GPPRMon
1.0.0
Dokumentasi terperinci tentang GPGPU-SIM, model dan arsitektur GPU apa yang ada, cara mengkonfigurasinya, dan panduan untuk kode sumber dapat ditemukan di sini. Juga, dokumentasi terperinci tentang Accelwattch untuk mengumpulkan metrik konsumsi daya untuk subkomponen dan panduan untuk kode sumber dapat ditemukan di sini.
Ketergantungan GPGPU-SIM:
gcc, g++, make, makedepend, xutils, bison, flex, zlib, CUDA Toolkit
(Opsional) GPGPU-SIM Dokumentasi Ketergantungan:doxygen, graphvi
(Opsional) Ketergantungan AerialVision:python-pmw, python-ply, python-numpy, libpng12-dev, python-matplotlib
Ketergantungan Cuda SDK:libxi-dev, libxmu-dev, libglut3-dev
Setelah memasang pustaka prasyarat untuk menjalankan simulator dengan benar, mengkloning implementasi Accelwattch dari simulator (GPGPU-SIM 4.2). Kemudian, Anda harus mengikuti perintah di bawah ini di dalam direktori simulator untuk membangun simulator.
user@GPPRMon:~ $ source setup_environment < build_type >
# That command sets the environment variables so that the simulator can find related executables in the linkage path.
# If you want to debug the simulator (as written in C/C++), you should specify build_type as ` debug ` .
# Otherwise, you do not need to specify it ; blank as empty. It will automatically build the executables with ` release ` version. user@GPPRMon:~ $ make # To compile source files, create and link the executable files of the simulator.
user@GPPRMon:~ $ make clean # To clean the simulator executablesSelain itu, jika Anda ingin menghasilkan file dokumentasi yang dependensi ditentukan sebagai opsional, Anda harus terlebih dahulu menginstal dependensi. Setelah itu, Anda bisa mendapatkan dokumen dengan
user@GPPRMon:~ $ make docs # Generates doxygen files describing simulator elements
user@GPPRMon:~ $ make cleandocs # Deletes pre-generated doxygen files if they exist.Dokumentasi yang dihasilkan dengan Doxygen memudahkan pemahaman kelas, templat, fungsi, dll., Untuk simulator.
Selama simulasi, simulator membuat informasi akses memori di jalur di bawah ini.
user@GPPRMon/runtime_profiling_metrics/memory_accesses:~ $ Untuk mengaktifkan pengumpulan metrik akses memori, seseorang harus menentukan bendera di bawah ini dalam file gpgpusim.config .
| Bendera | Deskripsi | Nilai default |
|---|---|---|
| -mem_profiler | Memungkinkan pengumpulan metrik akses memori | 0 = OFF |
| -mem_runtime_stat | Menentukan frekuensi pengambilan sampel untuk pengumpulan metrik | 100 (rekam setelah setiap 100 siklus GPU) |
| -Ipc_per_prof_interval | Merekam tarif IPC untuk setiap sampel pengumpulan metrik | 0 = Jangan mengumpulkan |
| -Instruction_monitor | Perekaman masalah/penyelesaian statistik instruksi | 0 = Jangan mengumpulkan |
| -L1d_metrics | Metrik Perekaman untuk Akses Cache L1D | 0 = Jangan mengumpulkan |
| -L2_metrics | Metrik Recordingollecting untuk Akses Cache L2 | 0 = Jangan mengumpulkan |
| -Dram_metrics | Metrik Rekaman untuk Akses DRAM | 0 = Jangan mengumpulkan |
| -store_enable | Merekam metrik untuk instruksi toko dan muatan | 0 = Cukup rekam metrik untuk beban |
| -accumulate_stats | Mengumpulkan metrik yang dikumpulkan | 0 = Jangan menumpuk |
Selama simulasi, simulator mencatat metrik konsumsi daya di jalur di bawah ini.
user@GPPRMon/runtime_profiling_metrics/energy_consumption:~ $Simulator akan membuat folder terpisah dan metrik profil daya untuk setiap kernel saat runtime. Untuk saat ini, metrik konsumsi daya di bawah ini didukung, tetapi metrik ini dapat ditingkatkan lebih lanjut untuk menyelidiki sub-unit secara mandiri.
GPU
Inti
Unit Eksekusi (Daftar FU, Penjadwal, Unit Fungsional, dll.)
Load Store Unit (Crossbar, Memori Bersama, Buffer MEM MISS/IFF Buffer, Cache, Buffer Prefetch Cache, Buffer WriteBack Cache, Buffer Cache Miss, dll.)
Instruksi Unit Fungsional (Cache Instruksi, Buffer Target Cabang, Decoder, Prediktor Cabang, dll.)Jaringan di Chip
L2 Cache
DRAM + Pengontrol MemoriMesin frontend
Phy antara controller memori dan drama
Mesin transaksi (mesin backend)
DRAM
| Bendera | Deskripsi | Nilai default |
|---|---|---|
| -power_simulation_enabled | Memungkinkan pengumpulan metrik konsumsi daya | 0 = OFF |
| -gpgpu_runtime_stat | Menentukan frekuensi pengambilan sampel dalam hal siklus GPU | 1000 siklus |
| -power_per_cycle_dump | Membuang output daya terperinci di setiap sampel | 0 = OFF |
| -dvfs_enabled | Menyalakan/mematikan penskalaan frekuensi tegangan dinamis untuk model daya | 0 = tidak diaktifkan |
| -aggregate_power_stats | Perekaman masalah/penyelesaian statistik instruksi | 0 = Jangan agregat |
| -steady_power_levels_enabled | Memproduksi file untuk tingkat daya yang stabil | 0 = OFF |
| -steady_state_definition | Diizinkan penyimpangan: jumlah sampel | 8: 4 |
| -power_trace_enabled | Memproduksi file untuk jejak daya | 0 = OFF |
| -power_trace_zlevel | Level kompresi log keluaran jejak daya | 6, (0 = tidak ada comp, 9 = tertinggi) |
| -power_simulation_mode | Switch Input Penghitung Kinerja untuk Simulasi Daya | 0, (0 = Sim, 1 = HW, 2 = HW-SIM Hybrid) |
Alat Visualizer kami mengambil file .csv yang diperoleh melalui simulasi runtime dari kernel GPU dan menghasilkan tiga skema visualisasi yang berbeda. Saat ini, simulator mendukung GTX480_FERMI, QV100_VOLTA, RTX2060S_TURING, RTX2060_TURING, RTX3070_AMPERE, TITAN_KEPLER, TITANV_VOLTA, TITANX_PASCAL saat ini. Karena setiap GPU memiliki hierarki memori yang berbeda, saya merancang berbagai skema untuk setiap hierarki. Namun, saya merancang visualisasi SM dan GPU sebagai salah satu sedemikian rupa sehingga desain mereka berlaku untuk setiap GPU.
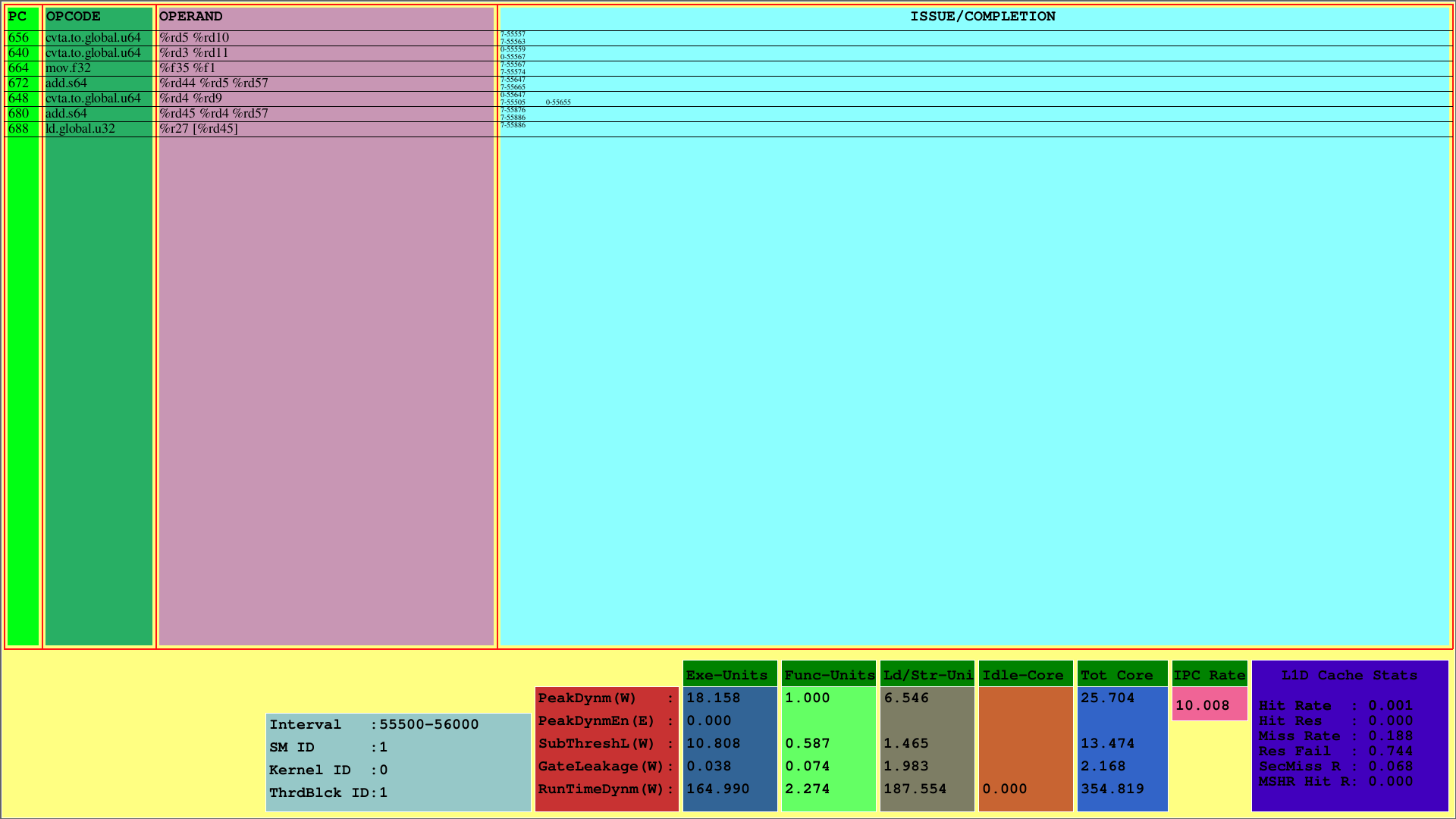
Visualisasi pertama menampilkan instruksi untuk CTA pertama, yang dipetakan ke SM 1. Sementara PC menunjukkan PC instruksi, opcode menunjukkan kode operasional dari instruksi blok utas pertama. Operan menunjukkan ID register untuk opcode yang sesuai dari instruksi.
Pada kolom paling kanan (masalah/penyelesaian), Visualiser menampilkan informasi penerbitan dan penyelesaian dari instruksi untuk setiap warp di baris pertama dan baris kedua, masing -masing. Sebagai contoh, instruksi pertama adalah cvta.to.global.u64, yang PC 656, dikeluarkan pada siklus 55577 pada warp ke -7 dan selesai pada siklus ke -55563.
Skema ini menunjukkan instruksi yang dikeluarkan dan diselesaikan CTA dalam interval siklus yang telah ditentukan. Untuk contoh di atas, interval ini adalah [55500, 56000).
Selain itu, orang dapat melihat penggunaan cache L1D dan pengukuran daya runtime yang dikonsumsi untuk subkomponen SMS. Parameter Runtimedynm mewakili total daya yang dikonsumsi untuk setiap bagian. Eksekusi, unit fungsional dan beban/penyimpanan, dan core idle adalah sub-bagian utama dari konsumsi daya SM. Juga, IPC per SM ditampilkan di bagian bawah.

Visualisasi kedua menunjukkan akses pada cache L1D, L2 (sebagai hits, hit_reserved_status, misses, reservation_failures, sector_misses, and mshr_hits ) dan partisi DRAM (sebagai row buffer hits and row buffer misses ) dalam interval yang sama. Untuk cache, deskripsi akses adalah sebagai berikut:
Untuk DRAM, deskripsi akses adalah sebagai berikut:
GPU terutama terdiri dari SMS, yang meliputi unit fungsional, mendaftar file dan cache, NOC, dan partisi memori di mana bank DRAM dan cache L2 ada. Untuk arsitektur yang dikonfigurasi, jumlah cache L1D sama dengan SMS (cluster inti SIMT), jumlah bank DRAM sama dengan jumlah partisi memori, dan jumlah cache L2 sama dengan dua kali jumlah partisi memori.
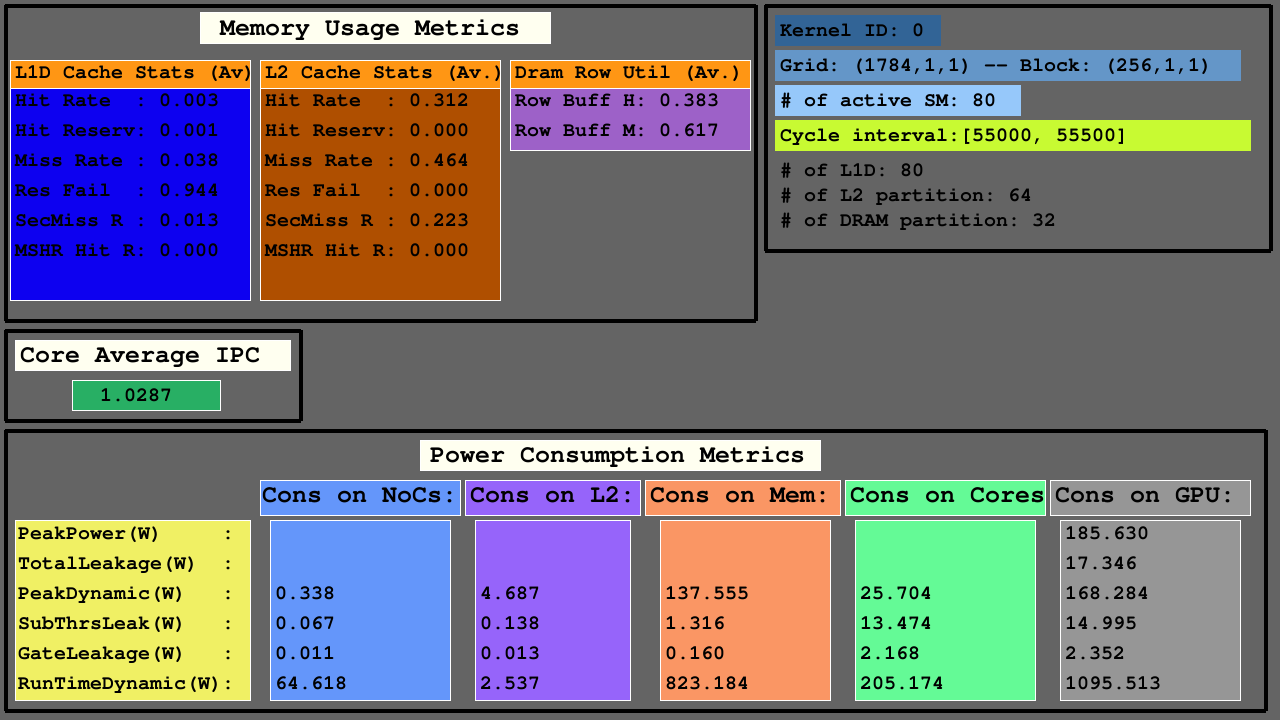
Visualisasi ketiga menunjukkan statistik akses L1D, L2 cache, dan DRAM pada metrik penggunaan memori, IPC rata-rata di antara SMS aktif dan metrik konsumsi daya NOC, partisi memori cache L2 dan MC+DRAM, dan SMS.
Selain opsi visualisasi runtime di atas, kami menyediakan opsi tampilan untuk rata -rata statistik akses memori runtime dan disipasi daya IPC vs di antara unit -unit di bawah ini. 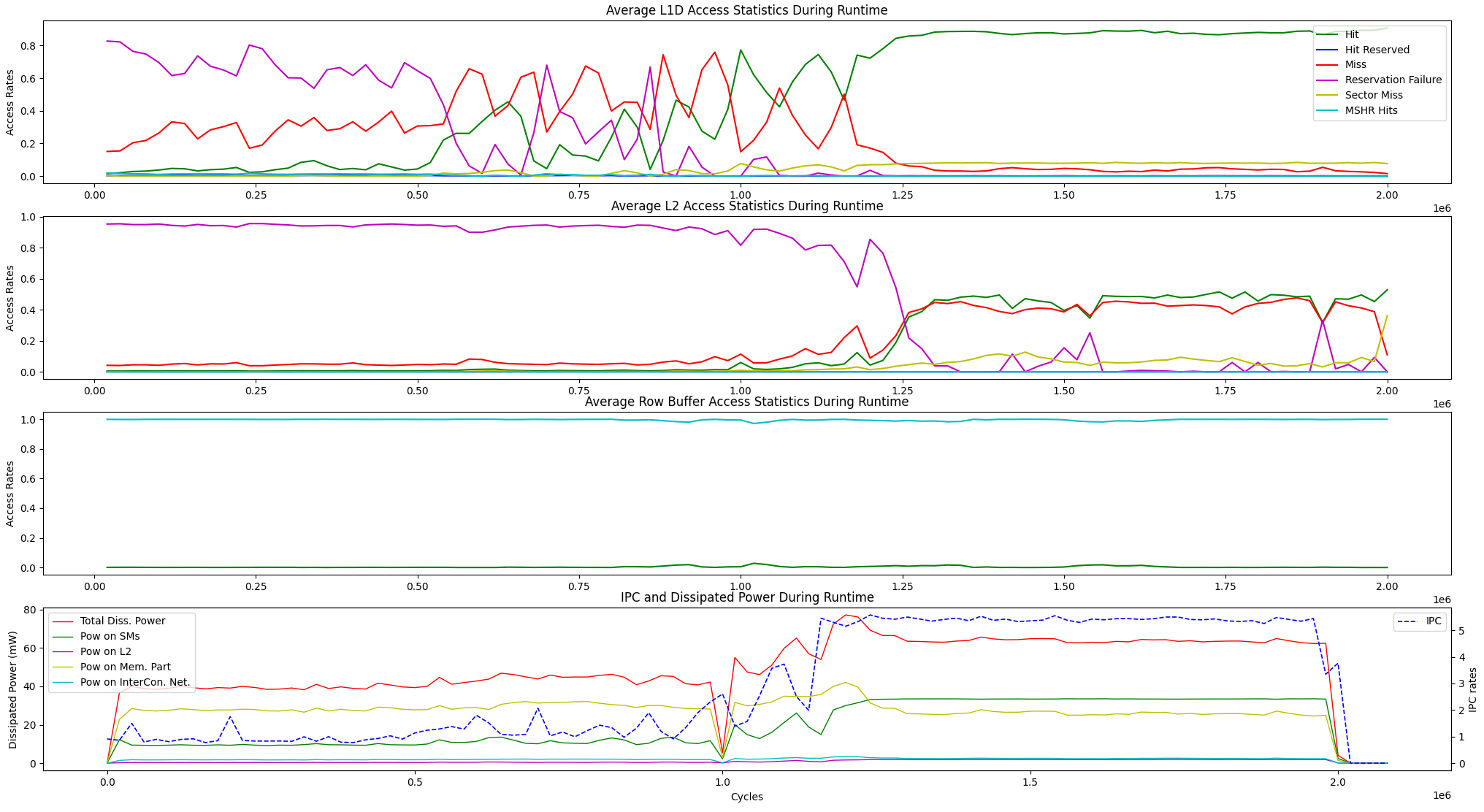
user@GPPRMon/runtime_visualizer:~ $ python3 average_disp.py param1 param2 param3 param4Kami telah bereksperimen dengan algoritma peringkat halaman (PR) pada GV100 dan RTX2060S. Juga, kami telah mengkonfigurasi GPU Jetson Agx Xavier dan Xavier NX GPU dan bereksperimen dengan mereka dengan algoritma FORM Fourier Transform. Profil eksperimental dan menampilkan hasil terlalu besar untuk diunggah di sini. Namun, kami memegangnya di server lokal kami. Jika Anda mau, kami dapat mengirimkan hasil itu. Jangan ragu untuk menghubungi kami untuk bantuan dan hasil apa pun.


