GPPRMon
1.0.0
Подробная документация по GPGPU-SIM, какие существуют модели и архитектуры графических процессоров, как его настроить, и здесь можно найти руководство к исходному коду. Кроме того, подробная документация по AccelWattch для сбора показателей энергопотребления для подкомпонентов и руководство по исходному коду можно найти здесь.
Зависимости GPGPU-SIM:
gcc, g++, make, makedepend, xutils, bison, flex, zlib, CUDA Toolkit
(Необязательно) Зависимости от документации GPGPU-SIM:doxygen, graphvi
(Необязательно) Зависимости AerialVision:python-pmw, python-ply, python-numpy, libpng12-dev, python-matplotlib
Зависимости CUDA SDK:libxi-dev, libxmu-dev, libglut3-dev
После установки обязательных библиотек для правильного запуска симулятора клонируйте реализацию Accelwattch Simulator (GPGPU-SIM 4.2). Затем вы должны следовать приведенным ниже командам внутри каталога симулятора, чтобы построить симулятор.
user@GPPRMon:~ $ source setup_environment < build_type >
# That command sets the environment variables so that the simulator can find related executables in the linkage path.
# If you want to debug the simulator (as written in C/C++), you should specify build_type as ` debug ` .
# Otherwise, you do not need to specify it ; blank as empty. It will automatically build the executables with ` release ` version. user@GPPRMon:~ $ make # To compile source files, create and link the executable files of the simulator.
user@GPPRMon:~ $ make clean # To clean the simulator executablesБолее того, если вы хотите генерировать файлы документации, зависимости которых указаны как необязательные, вы должны сначала установить зависимости. После этого вы можете получить документы с
user@GPPRMon:~ $ make docs # Generates doxygen files describing simulator elements
user@GPPRMon:~ $ make cleandocs # Deletes pre-generated doxygen files if they exist.Сгенерированная документация с доксигеном облегчает понимание классов, шаблонов, функций и т. Д. Для симулятора.
Во время симуляции симулятор создает информацию о доступе к памяти в приведенном ниже пути.
user@GPPRMon/runtime_profiling_metrics/memory_accesses:~ $ Чтобы включить сбор метрики доступа к памяти, необходимо указать приведенные ниже флаги в файле gpgpusim.config .
| Флаги | Описания | Значение по умолчанию |
|---|---|---|
| -mem_profiler | Включение сбора метрик доступа к памяти | 0 = выключен |
| -mem_runtime_stat | Определение частоты выборки для сбора метрики | 100 (запись после каждых 100 циклов GPU) |
| -Ipc_per_prof_interval | Запись ставок МПК для каждой выборки сбора метрики | 0 = не собирайте |
| -instruction_monitor | Запись/завершение статистики инструкций | 0 = не собирайте |
| -L1d_metrics | Метрики записи для кеша L1D | 0 = не собирайте |
| -L2_metrics | Запись метрик для доступа к кешу L2 | 0 = не собирайте |
| -Dram_metrics | Метрики записи для доступа к DRAM | 0 = не собирайте |
| -store_enable | Метрики записи для инструкций по магазинам и загрузке | 0 = просто записать метрики для загрузки |
| -АККУМУЛАТ_СТАТЫ | Накопление собранных метрик | 0 = не накапливаться |
Во время симуляции симулятор записывает метрики энергопотребления в приведенном ниже пути.
user@GPPRMon/runtime_profiling_metrics/energy_consumption:~ $Симулятор создаст отдельные папки и показатели профилирования мощности для каждого ядра во время выполнения. На данный момент приведенные ниже показатели энергопотребления поддерживаются, но эти показатели могут быть улучшены для самостоятельного изучения подразделений.
Графический процессор
Основной
Единица выполнения (регистрация FU, планировщики, функциональные единицы и т. Д.)
Блок запаса загрузки (перекладка, общая память, общий буфер MEM MISS/FILN, кэш, буфер с предварительным перефеткой кеша, буфер записи кеша, буфер с кешем и т. Д.)
Функциональный блок инструкции (кеш инструкции, целевой буфер ветвления, декодер, предиктор ветви и т. Д.)Сеть на чипе
Кэш L2
DRAM + контроллер памятиFrontend Engine
Phy между контроллером памяти и DRAM
Двигатель транзакций (бэкэнд -двигатель)
Драм
| Флаги | Описания | Значение по умолчанию |
|---|---|---|
| -power_simulation_enabled | Включение сбора показателей энергопотребления | 0 = выключен |
| -gpgpu_runtime_stat | Определение частоты отбора проб с точки зрения цикла GPU | 1000 циклов |
| -power_per_cycle_dump | Сбрасывание подробной выходной мощности в каждом образце | 0 = выключен |
| -dvfs_enabled | Включение/выключение динамического масштабирования частоты напряжения для модели мощности | 0 = не включено |
| -aggregate_power_stats | Запись/завершение статистики инструкций | 0 = не агрегируйте |
| -steady_power_levels_enabled | Создание файла для устойчивых уровней мощности | 0 = выключен |
| -steady_state_definition | разрешенное отклонение: количество образцов | 8: 4 |
| -power_trace_enabled | Создание файла для трассы питания | 0 = выключен |
| -power_trace_zlevel | Уровень сжатия вывода | 6, (0 = нет COMP, 9 = самый высокий) |
| -power_simulation_mode | Вход счетчика производительности переключения для моделирования питания | 0, (0 = sim, 1 = hw, 2 = гибрид HW-Sim) |
Наш инструмент визуализатора принимает файлы .csv, полученные с помощью моделирования времени выполнения ядра графического процессора, и генерирует три различные схемы визуализации. В настоящее время симулятор поддерживает GTX480_FERMI, QV100_VOLTA, RTX2060S_TURING, RTX2060_TURING, RTX3070_AMPERE, TITAN_KEPLER, TITANV_VOLTA, TITANX_PASCAL gpus в настоящее время. Поскольку каждый графический процессор имеет свою иерархию памяти, я разработал различные схемы для каждой иерархии. Тем не менее, я разработал визуализации SM и GPU как та, что их конструкции применимы для каждого графического процессора.
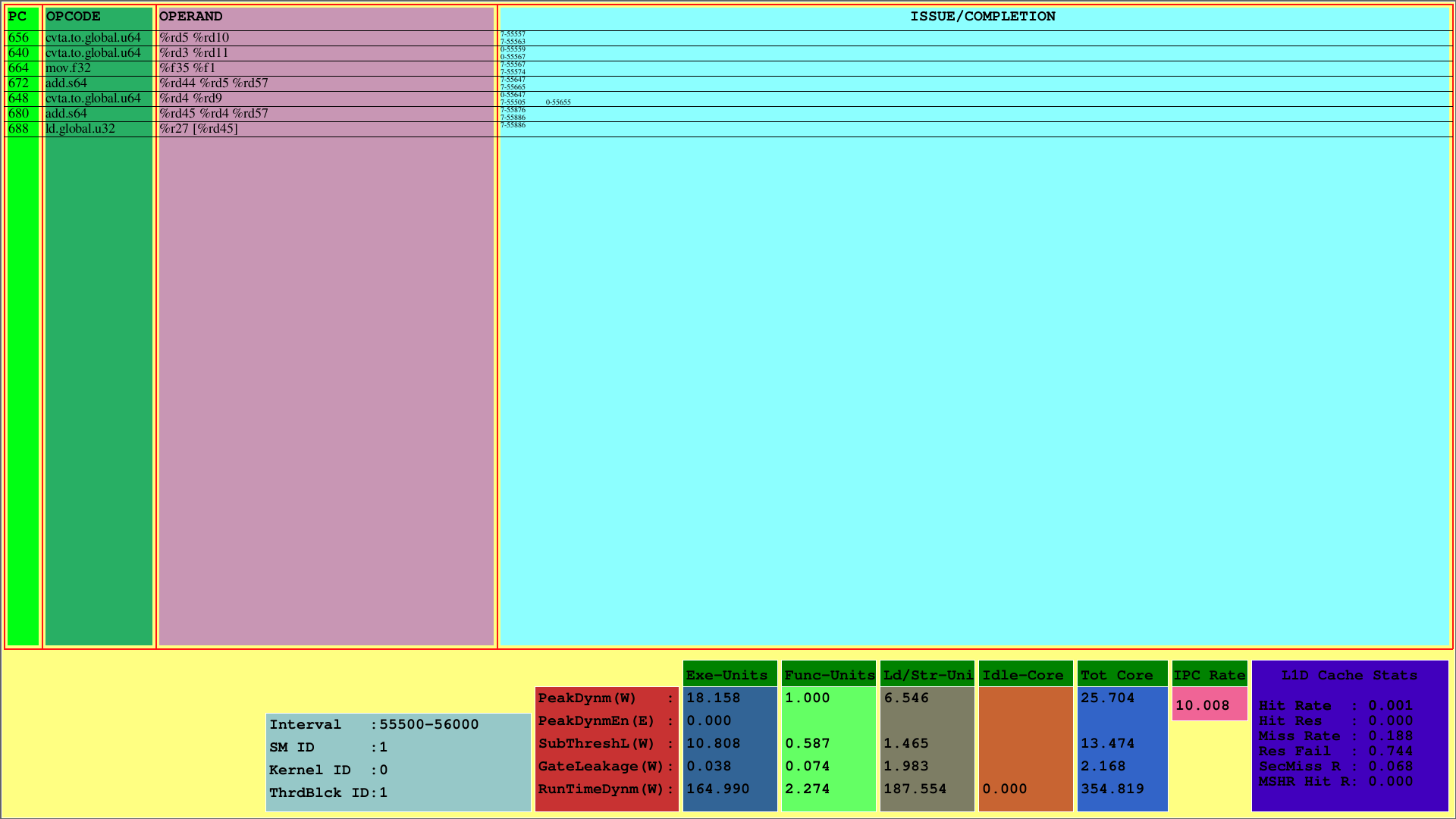
Первая визуализация отображает инструкции для 1 -й CTA, которая отображается на 1 -й SM. В то время как ПК показывает ПК инструкции, OPCODE показывает рабочие коды инструкций 1 -го блока потока. Операнды показывают идентификаторы реестра для соответствующего оптового кода инструкций.
В самом правом столбце (выпуск/завершение) визуализатор отображает информацию о выпуске и завершении инструкций для каждой основы в первой строке и второй строке соответственно. Например, первая инструкция - cvta.to.global.u64, ПК которого составляет 656, выпускается в 55577 -м цикле 7 -й деформацией и завершено в цикле 55563.
Эта схема показывает выпущенные и завершенные инструкции CTA в рамках интервала заданного цикла. Для приведенного выше примера этот интервал - это [55500, 56000).
Кроме того, можно увидеть использование кэша L1D и использование измерений мощности выполнения для подкомпонентов SMS. Параметр runtimedynm представляет общую потребляемую мощность для каждого раздела. Выполнение, функциональные и загрузки/хранилища, а также холостое ядро являются основными подразделениями энергопотребления SM. Кроме того, IPC на SM отображается внизу.

Вторая визуализация показывает доступ на кэшах L1D, L2 (как hits, hit_reserved_status, misses, reservation_failures, sector_misses, and mshr_hits ) и разбиения DRAM (как row buffer hits and row buffer misses ) в рамках интервала симулятора. Для кэши, описания доступа следующие:
Для DRAM описания доступа следующие:
Графические процессоры в основном состоят из SMS, которые включают функциональные единицы, файлы регистра и кэши, NOCS и разделы памяти, в которых существуют банки DRAM и кэши L2. Для настроенных архитектур количество CACHE L1D равно SMS (кластеры CORE CORE), количество банков DRAM равно количеству разделов памяти, а количество клеток L2 равно вдвое больше разделов памяти.
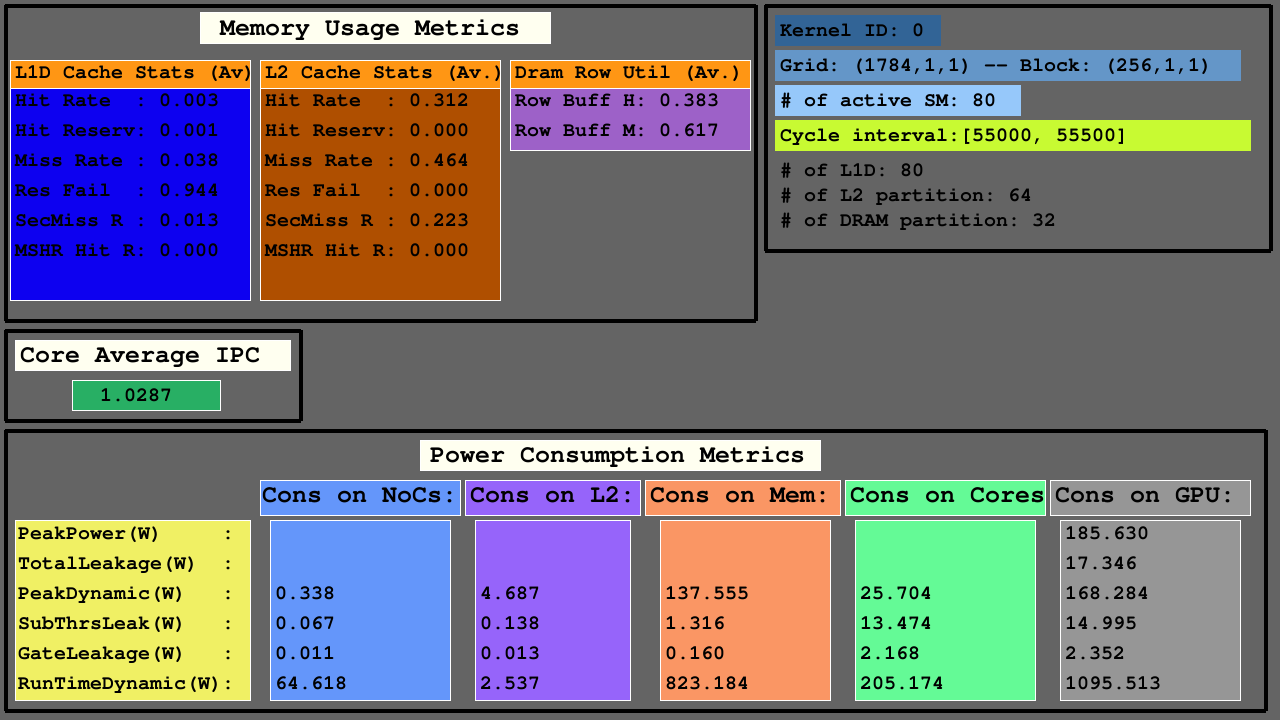
Третья визуализация показывает средневзвешенную L1D, кэш L2 и статистику доступа DRAM в показателях использования памяти, среднем IPC среди активных SMS и показателей энергопотребления NOCS, разделов памяти кэша L2 и MC+DRAM и SMS.
В дополнение к приведенным выше параметрам визуализации времени выполнения, мы предоставляем опцию отображения для средней статистики доступа к памяти введи и МПК против рассеивания мощности среди подразделений ниже. 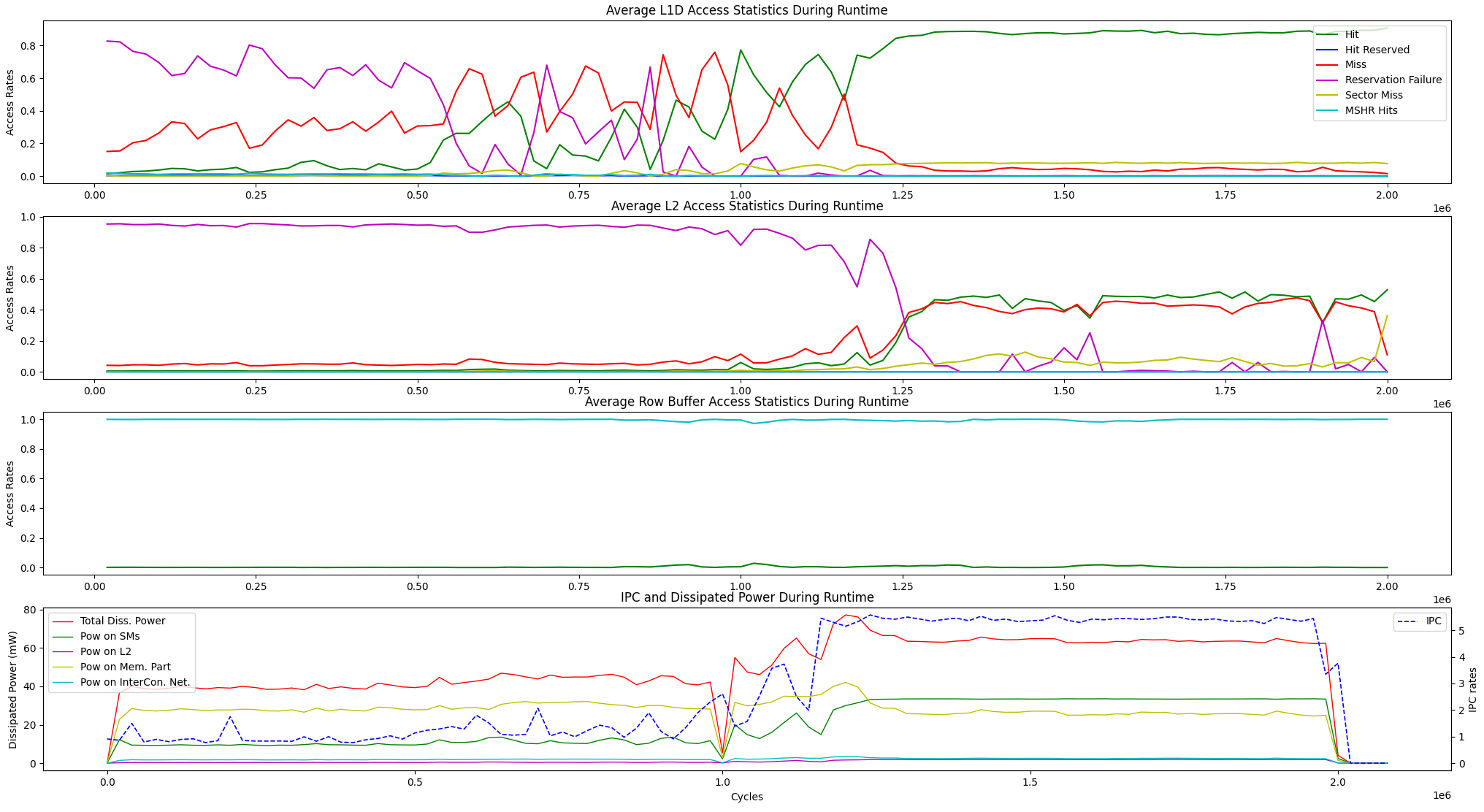
user@GPPRMon/runtime_visualizer:~ $ python3 average_disp.py param1 param2 param3 param4Мы экспериментировали с алгоритмом ранжирования страницы (PR) на GV100 и RTX2060S. Кроме того, мы настроили GPU GPU Jetson Agx Xavier и Xavier NX GPU и экспериментировали на них с помощью алгоритма быстрого преобразования Фурье. Экспериментальное профилирование и отображение результатов слишком велики, чтобы загрузить здесь. Тем не менее, мы держим их на наших местных серверах. Если хотите, мы можем отправить эти результаты. Не стесняйтесь обращаться к нам за любыми помощью и результатами.


