GPPRMon
1.0.0
有關GPGPU-SIM,GPU模型和體系結構的存在,如何配置以及源代碼指南的詳細文檔,可以在此處找到。此外,可以在此處找到有關Accelwattch的詳細文檔,以收集用於子組件的功耗指標和源代碼指南。
GPGPU-SIM依賴性:
gcc, g++, make, makedepend, xutils, bison, flex, zlib, CUDA Toolkit
(可選) gpgpu-sim文檔依賴性:doxygen, graphvi
(可選的)航空視頻依賴性:python-pmw, python-ply, python-numpy, libpng12-dev, python-matplotlib
cuda sdk依賴性:libxi-dev, libxmu-dev, libglut3-dev
安裝先決條件庫以正確運行模擬器後,克隆模擬器的AccelWattch實現(GPGPU-SIM 4.2)。然後,您應該按照模擬器目錄內的以下命令來構建模擬器。
user@GPPRMon:~ $ source setup_environment < build_type >
# That command sets the environment variables so that the simulator can find related executables in the linkage path.
# If you want to debug the simulator (as written in C/C++), you should specify build_type as ` debug ` .
# Otherwise, you do not need to specify it ; blank as empty. It will automatically build the executables with ` release ` version. user@GPPRMon:~ $ make # To compile source files, create and link the executable files of the simulator.
user@GPPRMon:~ $ make clean # To clean the simulator executables此外,如果要生成將依賴項指定為可選的文檔文件,則必須首先安裝依賴項。之後,您可以獲取文檔
user@GPPRMon:~ $ make docs # Generates doxygen files describing simulator elements
user@GPPRMon:~ $ make cleandocs # Deletes pre-generated doxygen files if they exist.帶有doxygen的生成文檔可以簡化模擬器對類,模板,功能等的理解。
在模擬過程中,模擬器在下面的路徑中創建內存訪問信息。
user@GPPRMon/runtime_profiling_metrics/memory_accesses:~ $要啟用內存訪問度量集合,必須在gpgpusim.config文件中指定以下標誌。
| 標誌 | 描述 | 預設值 |
|---|---|---|
| -mem_profiler | 啟用收集內存訪問指標 | 0 = OFF |
| -mem_runtime_stat | 確定公制收集的採樣頻率 | 100(每100個GPU週期後記錄) |
| -ipc_per_prof_interval | 記錄每個度量收集樣本的IPC率 | 0 =不要收集 |
| -instruction_monitor | 錄製問題/說明的完成統計 | 0 =不要收集 |
| -l1d_metrics | 錄製L1D緩存訪問的指標 | 0 =不要收集 |
| -l2_metrics | L2緩存訪問的錄音指標 | 0 =不要收集 |
| -dram_metrics | 錄製DRAM訪問的指標 | 0 =不要收集 |
| -store_enable | 記錄商店和加載說明的指標 | 0 =僅記錄負載的指標 |
| -accumulate_stats | 累積收集的指標 | 0 =不要累積 |
在模擬過程中,模擬器在以下路徑中記錄功耗指標。
user@GPPRMon/runtime_profiling_metrics/energy_consumption:~ $模擬器將在運行時為每個內核創建單獨的文件夾和電源分析指標。目前,支持下面的功耗指標,但是這些指標可能會進一步增強以獨立研究子單元。
GPU
核
執行單元(註冊FU,調度程序,功能單元等)
加載存儲單元(橫梁,共享內存,共享MEM MISS/FOLID BUFFER,CACHE,CACHE PREFETCH緩衝區,Cache寫入Buffer,Cache Miss Miss Buffer等)
指令功能單元(指令緩存,分支目標緩衝區,解碼器,分支預測器等)網絡上的芯片
L2緩存
DRAM +內存控制器前端引擎
記憶控制器和DRAM之間的PHY
交易引擎(後端引擎)
德拉姆
| 標誌 | 描述 | 預設值 |
|---|---|---|
| -power_simulation_enabled | 啟用收集功耗指標 | 0 = OFF |
| -gpgpu_runtime_stat | 根據GPU循環確定採樣頻率 | 1000個週期 |
| -power_per_cycle_dump | 在每個樣品中傾倒詳細的功率輸出 | 0 = OFF |
| -dvfs_enabled | 打開/關閉電源模型的動態電壓頻率縮放 | 0 =未啟用 |
| -aggregate_power_stats | 錄製問題/說明的完成統計 | 0 =不要匯總 |
| -steady_power_levels_enabled | 生產穩定功率水平的文件 | 0 = OFF |
| -steady_state_definition | 允許偏差:樣品數量 | 8:4 |
| -power_trace_enabled | 生成功率跟踪的文件 | 0 = OFF |
| -power_trace_zlevel | 功率跟踪輸出日誌的壓縮水平 | 6,(0 = no comp,9 =最高) |
| -power_simulation_mode | 開關性能計數器輸入用於電源模擬 | 0,(0 = SIM,1 = HW,2 = HW-SIM Hybrid) |
我們的可視化器工具採用了通過GPU內核的運行時模擬獲得的.CSV文件,並生成了三種不同的可視化方案。當前,模擬器支持GTX480_FERMI, QV100_VOLTA, RTX2060S_TURING, RTX2060_TURING, RTX3070_AMPERE, TITAN_KEPLER, TITANV_VOLTA, TITANX_PASCAL GPUS。由於每個GPU都有不同的內存層次結構,因此我為每個層次結構設計了不同的方案。但是,我將SM和GPU可視化設計為一種,使它們的設計適用於每個GPU。
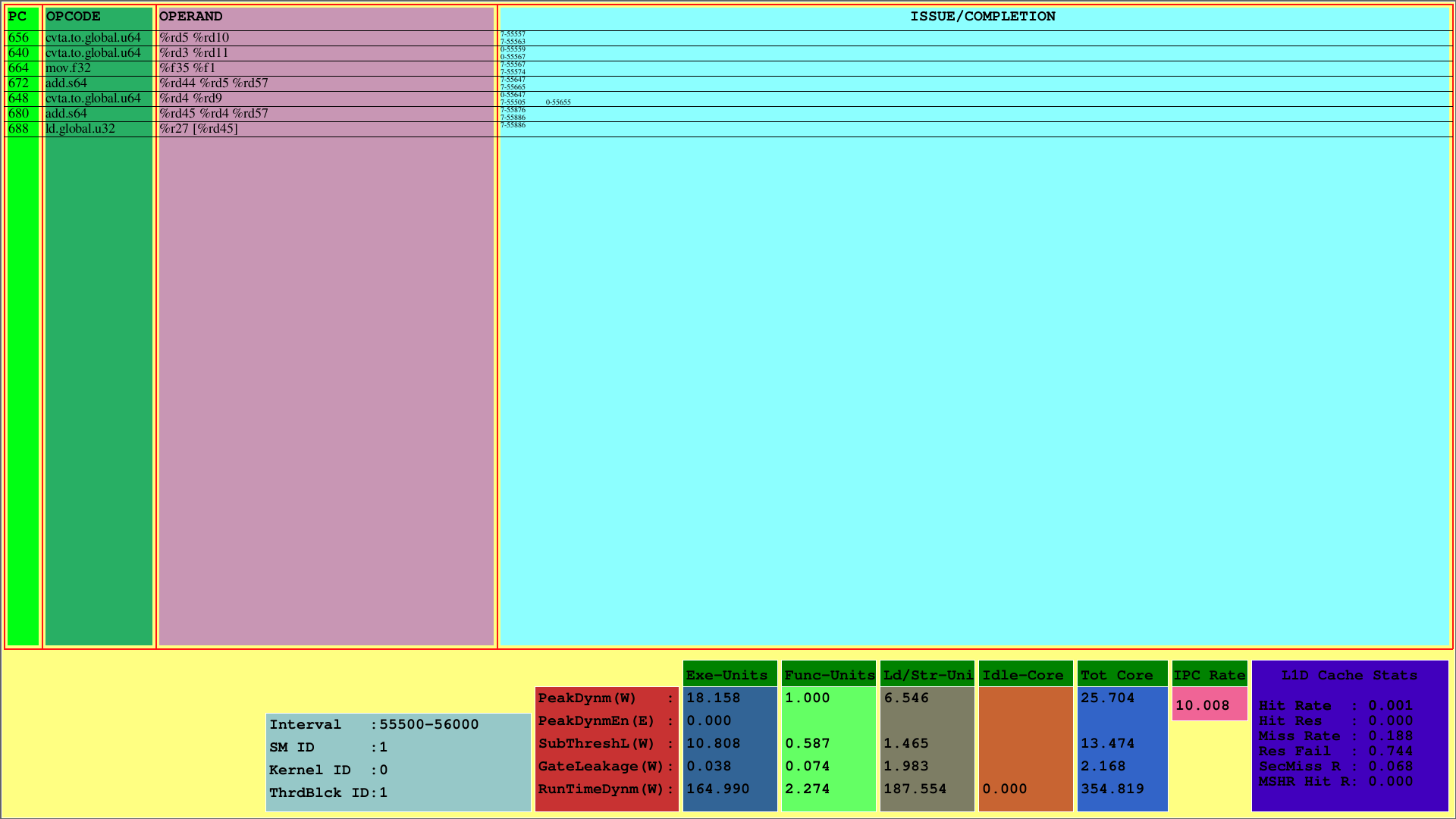
第一個可視化顯示了第1個CTA的指令,該指令映射到第一個SM。當PC顯示了指令的PC時,OPCODE顯示了第一線程塊的指令的操作代碼。操作數顯示了指令的相應操作碼的寄存器ID。
在最右邊的列(發行/完成),可視化器分別在第一行和第二行中顯示每個紗的發行和完成信息。例如,第一個指令是CVTA.TO.GLOBAL.U64的PC為656,是在第7個扭曲時在第55557個週期發行的,並在第55563個週期完成。
該方案顯示了在預定週期間隔內發布並完成的指示。在上面的示例中,此間隔為[55500,56000)。
此外,可能會看到SMS子組件的L1D緩存使用情況和消耗的運行時功率測量值。 RunTimedyNM參數表示每個部分的總消耗功率。執行,功能和負載/商店單元以及空閒核心是SM功耗的主要子部分。另外,底部顯示IPC每SM。

第二個可視化顯示了L1D,L2緩存(作為hits, hit_reserved_status, misses, reservation_failures, sector_misses, and mshr_hits )和DRAM分區(作為row buffer hits and row buffer misses )在模擬器間隔內的訪問。對於緩存,訪問說明如下:
對於DRAM,訪問說明如下:
GPU主要由SMS組成,其中包括功能單元,寄存器文件和卡車,NOC和內存分區,其中DRAM Banks和L2 Caches存在。對於配置的體系結構,L1D緩存的數量等於SMS(SIMT核心群集),DRAM庫的數量等於內存分區的數量,L2緩存的數量等於內存分區的兩倍。
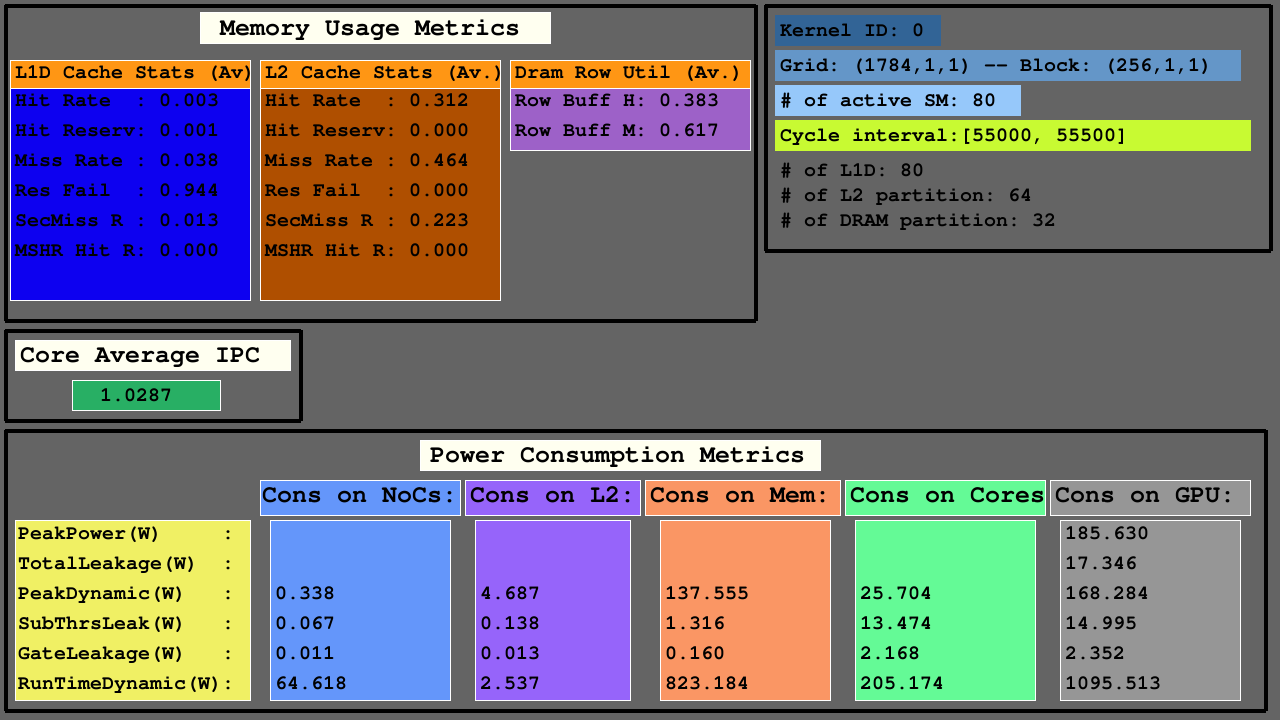
第三個可視化顯示了內存使用度量指標中的On-A-A-L1D,L2 CACHE和DRAM訪問統計信息,主動SMS中的平均IPC以及NOC的功耗指標,L2緩存和MC+DRAM的存儲器分區以及SMS。
除了上述運行時可視化選項外,我們還為以下單元之間的平均運行時內存訪問統計信息和IPC與功率耗散提供了一個顯示選項。 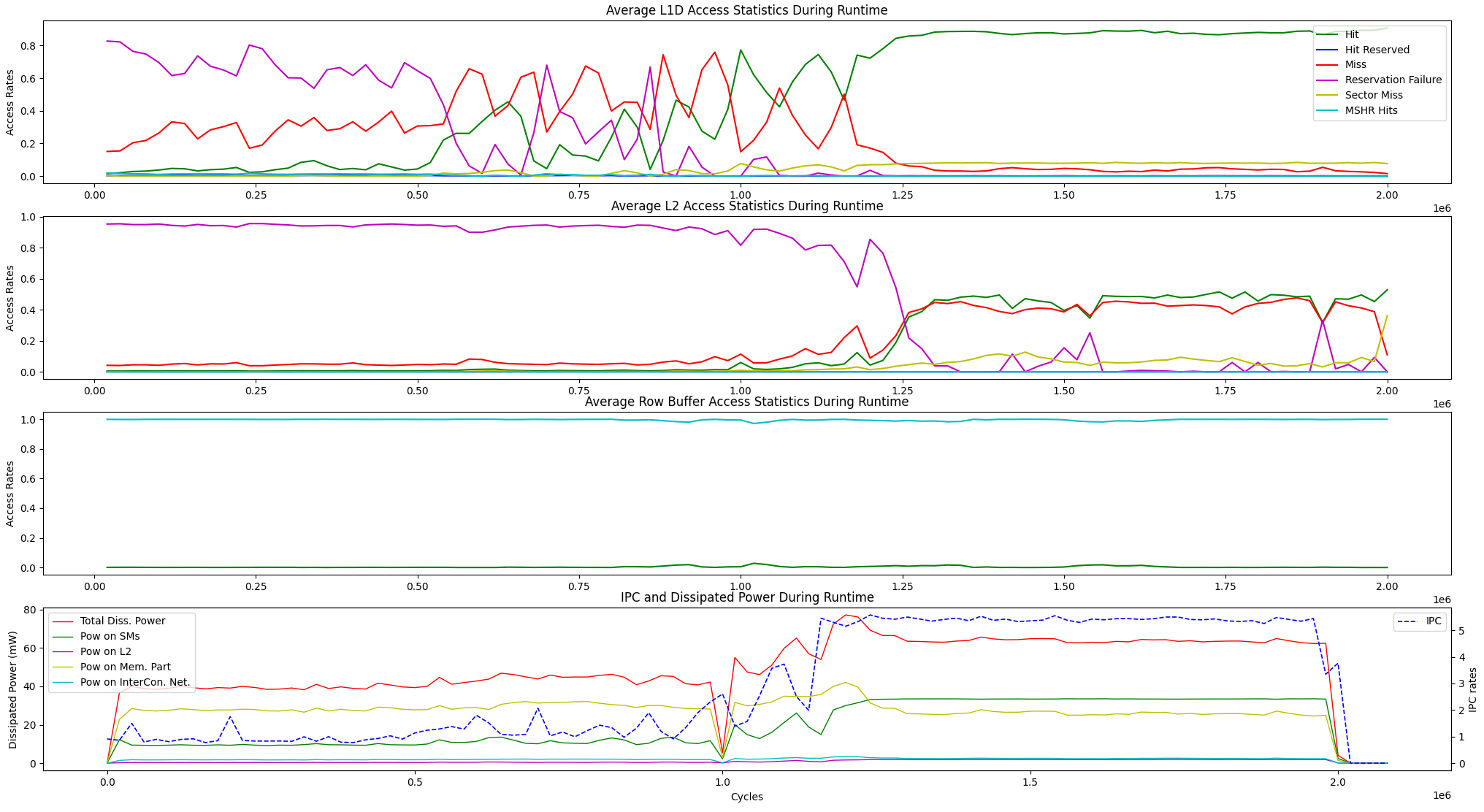
user@GPPRMon/runtime_visualizer:~ $ python3 average_disp.py param1 param2 param3 param4我們已經在GV100和RTX2060上使用頁面排名算法(PR)進行了實驗。此外,我們還配置了Jetson Agx Xavier和Xavier NX GPU的GPU,並使用快速傅立葉變換算法對它們進行了實驗。實驗分析和顯示結果太大,無法在此處上傳。但是,我們將它們固定在本地服務器上。如果需要,我們可以發送這些結果。請隨時與我們聯繫以尋求任何幫助和結果。


