GPPRMon
1.0.0
Documentation détaillée sur GPGPU-SIM, quels modèles et architectures GPU existent, comment le configurer et un guide du code source peut être trouvé ici. En outre, une documentation détaillée sur AccelWattch pour collecter des mesures de consommation d'énergie pour les sous-composants et un guide du code source peut être trouvée ici.
Dépendances GPGPU-SIM:
gcc, g++, make, makedepend, xutils, bison, flex, zlib, CUDA Toolkit
(facultatif) Dépendances de documentation GPGPU-SIM:doxygen, graphvi
(Facultatif) Dépendances aériennes:python-pmw, python-ply, python-numpy, libpng12-dev, python-matplotlib
Dépendances CUDA SDK:libxi-dev, libxmu-dev, libglut3-dev
Après avoir installé des bibliothèques préalables pour exécuter correctement le simulateur, clonez la mise en œuvre accelwattch du simulateur (GPGPU-SIM 4.2). Ensuite, vous devez suivre les commandes ci-dessous à l'intérieur du répertoire du simulateur pour construire le simulateur.
user@GPPRMon:~ $ source setup_environment < build_type >
# That command sets the environment variables so that the simulator can find related executables in the linkage path.
# If you want to debug the simulator (as written in C/C++), you should specify build_type as ` debug ` .
# Otherwise, you do not need to specify it ; blank as empty. It will automatically build the executables with ` release ` version. user@GPPRMon:~ $ make # To compile source files, create and link the executable files of the simulator.
user@GPPRMon:~ $ make clean # To clean the simulator executablesDe plus, si vous souhaitez générer des fichiers de documentation dont les dépendances sont spécifiées comme facultatives, vous devez d'abord installer les dépendances. Ensuite, vous pouvez obtenir les documents avec
user@GPPRMon:~ $ make docs # Generates doxygen files describing simulator elements
user@GPPRMon:~ $ make cleandocs # Deletes pre-generated doxygen files if they exist.La documentation générée avec le doxygen facilite la compréhension des classes, des modèles, des fonctions, etc., pour le simulateur.
Pendant la simulation, le simulateur crée des informations d'accès à la mémoire dans le chemin ci-dessous.
user@GPPRMon/runtime_profiling_metrics/memory_accesses:~ $ Pour activer la collection métrique d'accès à la mémoire, il faut spécifier les indicateurs ci-dessous dans le fichier gpgpusim.config .
| Drapeaux | Descriptions | Valeur par défaut |
|---|---|---|
| -mem_profiler | Permettant la collecte de mesures d'accès à la mémoire | 0 = off |
| -mem_runtime_stat | Déterminer la fréquence d'échantillonnage pour la collection métrique | 100 (enregistrer après chaque 100 cycles GPU) |
| -Ipc_per_prof_interval | Enregistrement des taux d'IPC pour chaque échantillon de collecte métrique | 0 = Ne collectez pas |
| -instruction_monitor | Enregistrement des statistiques sur le problème / l'achèvement des instructions | 0 = Ne collectez pas |
| -L1d_metrics | Enregistrement des mesures pour les accès au cache L1D | 0 = Ne collectez pas |
| -L2_metrics | Enregistrement des métriques de collecte pour les accès au cache L2 | 0 = Ne collectez pas |
| -Dram_Metrics | Enregistrement des mesures pour les accès DRAM | 0 = Ne collectez pas |
| -store_enable | Enregistrement des mesures pour les instructions de magasin et de chargement | 0 = Enregistrez simplement les mesures pour le chargement |
| -Accumulate_stats | Accumuler des mesures collectées | 0 = ne pas accumuler |
Pendant la simulation, le simulateur enregistre les mesures de consommation d'énergie dans le chemin ci-dessous.
user@GPPRMon/runtime_profiling_metrics/energy_consumption:~ $Le simulateur créera des dossiers séparés et des mesures de profilage d'alimentation pour chaque noyau à l'exécution. Pour l'instant, les mesures de consommation d'énergie ci-dessous sont prises en charge, mais ces mesures peuvent être améliorées davantage pour étudier les sous-unités indépendamment.
GPU
Cœur
Unité d'exécution (enregistrez FU, planificateurs, unités fonctionnelles, etc.)
Unité de chargement de chargement (barre transversale, mémoire partagée, tampon MEM MEM / remplissage partagé, cache, tampon de préfetch de cache, tampon d'écriture de cache, tampon de miss de cache, etc.)
Unité fonctionnelle d'instruction (cache d'instruction, tampon cible de branche, décodeur, prédicteur de branche, etc.)Réseau sur la puce
Cache L2
Contrôleur de mémoire DRAM +Frontend moteur
Phy entre le contrôleur de mémoire et DRAM
Moteur de transaction (moteur backend)
DRACHME
| Drapeaux | Descriptions | Valeur par défaut |
|---|---|---|
| -Power_Simulation_enabled | Permettant la collecte de mesures de consommation d'énergie | 0 = off |
| -gpgpu_runtime_stat | Déterminer la fréquence d'échantillonnage en termes de cycle GPU | 1000 cycles |
| -Power_Per_Cycle_Dump | Dumping Sortie détaillée de sortie dans chaque échantillon | 0 = off |
| -dvfs_enabled | Activer / désactiver la mise à l'échelle de fréquence de tension dynamique pour le modèle d'alimentation | 0 = non activé |
| -aggregate_power_stats | Enregistrement des statistiques sur le problème / l'achèvement des instructions | 0 = Ne pas agréger |
| -Steady_Power_Levels_enabled | Produire un fichier pour les niveaux de puissance réguliers | 0 = off |
| -Steady_State_Definition | Déviation autorisée: nombre d'échantillons | 8: 4 |
| -Power_Trace_enabled | Produire un fichier pour la trace de puissance | 0 = off |
| -Power_Trace_zlevel | Niveau de compression du journal de sortie de trace de puissance | 6, (0 = pas de comp, 9 = le plus élevé) |
| -Power_Simulation_Mode | Switch Performance Counter Entrée pour la simulation d'alimentation | 0, (0 = sim, 1 = hw, 2 = hybride HW-Sim) |
Notre outil de visualiseur prend des fichiers .csv obtenus via la simulation d'exécution d'un noyau GPU et génère trois schémas de visualisation différents. Actuellement, le simulateur prend en charge GTX480_FERMI, QV100_VOLTA, RTX2060S_TURING, RTX2060_TURING, RTX3070_AMPERE, TITAN_KEPLER, TITANV_VOLTA, TITANX_PASCAL GPUS. Comme chaque GPU a une hiérarchie de mémoire différente, j'ai conçu des schémas variables pour chaque hiérarchie. Cependant, j'ai conçu des visualisations SM et GPU comme une telle que leurs conceptions sont applicables pour chaque GPU.
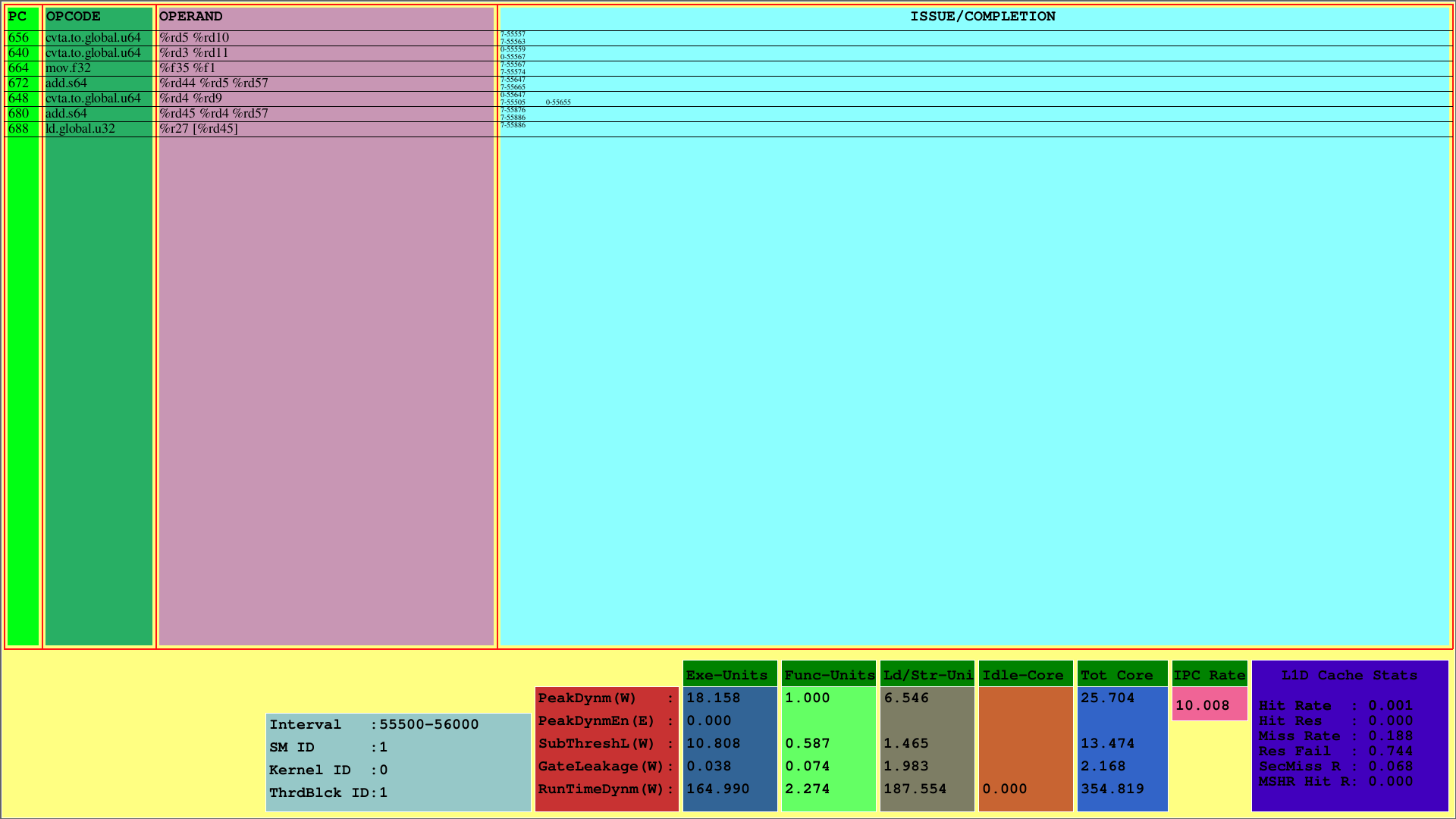
La première visualisation affiche les instructions du 1er CTA, qui est cartographiée sur le 1er SM. Alors que PC affiche le PC de l'instruction, Opcode affiche les codes opérationnels des instructions du 1er bloc de thread. Les opérandes affichent les ID de registre pour l'opcode correspondant des instructions.
Dans la colonne la plus à droite (problème / réalisation), le visualiseur affiche les informations d'émission et d'achèvement des instructions pour chaque chaîne dans la première ligne et la deuxième ligne, respectivement. Par exemple, la première instruction est CVTA.TO.Global.U64, dont le PC est 656, est publié au 55557e cycle par la 7e déformation et achevé au 55563e cycle.
Ce régime montre les instructions émises et terminées par CTA dans un intervalle de cycle prédéterminé. Pour l'exemple ci-dessus, cet intervalle est le [55500, 56000).
De plus, on peut voir l'utilisation du cache L1D et consommer des mesures de puissance d'exécution pour les sous-composants du SMS. Le paramètre Runtimedynm représente la puissance consommée totale pour chaque section. Les unités d'exécution, fonctionnelles et de charge / magasin, et le noyau inactif sont les principales sous-parties de la consommation d'énergie d'un SM. De plus, IPC par SM est affiché en bas.

La deuxième visualisation montre les accès sur les caches L1D, L2 (comme hits, hit_reserved_status, misses, reservation_failures, sector_misses, and mshr_hits ) et les partitions DRAM (en tant que row buffer hits and row buffer misses ) dans l'intervalle du simulateur. Pour les caches, les descriptions d'accès sont les suivantes:
Pour DRAM, les descriptions d'accès sont les suivantes:
Les GPU sont principalement constitués de SMS, qui incluent des unités fonctionnelles, des fichiers et des caches, des NOC et des partitions de mémoire dans lesquelles les banques DRAM et les caches L2 existent. Pour les architectures configurées, le nombre de caches L1D est égal à SMS (clusters de base SIMT), le nombre de banques DRAM est égale au nombre de partitions de mémoire, et le nombre de caches L2 est égal à deux fois le nombre de partitions de mémoire.
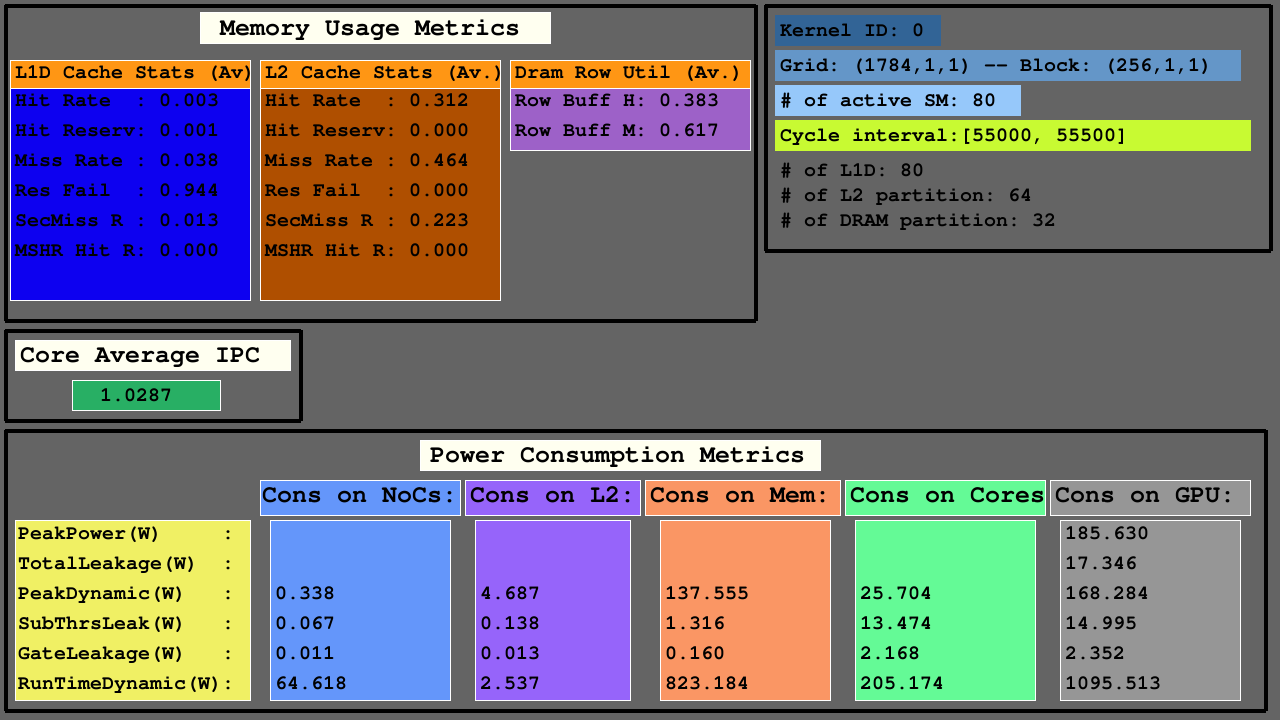
La troisième visualisation montre les statistiques d'accès L1D, L2 et DRAM sur la moyenne dans les mesures d'utilisation de la mémoire, IPC moyen parmi les SMS actifs et les mesures de consommation d'énergie des NOC, les partitions de mémoire des caches L2 et MC + DRAM et SMS.
En plus des options de visualisation d'exécution ci-dessus, nous fournissons une option d'affichage pour les statistiques moyennes d'accès à la mémoire d'exécution et la dissipation d'alimentation IPC vs entre les unités ci-dessous. 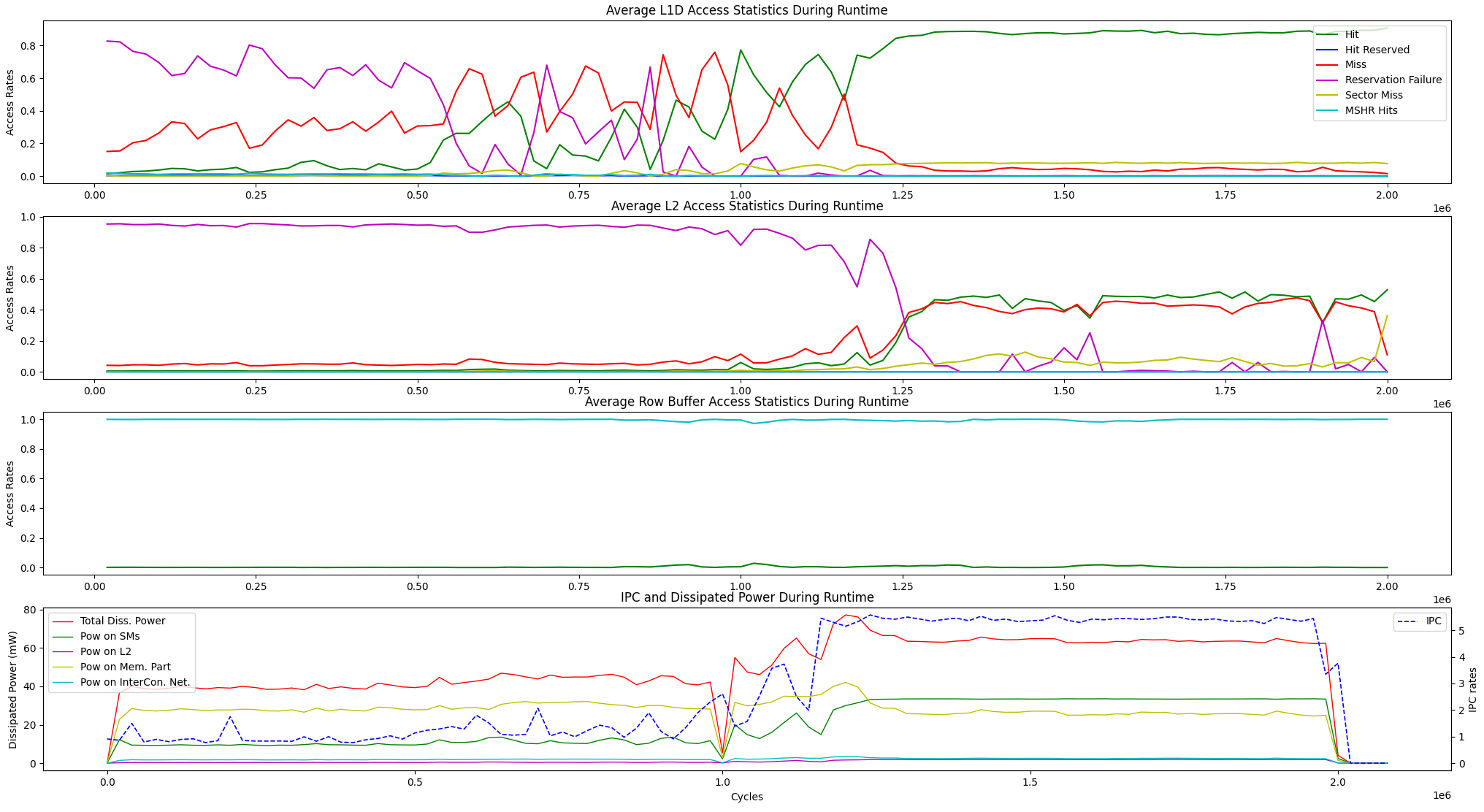
user@GPPRMon/runtime_visualizer:~ $ python3 average_disp.py param1 param2 param3 param4Nous avons expérimenté l'algorithme de classement des pages (PR) sur GV100 et RTX2060S. De plus, nous avons configuré le GPU des GPU de Jetson Agx Xavier et Xavier NX et expérimenté sur eux avec l'algorithme de transformation Fast Fourier. Le profilage expérimental et les résultats de l'affichage sont trop grands pour télécharger ici. Cependant, nous les tenons sur nos serveurs locaux. Si vous le souhaitez, nous pouvons envoyer ces résultats. N'hésitez pas à nous contacter pour toute aide et résultats.


