GPPRMon
1.0.0
Detaillierte Dokumentation zu GPGPU-SIM, welche GPU-Modelle und Architekturen existieren, wie man sie konfiguriert, und eine Anleitung zum Quellcode finden Sie hier. Eine detaillierte Dokumentation über Accelwattch zum Erfassen von Stromverbrauchsmetriken für Unterkomponenten und eine Anleitung zum Quellcode finden Sie hier.
GPGPU-SIM-Abhängigkeiten:
gcc, g++, make, makedepend, xutils, bison, flex, zlib, CUDA Toolkit
(Optional) GPGPU-SIM-Dokumentationsabhängigkeiten:doxygen, graphvi
(optionale) Aerialvision-Abhängigkeiten:python-pmw, python-ply, python-numpy, libpng12-dev, python-matplotlib
CUDA SDK-Abhängigkeiten:libxi-dev, libxmu-dev, libglut3-dev
Nach der Installation der Voraussetzung Bibliotheken zum ordnungsgemäßen Ausführen des Simulators klonen Sie die Accelwattch-Implementierung des Simulators (GPGPU-SIM 4.2). Anschließend sollten Sie den folgenden Befehlen im Simulator -Verzeichnis folgen, um den Simulator zu erstellen.
user@GPPRMon:~ $ source setup_environment < build_type >
# That command sets the environment variables so that the simulator can find related executables in the linkage path.
# If you want to debug the simulator (as written in C/C++), you should specify build_type as ` debug ` .
# Otherwise, you do not need to specify it ; blank as empty. It will automatically build the executables with ` release ` version. user@GPPRMon:~ $ make # To compile source files, create and link the executable files of the simulator.
user@GPPRMon:~ $ make clean # To clean the simulator executablesWenn Sie Dokumentationsdateien generieren möchten, deren Abhängigkeiten als optional angegeben sind, müssen Sie zunächst die Abhängigkeiten installieren. Danach können Sie die Dokumente mit erhalten
user@GPPRMon:~ $ make docs # Generates doxygen files describing simulator elements
user@GPPRMon:~ $ make cleandocs # Deletes pre-generated doxygen files if they exist.Die generierte Dokumentation mit Doxygen erleichtert das Verständnis von Klassen, Vorlagen, Funktionen usw. für den Simulator.
Während der Simulation erstellt der Simulator auf dem folgenden Pfad Speicherzugriffsinformationen.
user@GPPRMon/runtime_profiling_metrics/memory_accesses:~ $ Um die Erfassung von Speicherzugriffsmetrik zu aktivieren, muss man die folgenden Flags in der Datei gpgpusim.config angeben.
| Flaggen | Beschreibungen | Standardwert |
|---|---|---|
| -MEM_PROFILER | Aktivieren des Sammelns von Speicherzugriffsmetriken | 0 = aus |
| -Mem_Runtime_Stat | Bestimmung der Abtastfrequenz für die metrische Sammlung | 100 (Aufzeichnung nach jedem 100 GPU -Zyklen) |
| -Ipc_per_prof_interval | Aufzeichnung von IPC -Raten für jede metrische Sammelprobe | 0 = nicht sammeln |
| -Truction_Monitor | Aufzeichnung von Problemen/Abschlussstatistiken der Anweisungen | 0 = nicht sammeln |
| -L1d_metrics | Aufzeichnung von Metriken für L1D -Cache -Zugriffe | 0 = nicht sammeln |
| -L2_metrics | Aufnahme von Metriken für L2 -Cache -Zugriffe aufnehmen | 0 = nicht sammeln |
| -Dram_Metrics | Aufnahme von Metriken für DRAM -Zugriffe | 0 = nicht sammeln |
| -Store_Enable | Aufzeichnungsmetriken sowohl für Speicher- als auch für Ladeanweisungen | 0 = Metriken für die Last aufnehmen |
| -Accumulate_Stats | Sammeln gesammelte Metriken | 0 = nicht sammeln |
Während der Simulation zeichnet der Simulator Stromverbrauchsmetriken auf dem folgenden Pfad auf.
user@GPPRMon/runtime_profiling_metrics/energy_consumption:~ $Der Simulator erstellt für jeden Kernel zur Laufzeit separate Ordner und Stromerstellungsmetriken. Derzeit werden die folgenden Stromverbrauchsmetriken unterstützt, diese Metriken können jedoch weiter verbessert werden, um Untereinheiten unabhängig zu untersuchen.
GPU
Kern
Ausführungseinheit (Registrieren Sie FU, Scheduler, Funktionseinheiten usw.)
Laden Sie die Store -Einheit (Querlatte, gemeinsamer Speicher, freigegebenes MEM -Miss/Füllenpuffer, Cache, Cache Prefetch -Puffer, Cache -Schreibbackpuffer, Cache -Miss -Puffer usw.)
Anweisung Funktionseinheit (Befehlscache, Zweig -Zielpuffer, Decoder, Zweigprädiktor usw.)Netzwerk auf Chip
L2 Cache
Dram + SpeichercontrollerFrontendmotor
Phy zwischen Speichercontroller und DRAM
Transaktionsmotor (Backend -Motor)
Dram
| Flaggen | Beschreibungen | Standardwert |
|---|---|---|
| -Power_Simulation_Enabled | Ermöglichen der Sammlung von Stromverbrauchsmetriken | 0 = aus |
| -GPGPU_RUNTIME_STAT | Bestimmung der Stichprobenfrequenz in Bezug auf den GPU -Zyklus | 1000 Zyklen |
| -Power_per_cycle_dump | Dumpeln detaillierter Ausgabe in jeder Probe | 0 = aus |
| -dvfs_enabled | Ein-/Aus -Dynamikspannungsfrequenzskalierung für Leistungsmodell ein-/ausschaltet | 0 = nicht aktiviert |
| -Aggregate_power_stats | Aufzeichnung von Problemen/Abschlussstatistiken der Anweisungen | 0 = nicht aggregieren |
| -steady_power_levels_enabled | Erstellen einer Datei für die stetigen Leistungsstufen | 0 = aus |
| -steady_State_Definition | zulässige Abweichung: Anzahl der Proben | 8: 4 |
| -Power_Trace_Enabled | Erstellen einer Datei für die Power Trace | 0 = aus |
| -Power_trace_zlevel | Kompressionsniveau des Leistungsverfolgungsprotokolls | 6, (0 = nein comp, 9 = höchste) |
| -Power_Simulation_Mode | Leistungszähler -Eingabe für die Leistungssimulation umschalten | 0, (0 = SIM, 1 = HW, 2 = HW-SIM-Hybrid) |
Unser Visualizer -Tool enthält .CSV -Dateien, die über die Laufzeitsimulation eines GPU -Kernels erhalten wurden und drei verschiedene Visualisierungsschemata erzeugt. Derzeit unterstützt der Simulator GTX480_FERMI, QV100_VOLTA, RTX2060S_TURING, RTX2060_TURING, RTX3070_AMPERE, TITAN_KEPLER, TITANV_VOLTA, TITANX_PASCAL GPUS Derzeit. Da jede GPU eine andere Speicherhierarchie hat, habe ich für jede Hierarchie unterschiedliche Schemata entwickelt. Ich habe jedoch SM- und GPU -Visualisierungen als eine so gestaltet, dass ihre Designs für jede GPU anwendbar sind.
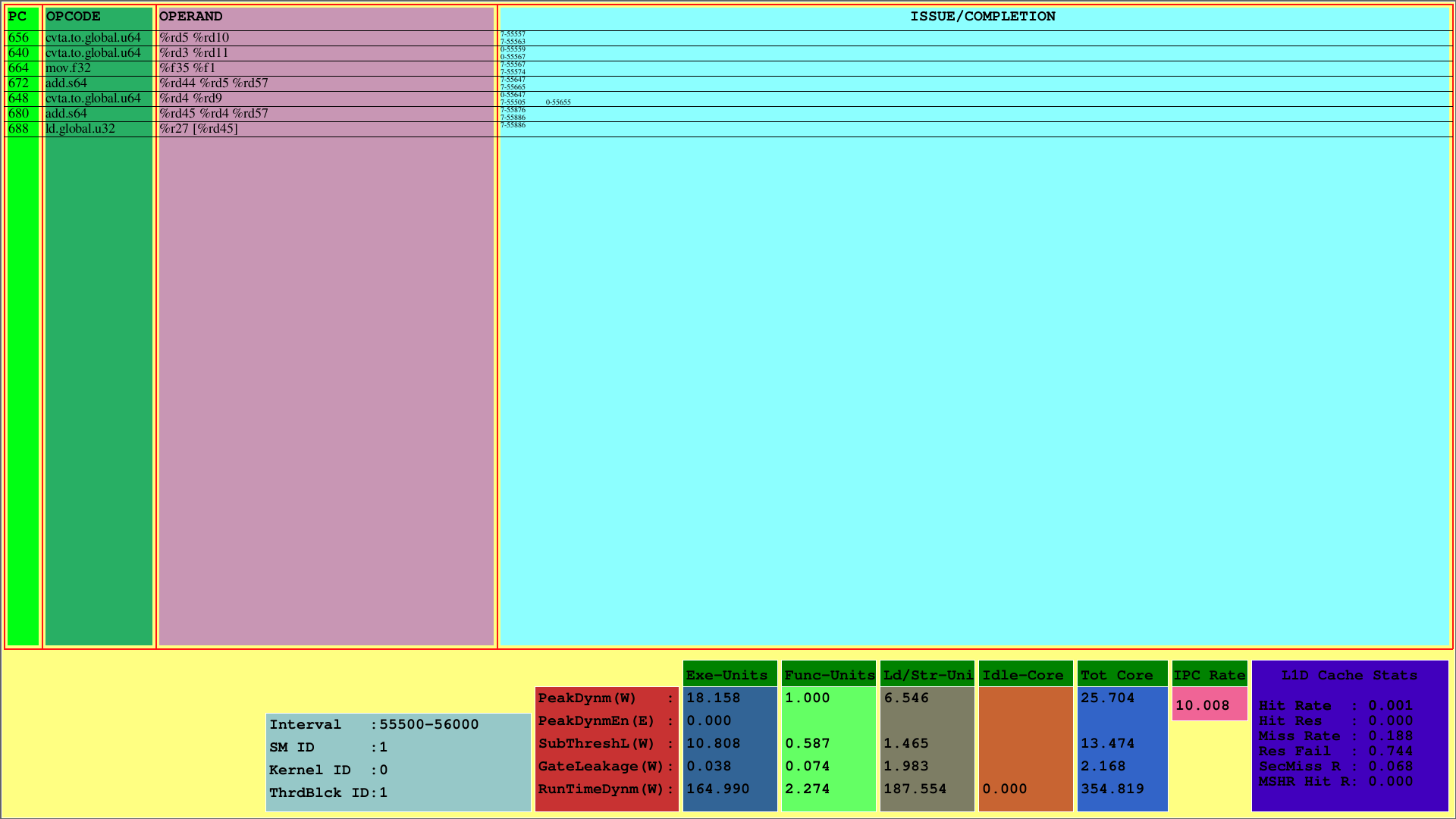
Die erste Visualisierung zeigt die Anweisungen für den 1. CTA an, der auf den 1. SM zugeordnet ist. Während PC den PC des Befehls anzeigt, zeigt Opcode die Betriebscodes der Anweisungen des 1. Threadblocks an. Operanden zeigen die Register -IDs für den entsprechenden Opcode der Anweisungen an.
Zur Spalte rechts (Ausgabe/Fertigstellung) zeigt der Visualizer die Ausstellungs- und Fertigstellungsinformationen der Anweisungen für jede Kette in der ersten Zeile bzw. der zweiten Reihe an. Beispielsweise lautet die erste Anweisung cvta.to.global.u64, dessen PC 656 ist, im 555557. Zyklus vom 7. Kette ausgestellt und im 55563. Zyklus abgeschlossen.
Dieses Schema zeigt die ausgestellten und abgeschlossenen Anweisungen eines CTA innerhalb eines vorgegebenen Zyklusintervalls. Für das obige Beispiel ist dieses Intervall das [55500, 56000).
Darüber hinaus kann die Nutzung von L1D -Cache und die Messungen der Laufzeit für die Unterkomponenten der SMS erfolgen. Der Parameter Runimedynm repräsentiert die Gesamtverbrauchsleistung für jeden Abschnitt. Ausführung, Funktions- und Last-/Speichereinheiten sowie Idle-Core sind die Hauptunterteilungen des Stromverbrauchs eines SM. Außerdem wird IPC pro SM unten angezeigt.

Die zweite Visualisierung zeigt die Zugriffe auf L1D-, L2 -Caches (als hits, hit_reserved_status, misses, reservation_failures, sector_misses, and mshr_hits ) und DRAM -Partitionen (als row buffer hits and row buffer misses ) innerhalb des Simulatorintervalls. Für Caches sind die Zugriffsbeschreibungen wie folgt:
Für DRAM sind die Zugriffsbeschreibungen wie folgt:
GPUs bestehen hauptsächlich aus SMS, die funktionale Einheiten, Registerdateien und Caches, NOCs und Speicherpartitionen enthalten, in denen DRAM -Banken und L2 -Caches existieren. Für die konfigurierten Architekturen entspricht die Anzahl der L1D -Caches SMS (SIMT -Kerncluster), die Anzahl der DRAM -Banken entspricht der Anzahl der Speicherpartitionen, und die Anzahl der L2 -Caches entspricht der doppelten Anzahl der Speicherpartitionen.
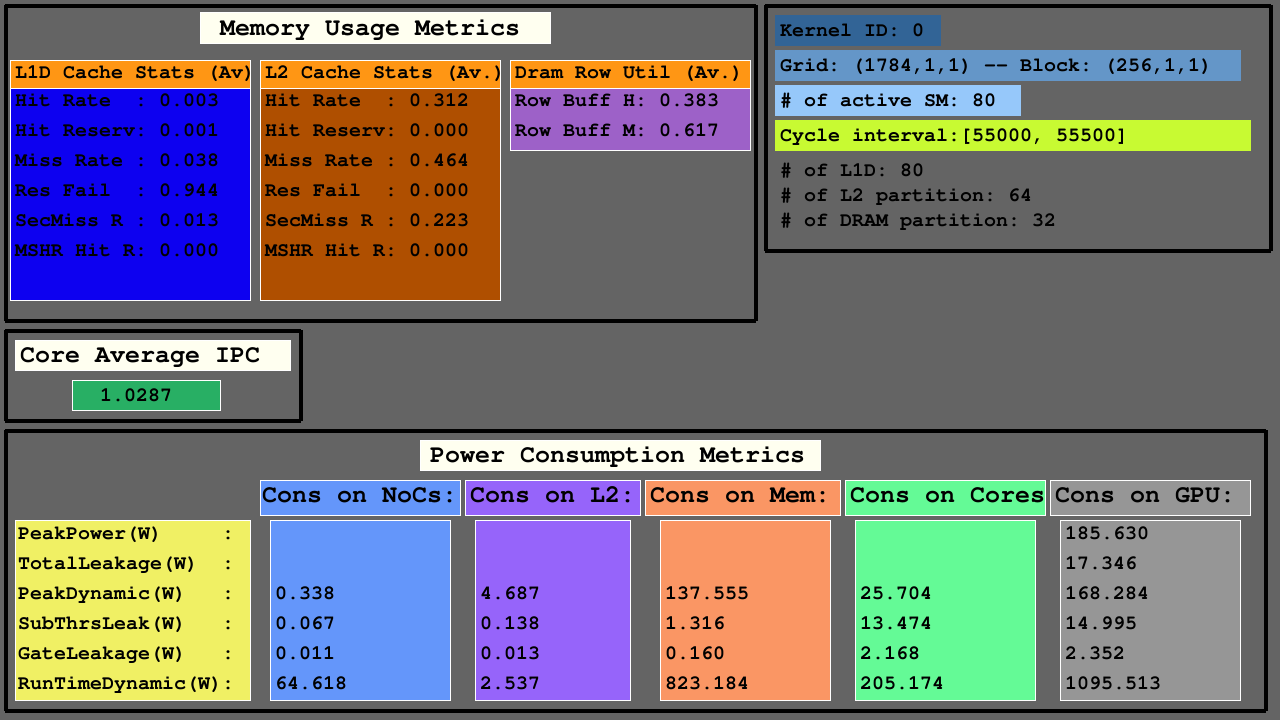
Die dritte Visualisierung zeigt die durchschnittlichen L1D-, L2-Cache- und DRAM-Zugriffsstatistiken in den Speicherverwendungsmetriken, durch durchschnittliche IPC zwischen aktiven SMS und Stromverbrauchsmetriken von NOCs, Speicherpartitionen von L2-Caches und MC+Dram sowie SMS.
Zusätzlich zu den oben genannten Optionen zur Laufzeitvisualisierung bieten wir eine Anzeigeoption für die durchschnittliche Statistiken des Laufzeitspeicherzugriffs und die IPC vs -Leistung zwischen den folgenden Einheiten. 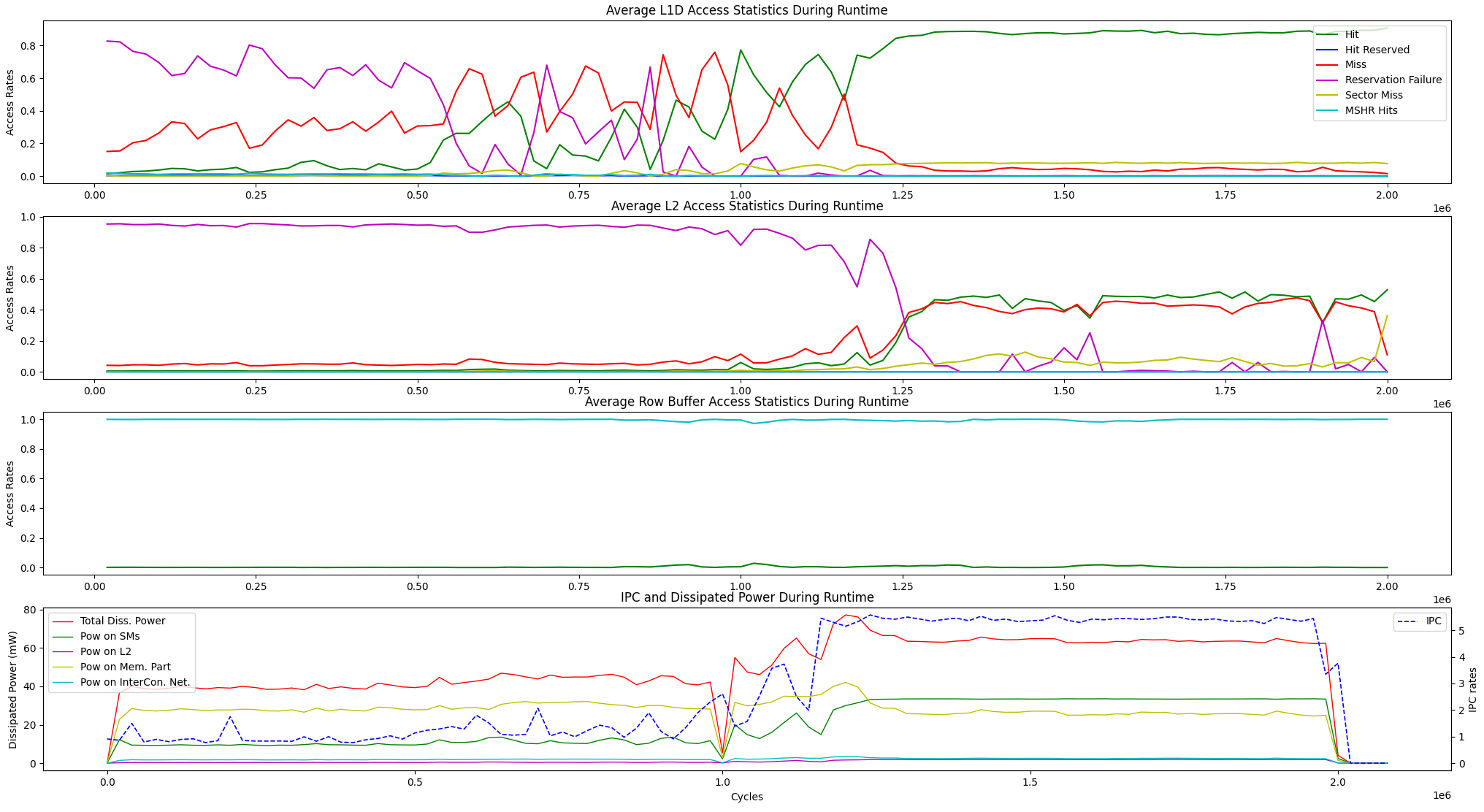
user@GPPRMon/runtime_visualizer:~ $ python3 average_disp.py param1 param2 param3 param4Wir haben mit dem Seitenranking -Algorithmus (PR) unter GV100 und RTX2060 experimentiert. Außerdem haben wir die GPU von Jetson Agx Xavier und Xavier NX GPUs konfiguriert und mit dem schnellen Fourier -Transformationsalgorithmus experimentiert. Experimentelle Profilerstellung und Anzeigen der Ergebnisse sind zu groß, um hier hochzuladen. Wir halten sie jedoch auf unseren lokalen Servern. Wenn Sie möchten, können wir diese Ergebnisse senden. Zögern Sie nicht, uns für Hilfe und Ergebnisse zu kontaktieren.


