Outil d'ouverture de puissance / performance ouverte (OPPAT)
Table des matières
- Introduction
- Types de données prises en charge
- Visualisation opposée
- caractéristiques du graphique
- types de graphiques
- Collecte de données pour Oppat
- Prise en charge des données PCM
- Bâtiment Oppat
- Courir Oppat
- Événements dérivés
- Utilisation de l'interface GUI Browswer
- Limites
Introduction
L'outil d'analyse de puissance / performance ouverte (OPPAT) est un outil de puissance inter-architecture et d'analyse des performances croisés.
- Cross-OS: prend en charge les fichiers de trace de Windows ETW et les fichiers Linux / Android Perf / Trace-CMD Trace
- Cross-Architecture: prend en charge les événements matériels Intel et Arm Chips (à l'aide de perf et / ou de PCM)
La page Web du projet est https://patinnc.github.io
Le repo de code source est https://github.com/patinnc/oppat
J'ai ajouté un système d'exploitation (OS_VIEW) à la fonction de diagramme de bloc CPU. Ceci basé sur les pages de Brendan Gregg telles que http://www.brendangregg.com/linuxperf.html. Voici quelques exemples de données pour exécuter une ancienne version de Geekbench V2.4.2 (code 32 bits) sur ARM 64BIT UBUNTU MATE V18.04.2 Raspberry Pi 3 B +, 4 CPU Cortex A53 ARM:
- Une vidéo des modifications du schéma de bloc OS_VIEW et ARM A53 CPU exécutant GeekBench:
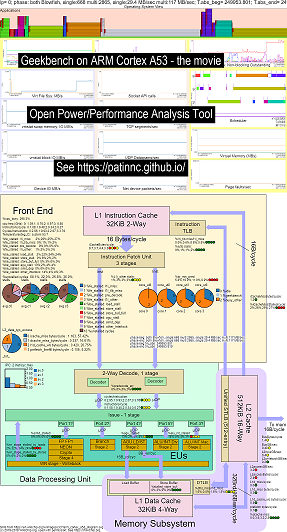
- Il y a quelques diapositives d'introduction à essayer d'expliquer la disposition OS_VIEW et CPU_DIAGRAM, puis 1 diapositive montrant les résultats pour chacun des 30 sous-tests
- Un fichier Excel des données dans le film: EXCEL Fichier de Geekbench le film
- Le HTML des données dans le film ... Voir Geekbench V2.4.2 sur 4 Core ARM CORTEXT A53 avec OS_VIEW, CPU Diagramme.
- Le tableau de bord PNG pour les 30 phases triés en augmentant les instructions / sec ... Voir ARM Cortex A53 Raspberry Pi 3 avec diagramme de CPU Tableau de bord à puce à 4 cœurs exécutant Geekbench.
Voici quelques exemples de données pour l'exécution de mon benchmark Spin (tests de bande passante de mémoire / cache, un test de Keep-Cpu-busy 'spin') sur Raspberry Pi 3 B + (Cortex A53) CPU:
- Une vidéo des modifications de l'OS_VIEW et ARM A53 Diagramme de blocs CPU Running Spin:
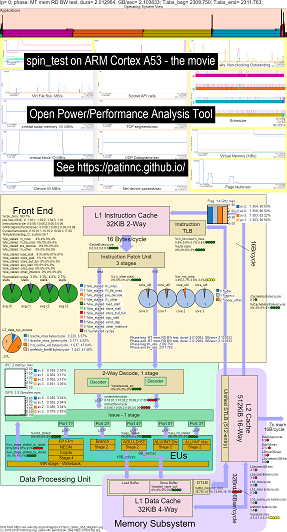
- Il y a quelques diapositives d'introduction pour essayer d'expliquer les graphiques OS_VIEW et la disposition CPU_DIAGRAM, une diapositive affichant à quel moment (en secondes) chaque sous-test affiche (afin que vous puissiez aller sur T = x Secs pour aller directement à ce sous-test) puis une diapositive pour chacun des 5 sous-tests
- Un fichier Excel des données dans le film: EXCEL Fichier de Geekbench le film
- Le HTML des données dans le film ... Voir ARM CORTEX A53 Raspberry Pi 3 avec diagramme CPU à 4 cœurs Running Spin Benchmark.
- Le tableau de bord PNG pour les 5 phases triés en augmentant les instructions / SEC ... Voir ARM Cortex A53 Raspberry Pi 3 avec diagramme CPU Tableau de bord de puce à 4 cœurs exécutant Benchmark.
Voici quelques exemples de données pour exécuter GeekBench sur les processeurs Haswell:
- Une vidéo des modifications du diagramme de blocs OS_View et Haswell CPU exécutant GeekBench:
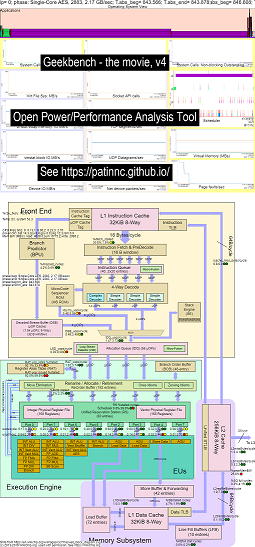
- Il y a quelques diapositives d'introduction pour essayer d'expliquer les graphiques OS_VIEW et la disposition CPU_DIAGRAM, une diapositive affichant à quel moment (en secondes) chaque sous-test affiche (afin que vous puissiez aller sur T = x Secs pour aller directement à ce sous-test) puis une diapositive pour chacun des 50 sous-tests
- Un fichier Excel des données dans le film: EXCEL Fichier de Geekbench le film
- Le HTML des données du film ... Voir Intel Haswell avec un diagramme CPU 4-CPU Chip exécutant Geekbench.
- Le tableau de bord PNG pour les 50 phases triés en augmentant UOPS Retired / SEC ... Voir le tableau de bord Intel Haswell avec diagramme de CPU Tableau de bord à puce à 4 cœurs exécutant GeekBench.
Voici quelques données pour exécuter ma référence 'Spin' avec 4 sous-tests sur les processeurs Haswell:
- Le 1er sous-test est un test de bande passante de mémoire de lecture. Le bloc L2 / L3 / mémoire est très utilisé et bloqué pendant le test. Le rat UOPS / cycle est faible car le rat est principalement bloqué.
- Le 2ème sous-test est un test de bande passante L3 à lire. La mémoire BW est maintenant faible. Le bloc L2 et L3 est très utilisé et bloqué pendant le test. Le rat UOPS / cycle est plus élevé car le rat est moins bloqué.
- Le 3ème sous-test est un test de bande passante en L2. Le L3 et la mémoire BW sont maintenant bas. Le bloc L2 est très utilisé et bloqué pendant le test. Le rat UOPS / cycle est encore plus élevé car le rat est encore moins bloqué.
- Le 4ème sous-test est un test de spin (juste un ADD LOOP). Le L2, L3 et Memory BW sont proches de zéro. Le rat UOPS / cycle est d'environ 3,3 UOPS / cycle, ce qui approche des 4 UOPS / cycle maximum possible.
- Une vidéo des modifications du diagramme du bloc Haswell CPU exécutant «spin» avec analyse. Voir
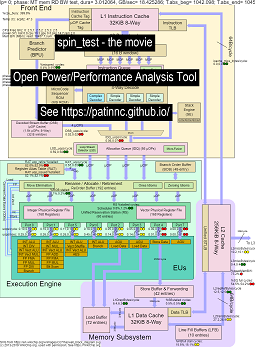
- Un fichier Excel des données dans le film: EXCEL Fichier de Spin the Movie
- Le HTML des données dans le film ... Voir Intel Haswell avec diagramme CPU 4-CPU Chip en cours de référence Spin.
Le Haswell Intel avec des collections de données du diagramme CPU concerne une puce Intel de 4 cpu, un système d'exploitation Linux, un fichier HTML avec plus de 50 événements HW via un échantillonnage perf et d'autres données collectées. CPU_DIAGRAM FARATS:
- Commencez avec un svg de diagramme de blocs de wikichip.org (utilisé avec permission),
- Regardez les contraintes de ressources (telles que Max BW, MAX octets / cycle sur divers chemins, cycles minimum / UOP, etc.),
- calculer les mesures pour l'utilisation des ressources
- Vous trouverez ci-dessous un tableau d'un test de bande passante en lecture de mémoire qui affiche les informations d'utilisation des ressources dans un tableau (ainsi qu'une estimation de la possibilité de l'obtention du processeur en raison de l'utilisation). La table HTML (mais pas la PNG) a des informations contextuelles lorsque vous survolez les champs. La table montre que:
- Le noyau est bloqué sur la bande passante de mémoire à 55% du maximum de 25,9 Go / s BW possible. C'est un test de mémoire bw
- La superquelue (SQ) est pleine (54,5% pour Core0 et 62,3% Core1) des cycles (donc plus de demandes L2 ne peuvent pas être manipulées)
- Le tampon de remplissage de ligne FB est plein (30% et 51%), les lignes ne peuvent donc pas être déplacées vers L1D de L2
- Le résultat est que le backend est bloqué (88% et 87%) des cycles qu'aucun UOPS n'est retiré.
- L'UOPS semble provenir du détecteur de flux de boucle (car les cycles LSD / UOP sont à peu près les mêmes que le rat UOPS / Cycle.
- Une capture d'écran de la table BW de mémoire du diagramme du CPU Haswell
- Vous trouverez ci-dessous un tableau d'un test de bande passante en L3.
- Maintenant, la mémoire BW et les octets / cycle L3 Miss sont à environ zéro.
- Le SQ est moins bloqué (car nous n'attendons pas de mémoire).
- Les octets / cycles de transactions L2 sont d'environ 2x plus élevés et environ 67% des 64 octets / cycle maximaux possibles.
- Le UOPS_Reredred_Stalls / Cycle est tombé à 66% du stand de test MEM BW de 88%.
- Les stands de tampon de remplissage sont désormais supérieurs à 2 fois plus élevés. L'UOPS vient toujours du LSD.
- Une capture d'écran du schéma du processeur Haswell L3 BW Table
- Vous trouverez ci-dessous un tableau d'un test de bande passante en L2.
- Les octets / cycle L2 manquent L2 est beaucoup plus bas que le test L3.
- L'UOPS_Reredred% a stappé est maintenant d'environ la moitié du test L3 à 34% et les stands FB sont également d'environ 17%.
- Les UOPs viennent toujours du LSD.
- Une capture d'écran du schéma de processeur Haswell L2 BW Table
- Vous trouverez ci-dessous un tableau d'un test de spin (pas de charges, il suffit d'ajouter une boucle).
- Maintenant, il y a juste des stands de sous-système de mémoire zéro.
- L'UOPS provient du tampon de flux de décodage (DSB).
- Rat Retired_uops / cycle à 3,31 cycles / UOP est près du maximum de 4,0 UOPS possible / cycle.
- Le rat retraité_uops% calé est assez faible à% 8.
- Une capture d'écran de la table de spin du diagramme du processeur Haswell
Actuellement, je n'ai que des films CPU_Diagram pour Haswell et ARM A53 (puisque je n'ai pas d'autres systèmes à tester), mais il ne devrait pas être difficile d'ajouter d'autres diagrammes de blocs. Vous obtenez toujours tous les graphiques mais pas le cpu_diagram.
Vous trouverez ci-dessous l'un des graphiques OPPAT. Le graphique «CPU_BUSY» montre ce qui fonctionne sur chaque CPU et les événements qui se produisent sur chaque CPU. Par exemple, le cercle vert montre un fil Spin.x fonctionnant sur CPU 1. Le cercle rouge montre certains des événements se produisant sur CPU1. Ce graphique est modélisé après le graphique Kernelshark de Trace-CMD. Plus d'informations sur le tableau CPU_BUSY se trouvent dans la section des types de graphiques. La boîte de callout affiche les données de l'événement (y compris CallStack (le cas échéant)) pour l'événement sous le curseur. Malheureusement, la capture d'écran Windows ne capture pas le curseur. 
Voici quelques exemples de fichiers HTML. La plupart des fichiers sont pour un intervalle plus court ~ 2, mais certains sont «complets» de 8 secondes. Les fichiers ne se chargeront pas directement à partir du dépôt, mais ils se chargeront à partir de la page Web du projet: https://patinnc.github.io
- Intel Haswell avec puce 4-CPU Diagramme CPU, OS Linux, fichier HTML avec plus de 50 événements HW via l'échantillonnage perf ou
- Chip Intel 4-CPU, Windows OS, fichier HTML avec 1 événements HW via un échantillonnage XPERF ou
- Full ~ 8 secondes de puce Intel 4-CPU, Windows OS, fichier HTML avec PCM et échantillonnage XPERF ou
- Chip Intel 4-CPU, OS Linux, fichier HTML avec 10 événements HW en 2 groupes multiplexés.
- Chip ARM (Broadcom A53), fichier Raspberry PI3 Linux HTML avec 14 événements HW (pour CPI, L2 Misses, Mem BW, etc. en 2 groupes multiplexés).
- 11 MB, version complète de la puce du bras ci-dessus (Broadcom A53), fichier Raspberry PI3 Linux HTML avec 14 événements HW (pour CPI, L2 Misses, Mem BW, etc. en 2 groupes multiplexés).
Certains des fichiers ci-dessus sont des intervalles d'environ 2 secondes extraits de environ 8 secondes de longues courses. Voici la course complète de 8 secondes:
- Le fichier compressé HTML compressé de 8 secondes complet de 8 secondes de 8 secondes pour un fichier plus complet. Le fichier fait une décompression ZLIB JavaScript des données du graphique afin que vous verrez des messages vous demander d'attendre (environ 20 secondes) pendant la décompression.
Données OPPAT soutenues
- Fichiers de performances Linux Perf et / ou Trace-CMD (fichiers binaires et texte),
- La sortie Perf STAT a également accepté
- Données Intel PCM,
- Autres données (importées à l'aide de scripts LUA),
- Cela devrait donc fonctionner avec les données de Linux ou Android ordinaires
- Actuellement pour les données PERF et Trace-CMD, OPPAT nécessite à la fois les fichiers texte binaires et post-traités et il y a certaines restrictions sur la ligne de commande 'Record' et la ligne de commande 'Script / Trace-CMD' PERF / PERF-CMD '.
- Oppat pourrait être fait pour simplement utiliser les fichiers de sortie de texte perf / trace-cmd, mais actuellement les fichiers binaires et texte sont requis
- Données Windows ETW (collectées par XPERF et vilées en texte) ou les données Intel PCM,
- Des données de puissance ou de performance arbitraires prises en charge à l'aide de scripts LUA (vous n'avez donc pas besoin de recompiler le code C ++ pour importer d'autres données (sauf si les performances LUA deviennent un problème))
- Lisez les fichiers de données sur Linux ou Windows, peu importe où les fichiers sont originaires (alors lisez les fichiers perf / trace-cmd sur les fichiers texte Windows ou ETW sur Linux)
Visualisation opposée
Voici quelques exemples de fichiers HTML VisualZation complets: Windows Exemple de fichier HTML ou cet exemple de fichier HTML Linux. Si vous êtes sur le dépôt (pas le site Web du projet GitHub.io), vous devrez télécharger le fichier, puis le charger dans votre navigateur. Ce sont des fichiers Web autonomes créés par OPPAT qui pourraient, par exemple, envoyer un e-mail à d'autres ou (comme ici) publié sur un serveur Web.
Oppat Viz fonctionne mieux dans Chrome que Firefox principalement parce que le zoom utilisant le défilement tactile 2 doigts fonctionne mieux sur Chrome.
Oppat a 3 modes de visualisation:
- Le mécanisme de graphique habituel (où Oppat Backend lit les fichiers de données et envoie des données au navigateur)
- Vous pouvez également créer une page Web autonome qui est l'équivalent du `` mécanisme de graphique ordinaire '' mais qui peut être échangée avec d'autres utilisateurs ... La page Web autonome a tous les scripts et données intégrés afin qu'il puisse être envoyé par e-mail à quelqu'un et ils pourraient le charger dans leur navigateur. Voir les fichiers HTML dans Sample_html_Files référencé ci-dessus et (pour une version plus longue de LNX_MEM_BW4) Voir le fichier compressé Exemple_html_files / lnx_mem_bw4_full.html
- Vous pouvez «- saisir» un fichier JSON de données puis - télécharger le fichier plus tard. Le fichier JSON enregistré est les données que Oppat doit envoyer au navigateur. Cela évite de relire les fichiers d'entrée perf / xperf, mais il ne ramassera aucune modification apportée dans Charts.json. Le fichier html complet créé avec l'option - web_file n'est que légèrement plus grand que le fichier - épreuve. Le mode - Save / - Charge nécessite la construction d'Oppat. Voir les exemples de fichiers «enregistrés» dans Sample_Data_Json_files Subdir.
À savoir les informations générales
- tracer toutes les données dans un navigateur (sur Linux ou Windows)
- Les graphiques sont définis dans un fichier JSON afin que vous puissiez ajouter des événements et des graphiques sans recompilation Oppat
- L'interface du navigateur est un peu comme Windows WPA (NAVBAR à gauche).
- Ci-dessous montre la barre de navigation gauche (menu coulissant du côté gauche).
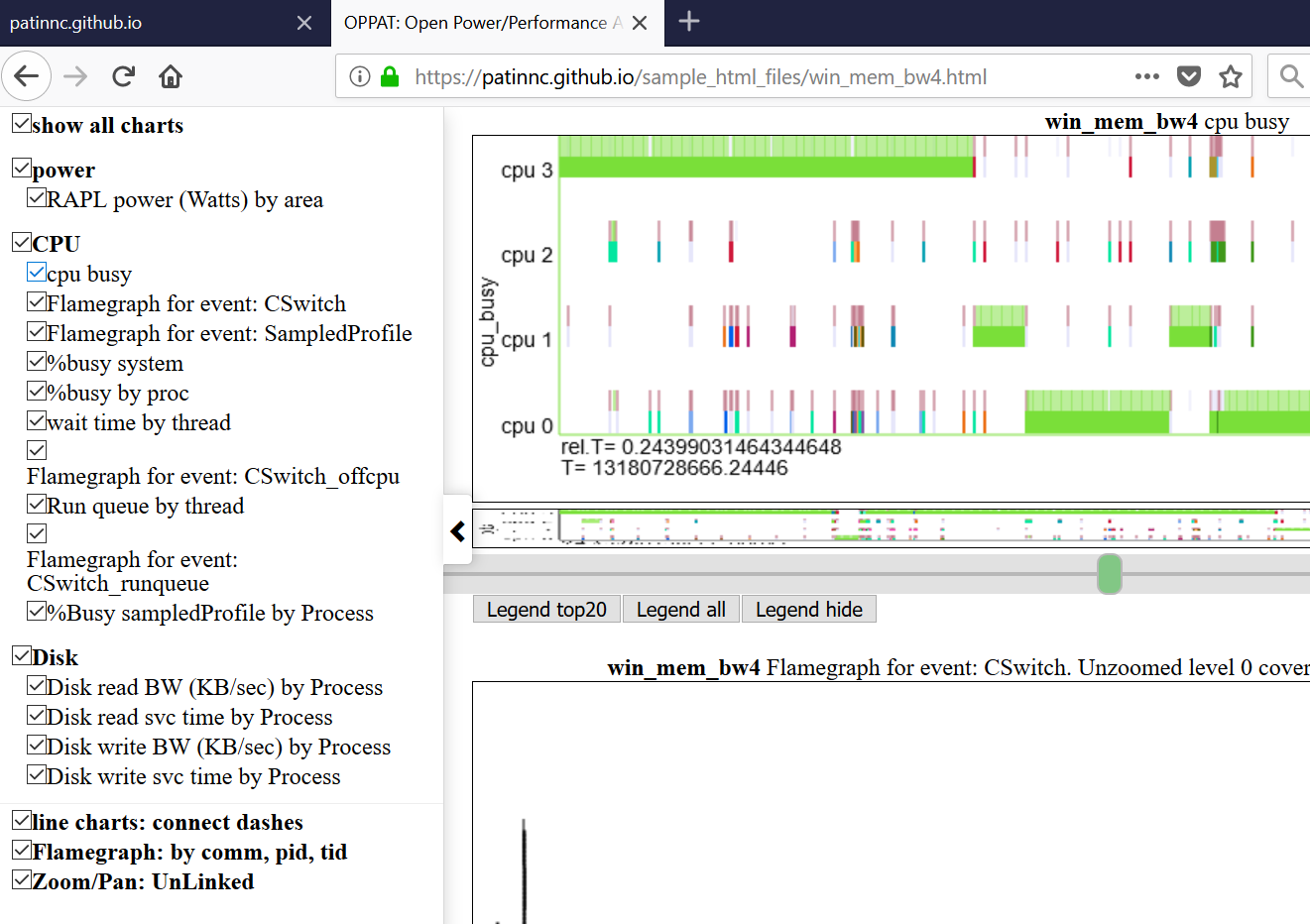
- Les graphiques sont regroupés par catégorie (GPU, CPU, puissance, etc.)
- Les catégories sont définies et attribuées dans Input_files / Charts.json
- Les graphiques peuvent être cachés ou affichés sélectivement en cliquant sur le graphique dans la barre navale.
- survoler un titre de graphique dans le menu de navigation de navigation de navigation de navigation qui trace en vue
- Les données d'un groupe de fichiers peuvent être tracées aux côtés d'un groupe différent
- afin que vous puissiez dire, comparez une performance Linux Perf vs une exécution de Windows ETW
- Ci-dessous le graphique Afficher Linux vs Windows Power Utilisation:
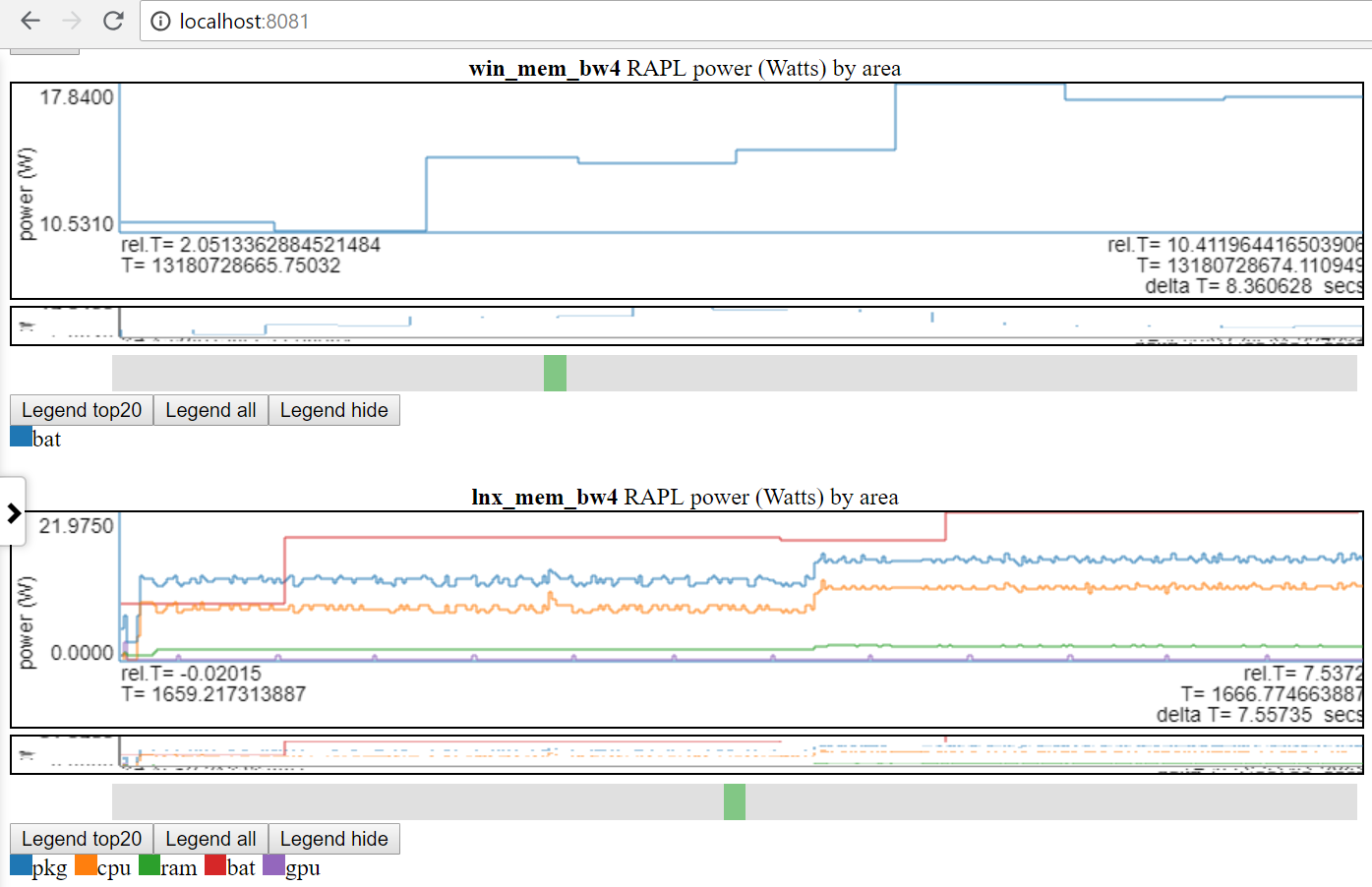
- Je n'ai accès qu'à l'alimentation de la batterie sur Linux et Windows.
- De nombreux sites ont des données de puissance bien meilleures (tensions / courants / puissance au taux MSEC (ou mieux)). Il serait facile d'incorporer ces types de données d'alimentation (comme de Kratos ou Qualcomm MDPS), mais je n'ai pas accès aux données.
- ou comparer 2 exécutions différentes sur la même plate-forme
- Une balise de groupe de fichiers (file_tag) est préfixée au titre pour distinguer les graphiques
- Un 'balise' est défini dans le fichier Data Dir's file_list.json et / ou input_files / input_data_files.json
- Le Input_files / Input_data_files.json est une liste de tous les réseaux de données OPPAT (mais l'utilisateur doit le maintenir).
- Les graphiques avec le même titre sont tracés l'un après l'autre pour permettre une comparaison facile
Caractéristiques du graphique:
planant sur une section d'une ligne du graphique montre le point de données de cette ligne à ce point
- Cela ne fonctionne pas pour les lignes verticales car elles ne connectent que 2 points ... seuls les éléments horizontaux de chaque ligne sont recherchés la valeur des données
- Vous trouverez ci-dessous une capture d'écran de survol sur l'événement. Cela montre le temps relatif de l'événement (CSWTICH), certaines informations comme le processus / PID / TID et le numéro de ligne dans le fichier texte afin que vous puissiez obtenir plus d'informations.

- Vous trouverez ci-dessous une capture d'écran montrant les informations de CallStack (le cas échéant) pour les événements.

zoom
- Illimite zoom sur le niveau nanosec et zoomer.
- Il y a probablement des ordres de grandeur plus de points à tracer que les pixels afin que plus de données soient affichées lorsque vous zoomez.
- Vous trouverez ci-dessous une capture d'écran montrant le zoom au niveau de la microseconde. Cela montre l'événement CallStack pour sched_switch où Spin.x est bloqué en effectuant un opération de mappage de mémoire et en passant au ralenti. Le graphique «CPU Busy» montre «devenant inactif» comme vide.
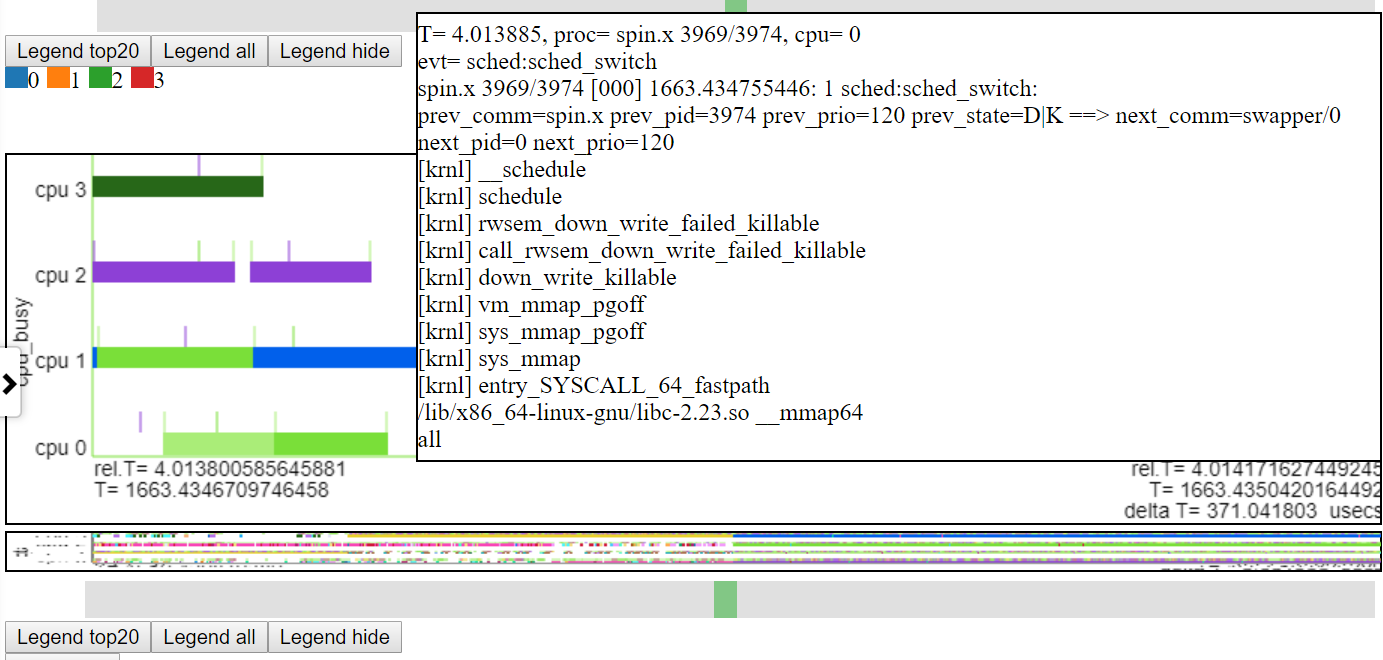 .
.
- Les graphiques peuvent être zoomés individuellement ou les graphiques avec le même fichier_tag peuvent être liés afin que le zoom / panoramique 1 modifie l'intervalle de tous les graphiques avec le même fichier_tag
- Faites défiler vers le bas de la barre de navigation gauche et cliquez sur «Zoom / Pan: non lié». Cela modifiera l'élément de menu en «zoom / pan: lié». Cela zoom / pan tous les graphiques d'un groupe de fichiers au plus récent temps absolu Zoom / Pan. Cela prendra un certain temps pour redessiner tous les graphiques.
- Initialement, chaque graphique est dessiné affichant toutes les données disponibles. Si vos graphiques proviennent de différentes sources, le T_Begin et T_end (pour les graphiques de différentes sources) est probablement différent.
- Une fois qu'une opération Zoom / Pan est effectuée tout et que la liaison est en vigueur, tous les graphiques du groupe de fichiers zoom / pan au même intervalle absolu.
- C'est pourquoi «l'horloge» utilisée pour chaque source doit être la même.
- Oppat pourrait traduire d'une horloge à une autre (comme entre gettime (horloge_monotonic) et getTimeOfday ()) mais cette logique
- Tous les flammes pour un intervalle sont toujours zoomés vers l'intervalle des «graphiques de possession» quel que soit le statut de liaison.
- Vous pouvez zoomer / sortir par:
- Zoomez: roue de souris verticalement sur la zone du graphique. Le graphique zoome sur l'heure au centre du graphique.
- Sur mon ordinateur portable, cela fait défiler 2 doigts verticalement sur le pavé tactile
- Zoomez: cliquer sur le graphique et faire glisser la souris vers la droite et libérer la souris (le graphique zoomera vers l'intervalle sélectionné)
- Zoomez: cliquer sur le graphique et faire glisser la souris vers la gauche et libérer la souris zoom out inversement de proportionnel à la quantité de graphique que vous avez sélectionné. Autrement dit, si vous avez laissé faire glisser presque toute la zone du graphique, le graphique zoomera ~ 2x. Si vous venez de faire glisser un petit intervalle, le graphique zoomera le ~ chemin entièrement.
- Zoom out: sur mon ordinateur portable, faisant un pavé tactile 2 doigt vertical défile dans la direction opposée du zoom
- Vous devez faire attention à l'endroit où se trouve le curseur ... vous pourriez zoomer par inadvertance un graphique lorsque vous voulez faire défiler la liste des graphiques. Je mets donc habituellement le curseur sur le bord gauche de l'écran lorsque je veux faire défiler les graphiques.
panoramique
- Sur mon ordinateur portable, cela fait 2 doigts sur le mouvement de défilement horizontal sur le pavé tactile
- Utilisation de la boîte verte sur la vignette sous le graphique
- Panning fonctionne à n'importe quel niveau de zoom
- Une photo «miniature» du graphique complet est placée sous chaque graphique avec un curseur pour glisser le long de la vignette afin que vous puissiez naviguer dans le graphique lorsque vous zoomez / panoramique
- Ci-dessous montre le panoramique du graphique «CPU Busy» à T = 1,8-2,37 secondes. Le temps relatif et le temps de début absolu sont host-il dans l'ovale rouge gauche. L'heure de fin est mise en évidence dans l'ovale rouge côté droit. La position relative sur la vignette est montrée par l'ovale rouge moyen.
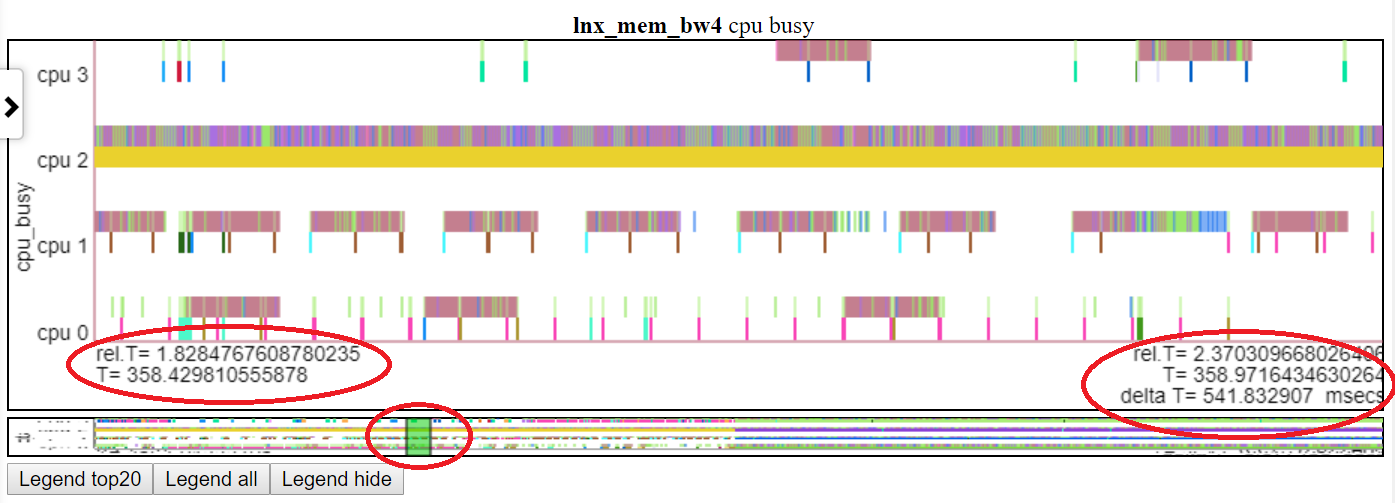 .
.
Faire planer sur une entrée de légende du graphique met en évidence cette ligne.
- Vous trouverez ci-dessous une capture d'écran où la puissance «pkg» (package) est mise en évidence
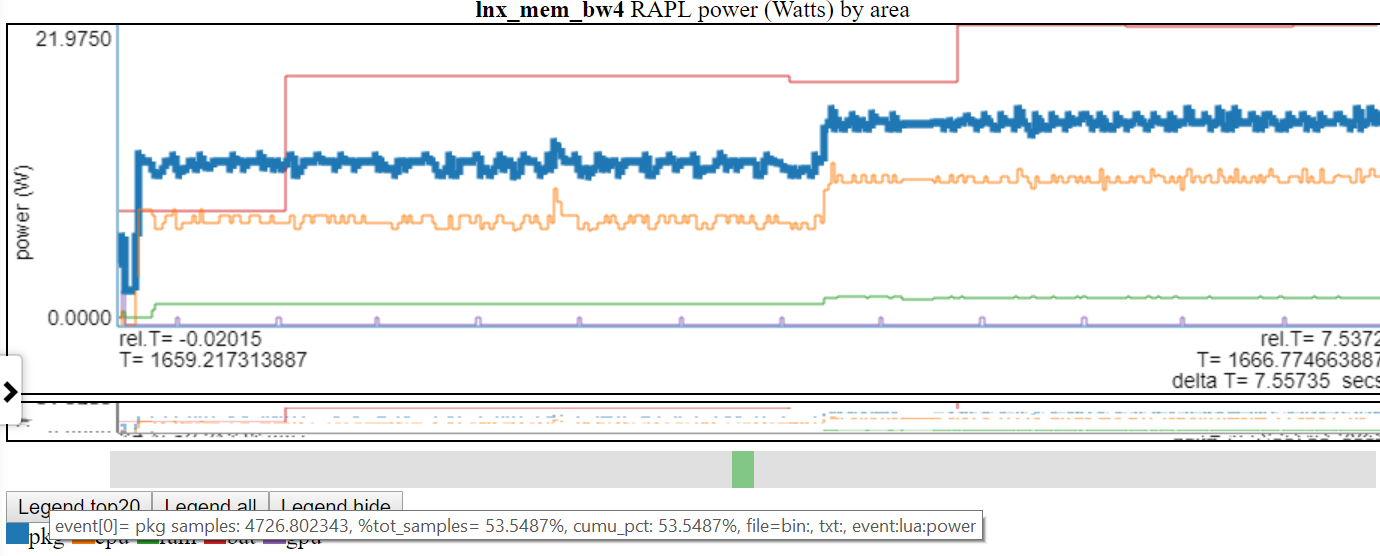
En cliquant sur une entrée de légende du graphique, bascule la visibilité de cette ligne.
Double-cliquez sur une entrée de légende ne rend que cette entrée visible / cachée
- Vous trouverez ci-dessous une capture d'écran où l'alimentation «PKG» a été double clic pour que seule la ligne PKG soit visible.
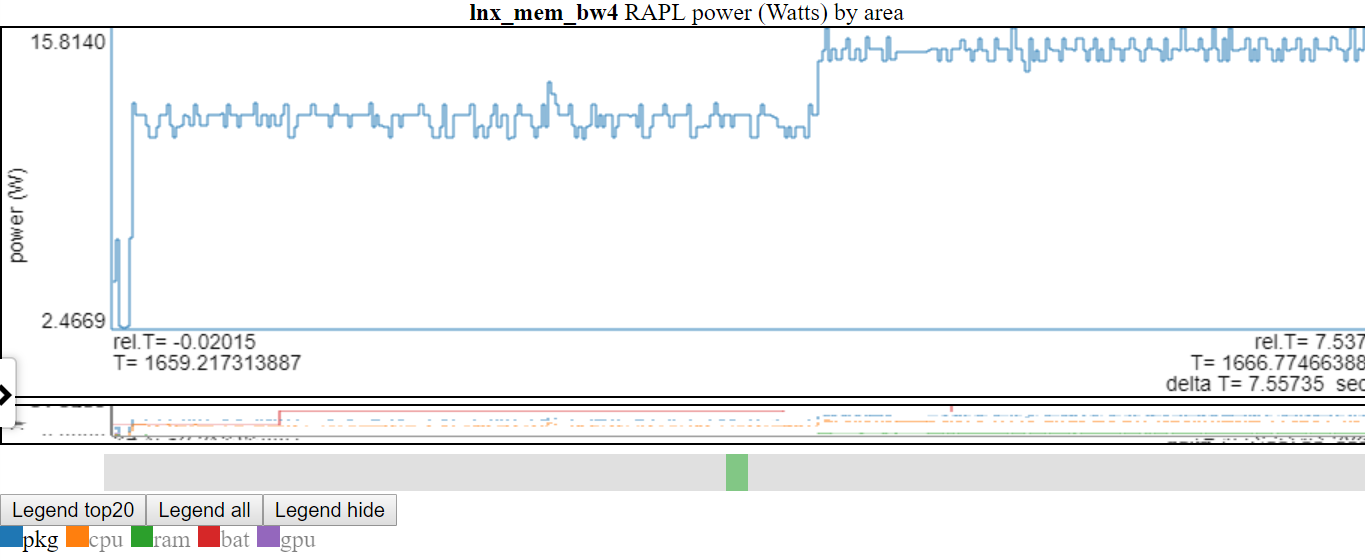
- Ci-dessus montre que l'axe y est ajusté à Min / max de la (s) variable affichée. Les lignes «non montrées» sont grisées dans la légende. Si vous survolez une ligne «non montrée» dans la légende, elle sera dessinée (pendant que vous planez sur l'élément de légende). Vous pouvez obtenir tous les articles à afficher à nouveau en double-cliquant sur une entrée de légende «mal décrit». Cela montrera toutes les lignes «non montrées», mais il basculera de la ligne que vous venez de cliquer ... donc un seul clic sur l'élément que vous venez de double-cliquer. Je sais que cela semble déroutant.
Si une entrée de légende est cachée et que vous planez dessus, elle sera affichée jusqu'à ce que vous soyez en volant
Types de graphiques:
Graphique «CPU Busy»: un graphique de type Kernelshark montrant l'occupation du CPU par PID / Thread. Voir Kernelshark Reference http://rostedt.homelinux.com/kernelshark/
- Vous trouverez ci-dessous une capture d'écran du graphique animé du CPU. Le graphique montre, pour chaque CPU, le processus / pid / tid fonctionnant à tout moment. Le processus inactif n'est pas dessiné. Pour «CPU 1» sur la capture d'écran, l'ovale vert est autour de la partie «commutateur de contexte» du graphique. Au-dessus des informations de commutation de contexte de chaque CPU, CPU Busy montre les événements qui se présentent dans le même fichier que l'événement de commutateur de contexte. L'ovale rouge sur la ligne CPU 1 montre la partie de l'événement du graphique.
- Le graphique est basé sur l'événement de commutateur de contexte et affiche le thread fonctionnant sur chaque CPU à un moment donné
- L'événement de commutateur de contexte est l'événement Linux Sched: Sched_Switch ou l'événement Windows ETW CSWitch.
- S'il y a plus d'événements que le commutateur de contexte dans le fichier de données, tous les autres événements sont représentés comme des tirets verticaux au-dessus du processeur.
- Si les événements ont des piles d'appels, la pile d'appels est également affichée dans le ballon popup
graphiques de ligne
- Les graphiques de ligne sont probablement appelés plus précisément les graphiques de pas, car chaque événement (jusqu'à présent) a une durée et ces «durées» sont représentées par des segments horizontaux et rejoints par des segments verticaux.
- La partie verticale du graphique de pas peut remplir un graphique si les lignes de graphique ont beaucoup de variation
- Vous pouvez sélectionner (dans la barre de navigation de gauche) pour ne pas connecter les segments horizontaux de chaque ligne ... donc le graphique devient une sorte de graphique de «tableau de bord dispersé». Les «tirets horizonataux» sont les points de données réels. Lorsque vous passez du graphique de pas vers le tableau de bord, le graphique n'est pas redessiné jusqu'à ce qu'il y ait une demande «redessiner» (comme zoom / pan ou en surbrillance (en survolant une entrée de légende)).
- Vous trouverez ci-dessous une capture d'écran des états de puissance CPU_IDLE à l'aide du graphique de ligne. Les lignes de connexion effacent les informations du graphique.
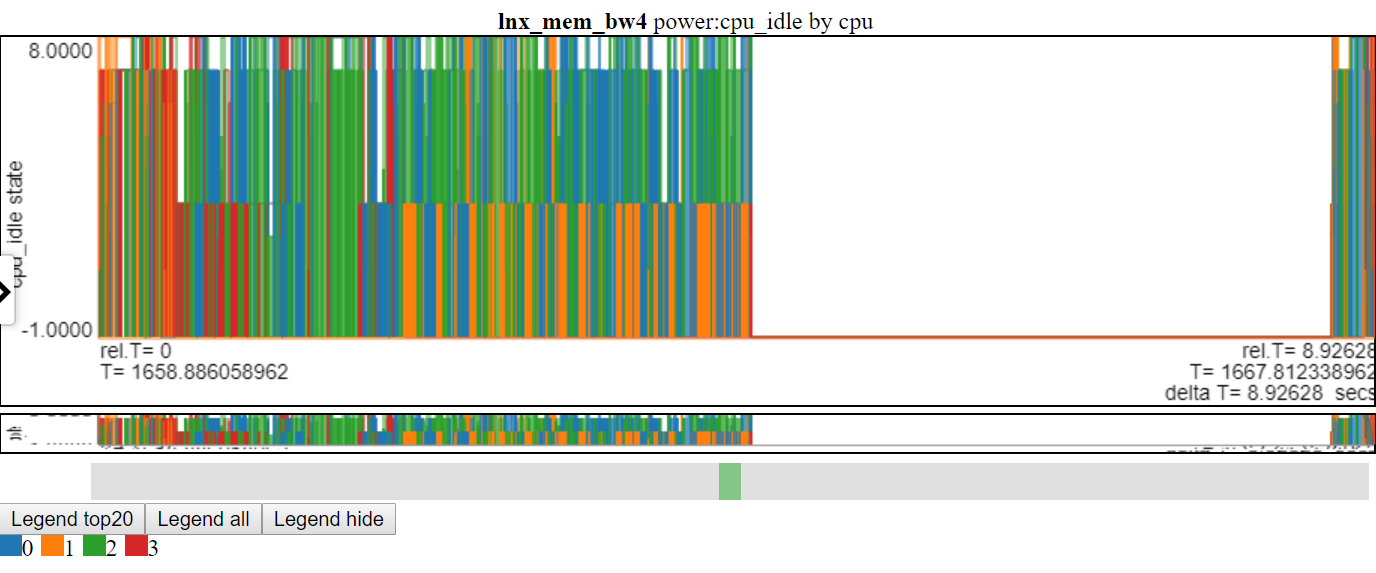
- Vous trouverez ci-dessous une capture d'écran des états de puissance CPU_IDLE à l'aide d'un graphique à bassin dispersé. Le graphique montre désormais un tableau de bord horizontal pour le point de données (la largeur du tableau de bord est la durée de l'événement). Maintenant, nous pouvons voir plus d'informations, mais ce graphique affiche également un inconvénient avec ma logique de cartographie: une grande partie des données est à la valeur maximale et à la valeur minime du graphique et elle est obscurcie.
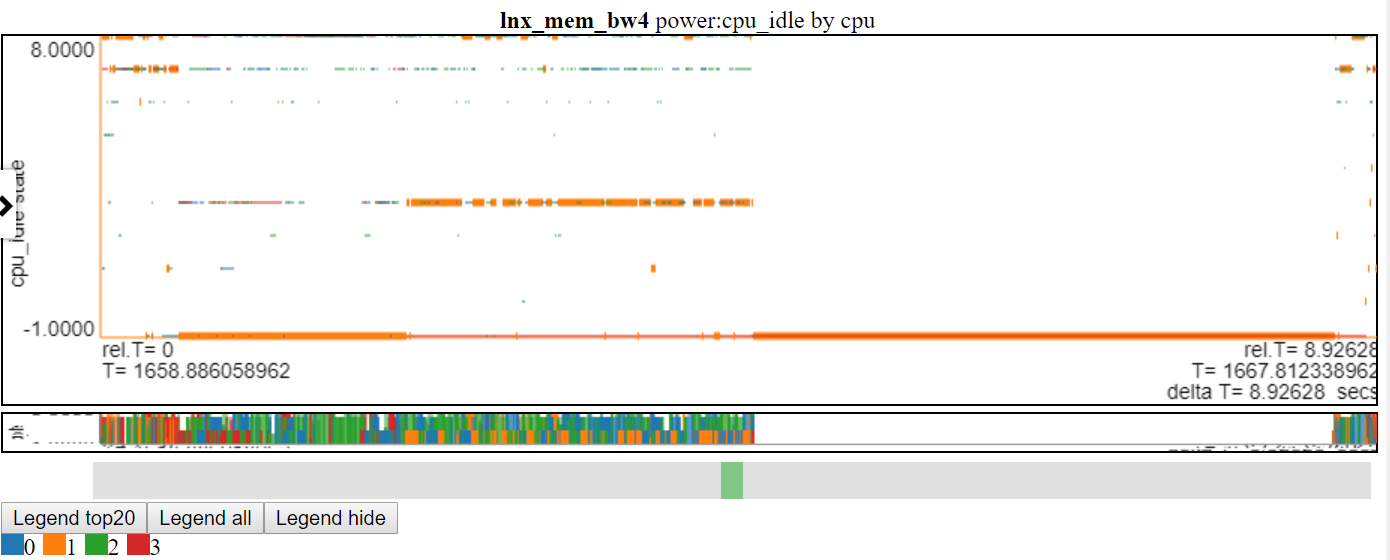
graphiques empilés
- Les graphiques empilés peuvent provoquer beaucoup plus de données que les graphiques de ligne. Par exemple, le dessin d'un graphique de ligne du moment où un thread particulier s'exécute ne dépend que de ce fil. Dessiner un graphique empilé pour les threads en cours d'exécution est différent: un événement de commutateur de contexte sur n'importe quel thread modifiera tous les autres threads en cours d'exécution ... Donc, si vous avez N CPU, vous obtiendrez N-1 plus de choses à dessiner par événement pour les graphiques empilés.
flamme. Pour chaque événement Perf qui a CallStacks et est dans le même fichier que l'événement sched_switch / cSwitch, un flamme est créé.
- Vous trouverez ci-dessous une capture d'écran d'une flamme par défaut typique. Habituellement, la hauteur par défaut du graphique FlameGraph n'est pas suffisante pour installer le texte dans chaque niveau du flamme. Mais vous obtenez toujours les informations de CallStack «Hover».
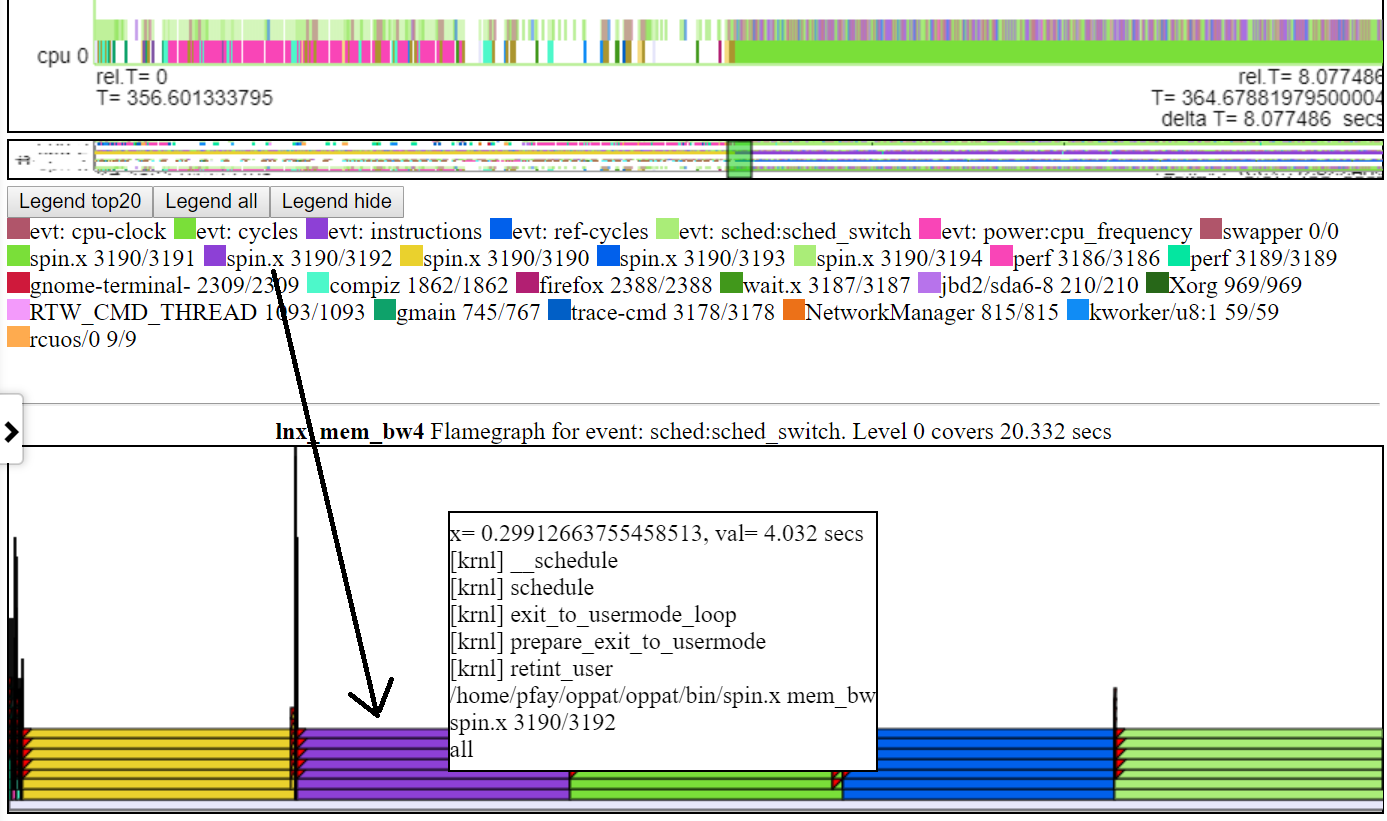 .
.- Si vous cliquez sur le calque du graphique, il se dilate plus de telle sorte que le texte s'adapte. Si vous cliquez sur la couche la plus basse, il couvre toutes les données pour l'intervalle du «graphique de possession».
- Vous trouverez ci-dessous une capture d'écran d'une flamme zoomée (après avoir cliqué sur l'une des couches d'une flamme).
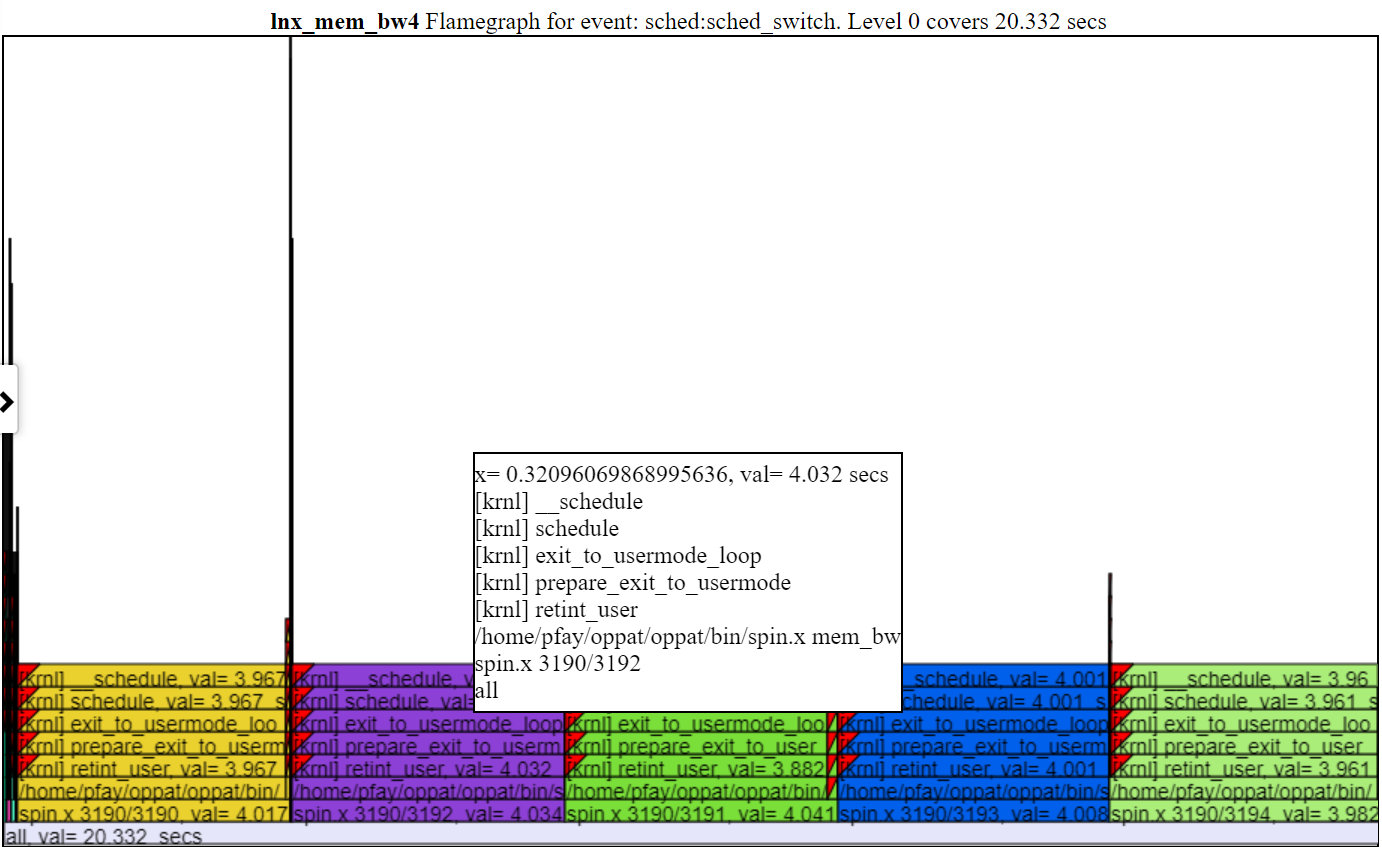 .
.- Habituellement, la hauteur par défaut du graphique FlameGraph n'est pas suffisante pour installer le texte dans chaque niveau du flamme. Mais vous obtenez toujours les informations de CallStack «Hover».
- La couleur de la flamme correspond au processus / pid / tid dans le graphique légende du CPU_BUSY ... donc il n'est pas aussi joli qu'un flamme, mais maintenant la couleur d'une `` flamme '' signifie réellement quelque chose.
- Le graphique Flamegraph CPI (horloges par instruction) colore le processus / pid / tid par l'IPC pour cette pile.
- Vous trouverez ci-dessous un échantillon du graphique CPI non zoomé. L'instance de gauche de Spin.x (en orange clair) a un CPI = 2,26 cycles / instruction. Les 4 spin.x à droite en vert clair ont un CPI = 6,465.
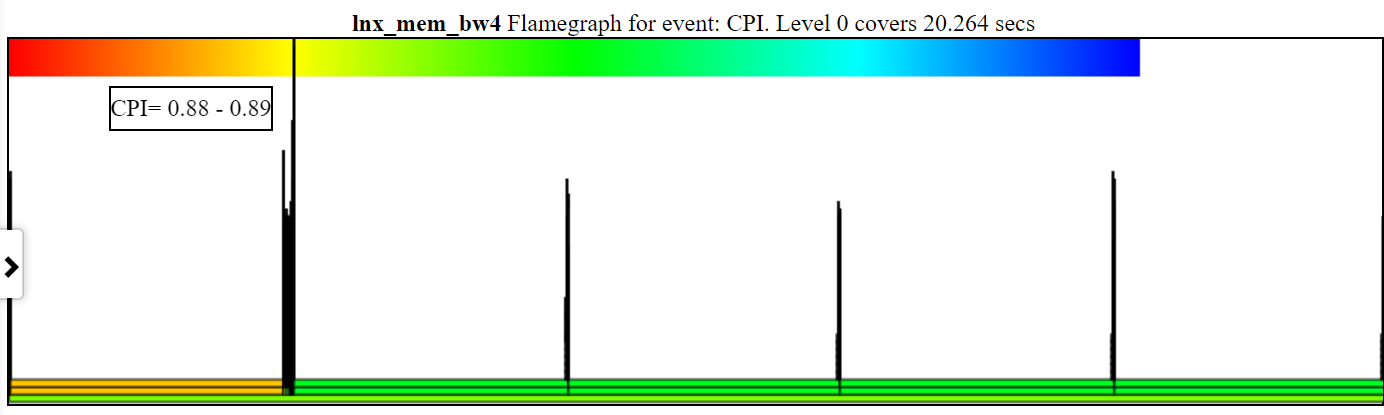
- Vous devez avoir des cycles, des instructions et un CPU-horloge (ou sched_switch) CallStacks
- La largeur de la «flamme» du CPI est basée sur le temps de blocage du CPU.
- La couleur est basée sur l'IPC. Un gradient rouge à vert à bleu en haut à gauche du graphique montre la coloration.
- Le rouge est un CPI faible (donc beaucoup d'instructions par horloge ... Je pense que comme «chaud»)
- Le bleu est un CPI élevé (si peu d'instructions par horloge ... Je pense que comme «froid»)
- Vous trouverez ci-dessous un exemple de graphique CPI zoomé montrant la coloration et l'IPC. Les threads 'spin.x' ont été désélectionnés dans la légende CPU_BUSY afin qu'ils n'apparaissent pas dans le flamme.
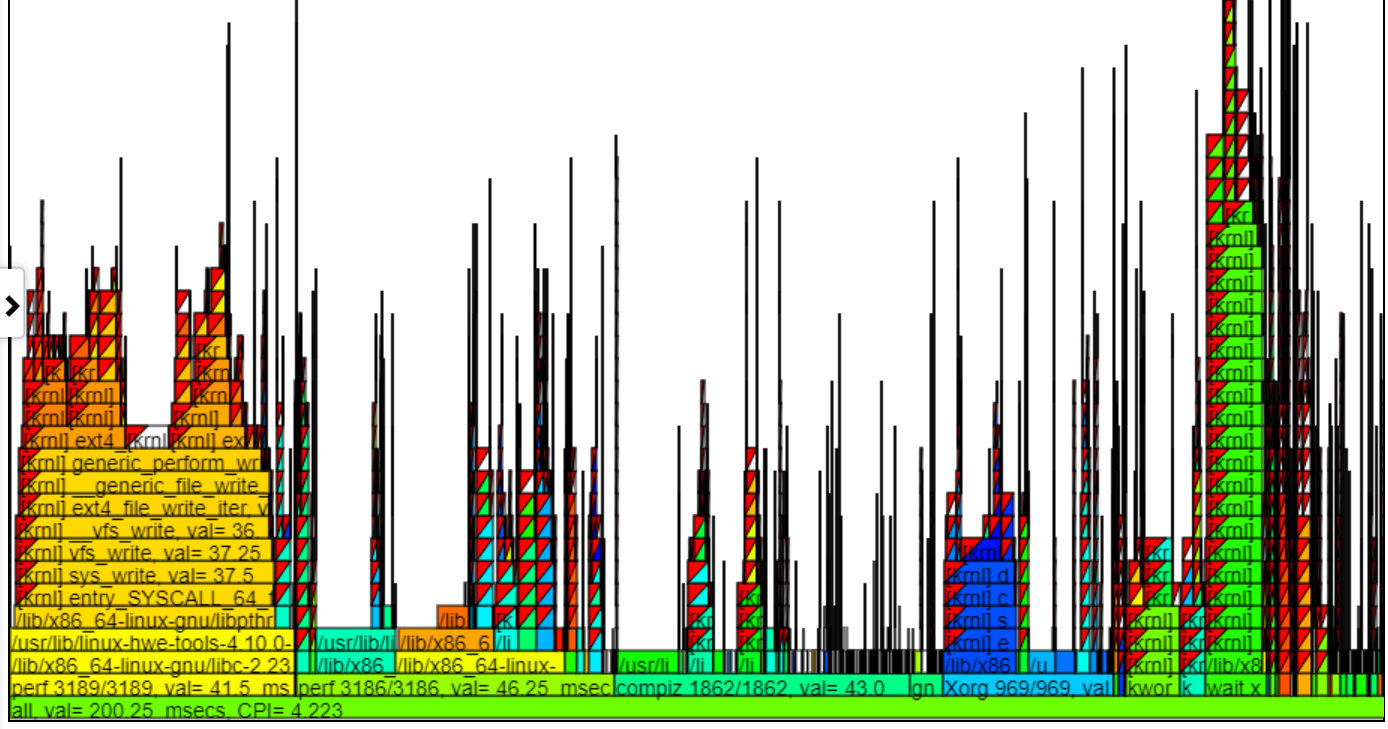
- Le graphique Flamegraph GIPS (Giga (milliards) par seconde colore le processus / pid / tid par les GIP pour cette pile.
- Vous trouverez ci-dessous un échantillon de graphique GIPS non zoomé (Giga / milliards d'instructions par seconde). L'instance de gauche de Spin.x (en vert clair) a un GIPS = 1,13. Les 4 spin.x à droite en vert bleu ont un GIPS = 0,377. Le Callstack dans le ballon est pour celui des pics d'appel à gauche du ballon.

- Dans le graphique ci-dessus, notez que la pile de gauche (pour Spin.x) obtient des instructions / sec plus élevés que les 4 instances les plus à droite de Spin.x. Cette 1ère instance de Spin.x s'exécute par elle-même (il obtient donc beaucoup de mémoire BW) et les filetages à droite 4 spin.x fonctionnent en parallèle et obtiennent un GIPS inférieur (car un thread peut à peu près maximiser la mémoire BW).
- Vous devez avoir des instructions et des calculs de CPU (ou sched_switch)
- La largeur de la «flamme» GIPS est basée sur le temps de blocage du CPU.
- La couleur est basée sur les GIP. Un gradient rouge à vert à bleu en haut à gauche du graphique montre la coloration.
- Le rouge est un GIPS élevé (donc beaucoup d'instructions par seconde ... Je pense que comme «chaud» en faisant beaucoup de travail)
- Le bleu est un gips bas (si peu d'instructions par seconde ... je pense que comme «froid»)
- Vous trouverez ci-dessous un exemple de graphique GIPS zoomé montrant la coloration et les GIP. J'ai cliqué sur le «Perf 3186/3186», donc cette flamme est indiquée ci-dessous.
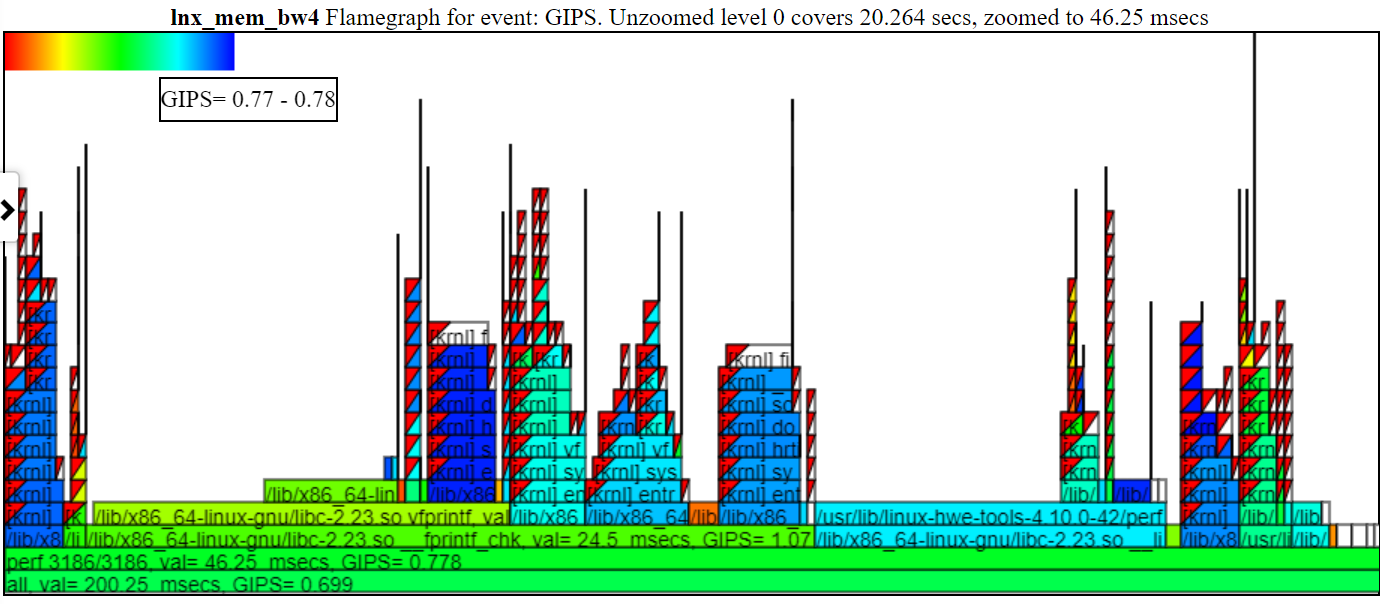
- Si vous masquez un processus dans la légende (cliquez sur l'entrée de la légende ... il sera grisé), le processus ne sera pas affiché dans le FlameGraph.
- Si vous faites glisser la souris dans la flamme, cette section du flamme sera zoom
- Cliquez sur un zoom 'Flame' sur cette flamme
- La gauche en traînant la souris dans le flamme à zoom
- cliquer sur un niveau inférieur du flammegraph «dézooms» à toutes les données de ce niveau
- Si vous cliquez sur le «tout» le plus bas de la flamme, vous zoomerez tout le chemin
- Lorsque vous cliquez sur le niveau de flamme, le graphique est redimensionné afin que chaque niveau soit suffisamment élevé pour afficher le texte. Cela fait redimensionner le graphique. Pour essayer d'ajouter une certaine santé mentale à ce redimensionnement, je positionne le dernier niveau du graphique redimensionné au bas de l'écran visible.
- Si vous retournez dans la légende et survolez-vous sur une entrée cachée, cette entrée sera affichée dans le flamme jusqu'à ce que vous soyez oscillé
- Si vous cliquez sur un niveau supérieur «Flame», cette section sera zoomée.
- Si vous zoomez / Out sur le graphique «parent», les flammeurs seront redessinés pour l'intervalle sélectionné
- Si vous vous bandez à gauche / à droite sur le graphique «parent», les flammes seront redessinés pour l'intervalle sélectionné
- Par défaut, le texte de chaque niveau du graphique de flamme ne s'adaptera probablement pas. Si vous cliquez sur FLAMEGRAPH, la taille sera étendue pour permettre à dessiner le texte également
- Vous pouvez sélectionner (dans la barre de navigation de gauche) si vous devez regrouper les flammes par processus / pid / tid ou par processus / pid ou par processus.
- Les flammes «sur CPU», «OFF CPU» et «Run Queue» sont dessinés.
- `` Sur le processeur '' est l'appel pour ce que faisait le fil pendant qu'il fonctionnait sur le processeur ... donc les callons d'échantillonnage ou les callstacks de CPU perf.
- «Off CPU» montre, pour les fils qui ne fonctionnent pas, combien de temps ils attendaient et le Callstack lorsqu'ils ont été échangés.
- Vous trouverez ci-dessous une capture d'écran du tableau Off-CPU ou d'attente. La popup montre (dans le flamme) que «Wait.x» attend Nanosleep.

- L'échange «état» (et sur ETW la «raison») est indiqué comme un niveau au-dessus du processus. Habituellement, la plupart des threads dormiront ou ne fonctionnent pas, mais cela aide à répondre à la question: "Quand mon fil n'a pas fonctionné ... Qu'est-ce qu'il attendait?".
- Affichage de «l'état» du commutateur de contexte vous permet de voir:
- Par exemple, si un fil attend sur un sommeil non interruptible (état == D sur Linux ... généralement IO)
- sommeil interruptible (état = s ... souvent un nanoslee ou futex)
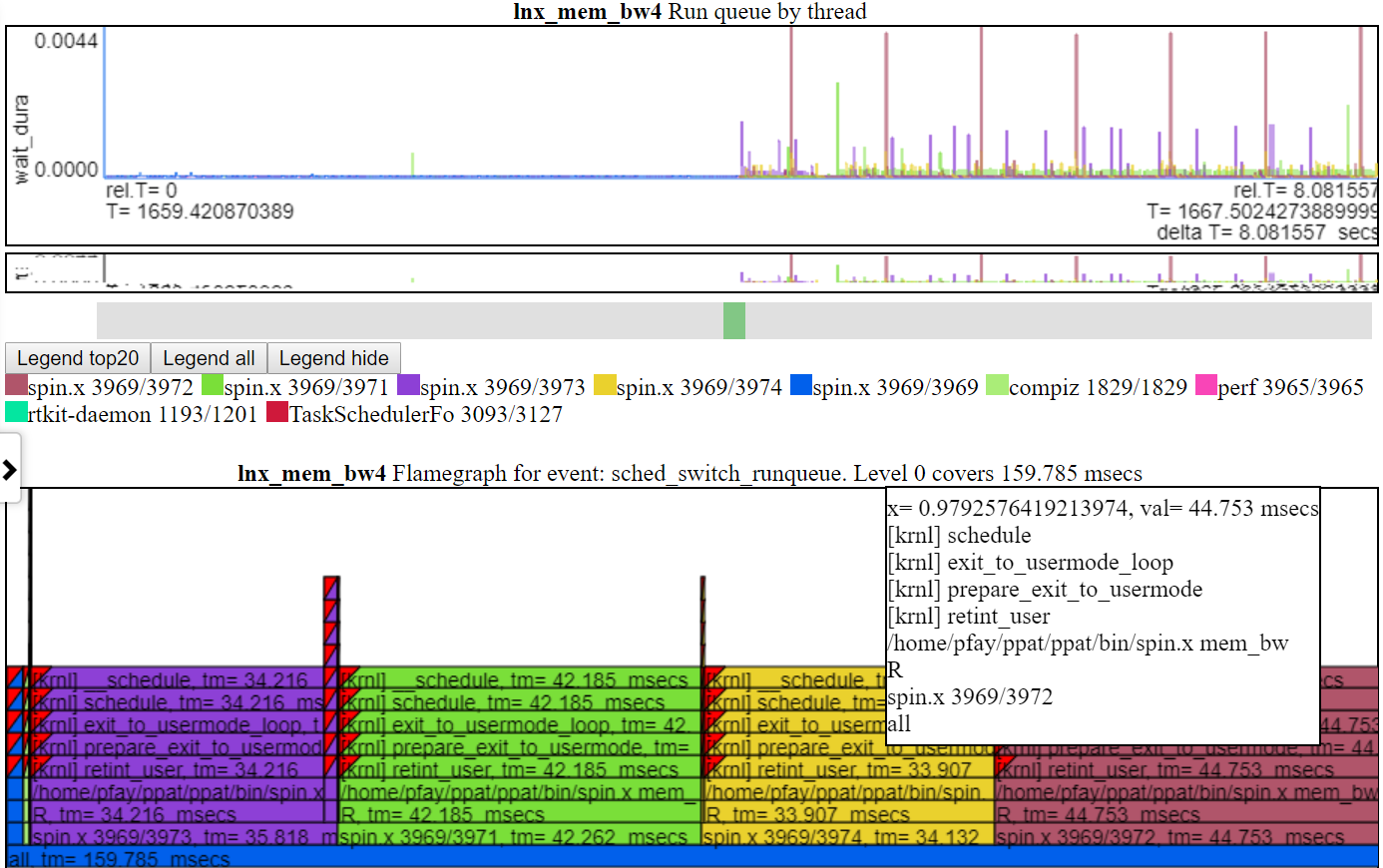
- «Run Queue» montre les fils qui ont été échangés et qui étaient dans un état de course ou de course. Donc, ce graphique montre la saturation du CPU s'il y a des threads dans un état coulant mais pas en cours d'exécution.
- Vous trouverez ci-dessous la capture d'écran du tableau Run_queue. Ce graphique montre le temps qu'un fil n'a pas exécuté car il n'y avait pas assez de processeur. Autrement dit, il était prêt à courir, mais quelque chose d'autre utilisait le CPU. Chaque Flamegraph montre le total couvert du graphique. Dans le cas du tableau Run_queue, il montre ~ 159 ms en temps d'attente. Donc, étant donné que Spin.x a environ 20 secondes de fonctionnement et 0,159 seconde d'attente, cela ne semble pas trop mauvais.
Je n'avais pas de bibliothèque de graphiques basée sur une toile à utiliser, donc les graphiques sont un peu grossiers ... Je ne voulais pas passer trop de temps à créer les graphiques s'il y a quelque chose de mieux là-bas. Les graphiques doivent utiliser la toile HTML (pas les SVG, D3.JS, etc.) en raison de la quantité de données.
Collecte de données pour Oppat
La collecte des données sur les performances et l'alimentation est très «situationnelle». Une personne voudra exécuter des scripts, une autre voudra démarrer des mesures avec un bouton, puis démarrer une vidéo, puis terminer la collection avec un bouton. J'ai un script pour Windows et un script pour Linux qui démontre:
- Démarrage de la collecte de données,
- exécuter une charge de travail,
- Arrêter la collecte des données
- Postez les données (création d'un fichier texte à partir des données binaires perf / xperf / trace-cmd)
- Mettre tous les fichiers de données dans un DIR de sortie
- Création d'un fichier file_list.json dans le Dir de sortie (qui indique à Oppat le nom et le type des fichiers de sortie)
Les étapes de la collecte de données à l'aide des scripts:
- Build Spin.exe (spin.x) et Wait.exe (Wait.x)
- de la racine Oppat Dir Do:
- sur linux:
./mk_spin.sh - sur Windows :
.mk_spin.bat (à partir d'une boîte CMD Visual Studio) - Les binaires seront placés dans le Subdir ./Bin
- Commencez par exécuter les scripts fournis:
- run_perf_x86_haswell.sh - Pour la collecte de données Haswell CPU_DIAGRAM
- Sur Linux, Type:
sudo bash ./scripts/run_perf.sh - Par défaut, le script met les données dans dir ../oppat_data/lnx/mem_bw7
- run_perf.sh - vous devez faire installer Trace-CMD et perf
- Sur Linux, Type:
sudo bash ./scripts/run_perf.sh - Par défaut, le script met les données dans dir ../oppat_data/lnx/mem_bw4
- run_xperf.bat - vous devez installer xperf.exe.
- Sous Windows, à partir d'une boîte CMD avec privilèges d'administration, tapez :
.scriptsrun_xperf.sh - Par défaut, le script met les données dans dir .. oppat_data win mem_bw4
- Modifiez le script d'exécution si vous souhaitez modifier les valeurs par défaut
- En plus des fichiers de données, le script d'exécution crée un fichier file_list.json dans le Dir de sortie. Oppat utilise le fichier file_list.json pour déterminer les noms de fichiers et le type de fichiers dans le Dir de sortie.
- La «charge de travail» pour le script d'exécution est spin.x (ou spin.exe) qui fait un test de bande passante de mémoire sur 1 CPU pendant 4 secondes, puis sur tous les processeurs pendant 4 secondes supplémentaires.
- Un autre programme wait.x / wait.exe est également démarré en arrière-plan. Wait.cpp lit les informations sur la batterie de mon ordinateur portable. Il fonctionne sur mon double ordinateur portable Ubuntu Boot Windows 10 / Linux. Le fichier sysfs peut avoir un nom différent sur votre Linux et est presque sûrement différent sur Android.
- Sur Linux, vous pourriez probablement générer un fichier prf_trace.data et prf_trace.txt en utilisant la même syntaxe que dans run_perf.sh mais je n'ai pas essayé cela.
- Si vous utilisez un ordinateur portable et que vous souhaitez obtenir la batterie, n'oubliez pas de déconnecter le câble d'alimentation avant d'exécuter le script.
Prise en charge des données PCM
- Oppat peut lire et tracer les fichiers .csv PCM.
- Vous trouverez ci-dessous un instantané de la liste des graphiques créés.
- Malheureusement, vous devez faire un correctif sur PCM pour créer un fichier avec un horodatage absolu pour Oppat à traiter.
- En effet, le fichier PCM CSV n'a pas d'horodatage que je peux utiliser pour être en corrélation avec les autres sources de données.
- J'ai ajouté le patch ici Patch PCM
Bâtiment Oppat
- Sur Linux, Type
make in Oppat Root Dir- Si tout fonctionne, il devrait y avoir un fichier bin / oppat.x
- Sur Windows, vous devez:
- Installez la version Windows de GNU Make. Voir http://gnuwin32.sourceforge.net/packages/make.htm ou, pour les binaires minimaux requis, utilisez http://gnuwin32.sourceforge.net/downlinks/make.php
- Mettez ce nouveau binaire «faire» sur le chemin
- Vous avez besoin d'un compilateur C / C ++ actuel Visual Studio 2015 ou 2017 (j'ai utilisé à la fois le VS 2015 Professional et les compilateurs communautaires VS 2017)
- Démarrer une boîte d'invite CMD Native CMD Windows Visual Studio X64
- Type
make in the Oppat Root Dir - Si tout fonctionne, il devrait y avoir un fichier bin oppat.exe
- Si vous modifiez le code source, vous avez probablement besoin de reconstruire le fichier de dépendance inclue
- Vous devez faire installer Perl
- Sur Linux, dans l'oppat root dir:
./mk_depends.sh . Cela créera un fichier de dépendance Defend_lnx.mk. - on Windows, in the OPPAT root dir do:
.mk_depends.bat . This will create a depends_win.mk dependency file.
- If you are going to run the sample run_perf.sh or run_xperf.bat scripts, then you need to build the spin and wait utilities:
- On Linux:
./mk_spin.sh - On Windows:
.mk_spin.bat
Running OPPAT
- Run the data collection steps above
- now you have data files in a dir (if you ran the default run_* scripts:
- on Windows ..oppat_datawinmem_bw4
- on Linux ../oppat_data/lnx/mem_bw4
- You need to add the created files to the input_filesinput_data_files.json file:
- Starting OPPAT reads all the data files and starts the web server
- on Windows to generate the haswell cpu_diagram (assuming your data dir is ..oppat_datalnxmem_bw7)
binoppat.exe -r ..oppat_datalnxmem_bw7 --cpu_diagram webhaswell_block_diagram.svg > tmp.txt
- on Windows (assuming your data dir is ..oppat_datawinmem_bw4)
binoppat.exe -r ..oppat_datawinmem_bw4 > tmp.txt
- on Linux (assuming your data dir is ../oppat_data/lnx/mem_bw4)
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 > tmp.txt
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 --web_file tst2.html > tmp.txt
- Then you can load the file into the browser with the URL address:
file:///C:/some_path/oppat/tst2.html
Derived Events
'Derived events' are new events created from 1 or more events in a data file.
- Say you want to use the ETW Win32k InputDeviceRead events to track when the user is typing or moving the mouse.
- ETW has 2 events:
- Microsoft-Windows-Win32k/InputDeviceRead/win:Start
- Microsoft-Windows-Win32k/InputDeviceRead/win:Stop
- So with the 2 above events we know when the system started reading input and we know when it stopped reading input
- But OPPAT plots just 1 event per chart (usually... the cpu_busy chart is different)
- We need a new event that marks the end of the InputDeviceRead and the duration of the event
- The derived event needs:
- a new event name (in chart.json... see for example the InputDeviceRead event)
- a LUA file and routine in src_lua subdir
- 1 or more 'used events' from which the new event is derived
- the derived events have to be in the same file
- For the InputDeviceRead example, the 2 Win32k InputDeviceRead Start/Stop events above are used.
- The 'used events' are passed to the LUA file/routine (along with the column headers for the 'used events') as the events are encountered in the input trace file
- In the InputDeviceRead lua script:
- the script records the timestamp and process/pid/tid of a 'start' event
- when the script gets a matching 'Stop' event (matching on process/pid/tid), the script computes a duration for the new event and passes it back to OPPAT
- A 'trigger event' is defined in chart.json and if the current event is the 'trigger event' then (after calling the lua script) the new event is emitted with the new data field(s) from the lua script.
- An alternate to the 'trigger event' method is to have the lua script indicate whether or not it is time to write the new event. For instance, the scr_lua/prf_CPI.lua script writes a '1' to a variable named ' EMIT ' to indicate that the new CPI event should be written.
- The new event will have:
- the name (from the chart.json evt_name field)
- The data from the trigger event (except the event name and the new fields (appended)
- I have tested this on ETW data and for perf/trace-cmd data
Using the browser GUI Interface
TBD
Defining events and charts in charts.json
TBD
Rules for input_data_files.json
- The file 'input_files/input_data_files.json' can be used to maintain a big list of all the data directories you have created.
- You can then select the directory by just specifying the file_tag like:
- bin/oppat.x -u lnx_mem_bw4 > tmp.txt # assuming there is a file_tag 'lnx_mem_bw4' in the json file.
- The big json file requires you to copy the part of the data dir's file_list.json into input_data_files.json
- in the file_list.json file you will see lines like:
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- don't copy the lines like below from the file_list.json file:
- paste the copied lines into input_data_files.json. Pay attention to where you paste the lines. If you are pasting the lines at the top of input_data_files.json (after the
{"root_dir":"/data/ppat/"}, then you need add a ',' after the last pasted line or else JSON will complain. - for Windows data files add an entry like below to the input_filesinput_data_files.json file:
- yes, use forward slashes:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- for Linux data files add an entry like below to the input_filesinput_data_files.json file:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/lnx/mem_bw4 " },
{ "cur_tag" : " lnx_mem_bw4 " },
{ "bin_file" : " prf_energy.txt " , "txt_file" : " prf_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " },
{ "bin_file" : " prf_trace.data " , "txt_file" : " prf_trace.txt " , "tag" : " %cur_tag% " , "type" : " PERF " },
{ "bin_file" : " tc_trace.dat " , "txt_file" : " tc_trace.txt " , "tag" : " %cur_tag% " , "type" : " TRACE_CMD " },- Unfortunately you have to pay attention to proper JSON syntax (such as trailing ','s)
- Here is an explanation of the fields:
- The 'root_dir' field only needs to entered once in the json file.
- It can be overridden on the oppat cmd line line with the
-r root_dir_path option - If you use the
-r root_dir_path option it is as if you had set "root_dir":"root_dir_path" in the json file - the 'root_dir' field has to be on a line by itself.
- The cur_dir field applies to all the files after the cur_dir line (until the next cur_dir line)
- the '%root_dir% string in the cur_dir field is replaced with the current value of 'root_dir'.
- the 'cur_dir' field has to be on a line by itself.
- the 'cur_tag' field is a text string used to group the files together. The cur_tag field will be used to replace the 'tag' field on each subsequent line.
- the 'cur_tag' field has to be on a line by itself.
- For now there are four types of data files indicated by the 'type' field:
- type:PERF These are Linux perf files. OPPAT currently requires both the binary data file (the bin_file field) created by the
perf record cmd and the perf script text file (the txt_file field). - type:TRACE_CMD These are Linux trace-cmd files. OPPAT currently requires both the binary dat file (the bin_file field) created by the
trace-cmd record cmd and the trace-cmd report text file (the txt_file field). - type:ETW These are Windows ETW xperf data files. OPPAT currently requires only the text file (I can't read the binary file). The txt_file is created with
xperf ... -a dumper command. - type:LUA These files are all text files which will be read by the src_lua/test_01.lua script and converted to OPPAT data.
- the 'prf_energy.txt' file is
perf stat output with Intel RAPL energy data and memory bandwidth data. - the 'prf_energy2.txt' file is created by the wait utility and contains battery usage data in the 'perf stat' format.
- the 'wait.txt' file is created by the wait utility and shows the timestamp when the wait utility began
- Unfortunately 'perf stat' doesn't report a high resolution timestamp for the 'perf stat' start time
Limites
- The data is not reduced on the back-end so every event is sent to the browser... this can be a ton of data and overwhelm the browsers memory
- I probably should have some data reduction logic but I wanted to get feedback first
- You can clip the files to a time range:
oppat.exe -b abs_beg_time -e abs_beg_time to reduce the amout of data- This is a sort of crude mechanism right now. I just check the timestamp of the sample and discard it if the timestamp is outside the interval. If the sample has a duration it might actually have data for the selected interval...
- There are many cases where you want to see each event as opposed to averages of events.
- On my laptop (with 4 CPUs), running for 10 seconds of data collection runs fine.
- Servers with lots of CPUs or running for a long time will probably blow up OPPAT currently.
- The stacked chart can cause lots of data to be sent due to how it each event on one line is now stacked on every other line.
- Limited mechanism for a chart that needs more than 1 event on a chart...
- say for computing CPI (cycles per instruction).
- Or where you have one event that marks the 'start' of some action and another event that marks the 'end' of the action
- There is a 'derived events' logic that lets you create a new event from 1 or more other events
- See the derived event section
- The user has to supply or install the data collection software:
- on Windows xperf
- See https://docs.microsoft.com/en-us/windows-hardware/get-started/adk-install
- You don't need to install the whole ADK... the 'select the parts you want to install' will let you select just the performance tools
- on Linux perf and/or trace-cmd
sudo apt-get install linux-tools-common linux-tools-generic linux-tools- ` uname -r `
- For trace-cmd, see https://github.com/rostedt/trace-cmd
- You can do (AFAIK) everything in 'perf' as you can in 'trace-cmd' but I have found trace-cmd has little overhead... perhaps because trace-cmd only supports tracepoints whereas perf supports tracepoints, sampling, callstacks and more.
- Currently for perf and trace-cmd data, you have to give OPPAT both the binary data file and the post-processed text file.
- Having some of the data come from the binary file speeds things up and is more reliable.
- But I don't want to the symbol handling and I can't really do the post-processing of the binary data. Near as I can tell you have to be part of the kernel to do the post processing.
- OPPAT requires certain clocks and a certain syntax of 'convert to text' for perf and trace-cmd data.
- OPPAT requires clock_monotonic so that different file timestamps can be correlated.
- When converting the binary data to text (trace-cmd report or 'perf script') OPPAT needs the timestamp to be in nanoseconds.
- see scriptsrun_xperf.bat and scriptsrun_perf.sh for the required syntax
- given that there might be so many files to read (for example, run_perf.sh generates 7 input files), it is kind of a pain to add these files to the json file input_filesinput_data_files.json.
- the run_xperf.bat and run_perf.sh generate a file_list.json in the output directory.
- perf has so, so many options... I'm sure it is easy to generate some data which will break OPPAT
- The most obvious way to break OPPAT is to generate too much data (causing browser to run out of memory). I'll probably handle this case better later but for this release (v0.1.0), I just try to not generate too much data.
- For perf I've tested:
- sampling hardware events (like cycles, instructions, ref-cycles) and callstacks for same
- software events (cpu-clock) and callstacks for same
- tracepoints (sched_switch and a bunch of others) with/without callstacks
- Zooming Using touchpad scroll on Firefox seems to not work as well it works on Chrome



