GPPRMon
1.0.0
Documentación detallada sobre GPGPU-SIM, qué modelos y arquitecturas de GPU existen, cómo configurarlo y una guía del código fuente se puede encontrar aquí. Además, se puede encontrar una documentación detallada en Accelwattch para recopilar métricas de consumo de energía para subcomponentes y una guía del código fuente aquí.
Dependencias GPGPU-SIM:
gcc, g++, make, makedepend, xutils, bison, flex, zlib, CUDA Toolkit
(opcional) Dependencias de documentación GPGPU-SIM:doxygen, graphvi
(Opcional) Dependencias AerialVision:python-pmw, python-ply, python-numpy, libpng12-dev, python-matplotlib
Dependencias CUDA SDK:libxi-dev, libxmu-dev, libglut3-dev
Después de instalar bibliotecas de requisitos previos para ejecutar el simulador correctamente, clone la implementación de Accelwattch del simulador (GPGPU-SIM 4.2). Luego, debe seguir los siguientes comandos dentro del directorio del simulador para construir el simulador.
user@GPPRMon:~ $ source setup_environment < build_type >
# That command sets the environment variables so that the simulator can find related executables in the linkage path.
# If you want to debug the simulator (as written in C/C++), you should specify build_type as ` debug ` .
# Otherwise, you do not need to specify it ; blank as empty. It will automatically build the executables with ` release ` version. user@GPPRMon:~ $ make # To compile source files, create and link the executable files of the simulator.
user@GPPRMon:~ $ make clean # To clean the simulator executablesAdemás, si desea generar archivos de documentación cuyas dependencias se especifican como opcionales, primero debe instalar las dependencias. Después, puede obtener los documentos con
user@GPPRMon:~ $ make docs # Generates doxygen files describing simulator elements
user@GPPRMon:~ $ make cleandocs # Deletes pre-generated doxygen files if they exist.La documentación generada con Doxygen facilita la comprensión de clases, plantillas, funciones, etc., para el simulador.
Durante la simulación, el simulador crea información de acceso a la memoria en la ruta a continuación.
user@GPPRMon/runtime_profiling_metrics/memory_accesses:~ $ Para habilitar la colección de métricas de acceso de memoria, uno debe especificar los indicadores a continuación en el archivo gpgpusim.config .
| Banderas | Descripciones | Valor predeterminado |
|---|---|---|
| -mem_profiler | Habilitando la recopilación de métricas de acceso a la memoria | 0 = APAGADO |
| -mem_runtime_stat | Determinación de la frecuencia de muestreo para la colección métrica | 100 (registro después de cada 100 ciclos de GPU) |
| -IPC_PER_PROF_INTERVAL | Registro de tarifas de IPC para cada muestra de colección métrica | 0 = No recolectar |
| -instruction_monitor | Registro de estadísticas de emisión/finalización de las instrucciones | 0 = No recolectar |
| -L1d_metrics | Grabación de métricas para accesos de caché L1D | 0 = No recolectar |
| -L2_metrics | RecordingOlecting Metrics para accesos de caché L2 | 0 = No recolectar |
| -Dram_Metrics | Grabando métricas para accesos a DRAM | 0 = No recolectar |
| -Store_enable | Grabación de métricas para instrucciones de tienda y carga | 0 = simplemente registre métricas para la carga |
| -Accumulate_stats | Acumulación de métricas recolectadas | 0 = No acumule |
Durante la simulación, el simulador registra las métricas de consumo de energía en la ruta a continuación.
user@GPPRMon/runtime_profiling_metrics/energy_consumption:~ $El simulador creará carpetas separadas y métricas de perfil de alimentación para cada núcleo en tiempo de ejecución. Por ahora, las métricas de consumo de energía a continuación son compatibles, pero estas métricas pueden mejorarse aún más para investigar las subunidades de forma independiente.
GPU
Centro
Unidad de ejecución (registrar FU, programadores, unidades funcionales, etc.)
Carga de la unidad de almacenamiento (barra transversal, memoria compartida, búfer de fallas/relleno de MEM compartida, caché, búfer de pre -captura de caché, búfer de reducción de escritura de caché, búfer de Miss Cache Miss, etc.)
Instrucción Unidad funcional (caché de instrucciones, búfer objetivo de rama, decodificador, predictor de rama, etc.)Red en chip
Cache L2
DRAM + controlador de memoriaMotor delantero
Phy entre el controlador de memoria y DRAM
Motor de transacción (motor de backend)
DRACMA
| Banderas | Descripciones | Valor predeterminado |
|---|---|---|
| -Power_Simulation_Enabled | Habilitando la recolección de métricas de consumo de energía | 0 = APAGADO |
| -gpgpu_runtime_stat | Determinación de la frecuencia de muestreo en términos de ciclo de GPU | 1000 ciclos |
| -power_per_cycle_dump | Dumping de potencia detallada en cada muestra | 0 = APAGADO |
| -dvfs_enabled | Encender/apagar la escala de frecuencia de voltaje dinámico para el modelo de potencia | 0 = No habilitado |
| -aggregate_power_stats | Registro de estadísticas de emisión/finalización de las instrucciones | 0 = No te agregue |
| -steady_power_levels_enabled | Producir un archivo para los niveles de potencia estables | 0 = APAGADO |
| -steady_state_definition | Desviación permitida: número de muestras | 8: 4 |
| -power_trace_enabled | Producir un archivo para el Trace de potencia | 0 = APAGADO |
| -Power_Trace_ZLevel | Nivel de compresión del registro de salida de rastreo de potencia | 6, (0 = sin comp, 9 = más alto) |
| -Power_Simulation_Mode | Entrada de contador de rendimiento del interruptor para la simulación de alimentación | 0, (0 = Sim, 1 = HW, 2 = HW-SIM Hybrid) |
Nuestra herramienta Visualizer toma archivos .CSV obtenidos mediante la simulación de tiempo de ejecución de un núcleo GPU y genera tres esquemas de visualización diferentes. Actualmente, el simulador admite GTX480_FERMI, QV100_VOLTA, RTX2060S_TURING, RTX2060_TURING, RTX3070_AMPERE, TITAN_KEPLER, TITANV_VOLTA, TITANX_PASCAL GPU Actualmente. Como cada GPU tiene una jerarquía de memoria diferente, diseñé esquemas variables para cada jerarquía. Sin embargo, diseñé visualizaciones SM y GPU como una de las que sus diseños son aplicables para cada GPU.
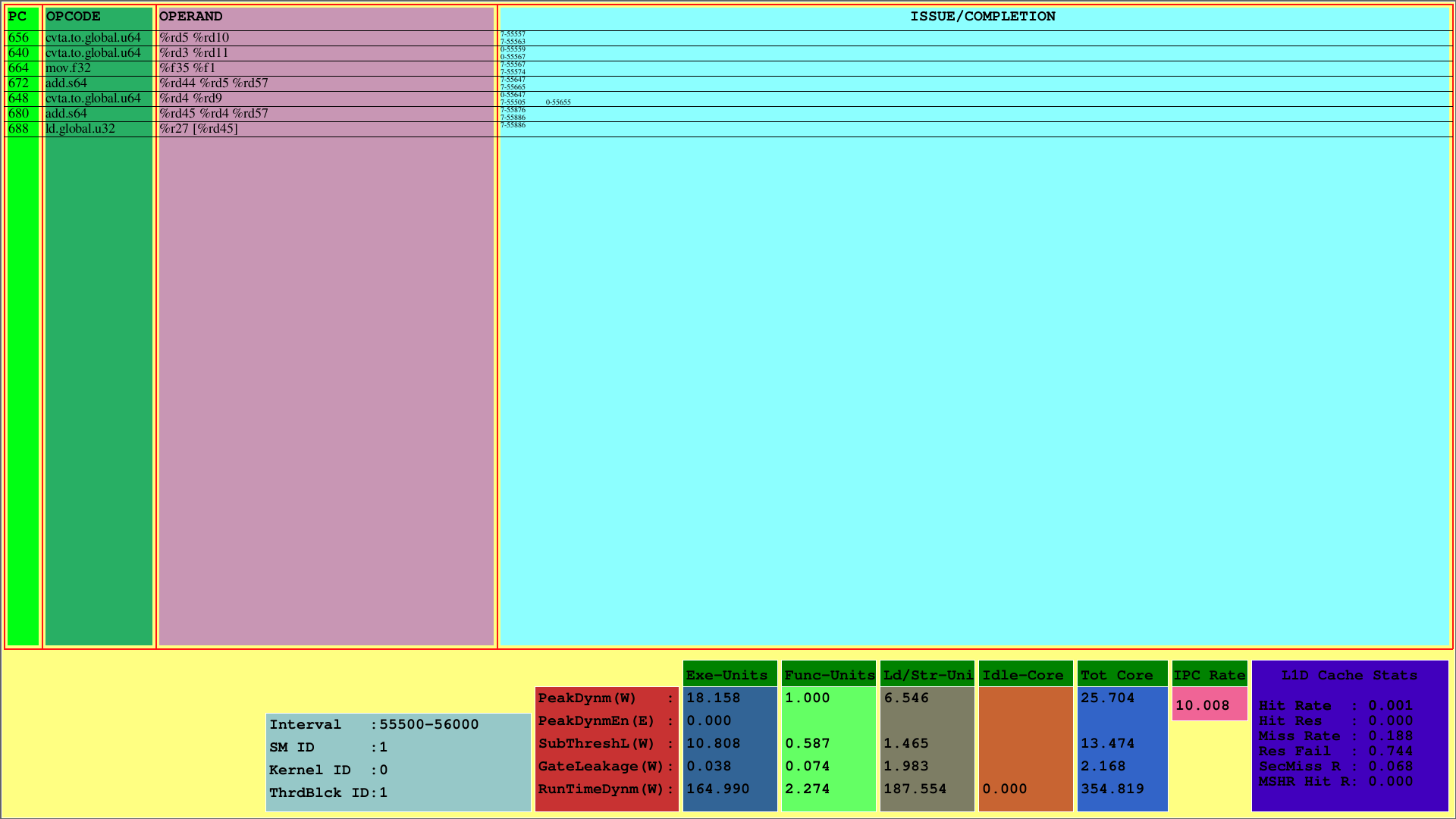
La primera visualización muestra las instrucciones para el 1er CTA, que se asigna a la primera SM. Mientras que la PC muestra la PC de la instrucción, OpCode muestra los códigos operativos de las instrucciones del primer bloque de subprocesos. Los operandos muestran los ID de registro para el código de operación correspondiente de las instrucciones.
En la columna más derecha (problema/finalización), el visualizador muestra la información de emisión y finalización de las instrucciones para cada urdimbre en la primera fila y segunda fila, respectivamente. Por ejemplo, la primera instrucción es CVTA.To.Global.U64, cuya PC es 656, se emite en el 55557º ciclo por la 7ª Warp y se completa en el ciclo 55563.
Este esquema muestra las instrucciones emitidas y completadas de un CTA dentro de un intervalo de ciclo predeterminado. Para el ejemplo anterior, este intervalo es el [55500, 56000).
Además, uno puede ver el uso de caché L1D y las mediciones de potencia de tiempo de ejecución consumidas para los subcomponentes del SMS. El parámetro Runtimedynm representa la potencia total consumida para cada sección. La ejecución, las unidades funcionales y de carga/almacenamiento, y el núcleo inactivo son las principales subpartes del consumo de energía de un SM. Además, IPC por SM se muestra en la parte inferior.

La segunda visualización muestra los accesos en L1D, L2 Caches (como hits, hit_reserved_status, misses, reservation_failures, sector_misses, and mshr_hits ) y divisas DRAM (a medida que row buffer hits and row buffer misses ) dentro del intervalo del simulador. Para los cachés, las descripciones de acceso son las siguientes:
Para DRAM, las descripciones de acceso son las siguientes:
Las GPU consisten principalmente en SMS, que incluyen unidades funcionales, archivos de registro y cachés, NOC y particiones de memoria en las que existen bancos DRAM y cachés L2. Para las arquitecturas configuradas, el número de cachés L1D es igual a SMS (clústeres de núcleo SIMT), el número de bancos DRAM es igual al número de particiones de memoria, y el número de cachés L2 es igual al doble del número de particiones de memoria.
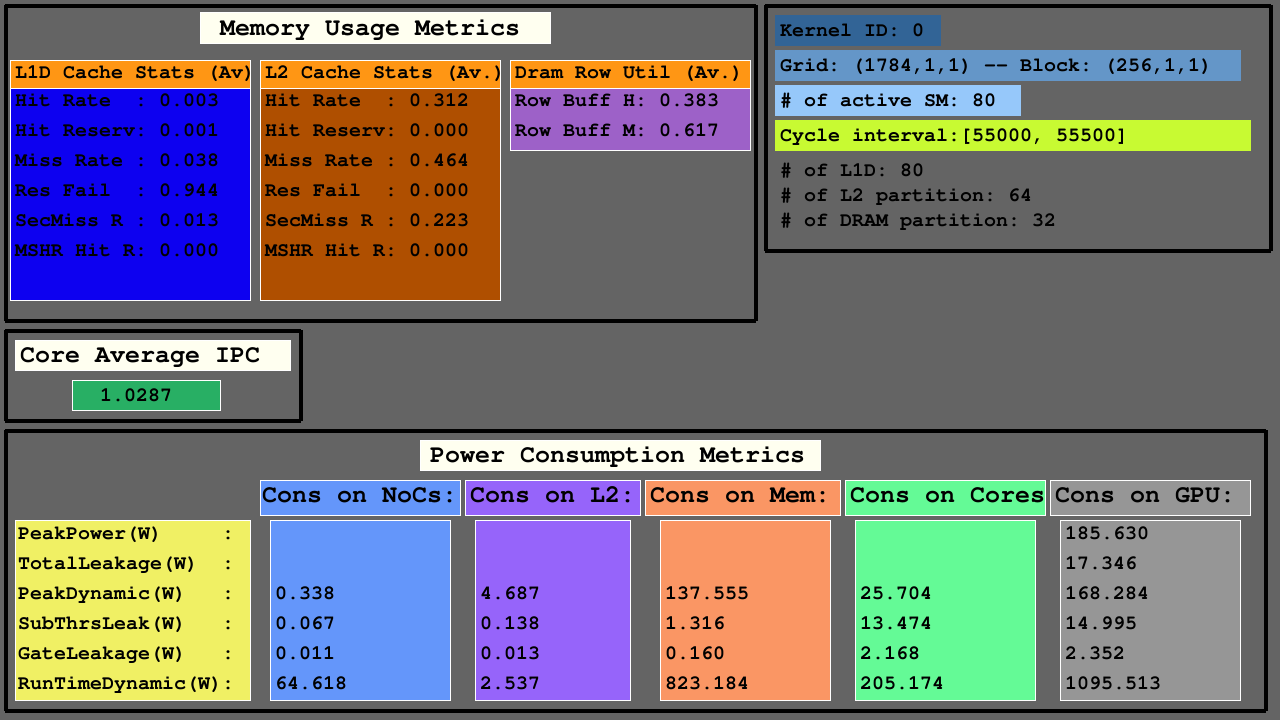
La tercera visualización muestra las estadísticas de acceso L1D, Cache y DRAM en el promedio de la media en las métricas de uso de la memoria, IPC promedio entre SMS activos y métricas de consumo de energía de NOC, particiones de memoria de cachés L2 y MC+DRAM, y SMS.
Además de las opciones de visualización de tiempo de ejecución anterior, proporcionamos una opción de visualización para las estadísticas promedio de acceso a la memoria de tiempo de ejecución y la disipación de potencia IPC vs entre las unidades a continuación. 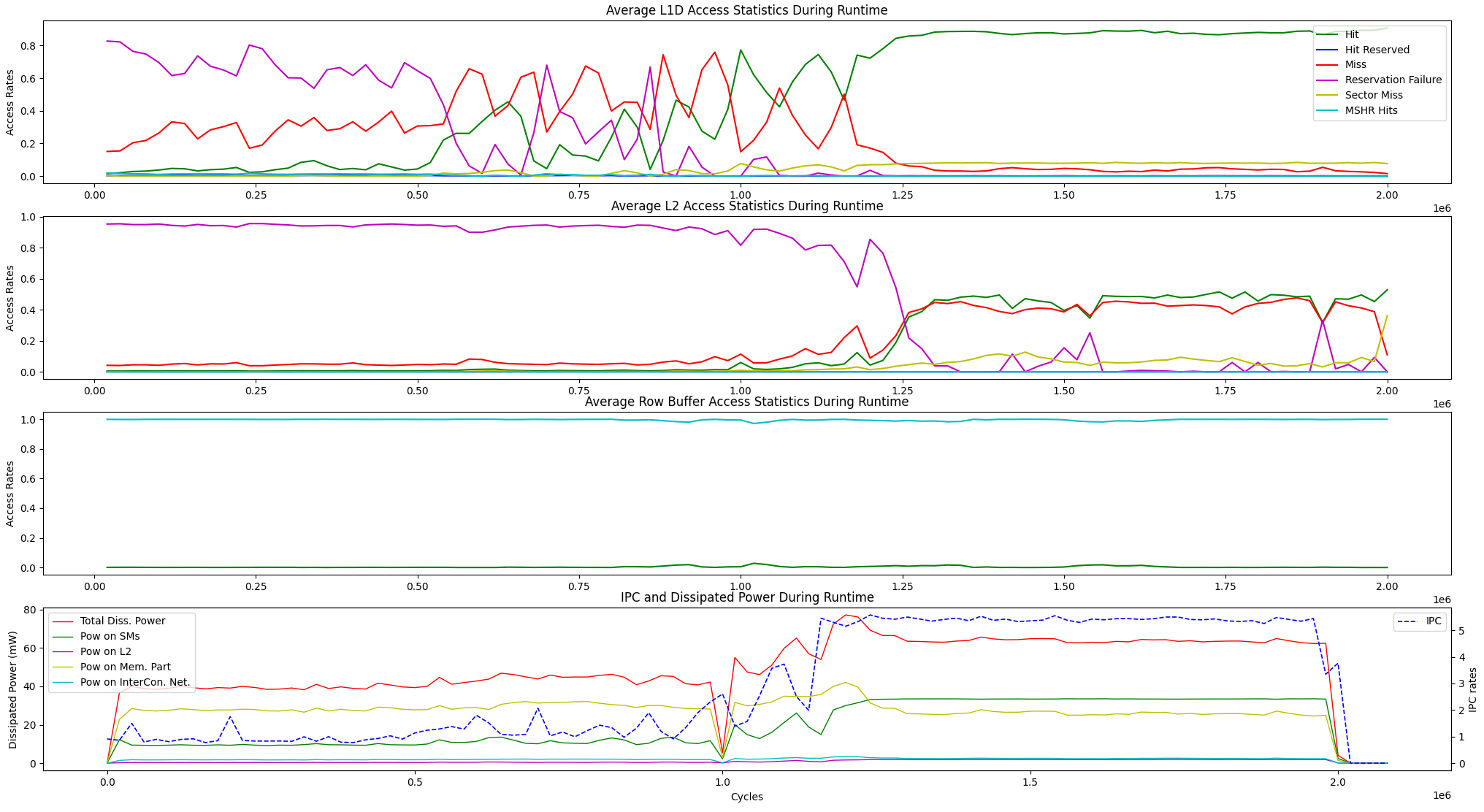
user@GPPRMon/runtime_visualizer:~ $ python3 average_disp.py param1 param2 param3 param4Hemos experimentado con el algoritmo de clasificación de página (PR) en GV100 y RTX2060. Además, hemos configurado la GPU de Jetson AGX Xavier y Xavier NX GPUS y experimentamos con ellos con el algoritmo de transformación rápida de Fourier. El perfil experimental y los resultados de visualización son demasiado grandes para cargar aquí. Sin embargo, los mantenemos en nuestros servidores locales. Si lo desea, podemos enviar esos resultados. No dude en contactarnos para obtener ayuda y resultados.


