GPPRMon
1.0.0
GPGPU-SIMに関する詳細なドキュメント、GPUモデルとアーキテクチャが存在するもの、設定方法、ソースコードのガイドはここにあります。また、サブコンポーネントの消費電力メトリックとソースコードのガイドを収集するためのAccelwattchの詳細なドキュメントは、こちらをご覧ください。
gpgpu-sim依存関係:
gcc, g++, make, makedepend, xutils, bison, flex, zlib, CUDA Toolkit
(オプション) gpgpu-simドキュメント依存関係:doxygen, graphvi
(オプション) aerialvision依存関係:python-pmw, python-ply, python-numpy, libpng12-dev, python-matplotlib
CUDA SDK依存関係:libxi-dev, libxmu-dev, libglut3-dev
シミュレーターを適切に実行するために前提条件ライブラリをインストールした後、シミュレーターのAccelwattch実装(GPGPU-SIM 4.2)をクローンします。次に、シミュレーターディレクトリ内の以下のコマンドに従って、シミュレーターを構築する必要があります。
user@GPPRMon:~ $ source setup_environment < build_type >
# That command sets the environment variables so that the simulator can find related executables in the linkage path.
# If you want to debug the simulator (as written in C/C++), you should specify build_type as ` debug ` .
# Otherwise, you do not need to specify it ; blank as empty. It will automatically build the executables with ` release ` version. user@GPPRMon:~ $ make # To compile source files, create and link the executable files of the simulator.
user@GPPRMon:~ $ make clean # To clean the simulator executablesさらに、依存関係がオプションとして指定されているドキュメントファイルを生成する場合は、最初に依存関係をインストールする必要があります。その後、ドキュメントを取得できます
user@GPPRMon:~ $ make docs # Generates doxygen files describing simulator elements
user@GPPRMon:~ $ make cleandocs # Deletes pre-generated doxygen files if they exist.Doxygenを使用した生成されたドキュメントは、シミュレーターのクラス、テンプレート、関数などの理解を緩和します。
シミュレーション中、シミュレータは以下のパスにメモリアクセス情報を作成します。
user@GPPRMon/runtime_profiling_metrics/memory_accesses:~ $メモリアクセスメトリックコレクションを有効にするには、 gpgpusim.configファイルの以下のフラグを指定する必要があります。
| フラグ | 説明 | デフォルト値 |
|---|---|---|
| -mem_profiler | メモリアクセスメトリックの収集を有効にします | 0 =オフ |
| -mem_runtime_stat | メトリックコレクションのサンプリング周波数の決定 | 100(100 GPUサイクルごとに記録) |
| -ipc_per_prof_interval | 各メトリックコレクションサンプルのIPCレートの記録 | 0 =収集しないでください |
| -instruction_monitor | 命令の問題/完了統計の記録 | 0 =収集しないでください |
| -l1d_metrics | L1Dキャッシュアクセスのメトリックの記録 | 0 =収集しないでください |
| -l2_metrics | L2キャッシュアクセスのメトリックの記録 | 0 =収集しないでください |
| -dram_metrics | DRAMアクセスのメトリックの記録 | 0 =収集しないでください |
| -store_enable | ストアと負荷の両方の手順のメトリックを記録します | 0 =負荷のメトリックを記録するだけです |
| -accumulate_stats | 収集されたメトリックを蓄積します | 0 =蓄積しないでください |
シミュレーション中、シミュレーターは以下のパスで消費電力メトリックを記録します。
user@GPPRMon/runtime_profiling_metrics/energy_consumption:~ $シミュレータは、実行時に各カーネルの個別のフォルダーと電源プロファイリングメトリックを作成します。今のところ、以下の消費電力メトリックはサポートされていますが、これらのメトリックは、サブユニットを独立して調査するためにさらに強化される可能性があります。
GPU
コア
実行ユニット(登録FU、スケジューラー、機能ユニットなど)
ロードストアユニット(クロスバー、共有メモリ、共有MEMミス/フィルバッファー、キャッシュ、キャッシュプリファッチバッファー、キャッシュ書き込みバッファー、キャッシュミスバッファなど)
命令機能ユニット(命令キャッシュ、分岐ターゲットバッファー、デコーダー、ブランチ予測子など)チップのネットワーク
L2キャッシュ
DRAM +メモリコントローラーフロントエンジン
メモリコントローラーとDRAMの間のPhy
トランザクションエンジン(バックエンドエンジン)
ドラム
| フラグ | 説明 | デフォルト値 |
|---|---|---|
| -power_simulation_enabled | 電力消費メトリックの収集を有効にします | 0 =オフ |
| -gpgpu_runtime_stat | GPUサイクルの観点からサンプリング周波数を決定します | 1000サイクル |
| -power_per_cycle_dump | 各サンプルに詳細な出力を投棄します | 0 =オフ |
| -dvfs_enabled | 電源モデルの動的電圧周波数スケーリングをオン/オフします | 0 =有効になっていません |
| -aggregate_power_stats | 命令の問題/完了統計の記録 | 0 =集約しないでください |
| -steady_power_levels_enabled | 定常電力レベルのファイルを生成します | 0 =オフ |
| -steady_state_definition | 許可偏差:サンプル数 | 8:4 |
| -power_trace_enabled | 電源トレース用のファイルを生成します | 0 =オフ |
| -power_trace_zlevel | 電源トレース出力ログの圧縮レベル | 6、(0 = comp、9 =最高) |
| -power_simulation_mode | パワーシミュレーションのパフォーマンスカウンター入力を切り替えます | 0、(0 = sim、1 = hw、2 = hw-simハイブリッド) |
Visualizerツールは、GPUカーネルのランタイムシミュレーションを介して取得された.CSVファイルを採用し、3つの異なる視覚化スキームを生成します。現在、シミュレーターはGTX480_FERMI, QV100_VOLTA, RTX2060S_TURING, RTX2060_TURING, RTX3070_AMPERE, TITAN_KEPLER, TITANV_VOLTA, TITANX_PASCAL GPUSをサポートしています。各GPUには異なるメモリ階層があるため、各階層のさまざまなスキームを設計しました。ただし、SMおよびGPUの視覚化を設計し、各GPUにデザインが適用できるように設計しました。
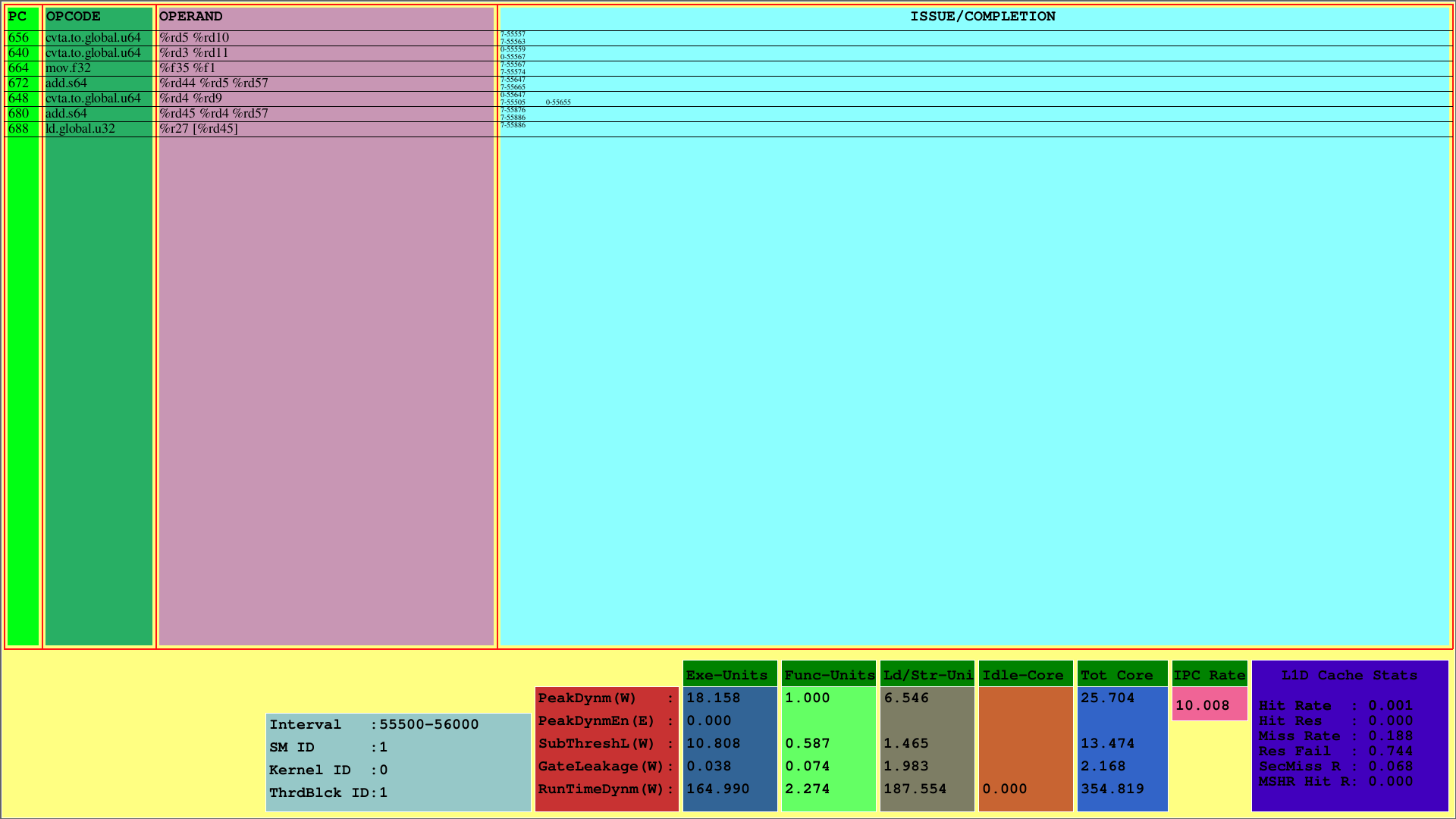
最初の視覚化には、1番目のSMにマッピングされる1番目のCTAの命令が表示されます。 PCは命令のPCを表示しますが、Opcodeは最初のスレッドブロックの命令の動作コードを表示します。オペランドは、命令の対応するオペコードの登録IDを示します。
右端の列(発行/完了)に、Visualizerは、それぞれ1行目と2列目の各ワープの指示の発行および完了情報を表示します。たとえば、最初の命令はCVTA.TO.GLOBAL.U64で、そのPCは656であり、55557番目のサイクルで7回目のワープで発行され、55563回目のサイクルで完了します。
このスキームは、所定のサイクル間隔内でCTAの発行および完了した命令を示しています。上記の例では、この間隔は[55500、56000)です。
さらに、SMSのサブコンポーネントのL1Dキャッシュの使用が見られ、ランタイム電源測定値を消費する場合があります。 runtimedynmパラメーターは、各セクションの総消費電力を表します。実行、機能およびロード/ストアユニット、およびアイドルコアは、SMの消費電力の主要なサブパートです。また、SMあたりのIPCは下部に表示されます。

2番目の視覚化は、L1D、L2キャッシュ( hits, hit_reserved_status, misses, reservation_failures, sector_misses, and mshr_hits )およびDRAMパーティション( row buffer hits and row buffer misses )のシミュレーター間でアクセスを示しています。キャッシュの場合、アクセスの説明は次のとおりです。
DRAMの場合、アクセスの説明は次のとおりです。
GPUは主に、機能ユニット、登録ファイル、キャッシュ、NOC、DRAMバンクとL2キャッシュが存在するメモリパーティションを含むSMSで構成されています。構成されたアーキテクチャの場合、L1Dキャッシュの数はSMS(SIMTコアクラスター)に等しく、DRAMバンクの数はメモリパーティションの数に等しく、L2キャッシュの数はメモリパーティションの2倍に等しくなります。
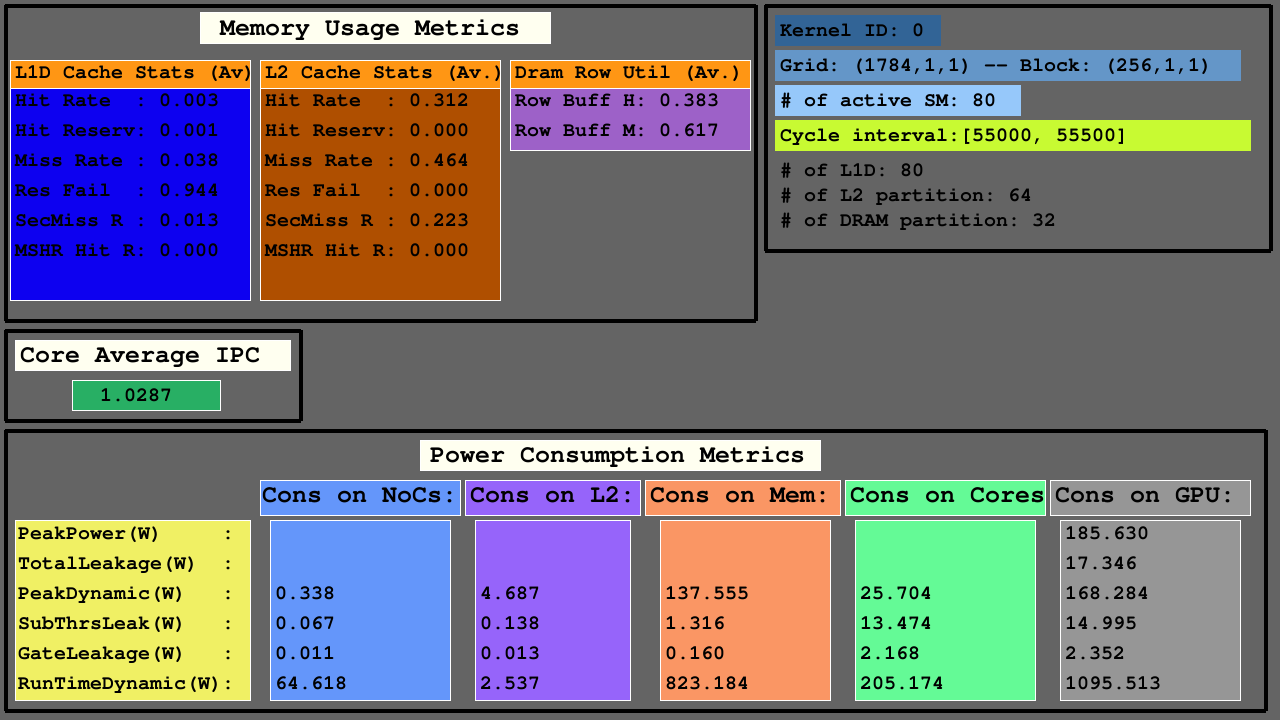
3番目の視覚化は、メモリ使用量メトリックにおけるL1D、L2キャッシュ、およびDRAMアクセス統計、アクティブSMS間の平均IPCおよびNOCの消費電力メトリック、L2キャッシュとMC+DRAMのメモリパーティション、およびSMSを示しています。
上記のランタイム視覚化オプションに加えて、以下のユニット間の平均ランタイムメモリアクセス統計とIPC対電力散逸のディスプレイオプションを提供します。 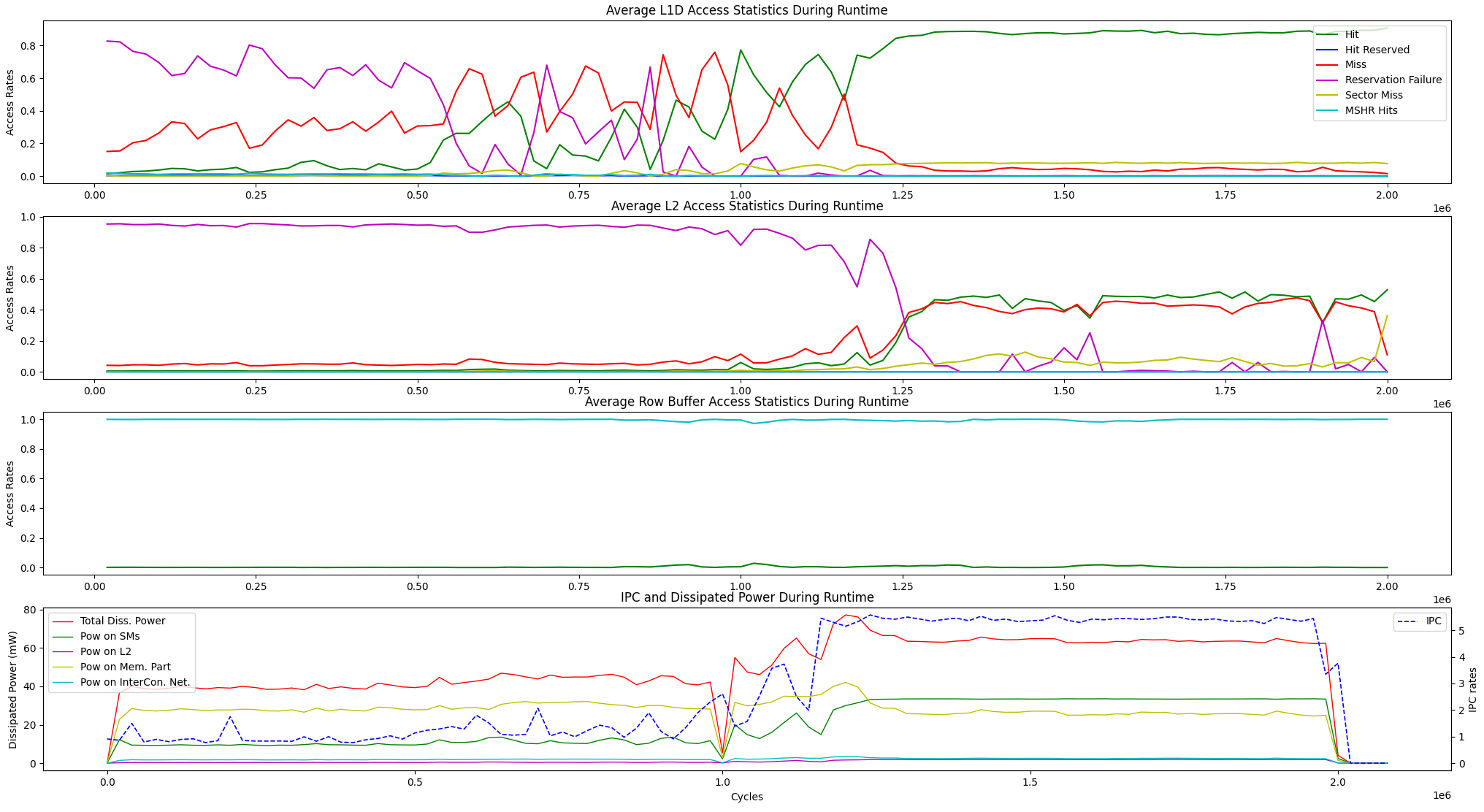
user@GPPRMon/runtime_visualizer:~ $ python3 average_disp.py param1 param2 param3 param4GV100およびRTX2060Sのページランキングアルゴリズム(PR)を実験しました。また、Jetson AGX XavierとXavier NX GPUのGPUを構成し、高速フーリエ変換アルゴリズムで実験しました。実験的なプロファイリングと結果の表示は、ここにアップロードするには大きすぎます。ただし、ローカルサーバーに保持しています。必要に応じて、これらの結果を送信できます。助けや結果についてお問い合わせください。


