GPPRMon
1.0.0
وثائق مفصلة حول GPGPU-SIM ، ما هي نماذج GPU والبنية الموجودة ، وكيفية تكوينها ، ويمكن العثور على دليل للرمز المصدري هنا. وأيضًا ، يمكن العثور هنا على وثائق مفصلة حول Accelwattch لجمع مقاييس استهلاك الطاقة للأفراد الفرعيين ودليلًا للرمز المصدري.
تبعيات GPGPU-SIM:
gcc, g++, make, makedepend, xutils, bison, flex, zlib, CUDA Toolkit
(اختياري) تبعيات توثيق GPGPU-SIM:doxygen, graphvi
(اختياري) التبعيات AerialVision:python-pmw, python-ply, python-numpy, libpng12-dev, python-matplotlib
تبعيات CUDA SDK:libxi-dev, libxmu-dev, libglut3-dev
بعد تثبيت المكتبات المتطلب السابق لتشغيل المحاكاة بشكل صحيح ، استنساخ تطبيق accelwattch للمحاكاة (GPGPU-SIM 4.2). بعد ذلك ، يجب عليك اتباع الأوامر أدناه داخل دليل المحاكاة لإنشاء جهاز محاكاة.
user@GPPRMon:~ $ source setup_environment < build_type >
# That command sets the environment variables so that the simulator can find related executables in the linkage path.
# If you want to debug the simulator (as written in C/C++), you should specify build_type as ` debug ` .
# Otherwise, you do not need to specify it ; blank as empty. It will automatically build the executables with ` release ` version. user@GPPRMon:~ $ make # To compile source files, create and link the executable files of the simulator.
user@GPPRMon:~ $ make clean # To clean the simulator executablesعلاوة على ذلك ، إذا كنت ترغب في إنشاء ملفات توثيق يتم تحديد تبعياتها على أنها اختيارية ، فيجب عليك أولاً تثبيت التبعيات. بعد ذلك ، يمكنك الحصول على المستندات مع
user@GPPRMon:~ $ make docs # Generates doxygen files describing simulator elements
user@GPPRMon:~ $ make cleandocs # Deletes pre-generated doxygen files if they exist.إن الوثائق التي تم إنشاؤها مع Doxygen تخفف من فهم الفصول والقوالب والوظائف ، وما إلى ذلك ، للمحاكاة.
أثناء المحاكاة ، يقوم جهاز المحاكاة بإنشاء معلومات الوصول إلى الذاكرة في المسار أدناه.
user@GPPRMon/runtime_profiling_metrics/memory_accesses:~ $ لتمكين مجموعة متري الوصول إلى الذاكرة ، يجب على المرء تحديد الأعلام أدناه في ملف gpgpusim.config .
| أعلام | الأوصاف | القيمة الافتراضية |
|---|---|---|
| -mem_profiler | تمكين جمع مقاييس الوصول إلى الذاكرة | 0 = قبالة |
| -MEM_RUNTIME_STAT | تحديد تردد أخذ العينات للمجموعة المتري | 100 (سجل بعد كل 100 دورة GPU) |
| -IPC_PER_PROF_INTERVAL | تسجيل معدلات IPC لكل عينة جمع متري | 0 = لا تجمع |
| -instruction_monitor | تسجيل الإحصائيات/إكمال الإكمال | 0 = لا تجمع |
| -l1d_metrics | تسجيل مقاييس للوصول إلى ذاكرة التخزين المؤقت L1D | 0 = لا تجمع |
| -l2_metrics | مقاييس التسجيل للوصول إلى ذاكرة التخزين المؤقت L2 | 0 = لا تجمع |
| -dram_metrics | تسجيل المقاييس للوصول إلى DRAM | 0 = لا تجمع |
| -store_enable | تسجيل المقاييس لكل من تعليمات المتجر والتحميل | 0 = مجرد تسجيل مقاييس للتحميل |
| -accumulate_stats | تراكم المقاييس جمعت | 0 = لا تتراكم |
أثناء المحاكاة ، يسجل محاكاة مقاييس استهلاك الطاقة في المسار أدناه.
user@GPPRMon/runtime_profiling_metrics/energy_consumption:~ $سيقوم جهاز المحاكاة بإنشاء مجلدات منفصلة ومقاييس توصيف الطاقة لكل نواة في وقت التشغيل. في الوقت الحالي ، يتم دعم مقاييس استهلاك الطاقة أدناه ، ولكن قد يتم تعزيز هذه المقاييس بشكل أكبر للتحقيق في الوحدات الفرعية بشكل مستقل.
GPU
جوهر
وحدة التنفيذ (سجل فو ، جدولين ، وحدات وظيفية ، وما إلى ذلك)
تحميل وحدة متجر (العارضة ، الذاكرة المشتركة ، MEM MISS/FILL المشتركة ، ذاكرة التخزين المؤقت ، ذاكرة التخزين المؤقت المخزن المؤقت ، المخزن المؤقت للكتابة ذاكرة التخزين المؤقت ، ذاكرة التخزين المؤقتة ذاكرة التخزين المؤقت ، إلخ) وما إلى ذلك)
الوحدة الوظيفية للتعليمات (تعليمات التخزين المؤقت ، المخزن المؤقت المستهدف الفرع ، وحدة فك ترميز ، تنبؤ الفرع ، إلخ)شبكة على رقاقة
ذاكرة التخزين المؤقت L2
DRAM + وحدة تحكم الذاكرةمحرك الواجهة الأمامية
PHY بين وحدة تحكم الذاكرة والدراما
محرك المعاملات (محرك الواجهة الخلفية)
درهم
| أعلام | الأوصاف | القيمة الافتراضية |
|---|---|---|
| -power_simulation_enabled | تمكين جمع مقاييس استهلاك الطاقة | 0 = قبالة |
| -GPGPU_RUNTIME_STAT | تحديد تردد أخذ العينات من حيث دورة GPU | 1000 دورة |
| -power_per_cycle_dump | إلقاء إخراج طاقة مفصل في كل عينة | 0 = قبالة |
| -DVFS_ENABLED | تشغيل/إيقاف تشغيل تواتر الجهد الديناميكي لنموذج الطاقة | 0 = لم يتم تمكينه |
| -AGGREGATE_POWER_STATS | تسجيل الإحصائيات/إكمال الإكمال | 0 = لا تجمع |
| -steady_power_levels_enabled | إنتاج ملف لمستويات الطاقة الثابتة | 0 = قبالة |
| -steady_state_definition | الانحراف المسموح به: عدد العينات | 8: 4 |
| -power_trace_enabled | إنتاج ملف لتتبع الطاقة | 0 = قبالة |
| -power_trace_zlevel | مستوى ضغط سجل إخراج تتبع الطاقة | 6 ، (0 = لا شركات ، 9 = أعلى) |
| -power_simulation_mode | تبديل إدخال عداد الأداء لمحاكاة الطاقة | 0 ، (0 = SIM ، 1 = HW ، 2 = HW-SIM Hybrid) |
تأخذ أداة Visualizer الخاصة بنا. حاليًا ، يدعم Simulator GTX480_FERMI, QV100_VOLTA, RTX2060S_TURING, RTX2060_TURING, RTX3070_AMPERE, TITAN_KEPLER, TITANV_VOLTA, TITANX_PASCAL GPUS حاليًا. نظرًا لأن كل وحدة معالجة الرسومات لديها تسلسل هرمي ذاكرة مختلف ، فقد صممت مخططات مختلفة لكل تسلسل هرمي. ومع ذلك ، فقد صممت تصورات SM و GPU كأحد أن تصاميمها قابلة للتطبيق على كل وحدة معالجة الرسومات.
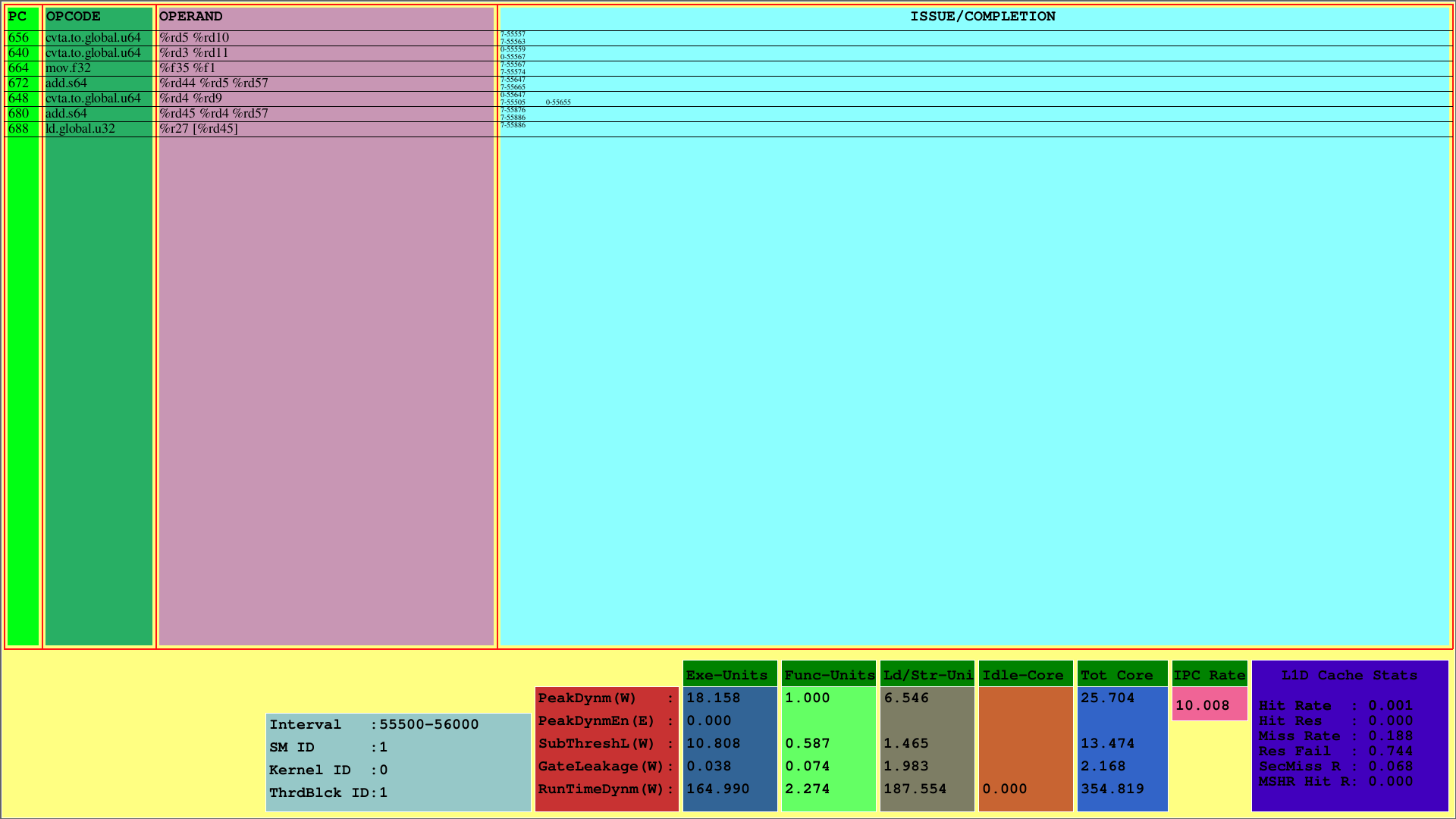
يعرض التصور الأول إرشادات CTA الأولى ، والتي يتم تعيينها على SM 1st. بينما يعرض الكمبيوتر الشخصي كمبيوتر التعليم ، يعرض الرمز OPCODE الرموز التشغيلية لتعليمات كتلة مؤشر الترابط الأولى. تعرض المعاملات معرفات التسجيل لرمز opcode المقابل للتعليمات.
في أقصى اليمين (العدد/الإكمال) ، يعرض المرئي معلومات إصدار وإكمال التعليمات الخاصة بكل WARP في الصف الأول والصف الثاني ، على التوالي. على سبيل المثال ، فإن التعليمات الأولى هي CVTA.TO.GLOBAL.U64 ، الذي يبلغ جهاز الكمبيوتر الخاص به 656 ، في الدورة 55557 من خلال الاعوجاج السابع ويتم الانتهاء منه في الدورة 55563.
يوضح هذا المخطط تعليمات صادرة من CTA وإكمالها ضمن فاصل دورة محدد مسبقًا. على سبيل المثال أعلاه ، هذا الفاصل هو [55500 ، 56000).
بالإضافة إلى ذلك ، قد يرى المرء استخدام ذاكرة التخزين المؤقت L1D وقياسات طاقة وقت التشغيل المستهلكة للرسائل الفرعية للرسائل القصيرة. تمثل معلمة RunTimedynm الطاقة الكلية المستهلكة لكل قسم. تعتبر وحدات التنفيذ ، وحدات التنفيذ والتحميل/المتجر ، والخمول الأجزاء الفرعية الرئيسية لاستهلاك طاقة SM. أيضا ، يتم عرض IPC لكل SM في الأسفل.

يوضح التصور الثاني الوصول إلى Caches L1D و L2 (مثل hits, hit_reserved_status, misses, reservation_failures, sector_misses, and mshr_hits ) وأقسام DRAM ( row buffer hits and row buffer misses ) ضمن فاصل Simulator. بالنسبة لذاكرة التخزين المؤقت ، فإن أوصاف الوصول هي كما يلي:
بالنسبة إلى DRAM ، فإن أوصاف الوصول هي كما يلي:
تتألف وحدات معالجة الرسومات المعالجة الرسمية بشكل أساسي من الرسائل القصيرة ، والتي تشمل الوحدات الوظيفية ، وتسجيل الملفات وذاكرة التخزين المؤقت ، و NOCs ، وأقسام الذاكرة التي توجد فيها بنوك DRAM وذاكرة التخزين المؤقت L2. بالنسبة للبنية التي تم تكوينها ، فإن عدد ذاكرة التخزين المؤقت L1D يساوي SMS (مجموعات SIMT الأساسية) ، ويساوي عدد بنوك DRAM عدد أقسام الذاكرة ، ويساوي عدد ذاكرة التخزين المؤقت L2 ضعف عدد أقسام الذاكرة.
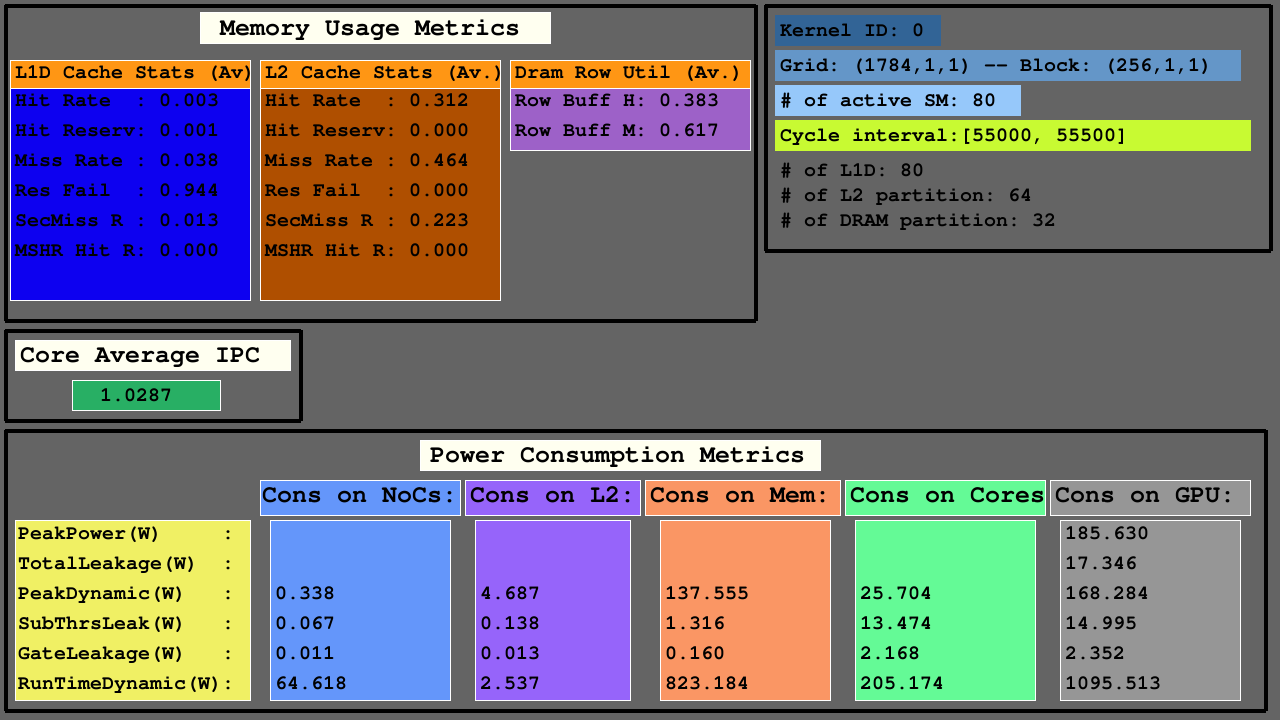
يوضح التصور الثالث إحصائيات L1D ، L2 ، وإحصائيات الوصول إلى DRAM في مقاييس استخدام الذاكرة ، ومتوسط IPC بين SMS النشط ومقاييس استهلاك الطاقة من NOCs ، وأقسام الذاكرة من Caches L2 و MC+DRAM ، و SMS.
بالإضافة إلى خيارات تصور وقت التشغيل أعلاه ، فإننا نقدم خيارًا عرضًا لإحصائيات الوصول إلى ذاكرة وقت التشغيل المتوسط وتبديد الطاقة بين الوحدات أدناه. 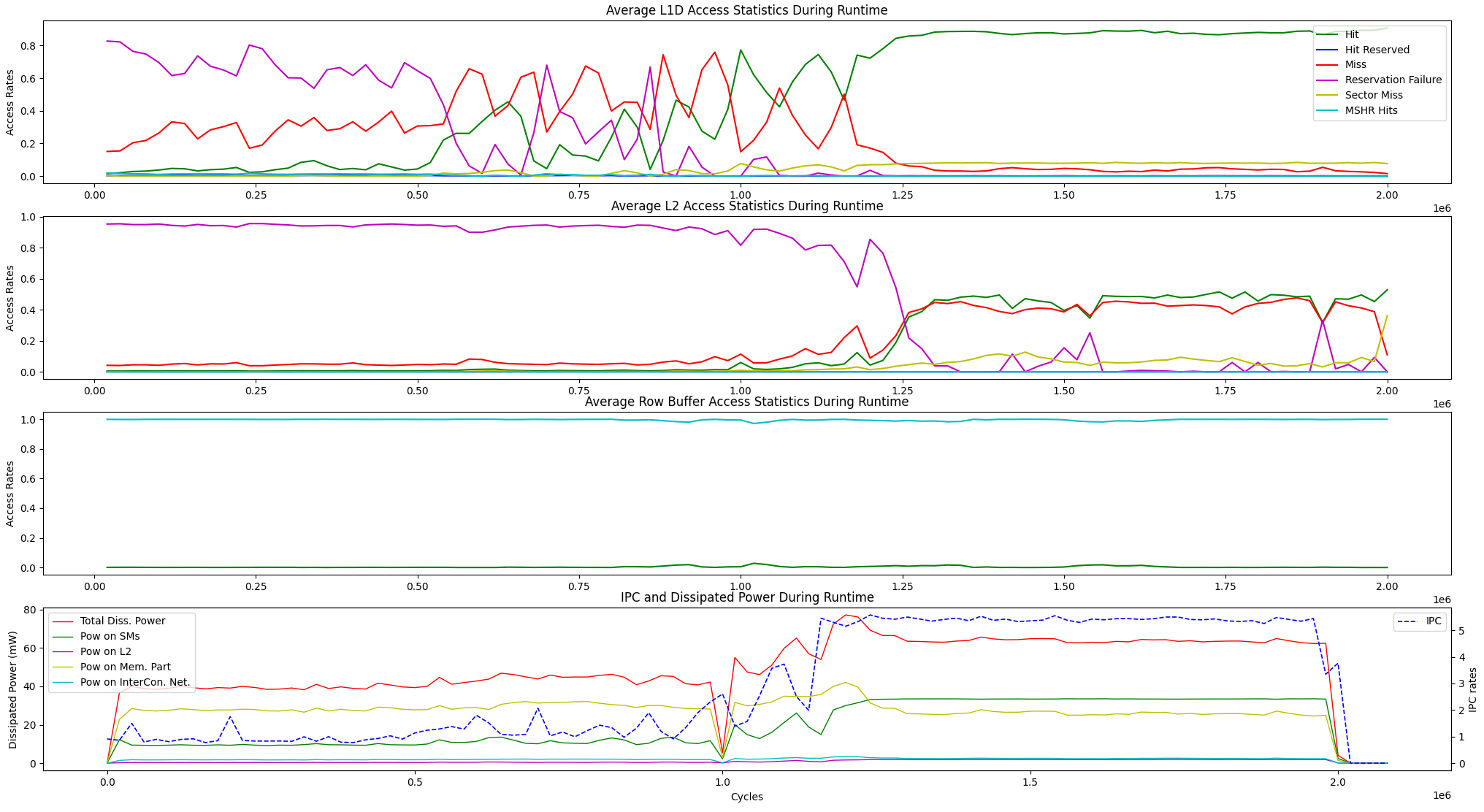
user@GPPRMon/runtime_visualizer:~ $ python3 average_disp.py param1 param2 param3 param4لقد جربنا خوارزمية تصنيف الصفحة (PR) على GV100 و RTX2060s. أيضًا ، قمنا بتكوين وحدة معالجة الرسومات في Jetson Agx Xavier و Xavier NX GPU وقمنا بتجربة خوارزمية تحويل فورييه السريعة. التوصيف التجريبي وعرض النتائج أكبر من أن يتم تحميلها هنا. ومع ذلك ، فإننا نحتفظ بهم على خوادمنا المحلية. إذا كنت تريد ، يمكننا إرسال هذه النتائج. لا تتردد في الاتصال بنا للحصول على أي مساعدة ونتائج.


