento de performación de Linux frente a un ETW Windows Etw
- A continuación se muestra el uso de Linux vs Windows Power:
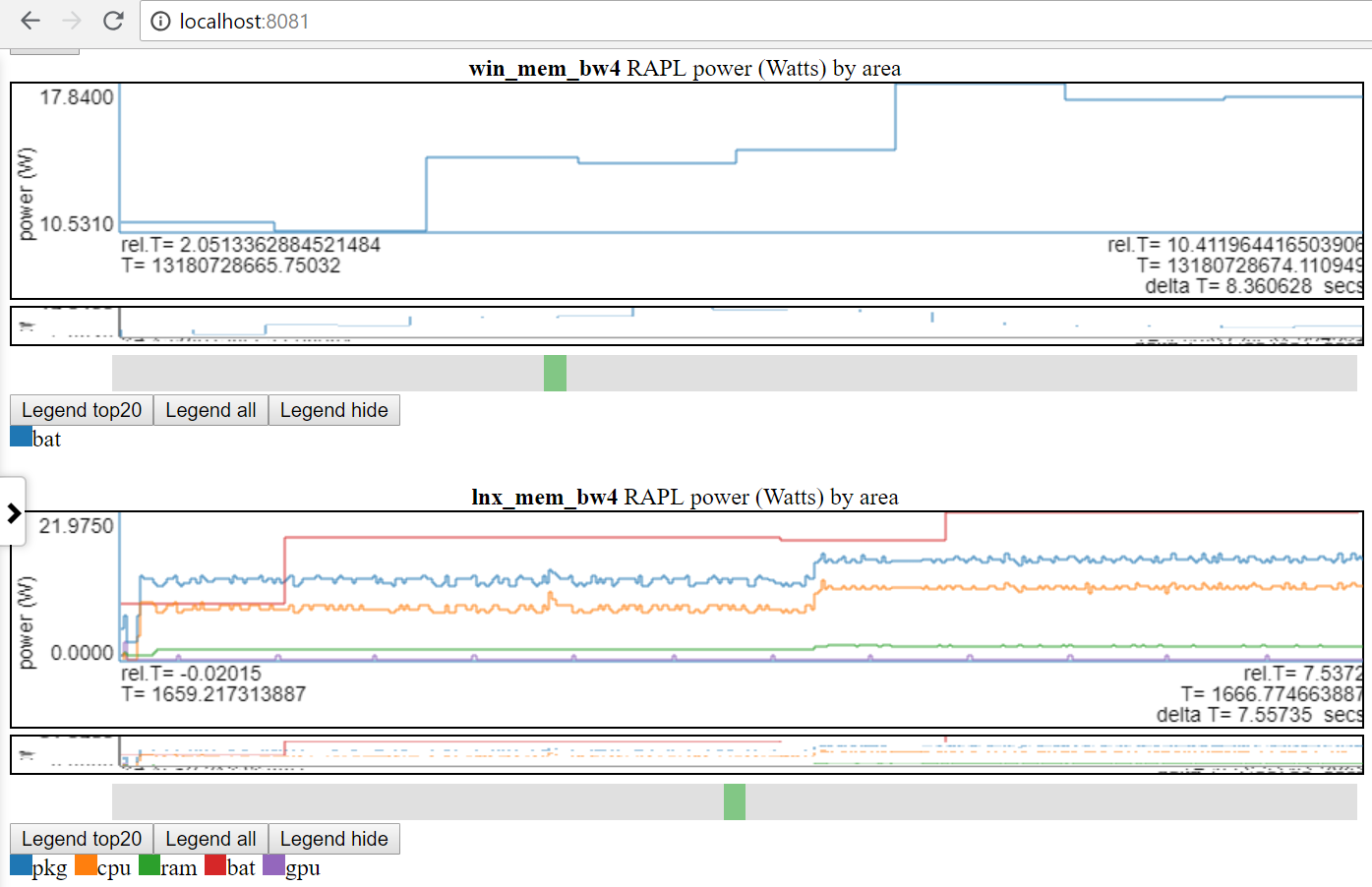
- Solo tengo acceso a la alimentación de la batería tanto en Linux como en Windows.
- Muchos sitios tienen datos de potencia mucho mejores (voltajes/corrientes/potencia a la velocidad de MSEC (o mejor)). Sería fácil incorporar este tipo de datos de potencia (como de Kratos o Qualcomm MDPS), pero no tengo acceso a los datos.
- o comparar 2 ejecuciones diferentes en la misma plataforma
- Una etiqueta de grupo de archivos (file_tag) tiene prefijo el título para distinguir gráficos
- Una 'etiqueta' se define en el archivo File_list.json de Data Dir y/o input_files/input_data_files.json
- El input_files/input_data_files.json es una lista de todos los Dires de datos opatales (pero el usuario tiene que mantenerlo).
- Los gráficos con el mismo título se trazan uno tras otro para permitir una comparación fácil
Características del gráfico:
Rovering sobre una sección de una línea de la tabla muestra el punto de datos para esa línea en ese punto
- Esto no funciona para las líneas verticales, ya que solo están conectando 2 puntos ... solo se busca las piezas horizontales de cada línea el valor de los datos
- A continuación se muestra una captura de pantalla de pasar el evento. Esto muestra el tiempo relativo del evento (CSWTICH), cierta información como Process/PID/TID y el número de línea en el archivo de texto para que pueda obtener más información.

- A continuación se muestra una captura de pantalla que muestra la información de CallStack (si corresponde) para los eventos.

zoom
- zoom ilimitado al nivel de Nanosec y el zoom retrocediendo.
- Probablemente hay órdenes de magnitud más puntos para trazar que los píxeles, por lo que se muestran más datos a medida que se acerca.
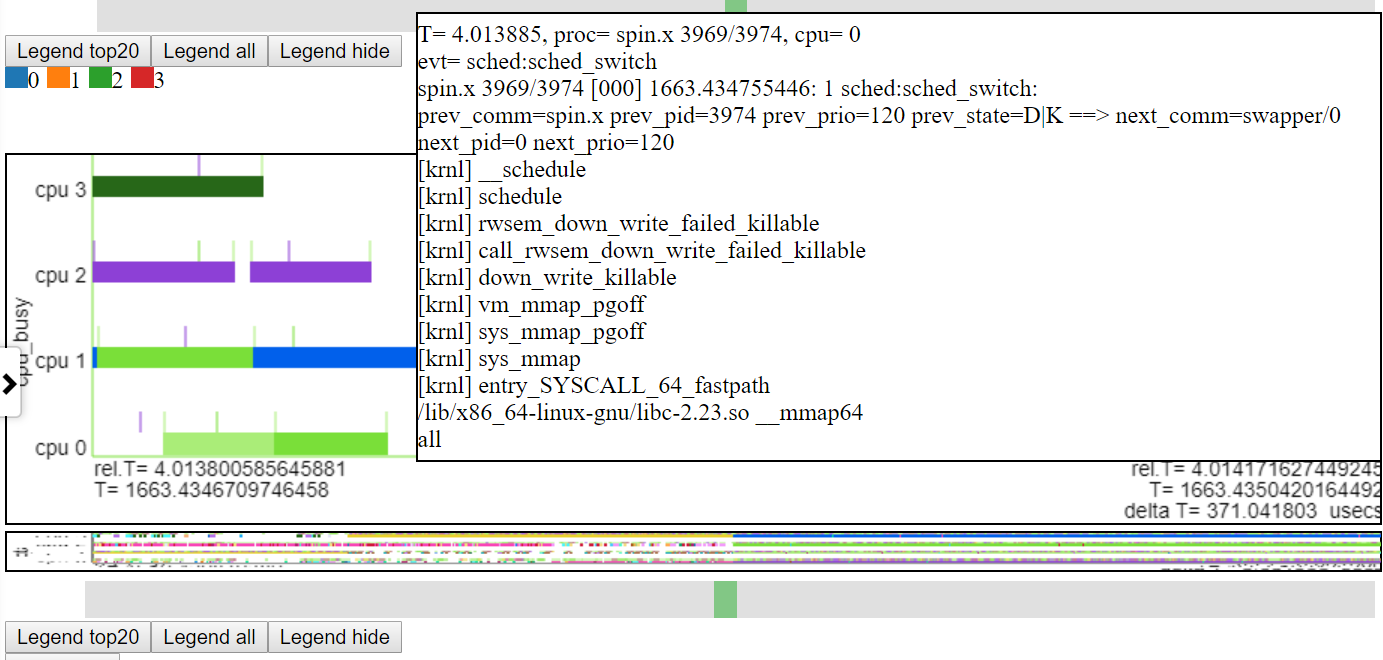
- A continuación se muestra una captura de pantalla que muestra el zoom al nivel de microsegundos. Esto muestra el evento CallStack para Sched_Switch donde Spin.x se bloquea haciendo la operación de mapeo de memoria y está inactivo. La tabla de 'CPU ocupada' muestra 'ir inactiva' como en blanco.
 .
.
- Los gráficos se pueden acercar individualmente o los gráficos con el mismo archivo_tag se pueden vincular para que el zooming/panning 1 sea cambie el intervalo de todos los gráficos con el mismo archivo_tag
- Desplácese hasta la parte inferior de la barra de navegación izquierda y haga clic en 'Zoom/Pan: Unlinked'. Esto cambiará el elemento del menú a 'Zoom/Pan: Linked'. Esto Zoom/Paneará todos los gráficos en un grupo de archivos al tiempo absoluto de Zoom/Pan más reciente. Esto tomará algún tiempo para volver a dibujar todas las listas.
- Inicialmente, cada gráfico se dibuja que muestra todos los datos disponibles. Si sus gráficos son de diferentes fuentes, el T_Begin y T_end (para gráficos de diferentes fuentes) es probablemente diferente.
- Una vez que se realiza una operación de zoom/panorámica y está en vigencia, todos los gráficos en el grupo de archivos se acercarán/pan al mismo intervalo absoluto.
- Esta es la razón por la cual el 'reloj' utilizado para cada fuente tiene que ser el mismo.
- Oppat podría traducirse de un reloj a otro (como entre gettime (clock_monotonic) y gettimeofday ()) pero esa lógica
- Cualquier llama de flameos para un intervalo siempre se acerca al intervalo de 'Propiedad de gráficos' independientemente del estado de enlace.
- Puedes acercar/salir por:
- zoom: la rueda del mouse verticalmente en el área del gráfico. La tabla se acerca al tiempo en el centro de la tabla.
- En mi computadora portátil esto está desplazando 2 dedos verticalmente en el panel táctil
- zoom: haga clic en la tabla y arrastre el mouse hacia la derecha y libere el mouse (el gráfico se acercará al intervalo seleccionado)
- Apare: hacer clic en la tabla y arrastrar el mouse hacia la izquierda y liberar el mouse se alejará en una especie de inversión proporcional a la cantidad de la tabla que seleccionó. Es decir, si dejaste arrastrar casi todo el área del gráfico, entonces el gráfico se alejará ~ 2x. Si acaba de dejar arrastrar un intervalo pequeño, el gráfico se alejará todo el camino.
- Zoom Out: en mi computadora portátil, haciendo un touchpad 2 dedo se desplaza vertical en la dirección opuesta de zoom
- Debe tener cuidado donde está el cursor ... puede ampliar inadvertidamente una tabla cuando quiere desplazar la lista de gráficos. Por lo tanto, generalmente pongo el cursor en el borde izquierdo de la pantalla cuando quiero desplazar los gráficos.
rango
- En mi computadora portátil esto está haciendo 2 dedos en el movimiento de desplazamiento horizontal en el panel táctil
- Usando la caja verde en la miniatura debajo de la tabla
- La panorama funciona a nivel de zoom
- Una imagen de 'miniatura' de la tabla completa se coloca debajo de cada gráfico con un cursor para deslizarse a lo largo de la miniatura para que pueda navegar alrededor de la tabla cuando esté zoom/panorámica
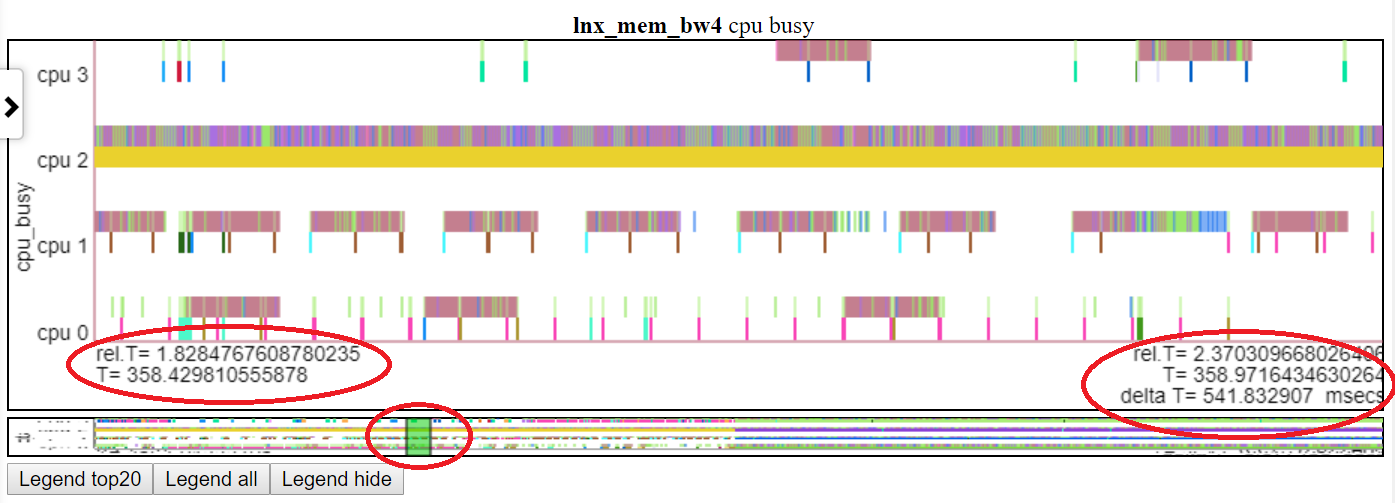
- A continuación muestra la tabla de paneles de 'CPU Busy' a T = 1.8-2.37 segundos. El tiempo relativo y el tiempo de inicio absoluto se resaltan en el óvalo rojo izquierdo. El tiempo de finalización se destaca en el oval rojo del lado derecho. La posición relativa en la miniatura se muestra mediante el oval rojo medio.
 .
.
flotando en una entrada de leyenda de la tabla resalta esa línea.
- A continuación se muestra una captura de pantalla donde se resalta 'PKG' (paquete)
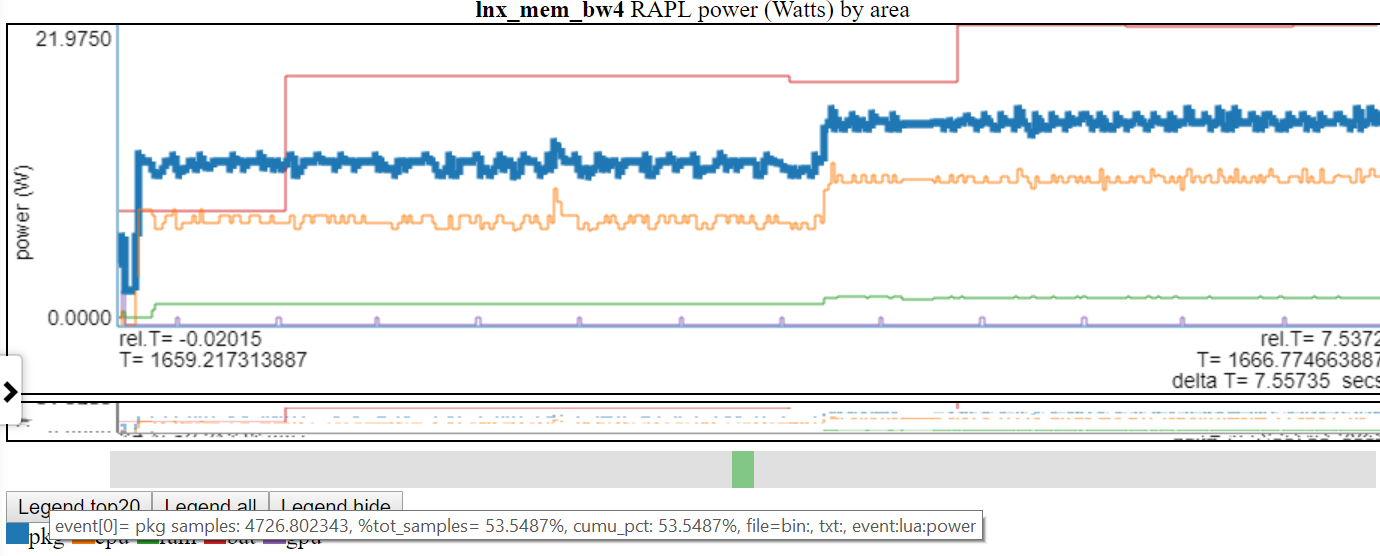
Al hacer clic en una entrada de leyenda de la tabla, alterna la visibilidad de esa línea.
hacer doble clic en una entrada de leyenda solo hace que esa entrada sea visible/oculta
- A continuación se muestra una captura de pantalla donde la potencia 'PKG' se hizo doble clic, por lo que solo la línea PKG es visible.
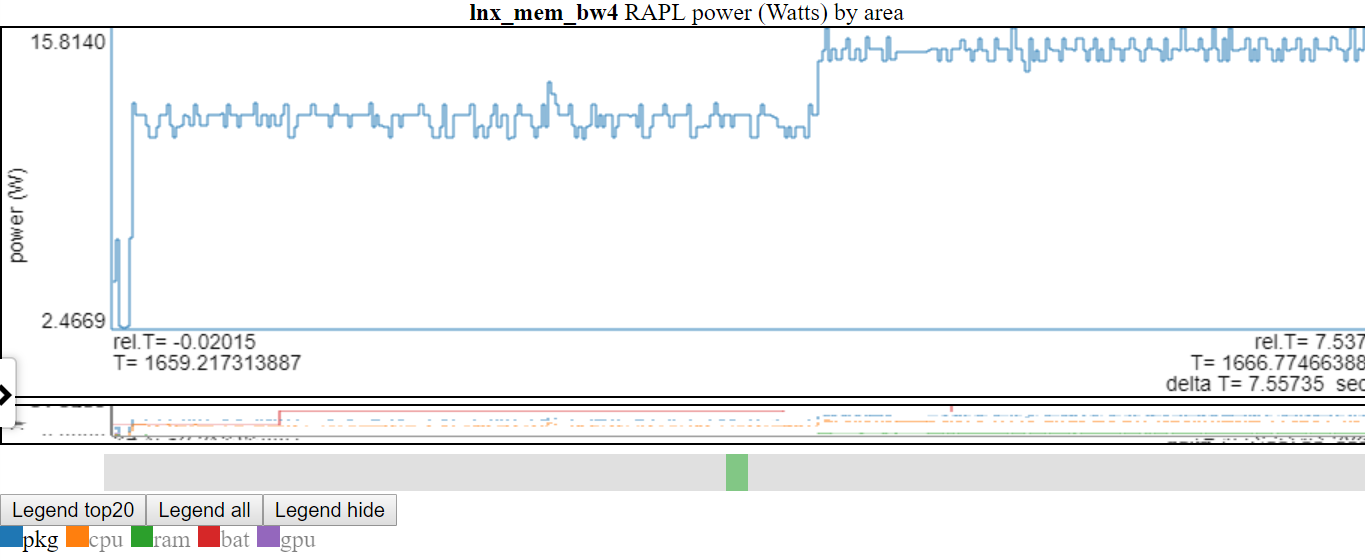
- Arriba muestra que el eje y se ajusta a min/max de las variables mostradas. Las líneas 'no mostradas' son grises en la leyenda. Si se desplaza sobre una línea 'no mostrada' en la leyenda, se dibujará (mientras se desplaza en el elemento de la leyenda). Puede obtener todos los elementos para que se muestren nuevamente haciendo doble clic en una entrada de leyenda 'no desgastada'. Esto mostrará todas las líneas 'no mostradas', pero alternará la línea que acaba de hacer clic ... así que haga clic en el elemento que acaba de hacer doble clic. Sé que suena confuso.
Si se oculta una entrada de leyenda y se desplaza sobre ella, se mostrará hasta que se desplace
Tipos de gráficos:
Gráfico de 'CPU Busy': una tabla similar a Kernelshark que muestra la ocupación de la CPU por PID/hilo. Ver referencia de Kernelshark http://rostedt.homelinux.com/kernelshark/
- A continuación se muestra una captura de pantalla de la tabla ocupada de la CPU. El gráfico muestra, para cada CPU, el proceso/PID/TID ejecutándose en cualquier momento. El proceso inactivo no se dibuja. Para 'CPU 1' en la captura de pantalla, el óvalo verde está alrededor de la parte del 'interruptor de contexto' de la tabla. Por encima de la información del interruptor de contexto de cada CPU, CPU Busy muestra los eventos que se presentan en el mismo archivo que el evento de conmutación de contexto. El óvalo rojo en la línea CPU 1 muestra la parte del evento de la tabla.
- El gráfico se basa en el evento de conmutación de contexto y muestra el hilo que se ejecuta en cada CPU en cualquier momento dado.
- El evento Switch de contexto es el Linux Sched: SHET_SWITCH o el evento Windows ETW CSWitch.
- Si hay más eventos que el interruptor de contexto en el archivo de datos, entonces todos los demás eventos se representan como guiones verticales por encima de la CPU.
- Si los eventos tienen pilas de llamadas, la pila de llamadas también se muestra en el globo emergente
gráficos de línea
- Los gráficos de línea probablemente se llaman con mayor precisión los gráficos de pasos ya que cada evento (hasta ahora) tiene una duración y estas 'duraciones' están representadas por segmentos horizontales y unidos por segmentos verticales.
- La parte vertical del gráfico de pasos puede llenar un gráfico si las líneas de gráfico tienen mucha variación
- Puede seleccionar (en la barra de navegación izquierda) para no conectar los segmentos horizontales de cada línea ... para que el gráfico se convierta en una especie de gráfico de 'tablero disperso'. Los 'guiones horizonatales' son los puntos de datos reales. Cuando cambia de un gráfico de pasos a un diagrama de tablero, el gráfico no se vuelve a dibujar hasta que haya alguna solicitud de 'volver a dibujar' (como zoom/sartén o resaltado (pasando sobre una entrada de leyenda)).
- A continuación se muestra una captura de pantalla de los estados de alimentación CPU_IDLE que usan gráfico de línea. Las líneas de conexión borra la información en el gráfico.
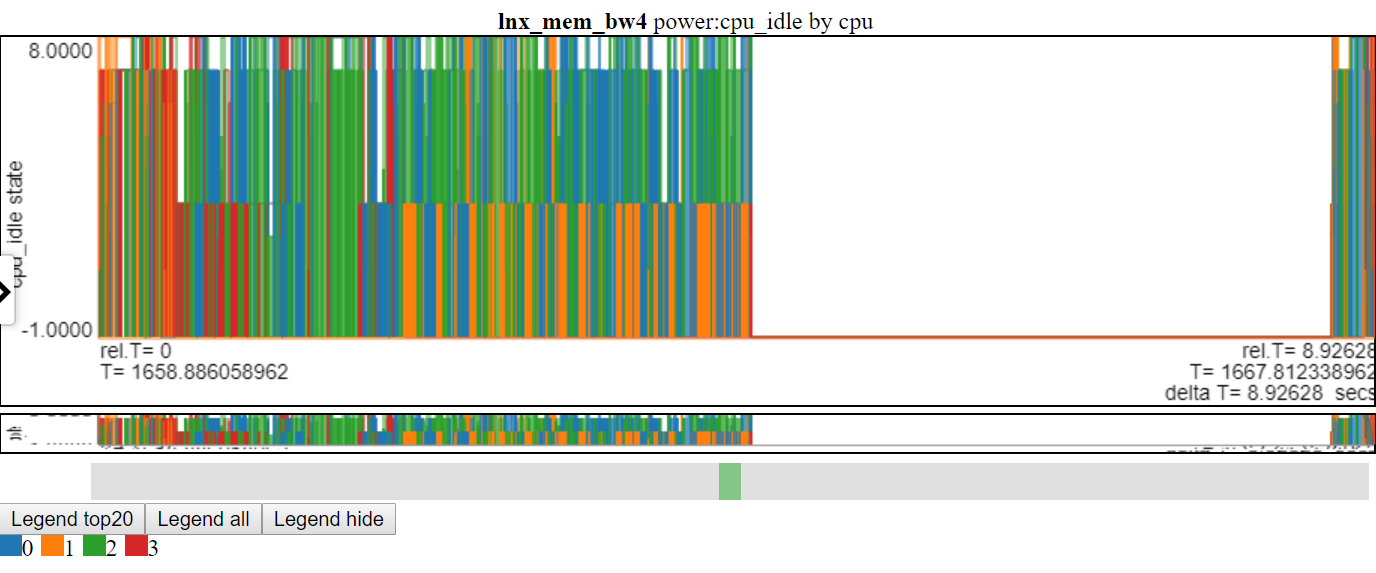
- A continuación se muestra una captura de pantalla de los estados de alimentación CPU_IDLE que usan gráfico de arranque disperso. El gráfico ahora muestra un tablero horizontal para el punto de datos (el ancho del tablero es la duración del evento). Ahora podemos ver más información, pero este gráfico también muestra un inconveniente con mi lógica de gráficos: muchos de los datos están en el valor máximo y en el valor min y del gráfico y se oscurece.
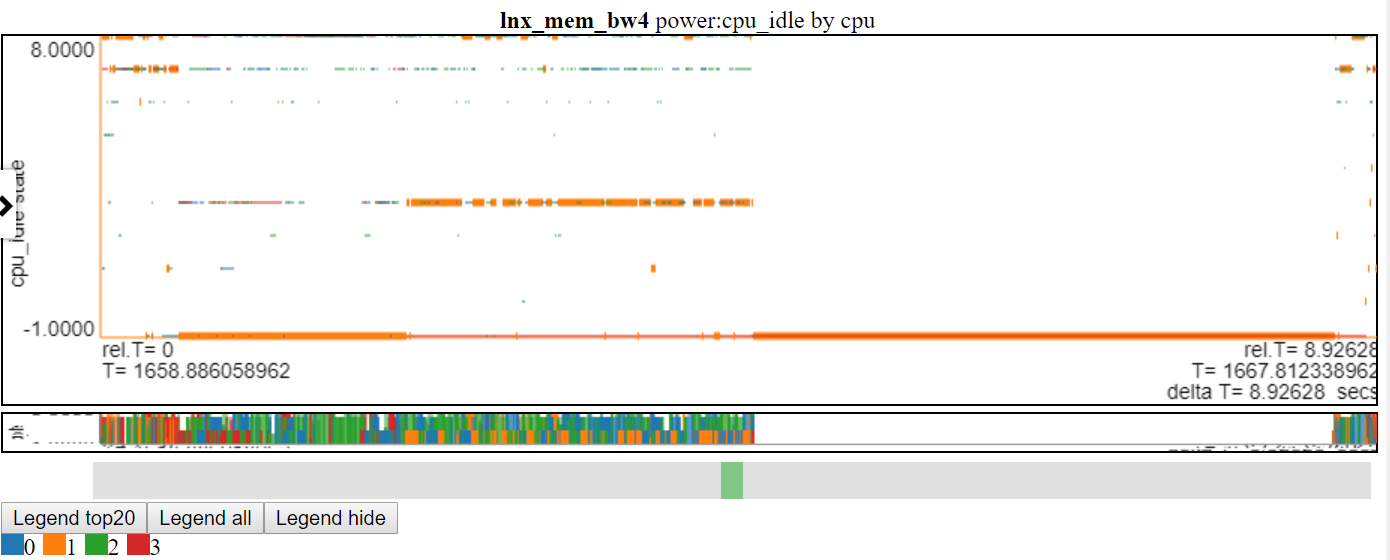
gráficos apilados
- Los gráficos apilados pueden generar muchos más datos que los gráficos de línea. Por ejemplo, dibujar un gráfico de línea de cuándo se ejecuta un hilo en particular solo depende de ese hilo. Dibujar un gráfico apilado para ejecutar hilos es diferente: un evento de conmutación de contexto en cualquier hilo cambiará todos los otros hilos de ejecución ... así que si tiene N CPU, obtendrá N-1 más cosas para dibujar por evento para gráficos apilados.
FlameGraphs. Para cada evento PERF que tiene CallStacks y está en el mismo archivo que el evento SHET_SWITCH/CSWITCH, se crea un FlameGraph.
- A continuación se muestra una captura de pantalla de un típico FlameGraph predeterminado. Por lo general, la altura predeterminada de la tabla de llama no es suficiente para ajustar el texto en cada nivel del flamegraph. Pero aún obtienes la información de CallStack 'flotar'.
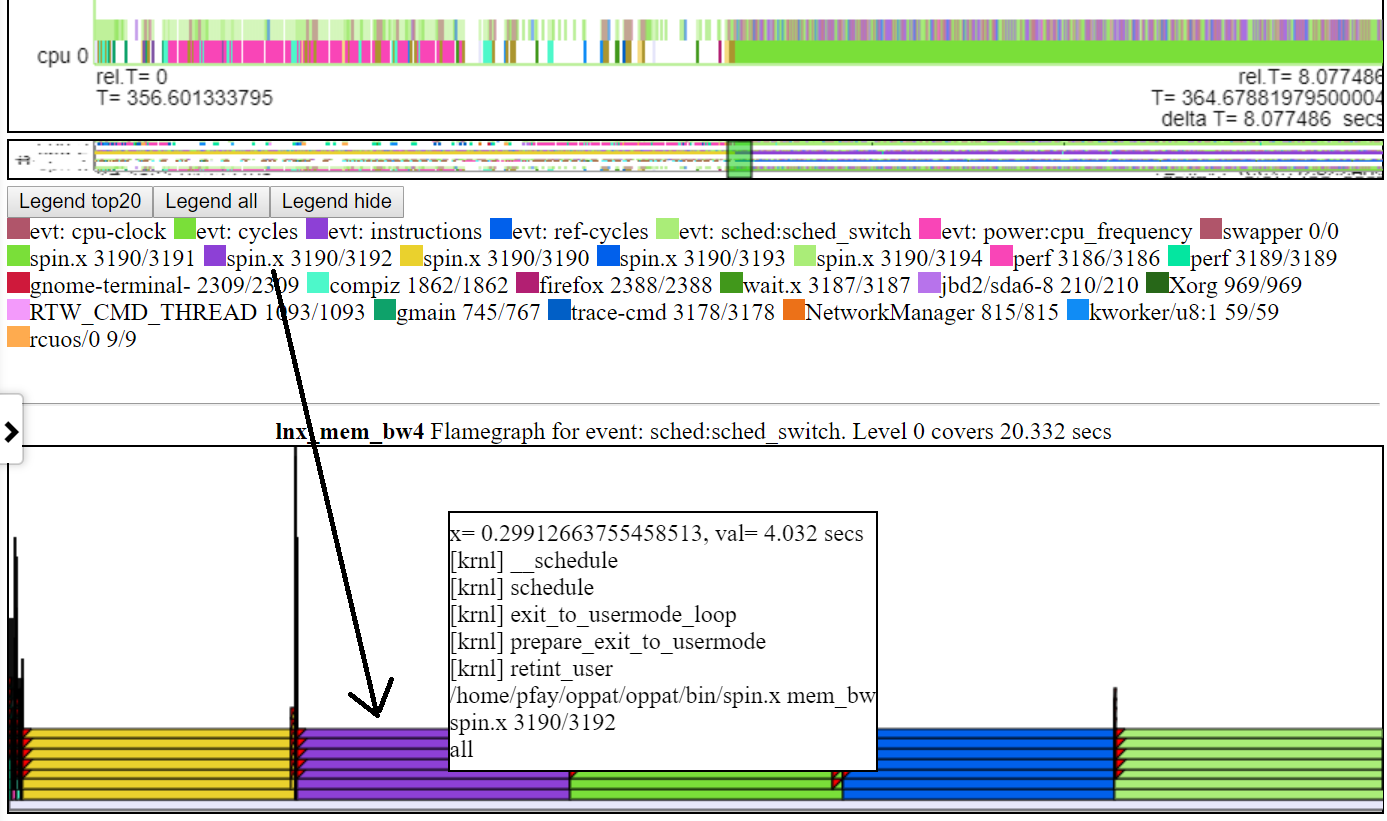 .
.- Si hace clic en la capa de la tabla, se expande más alto de tal manera que el texto se ajusta. Si hace clic en la capa más baja, cubre todos los datos para el intervalo del 'Gráfico de propiedad'.
- A continuación se muestra una captura de pantalla de un flamegraph zoom (después de hacer clic en una de las capas de una llama).
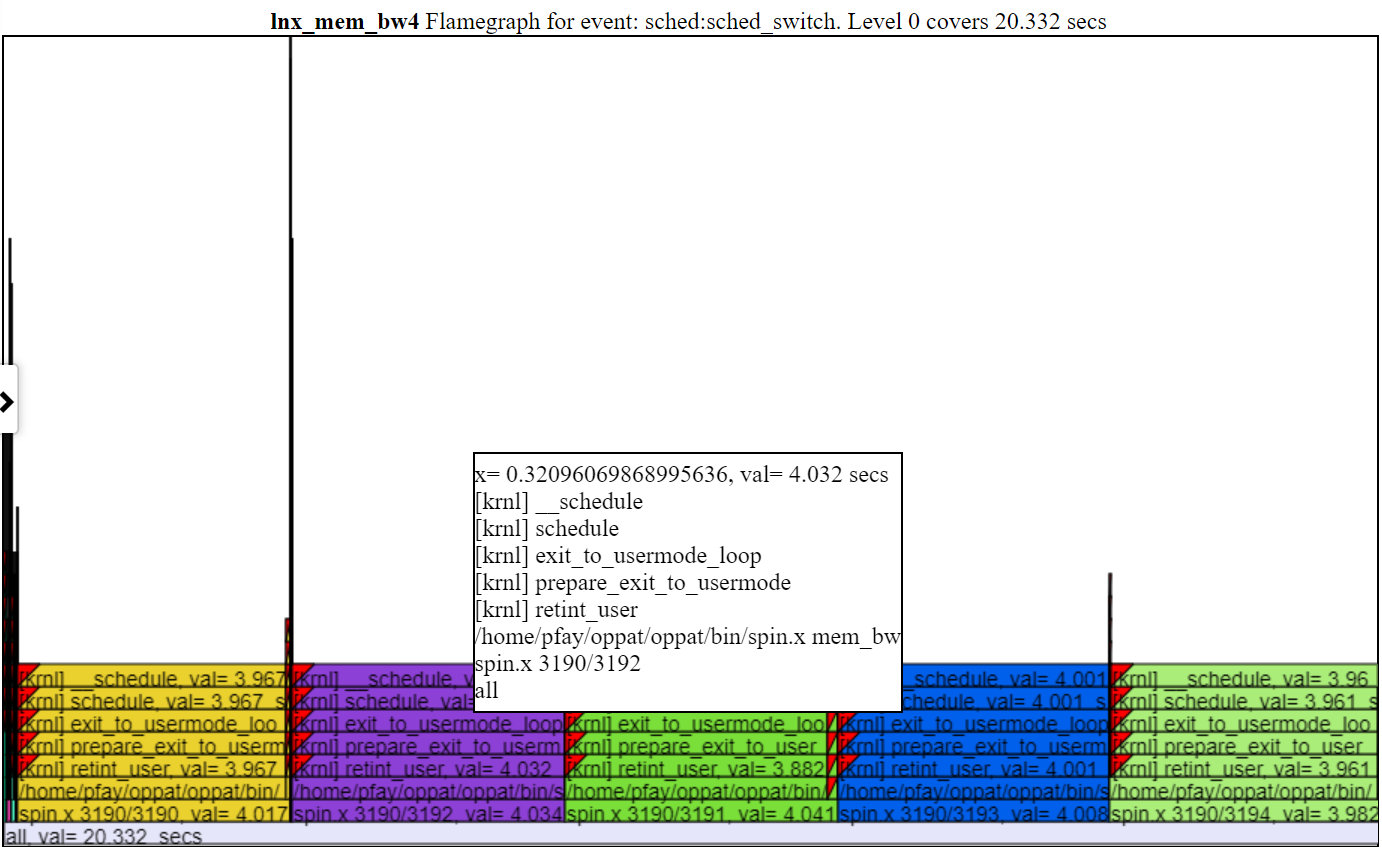 .
.- Por lo general, la altura predeterminada de la tabla de llama no es suficiente para ajustar el texto en cada nivel del flamegraph. Pero aún obtienes la información de CallStack 'flotar'.
- El color del flamegraph coincide con el proceso/pid/tid en la leyenda del gráfico CPU_BUSY ... por lo que no es tan bonito como un flamegraph, pero ahora el color de una 'llama' en realidad significa algo.
- El gráfico CPI (relojes por instrucción) colorea la gráfico de flameos para el proceso/PID/tid por el IPC para esa pila.
- A continuación se muestra una muestra de gráfico de IPC sin zarzo. La instancia de la izquierda de Spin.x (en naranja claro) tiene un IPC = 2.26 ciclos/instrucción. Los 4 spin.x a la derecha en verde claro tienen un CPI = 6.465.
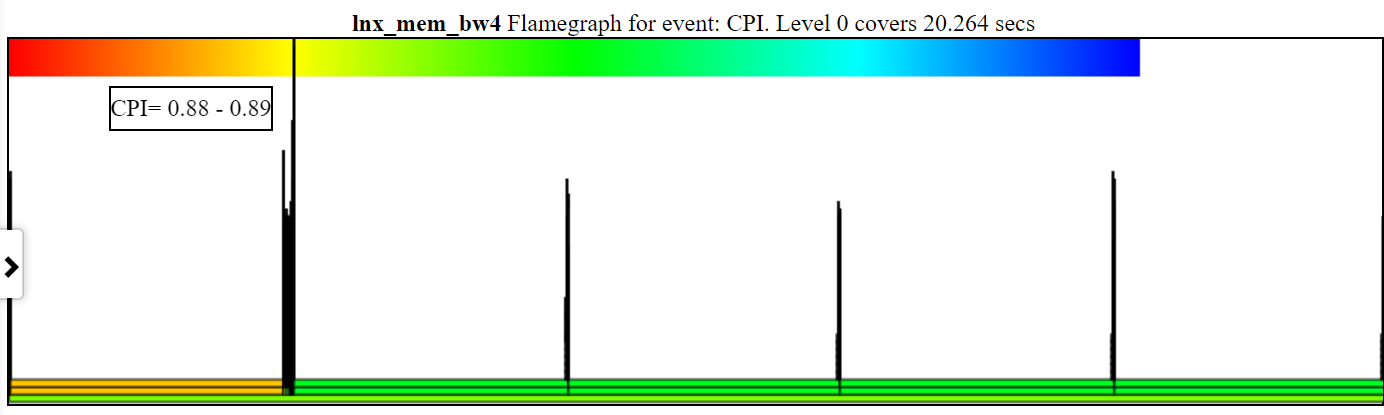
- Debe tener ciclos, instrucciones y CPU-Clock (o Sched_switch) CallStacks
- El ancho del CPI 'Flame' se basa en el tiempo de Clock CPU.
- El color se basa en el IPC. Un gradiente rojo a verde a azul en la parte superior izquierda de la tabla muestra la coloración.
- El rojo es un IPC bajo (por lo que muchas instrucciones por reloj ... considero que es "caliente")
- El azul es un IPC alto (tan pocas instrucciones por reloj ... Pienso en ello como 'frío')
- A continuación se muestra una muestra de la tabla de CPI con zoom que muestra la coloración y el IPC. Los hilos 'spin.x' han sido deseleccionados en la leyenda CPU_BUSY para que no aparezcan en el flamegraph.
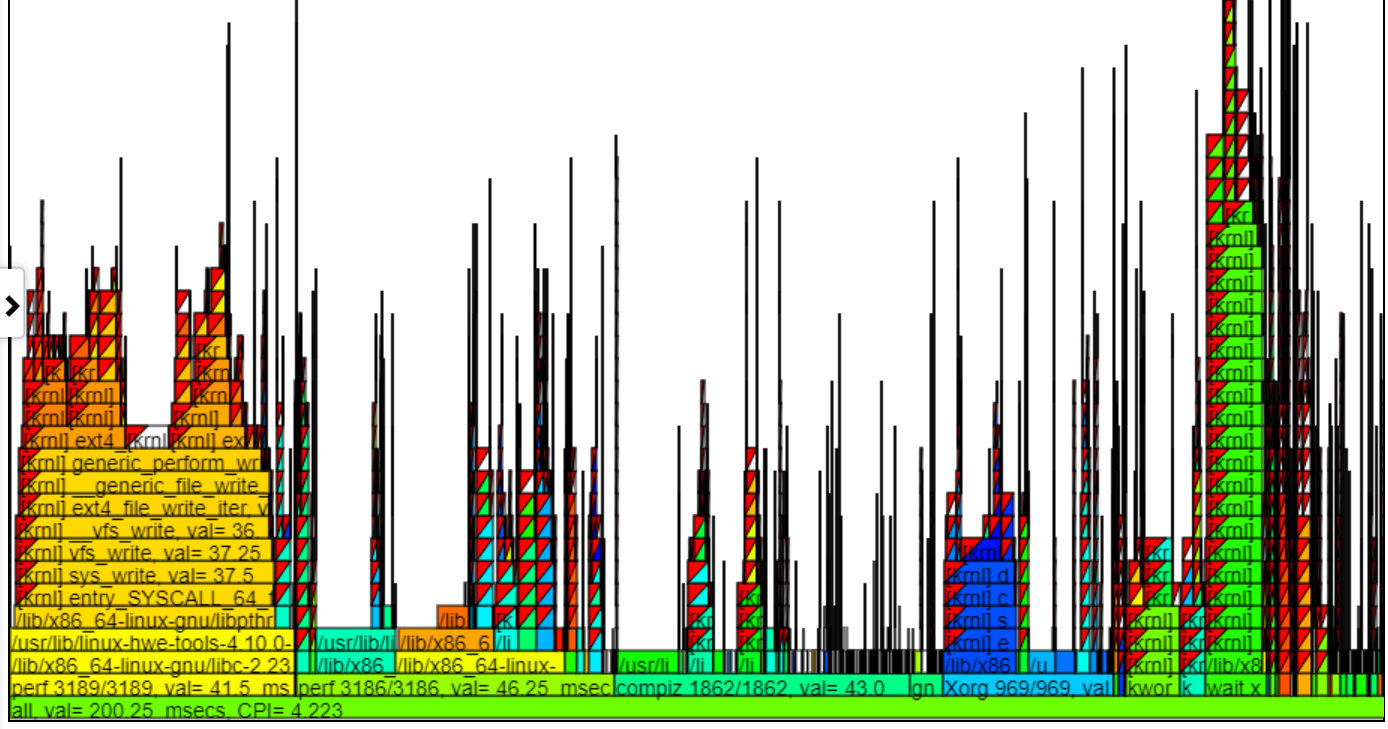
- Las instrucciones GIPS (GIGA (mil millones) por segundo) gráfica de flamegraph coloran el proceso/pid/tid por los GIPS para esa pila.
- A continuación se muestra una muestra de GIPS sin zarzo (GIGA/mil millones de instrucciones por segundo). La instancia de la izquierda de Spin.x (en verde claro) tiene un GIPS = 1.13. Los 4 spin.x a la derecha en verde azul tienen un GIPS = 0.377. El Callstack en el globo es para uno de los Spike Callstacks a la izquierda del globo.

- En el gráfico anterior, tenga en cuenta que la pila de la mano izquierda (para spin.x) obtiene instrucciones/seg más altas que las 4 instancias más derecha de spin.x. Esta primera instancia de Spin.x se ejecuta por sí misma (por lo que obtiene mucha memoria BW) y los hilos de 4 spin.x correctos se ejecutan en paralelo y obtienen un GIPS más bajo (ya que un hilo puede casi maximizar la memoria BW).
- Debe tener instrucciones y CPU-Clock (o Sched_Switch) CallStacks
- El ancho de la 'llama' de los GIPS se basa en el tiempo de Clock CPU.
- El color se basa en los GIPS. Un gradiente rojo a verde a azul en la parte superior izquierda de la tabla muestra la coloración.
- El rojo es un GIPS alto (así que muchas instrucciones por segundo ... considero que es "caliente" haciendo mucho trabajo)
- El azul es un GIPS bajo (tan pocas instrucciones por segundo ... Pienso en ello como 'frío')
- A continuación se muestra una muestra de la tabla de GIPS zoom zoom que muestra la coloración y los GIP. Hice clic en el 'PERF 3186/3186', por lo que solo esa llama se muestra a continuación.
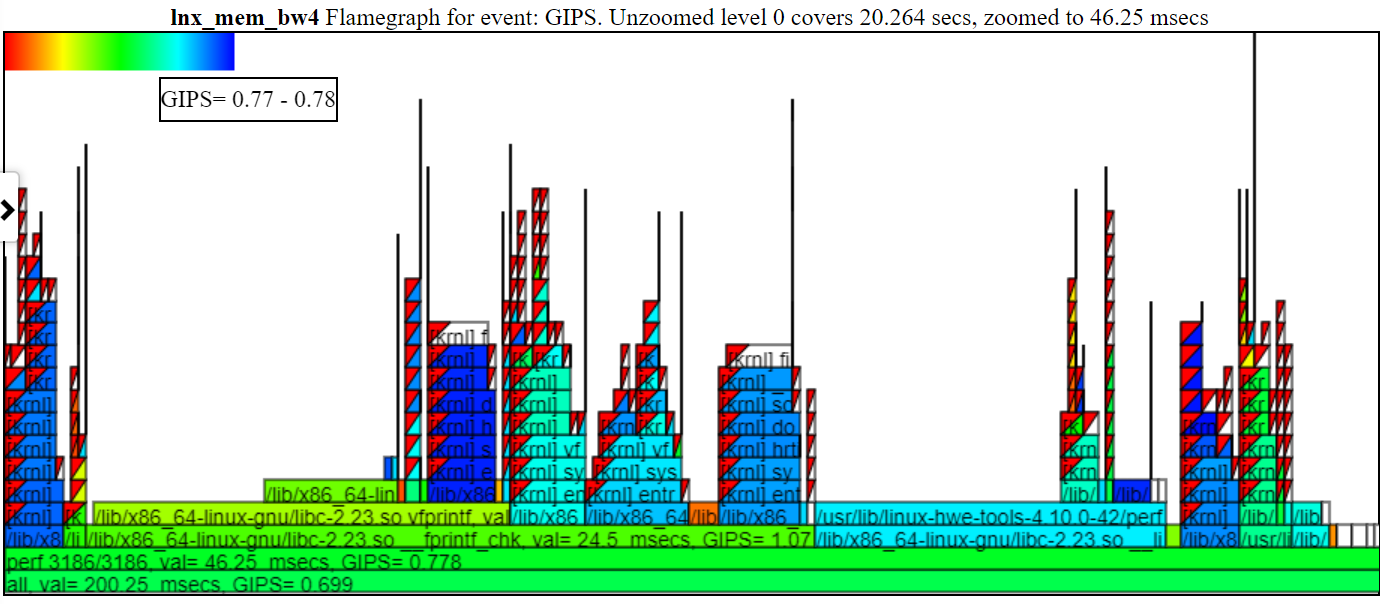
- Si esconde un proceso en la leyenda (haga clic en la entrada de la leyenda ... será atenuado), entonces el proceso no se mostrará en el flamegraph.
- Si está correctamente, arrastre el mouse en el flamegraph, esa sección del flamegraph se acercará
- Haga clic en un zoom de 'Flame' a esa llama
- Izquierda arrastrando el mouse en el flamegraph se alejará
- Al hacer clic en un nivel más bajo del flamegraph 'sin zarzo' a todos los datos para ese nivel
- Si hace clic en el nivel más bajo 'All' del FlameGraph, se alejará todo el camino.
- Cuando hace clic en el nivel de FlameGraph, el gráfico se redimensiona para que cada nivel sea lo suficientemente alto como para mostrar el texto. Esto hace que el gráfico cambie de tamaño. Para intentar agregar algo de cordura a este cambio de tamaño, coloco el último nivel del gráfico redimensionado hasta la parte inferior de la pantalla visible.
- Si vuelve a la leyenda y se desplaza sobre una entrada oculta, entonces esa entrada se mostrará en la llama hasta que salga a pasar el rato
- Si hace clic en un nivel superior de 'Llama', entonces solo esa sección se acercará.
- Si se acerca/sale en la tabla 'Padre', los FlameGraphs se volverán a dibujar para el intervalo seleccionado
- Si se desplaza a la izquierda/derecha en la tabla 'padre', entonces los flamages serán rediseñados para el intervalo seleccionado
- Por defecto, el texto de cada nivel del gráfico de la llama probablemente no se ajuste. Si hace clic en FlameGraph, el tamaño se ampliará para habilitar el dibujo del texto también
- Puede seleccionar (en la barra de navegación izquierda) si se debe agrupar los flamesgrafs por proceso/pid/tid o por proceso/pid o simplemente proceso.
- Se dibujan 'en CPU', 'Off CPU' y 'Run Queue' FlameGraphs.
- 'En CPU' es el Callstack de lo que el hilo estaba haciendo mientras se ejecutaba en la CPU ... así que el SampledProfile CallStacks o el CallStacks de CPU-Clock de perforación indican lo que el hilo estaba haciendo cuando estaba funcionando en la CPU
- Se muestran 'Off CPU', para hilos que no funcionan, cuánto tiempo estaban esperando y el Callstack cuando se cambiaron.
- A continuación se muestra una captura de pantalla de la tabla OFF-CPU o de tiempo de espera. La ventana emergente muestra (en el FlameGraph) que 'Wait.x' está esperando a Nanos Sleep.

- El intercambio de 'estado' (y en ETW la 'razón') se muestra como un nivel por encima del proceso. Por lo general, la mayoría de los hilos estarán durmiendo o no se ejecutarán, pero esto ayuda a responder la pregunta: "Cuando mi hilo no funcionó ... ¿qué estaba esperando?".
- Mostrar el 'estado' para el interruptor de contexto le permite ver:
- Por ejemplo, si un hilo está esperando un sueño no interrumpible (estado == D en Linux ... generalmente io)
- sueño interrumpible (estado = s ... frecuentemente un nanoSleep o futex)
- 'Run Queue' muestra los hilos que se intercambiaron y estaban en un estado de ejecución o ejecutable. Entonces, este gráfico muestra la saturación de la CPU si hay hilos en un estado ejecutable pero no en ejecución.
- A continuación se muestra la captura de pantalla de la tabla Run_queue. Este gráfico muestra la cantidad de tiempo que no se ejecutó un hilo porque no había suficiente CPU. Es decir, estaba listo para funcionar, pero algo más estaba usando la CPU. Cada llama muestra el total cubierto en el gráfico. En el caso de la tabla Run_queue, muestra ~ 159 ms en el tiempo de espera. Entonces, dado que Spin.x tiene alrededor de 20 segundos de tiempo de ejecución y 0.159 SECS 'Wait' Time, eso no parece tan malo.
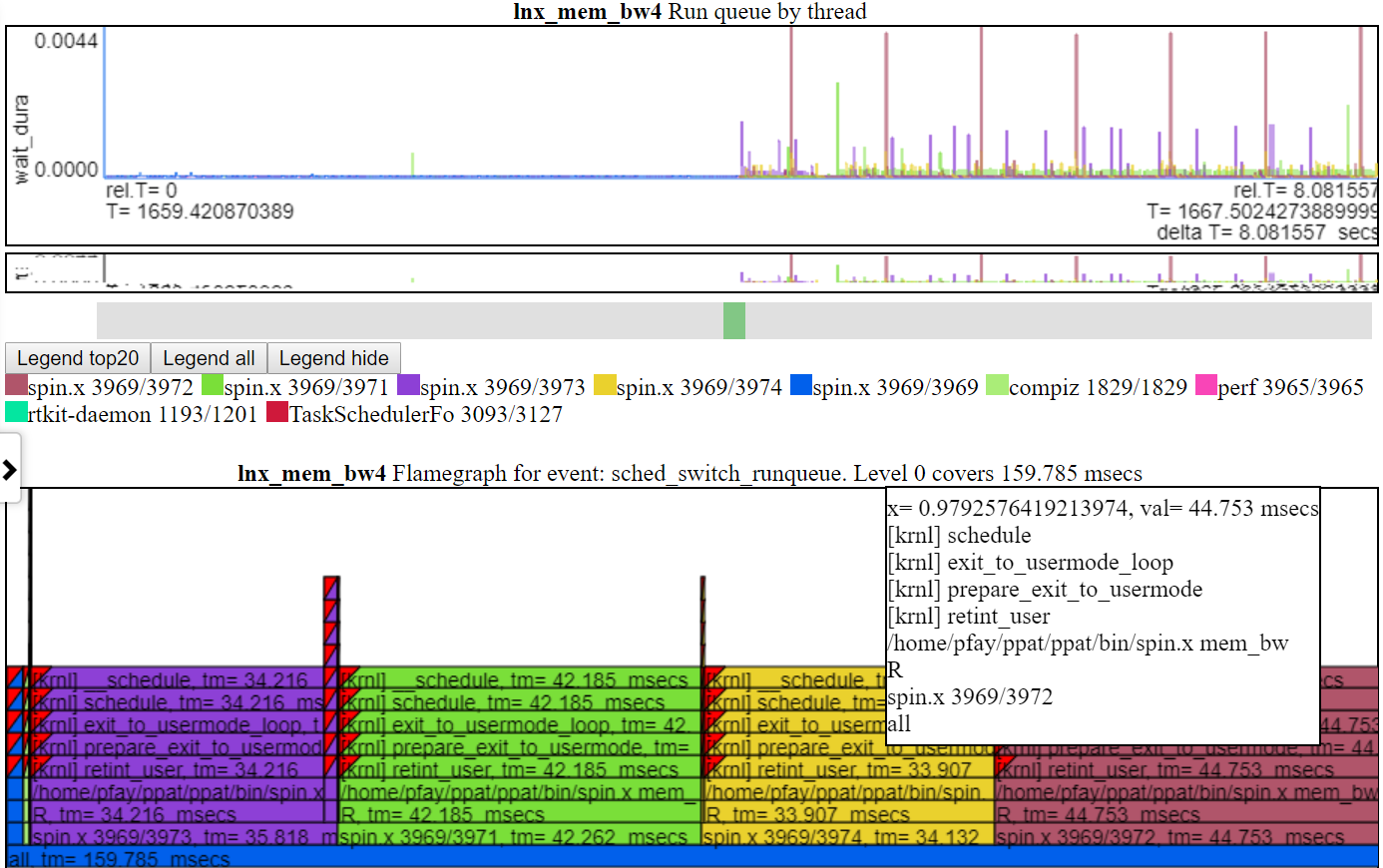
No tenía una biblioteca de gráficos basada en lienzo para usar, por lo que los gráficos son un poco crudos ... No quería pasar demasiado tiempo creando los gráficos si hay algo mejor por ahí. Los gráficos deben usar el lienzo HTML (no SVGS, D3.JS, etc.) debido a la cantidad de datos.
Recopilación de datos para Oppat
La recopilación de datos de rendimiento y potencia es muy "situacional". Una persona querrá ejecutar scripts, otra querrá iniciar medidas con un botón, luego iniciar un video y luego finalizar la colección con la presión de un botón. Tengo un script para Windows y un script para Linux que demuestra:
- recopilación de datos inicial,
- ejecutar una carga de trabajo,
- Detener la recopilación de datos
- Postprocese los datos (creando un archivo de texto a partir de los datos binarios perf/xperf/trace-cmd)
- Poner todos los archivos de datos en un Dir de salida
- Creación de un archivo file_list.json en el Dir de salida (que le dice a Oppat el nombre y el tipo de los archivos de salida)
Los pasos para la recopilación de datos utilizando los scripts:
- Construir spin.exe (spin.x) y wait.exe (wait.x) utilidades
- Desde el directorio de la raíz opcat do:
- En Linux:
./mk_spin.sh - En Windows :
.mk_spin.bat (desde un cuadro CMD de Visual Studio) - Los binarios se colocarán en el ./bin subdir
- Comience con la ejecución de los scripts proporcionados:
- run_perf_x86_haswell.sh - para la recopilación de datos de Haswell CPU_DIAGRAM
- En Linux, escriba:
sudo bash ./scripts/run_perf.sh - Por defecto, el script coloca los datos en dir ../oppat_data/lnx/mem_bw7
- run_perf.sh: debe tener rastreo y perfil
- En Linux, escriba:
sudo bash ./scripts/run_perf.sh - Por defecto, el script coloca los datos en dir ../oppat_data/lnx/mem_bw4
- run_xperf.bat: debe tener instalado xperf.exe.
- En Windows, desde un cuadro CMD con privilegios de administración, escriba :
.scriptsrun_xperf.sh - Por defecto, el script coloca los datos en dir .. oppat_data win mem_bw4
- Editar el script Ejecutar si desea cambiar los valores predeterminados
- Además de los archivos de datos, el script Ejecutar crea un archivo file_list.json en el directorio de salida. Oppat usa el archivo file_list.json para descubrir los nombres de archivo y el tipo de archivos en el directorio de salida.
- La 'carga de trabajo' para el script Ejecutar es spin.x (o spin.exe) que realiza una prueba de ancho de banda de memoria en 1 CPU durante 4 segundos y luego en todas las CPU durante otros 4 segundos.
- Otro programa Wait.x/Wait.exe también se inicia en segundo plano. Wait.cpp lee la información de la batería para mi computadora portátil. Funciona en mi computadora portátil Dual Boot Windows 10/Linux Ubuntu. El archivo SYSFS puede tener un nombre diferente en su Linux y casi seguramente es diferente en Android.
- En Linux, probablemente podría generar un archivo prf_trace.data y prf_trace.txt usando la misma sintaxis que en run_perf.sh, pero no lo he probado.
- Si se ejecuta en una computadora portátil y desea obtener la batería, recuerde desconectar el cable de alimentación antes de ejecutar el script.
Soporte de datos de PCM
- Oppat puede leer y trazar archivos PCM .CSV.
- A continuación se muestra una instantánea de la lista de gráficos creados.
- Desafortunadamente, debe hacer un parche a PCM para crear un archivo con una marca de tiempo absoluta para que el Oppat procese.
- Esto se debe a que el archivo CSV PCM no tiene una marca de tiempo que pueda usar para correlacionar con las otras fuentes de datos.
- He agregado el parche aquí PCM Patch
Edificio Oppat
- En Linux, escriba
make en el directorio de raíz opcat- Si todo funciona, debería haber un archivo bin/oppat.x
- En Windows, necesitas:
- Instale la versión de Windows de GNU. Consulte http://gnuwin32.sourceforge.net/packages/make.htm o, para los binarios mínimos requeridos, use http://gnuwin32.sourceforge.net/downlinks/make.php
- Pon este nuevo 'hacer' binario en el camino
- Necesita un compilador actual de Visual Studio 2015 o 2017 C ++ (utilicé tanto el VS 2015 Professional como los compiladores comunitarios VS 2017)
- Iniciar un cuadro de solicitud CMD nativo de Windows Visual Studio X64
- escriba
make en el directorio de la raíz opcat - Si todo funciona, debería haber un archivo bin oppat.exe
- Si está cambiando el código fuente, probablemente necesite reconstruir el archivo de dependencia de incluir
- Necesitas tener Perl instalado
- En Linux, en la raíz opatista Dir do:
./mk_depends.sh . Esto creará un archivo de dependencia depends_lnx.mk. - on Windows, in the OPPAT root dir do:
.mk_depends.bat . This will create a depends_win.mk dependency file.
- If you are going to run the sample run_perf.sh or run_xperf.bat scripts, then you need to build the spin and wait utilities:
- On Linux:
./mk_spin.sh - On Windows:
.mk_spin.bat
Running OPPAT
- Run the data collection steps above
- now you have data files in a dir (if you ran the default run_* scripts:
- on Windows ..oppat_datawinmem_bw4
- on Linux ../oppat_data/lnx/mem_bw4
- You need to add the created files to the input_filesinput_data_files.json file:
- Starting OPPAT reads all the data files and starts the web server
- on Windows to generate the haswell cpu_diagram (assuming your data dir is ..oppat_datalnxmem_bw7)
binoppat.exe -r ..oppat_datalnxmem_bw7 --cpu_diagram webhaswell_block_diagram.svg > tmp.txt
- on Windows (assuming your data dir is ..oppat_datawinmem_bw4)
binoppat.exe -r ..oppat_datawinmem_bw4 > tmp.txt
- on Linux (assuming your data dir is ../oppat_data/lnx/mem_bw4)
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 > tmp.txt
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 --web_file tst2.html > tmp.txt
- Then you can load the file into the browser with the URL address:
file:///C:/some_path/oppat/tst2.html
Derived Events
'Derived events' are new events created from 1 or more events in a data file.
- Say you want to use the ETW Win32k InputDeviceRead events to track when the user is typing or moving the mouse.
- ETW has 2 events:
- Microsoft-Windows-Win32k/InputDeviceRead/win:Start
- Microsoft-Windows-Win32k/InputDeviceRead/win:Stop
- So with the 2 above events we know when the system started reading input and we know when it stopped reading input
- But OPPAT plots just 1 event per chart (usually... the cpu_busy chart is different)
- We need a new event that marks the end of the InputDeviceRead and the duration of the event
- The derived event needs:
- a new event name (in chart.json... see for example the InputDeviceRead event)
- a LUA file and routine in src_lua subdir
- 1 or more 'used events' from which the new event is derived
- the derived events have to be in the same file
- For the InputDeviceRead example, the 2 Win32k InputDeviceRead Start/Stop events above are used.
- The 'used events' are passed to the LUA file/routine (along with the column headers for the 'used events') as the events are encountered in the input trace file
- In the InputDeviceRead lua script:
- the script records the timestamp and process/pid/tid of a 'start' event
- when the script gets a matching 'Stop' event (matching on process/pid/tid), the script computes a duration for the new event and passes it back to OPPAT
- A 'trigger event' is defined in chart.json and if the current event is the 'trigger event' then (after calling the lua script) the new event is emitted with the new data field(s) from the lua script.
- An alternate to the 'trigger event' method is to have the lua script indicate whether or not it is time to write the new event. For instance, the scr_lua/prf_CPI.lua script writes a '1' to a variable named ' EMIT ' to indicate that the new CPI event should be written.
- The new event will have:
- the name (from the chart.json evt_name field)
- The data from the trigger event (except the event name and the new fields (appended)
- I have tested this on ETW data and for perf/trace-cmd data
Using the browser GUI Interface
TBD
Defining events and charts in charts.json
TBD
Rules for input_data_files.json
- The file 'input_files/input_data_files.json' can be used to maintain a big list of all the data directories you have created.
- You can then select the directory by just specifying the file_tag like:
- bin/oppat.x -u lnx_mem_bw4 > tmp.txt # assuming there is a file_tag 'lnx_mem_bw4' in the json file.
- The big json file requires you to copy the part of the data dir's file_list.json into input_data_files.json
- in the file_list.json file you will see lines like:
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- don't copy the lines like below from the file_list.json file:
- paste the copied lines into input_data_files.json. Pay attention to where you paste the lines. If you are pasting the lines at the top of input_data_files.json (after the
{"root_dir":"/data/ppat/"}, then you need add a ',' after the last pasted line or else JSON will complain. - for Windows data files add an entry like below to the input_filesinput_data_files.json file:
- yes, use forward slashes:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- for Linux data files add an entry like below to the input_filesinput_data_files.json file:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/lnx/mem_bw4 " },
{ "cur_tag" : " lnx_mem_bw4 " },
{ "bin_file" : " prf_energy.txt " , "txt_file" : " prf_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " },
{ "bin_file" : " prf_trace.data " , "txt_file" : " prf_trace.txt " , "tag" : " %cur_tag% " , "type" : " PERF " },
{ "bin_file" : " tc_trace.dat " , "txt_file" : " tc_trace.txt " , "tag" : " %cur_tag% " , "type" : " TRACE_CMD " },- Unfortunately you have to pay attention to proper JSON syntax (such as trailing ','s)
- Here is an explanation of the fields:
- The 'root_dir' field only needs to entered once in the json file.
- It can be overridden on the oppat cmd line line with the
-r root_dir_path option - If you use the
-r root_dir_path option it is as if you had set "root_dir":"root_dir_path" in the json file - the 'root_dir' field has to be on a line by itself.
- The cur_dir field applies to all the files after the cur_dir line (until the next cur_dir line)
- the '%root_dir% string in the cur_dir field is replaced with the current value of 'root_dir'.
- the 'cur_dir' field has to be on a line by itself.
- the 'cur_tag' field is a text string used to group the files together. The cur_tag field will be used to replace the 'tag' field on each subsequent line.
- the 'cur_tag' field has to be on a line by itself.
- For now there are four types of data files indicated by the 'type' field:
- type:PERF These are Linux perf files. OPPAT currently requires both the binary data file (the bin_file field) created by the
perf record cmd and the perf script text file (the txt_file field). - type:TRACE_CMD These are Linux trace-cmd files. OPPAT currently requires both the binary dat file (the bin_file field) created by the
trace-cmd record cmd and the trace-cmd report text file (the txt_file field). - type:ETW These are Windows ETW xperf data files. OPPAT currently requires only the text file (I can't read the binary file). The txt_file is created with
xperf ... -a dumper command. - type:LUA These files are all text files which will be read by the src_lua/test_01.lua script and converted to OPPAT data.
- the 'prf_energy.txt' file is
perf stat output with Intel RAPL energy data and memory bandwidth data. - the 'prf_energy2.txt' file is created by the wait utility and contains battery usage data in the 'perf stat' format.
- the 'wait.txt' file is created by the wait utility and shows the timestamp when the wait utility began
- Unfortunately 'perf stat' doesn't report a high resolution timestamp for the 'perf stat' start time
Limitaciones
- The data is not reduced on the back-end so every event is sent to the browser... this can be a ton of data and overwhelm the browsers memory
- I probably should have some data reduction logic but I wanted to get feedback first
- You can clip the files to a time range:
oppat.exe -b abs_beg_time -e abs_beg_time to reduce the amout of data- This is a sort of crude mechanism right now. I just check the timestamp of the sample and discard it if the timestamp is outside the interval. If the sample has a duration it might actually have data for the selected interval...
- There are many cases where you want to see each event as opposed to averages of events.
- On my laptop (with 4 CPUs), running for 10 seconds of data collection runs fine.
- Servers with lots of CPUs or running for a long time will probably blow up OPPAT currently.
- The stacked chart can cause lots of data to be sent due to how it each event on one line is now stacked on every other line.
- Limited mechanism for a chart that needs more than 1 event on a chart...
- say for computing CPI (cycles per instruction).
- Or where you have one event that marks the 'start' of some action and another event that marks the 'end' of the action
- There is a 'derived events' logic that lets you create a new event from 1 or more other events
- See the derived event section
- The user has to supply or install the data collection software:
- on Windows xperf
- See https://docs.microsoft.com/en-us/windows-hardware/get-started/adk-install
- You don't need to install the whole ADK... the 'select the parts you want to install' will let you select just the performance tools
- on Linux perf and/or trace-cmd
sudo apt-get install linux-tools-common linux-tools-generic linux-tools- ` uname -r `
- For trace-cmd, see https://github.com/rostedt/trace-cmd
- You can do (AFAIK) everything in 'perf' as you can in 'trace-cmd' but I have found trace-cmd has little overhead... perhaps because trace-cmd only supports tracepoints whereas perf supports tracepoints, sampling, callstacks and more.
- Currently for perf and trace-cmd data, you have to give OPPAT both the binary data file and the post-processed text file.
- Having some of the data come from the binary file speeds things up and is more reliable.
- But I don't want to the symbol handling and I can't really do the post-processing of the binary data. Near as I can tell you have to be part of the kernel to do the post processing.
- OPPAT requires certain clocks and a certain syntax of 'convert to text' for perf and trace-cmd data.
- OPPAT requires clock_monotonic so that different file timestamps can be correlated.
- When converting the binary data to text (trace-cmd report or 'perf script') OPPAT needs the timestamp to be in nanoseconds.
- see scriptsrun_xperf.bat and scriptsrun_perf.sh for the required syntax
- given that there might be so many files to read (for example, run_perf.sh generates 7 input files), it is kind of a pain to add these files to the json file input_filesinput_data_files.json.
- the run_xperf.bat and run_perf.sh generate a file_list.json in the output directory.
- perf has so, so many options... I'm sure it is easy to generate some data which will break OPPAT
- The most obvious way to break OPPAT is to generate too much data (causing browser to run out of memory). I'll probably handle this case better later but for this release (v0.1.0), I just try to not generate too much data.
- For perf I've tested:
- sampling hardware events (like cycles, instructions, ref-cycles) and callstacks for same
- software events (cpu-clock) and callstacks for same
- tracepoints (sched_switch and a bunch of others) with/without callstacks
- Zooming Using touchpad scroll on Firefox seems to not work as well it works on Chrome



