GPPRMon
1.0.0
Documentação detalhada sobre GPGPU-SIM, o que existem modelos e arquiteturas de GPU, como configurá-lo e um guia para o código-fonte pode ser encontrado aqui. Além disso, documentação detalhada sobre Accelwattch para coletar métricas de consumo de energia para subcomponentes e um guia para o código -fonte pode ser encontrado aqui.
GPGPU-SIM Dependências:
gcc, g++, make, makedepend, xutils, bison, flex, zlib, CUDA Toolkit
(Opcional) GPGPU-SIM Dependências de documentação:doxygen, graphvi
(Opcional) Dependências Aerialvision:python-pmw, python-ply, python-numpy, libpng12-dev, python-matplotlib
Dependências CUDA SDK:libxi-dev, libxmu-dev, libglut3-dev
Depois de instalar bibliotecas de pré-requisito para executar o simulador corretamente, clone a implementação do Accelwattch do simulador (GPGPU-SIM 4.2). Em seguida, você deve seguir os comandos abaixo dentro do diretório do simulador para criar o simulador.
user@GPPRMon:~ $ source setup_environment < build_type >
# That command sets the environment variables so that the simulator can find related executables in the linkage path.
# If you want to debug the simulator (as written in C/C++), you should specify build_type as ` debug ` .
# Otherwise, you do not need to specify it ; blank as empty. It will automatically build the executables with ` release ` version. user@GPPRMon:~ $ make # To compile source files, create and link the executable files of the simulator.
user@GPPRMon:~ $ make clean # To clean the simulator executablesAlém disso, se você deseja gerar arquivos de documentação cujas dependências são especificadas como opcionais, você deve primeiro instalar as dependências. Depois, você pode obter os documentos com
user@GPPRMon:~ $ make docs # Generates doxygen files describing simulator elements
user@GPPRMon:~ $ make cleandocs # Deletes pre-generated doxygen files if they exist.A documentação gerada com doxygen facilita o entendimento de classes, modelos, funções etc. para o simulador.
Durante a simulação, o simulador cria informações de acesso à memória no caminho abaixo.
user@GPPRMon/runtime_profiling_metrics/memory_accesses:~ $ Para ativar a coleção de métricas de acesso à memória, é preciso especificar os sinalizadores abaixo no arquivo gpgpusim.config .
| Bandeiras | Descrições | Valor padrão |
|---|---|---|
| -mem_profiler | Permitindo a coleta de métricas de acesso à memória | 0 = OFF |
| -mem_runtime_stat | Determinando a frequência de amostragem para a coleção métrica | 100 (recorde após cada 100 ciclos de GPU) |
| -Ipc_per_prof_interval | Gravando taxas de IPC para cada amostra de coleta métrica | 0 = Não colete |
| -Instruction_monitor | Gravação em questão/conclusão estatísticas das instruções | 0 = Não colete |
| -L1d_metrics | Métricas de gravação para acessos de cache L1D | 0 = Não colete |
| -L2_metrics | Recordingingollecting Métricas para acessos de cache L2 | 0 = Não colete |
| -Dram_metrics | Métricas de gravação para acesso à DRAM | 0 = Não colete |
| -store_enable | Registrando métricas para instruções de loja e de carga | 0 = Basta registrar métricas para carga |
| -accumulate_stats | Acumulação de métricas coletadas | 0 = não acumule |
Durante a simulação, o simulador registra métricas de consumo de energia no caminho abaixo.
user@GPPRMon/runtime_profiling_metrics/energy_consumption:~ $O simulador criará pastas separadas e métricas de perfil de energia para cada kernel em tempo de execução. Por enquanto, as métricas de consumo de energia abaixo são suportadas, mas essas métricas podem ser aprimoradas ainda mais para investigar as subunidades de forma independente.
GPU
Essencial
Unidade de execução (registro FU, agendadores, unidades funcionais, etc.)
Carregar unidade de armazenamento (barra cruzada, memória compartilhada, buffer de miss/preenchimento compartilhado, buffer de cache, buffer de pré -busca de cache, buffer de writeback de cache, buffer de cache Miss Miss, etc.)
Instrução Unidade funcional (cache de instrução, buffer de destino da filial, decodificador, preditor de filial etc.)Rede no chip
L2 Cache
DRAM + Memory ControllerMotor front -end
Phy entre controlador de memória e DRAM
Motor de transação (motor de back -end)
Dram
| Bandeiras | Descrições | Valor padrão |
|---|---|---|
| --power_simulation_enabled | Ativando as métricas de consumo de energia de coleta | 0 = OFF |
| -gpgpu_runtime_stat | Determinando a frequência de amostragem em termos de ciclo de GPU | 1000 ciclos |
| --power_per_cycle_dump | Dumping de potência detalhada em cada amostra | 0 = OFF |
| -dvfs_enabled | Ativar/desligar/desligar a escala de frequência de tensão dinâmica para modelo de energia | 0 = não habilitado |
| -Aggregate_power_stats | Gravação em questão/conclusão estatísticas das instruções | 0 = Não agregue |
| -steady_power_levels_enabled | Produzindo um arquivo para os níveis constantes de energia | 0 = OFF |
| -steady_state_definition | Desvio permitido: número de amostras | 8: 4 |
| --power_trace_enabled | Produzindo um arquivo para o Power Trace | 0 = OFF |
| --power_trace_zlevel | Nível de compressão do log de saída de rastreamento de potência | 6, (0 = sem comp, 9 = mais alto) |
| --power_simulation_mode | Switch Deformat Counter Entrada para simulação de energia | 0, (0 = sim, 1 = hw, 2 = hw-sim híbrido) |
Nossa ferramenta de visualizador pega arquivos .csv obtidos via simulação de tempo de execução de um kernel GPU e gera três esquemas de visualização diferentes. Atualmente, o simulador suporta GTX480_FERMI, QV100_VOLTA, RTX2060S_TURING, RTX2060_TURING, RTX3070_AMPERE, TITAN_KEPLER, TITANV_VOLTA, TITANX_PASCAL GPUS Atualmente. Como cada GPU tem uma hierarquia de memória diferente, projetei esquemas variados para cada hierarquia. No entanto, eu projetei visualizações de SM e GPU como uma, de modo que seus projetos sejam aplicáveis a cada GPU.
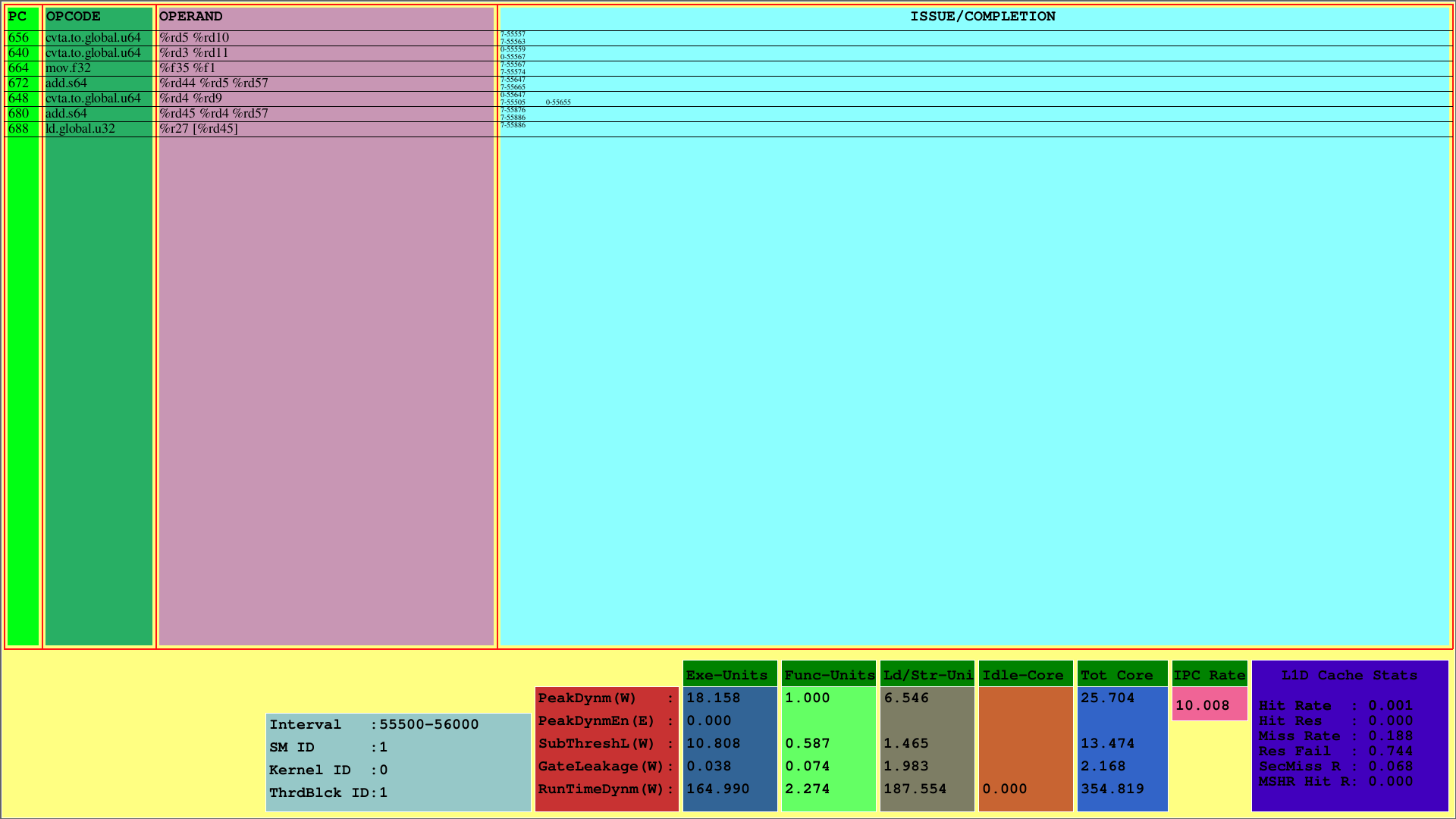
A primeira visualização exibe as instruções para o 1º CTA, que é mapeado no 1º SM. Enquanto o PC mostra o PC da instrução, o OpCode mostra os códigos operacionais das instruções do 1º bloco de threads. Os operando mostram os IDs de registro para o código opcil correspondente das instruções.
Na coluna mais à direita (edição/conclusão), o visualizador exibe as informações de emissão e conclusão das instruções para cada urdidura na primeira linha e segunda linha, respectivamente. Por exemplo, a primeira instrução é CVTA.TO.GLOBAL.U64, cujo PC é 656, é emitido no 55557º ciclo pelo 7º Warp e concluído no ciclo 55563.
Esse esquema mostra as instruções emitidas e concluídas de um CTA dentro de um intervalo de ciclo predeterminado. Para o exemplo acima, esse intervalo é o [55500, 56000).
Além disso, pode -se ver o uso do cache L1D e as medições de potência de tempo de execução para os subcomponentes do SMS. O parâmetro runtimedynm representa o total de energia consumido para cada seção. Execução, unidades funcionais e de carga/armazenamento, e o núcleo inativo são as principais sub-partes do consumo de energia de um SM. Além disso, o IPC por SM é exibido na parte inferior.

A segunda visualização mostra os acessos em caches L1D, L2 (como hits, hit_reserved_status, misses, reservation_failures, sector_misses, and mshr_hits ) e partições de DRAM (como row buffer hits and row buffer misses ) dentro do intervalo do simulador. Para caches, as descrições de acesso são as seguintes:
Para DRAM, as descrições de acesso são as seguintes:
As GPUs consistem principalmente em SMS, que incluem unidades funcionais, arquivos e caches de registro, NOCs e partições de memória nas quais existem bancos de DRAM e caches L2. Para as arquiteturas configuradas, o número de caches L1D é igual a SMS (clusters do núcleo SIMT), o número de bancos de DRAM é igual ao número de partições de memória e o número de caches L2 é igual a duas vezes o número de partições de memória.
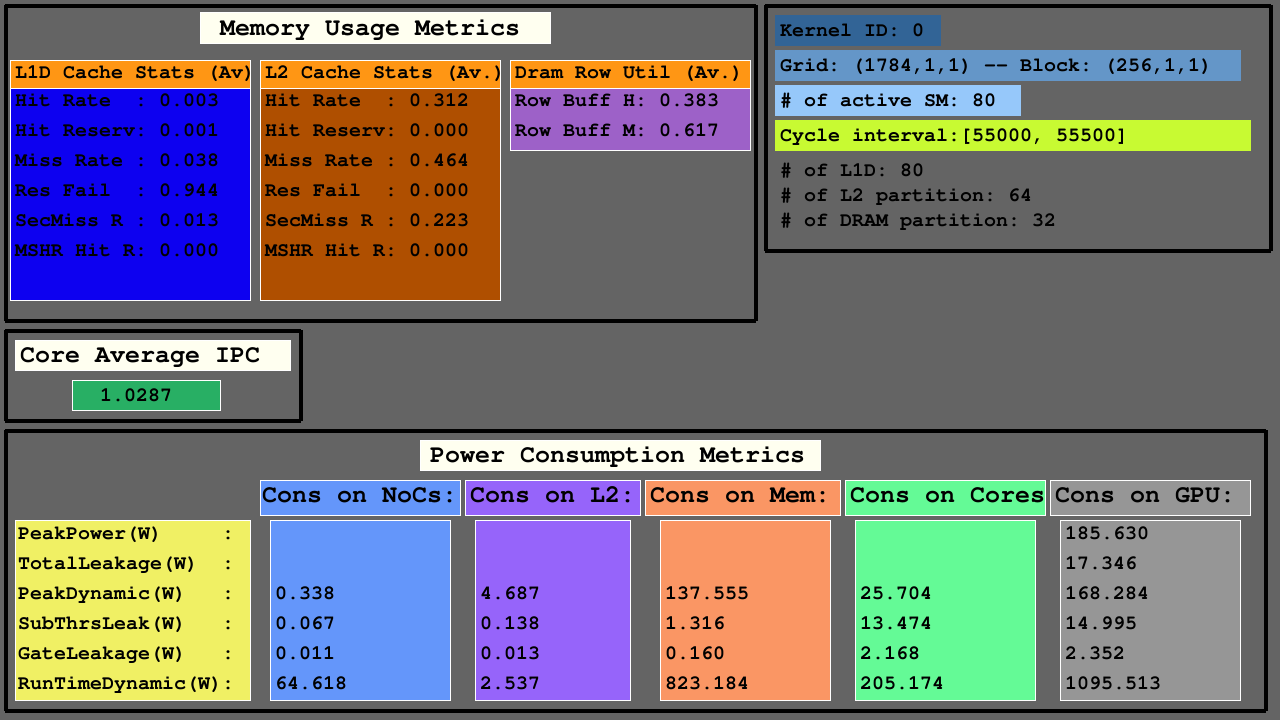
A terceira visualização mostra as estatísticas de cache L1D, L2 e DRAM de acesso às métricas de uso de memória, IPC médio entre métricas de SMS ativo e consumo de energia de NOCs, partições de memória de caches L2 e MC+DRAM e SMS.
Além das opções de visualização de tempo de execução acima, fornecemos uma opção de exibição para as estatísticas médias de acesso à memória de tempo de execução e a dissipação de IPC vs de energia entre as unidades abaixo. 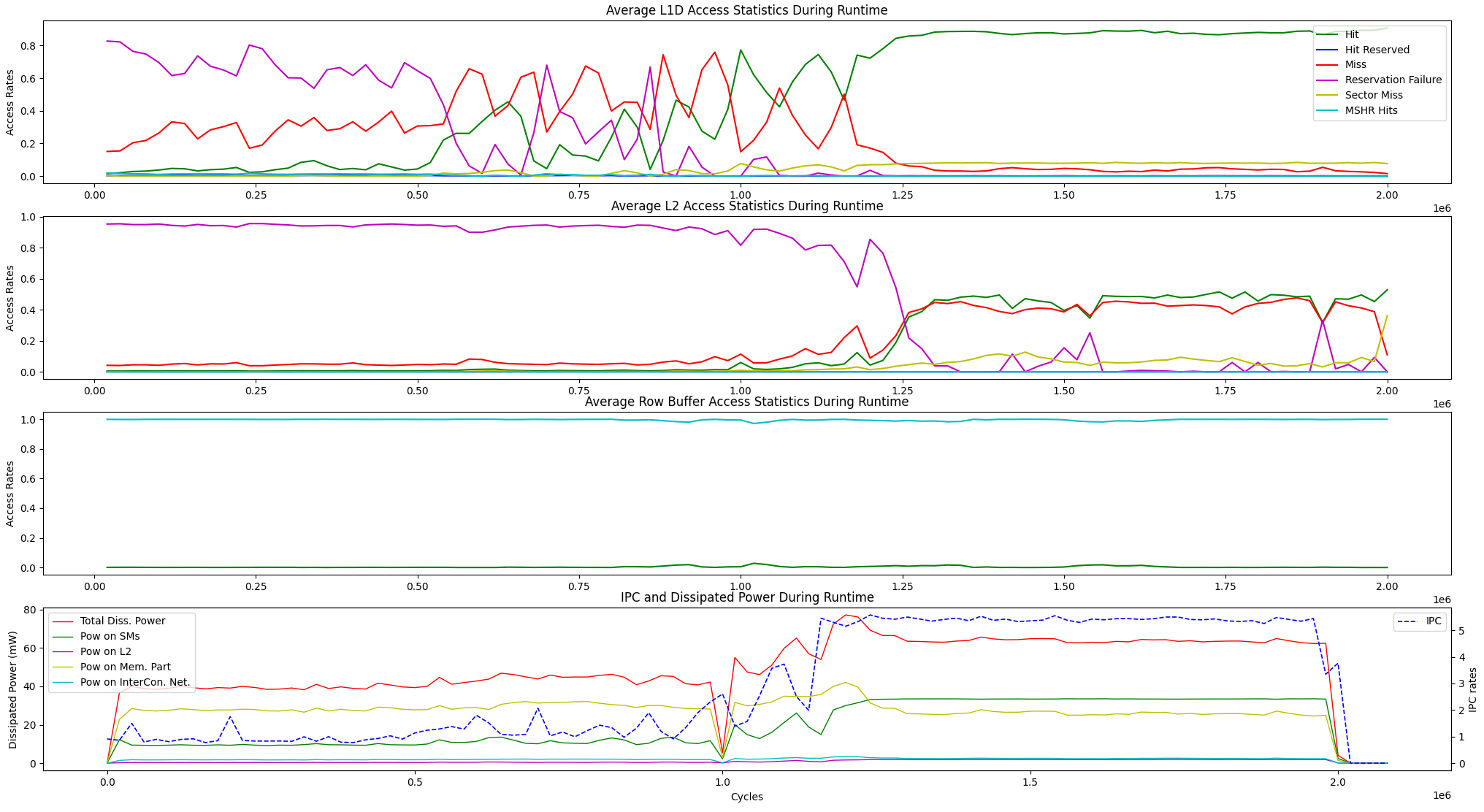
user@GPPRMon/runtime_visualizer:~ $ python3 average_disp.py param1 param2 param3 param4Experimentamos o algoritmo de classificação da página (PR) no GV100 e RTX2060S. Além disso, configuramos a GPU de Jetson Agx Xavier e Xavier NX GPUs e experimentamos o algoritmo de transformação de Fourier Fast Fourier. O perfil experimental e a exibição dos resultados são muito grandes para fazer upload aqui. No entanto, nós os mantemos em nossos servidores locais. Se você quiser, podemos enviar esses resultados. Não hesite em entrar em contato conosco para obter ajuda e resultados.


