GPPRMon
1.0.0
เอกสารรายละเอียดเกี่ยวกับ GPGPU-SIM โมเดล GPU และสถาปัตยกรรมที่มีอยู่วิธีการกำหนดค่าและคำแนะนำเกี่ยวกับซอร์สโค้ดสามารถพบได้ที่นี่ นอกจากนี้เอกสารโดยละเอียดเกี่ยวกับ Accelwattch เพื่อรวบรวมตัวชี้วัดการใช้พลังงานสำหรับส่วนประกอบย่อยและคู่มือสำหรับซอร์สโค้ดสามารถพบได้ที่นี่
การพึ่งพา GPGPU-SIM:
gcc, g++, make, makedepend, xutils, bison, flex, zlib, CUDA Toolkit
(ไม่บังคับ) การพึ่งพาเอกสารของ GPGPU-SIM:doxygen, graphvi
(ไม่บังคับ) การพึ่งพาทางอากาศ:python-pmw, python-ply, python-numpy, libpng12-dev, python-matplotlib
การพึ่งพา CUDA SDK:libxi-dev, libxmu-dev, libglut3-dev
หลังจากติดตั้งไลบรารีที่จำเป็นต้องใช้เพื่อเรียกใช้เครื่องจำลองอย่างถูกต้อง จากนั้นคุณควรทำตามคำสั่งด้านล่างภายในไดเรกทอรี Simulator เพื่อสร้างตัวจำลอง
user@GPPRMon:~ $ source setup_environment < build_type >
# That command sets the environment variables so that the simulator can find related executables in the linkage path.
# If you want to debug the simulator (as written in C/C++), you should specify build_type as ` debug ` .
# Otherwise, you do not need to specify it ; blank as empty. It will automatically build the executables with ` release ` version. user@GPPRMon:~ $ make # To compile source files, create and link the executable files of the simulator.
user@GPPRMon:~ $ make clean # To clean the simulator executablesยิ่งไปกว่านั้นหากคุณต้องการสร้างไฟล์เอกสารที่มีการอ้างอิงที่ระบุว่าเป็นตัวเลือกคุณต้องติดตั้งการอ้างอิงก่อน หลังจากนั้นคุณสามารถรับเอกสารได้ด้วย
user@GPPRMon:~ $ make docs # Generates doxygen files describing simulator elements
user@GPPRMon:~ $ make cleandocs # Deletes pre-generated doxygen files if they exist.เอกสารที่สร้างขึ้นด้วย doxygen ช่วยลดความเข้าใจในชั้นเรียนเทมเพลตฟังก์ชั่น ฯลฯ สำหรับตัวจำลอง
ในระหว่างการจำลองสถานการณ์จำลองจะสร้างข้อมูลการเข้าถึงหน่วยความจำในเส้นทางด้านล่าง
user@GPPRMon/runtime_profiling_metrics/memory_accesses:~ $ ในการเปิดใช้งานการรวบรวมตัวชี้วัดการเข้าถึงหน่วยความจำเราต้องระบุแฟล็กด้านล่างในไฟล์ gpgpusim.config
| ธง | คำอธิบาย | ค่าเริ่มต้น |
|---|---|---|
| -mem_profiler | เปิดใช้งานการรวบรวมตัวชี้วัดการเข้าถึงหน่วยความจำ | 0 = ปิด |
| -mem_runtime_stat | การกำหนดความถี่การสุ่มตัวอย่างสำหรับการรวบรวมตัวชี้วัด | 100 (บันทึกหลังจากแต่ละรอบ 100 GPU) |
| -IPC_PER_PROF_INTERVAL | บันทึกอัตรา IPC สำหรับตัวอย่างการรวบรวมตัวชี้วัดแต่ละตัวอย่าง | 0 = อย่ารวบรวม |
| -instruction_monitor | การบันทึกปัญหา/สถิติการเสร็จสิ้นของคำแนะนำ | 0 = อย่ารวบรวม |
| -l1d_metrics | การบันทึกตัวชี้วัดสำหรับการเข้าถึงแคช L1D | 0 = อย่ารวบรวม |
| -l2_metrics | การบันทึกตัวชี้วัดสำหรับการเข้าถึงแคช L2 | 0 = อย่ารวบรวม |
| -dram_metrics | การบันทึกตัวชี้วัดสำหรับการเข้าถึง DRAM | 0 = อย่ารวบรวม |
| -store_enable | การบันทึกตัวชี้วัดสำหรับทั้งคำแนะนำในการจัดเก็บและโหลด | 0 = เพียงแค่บันทึกตัวชี้วัดสำหรับการโหลด |
| -สะสม _stats | สะสมตัวชี้วัดที่รวบรวมได้ | 0 = อย่าสะสม |
ในระหว่างการจำลองตัวจำลองจะบันทึกตัวชี้วัดการใช้พลังงานในเส้นทางด้านล่าง
user@GPPRMon/runtime_profiling_metrics/energy_consumption:~ $ตัวจำลองจะสร้างโฟลเดอร์แยกต่างหากและตัวชี้วัดการทำโปรไฟล์พลังงานสำหรับแต่ละเคอร์เนลที่รันไทม์ สำหรับตอนนี้การวัดการใช้พลังงานด้านล่างได้รับการสนับสนุน แต่ตัวชี้วัดเหล่านี้อาจได้รับการปรับปรุงเพิ่มเติมเพื่อตรวจสอบหน่วยย่อยอย่างอิสระ
GPU
แกนกลาง
หน่วยดำเนินการ (ลงทะเบียน FU, Schedulers, หน่วยการทำงาน ฯลฯ )
โหลดหน่วยเก็บ (คาน, หน่วยความจำที่ใช้ร่วมกัน, MEM Miss/Fill Buffer, Cache, Cache Prefetch Buffer, Cache Writeback Buffer, Cache Miss Buffer ฯลฯ )
หน่วยการทำงานหน่วยการทำงาน (แคชคำสั่ง, บัฟเฟอร์เป้าหมายสาขา, ตัวถอดรหัส, ตัวทำนายสาขา ฯลฯ )เครือข่ายบนชิป
แคช L2
ตัวควบคุม DRAM + หน่วยความจำเครื่องยนต์ส่วนหน้า
Phy ระหว่างตัวควบคุมหน่วยความจำและ DRAM
เครื่องยนต์ธุรกรรม (Backend Engine)
เครื่องราง
| ธง | คำอธิบาย | ค่าเริ่มต้น |
|---|---|---|
| -powor_simulation_enabled | การเปิดใช้งานตัวชี้วัดการใช้พลังงาน | 0 = ปิด |
| -gpgpu_runtime_stat | การกำหนดความถี่การสุ่มตัวอย่างในแง่ของวัฏจักร GPU | 1,000 รอบ |
| -powor_per_cycle_dump | การทิ้งกำลังไฟโดยละเอียดในแต่ละตัวอย่าง | 0 = ปิด |
| -dvfs_enabled | การเปิด/ปิดการปรับความถี่แรงดันไฟฟ้าแบบไดนามิกสำหรับโมเดลพลังงาน | 0 = ไม่เปิดใช้งาน |
| -aggregate_power_stats | การบันทึกปัญหา/สถิติการเสร็จสิ้นของคำแนะนำ | 0 = อย่ารวม |
| -steady_power_levels_enabled | ผลิตไฟล์สำหรับระดับพลังงานคงที่ | 0 = ปิด |
| -steady_state_definition | การเบี่ยงเบนที่อนุญาต: จำนวนตัวอย่าง | 8: 4 |
| -powor_trace_enabled | การผลิตไฟล์สำหรับการติดตามพลังงาน | 0 = ปิด |
| -powor_trace_zlevel | ระดับการบีบอัดของบันทึกเอาต์พุตการติดตามกำลัง | 6, (0 = ไม่มี comp, 9 = สูงสุด) |
| -powor_simulation_mode | สวิตช์อินพุตตัวนับประสิทธิภาพสำหรับการจำลองพลังงาน | 0, (0 = ซิม, 1 = hw, 2 = hw-sim ไฮบริด) |
เครื่องมือ Visualizer ของเราใช้ไฟล์. CSV ที่ได้รับผ่านการจำลองรันไทม์ของเคอร์เนล GPU และสร้างแผนการสร้างภาพที่แตกต่างกันสามแบบ ขณะนี้ตัวจำลองรองรับ GTX480_FERMI, QV100_VOLTA, RTX2060S_TURING, RTX2060_TURING, RTX3070_AMPERE, TITAN_KEPLER, TITANV_VOLTA, TITANX_PASCAL GPU ในปัจจุบัน เนื่องจาก GPU แต่ละตัวมีลำดับชั้นของหน่วยความจำที่แตกต่างกันฉันจึงออกแบบรูปแบบที่แตกต่างกันสำหรับแต่ละลำดับชั้น อย่างไรก็ตามฉันออกแบบการสร้างภาพข้อมูล SM และ GPU เป็นสิ่งหนึ่งที่การออกแบบของพวกเขาใช้สำหรับแต่ละ GPU
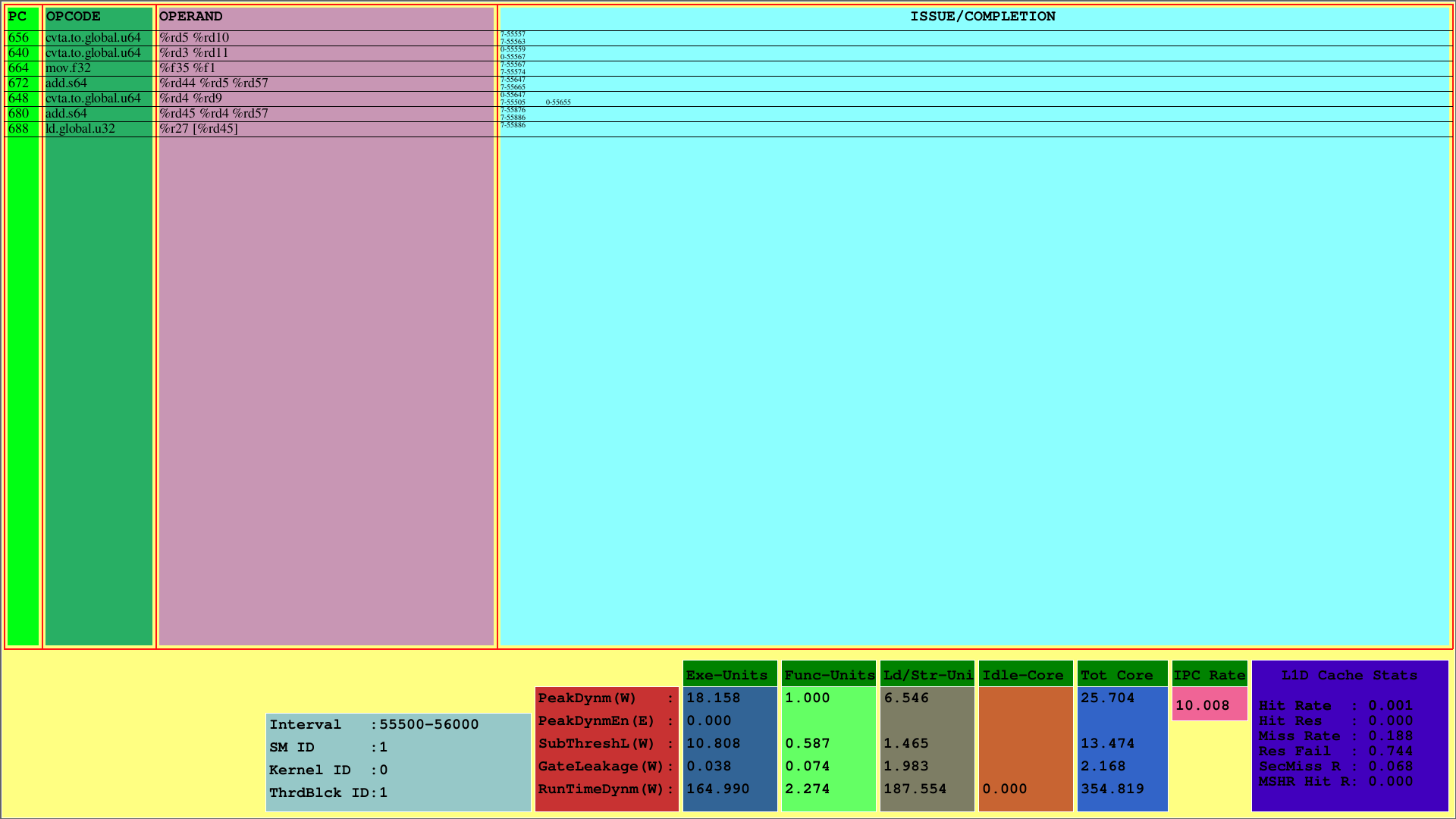
การสร้างภาพครั้งแรกแสดงคำแนะนำสำหรับ CTA ที่ 1 ซึ่งแมปเข้ากับ SM ที่ 1 ในขณะที่พีซีแสดงพีซีของคำสั่ง Opcode จะแสดงรหัสการทำงานของคำสั่งของบล็อกเธรดที่ 1 ตัวถูกดำเนินการแสดงรหัสการลงทะเบียนสำหรับ opcode ที่สอดคล้องกันของคำแนะนำ
ที่คอลัมน์ขวาสุด (ปัญหา/เสร็จสิ้น) Visualizer จะแสดงข้อมูลการออกและการเสร็จสิ้นของคำแนะนำสำหรับแต่ละ warp ในแถวแรกและแถวที่สองตามลำดับ ตัวอย่างเช่นคำสั่งแรกคือ cvta.to.global.u64 ซึ่งพีซีคือ 656 ออกในรอบ 55557th โดย Warp ที่ 7 และเสร็จสิ้นในรอบ 55563rd
รูปแบบนี้แสดงคำแนะนำที่ออกและเสร็จสิ้นของ CTA ภายในช่วงเวลารอบที่กำหนดไว้ล่วงหน้า สำหรับตัวอย่างข้างต้นช่วงเวลานี้คือ [55500, 56000)
นอกจากนี้หนึ่งอาจเห็นการใช้แคช L1D และการวัดพลังงานรันไทม์ที่ใช้สำหรับส่วนประกอบย่อยของ SMS พารามิเตอร์ Runtimedynm แสดงถึงพลังงานที่ใช้ทั้งหมดสำหรับแต่ละส่วน การดำเนินการหน่วยงานและการโหลด/ร้านค้าและการไม่ได้ใช้งานเป็นส่วนย่อยหลักของการใช้พลังงานของ SM นอกจากนี้ IPC ต่อ SM จะปรากฏขึ้นที่ด้านล่าง

การสร้างภาพครั้งที่สองแสดงการเข้าถึงบน L1D, L2 แคช (เช่น hits, hit_reserved_status, misses, reservation_failures, sector_misses, and mshr_hits ) และพาร์ row buffer hits and row buffer misses ชัน DRAM สำหรับแคชคำอธิบายการเข้าถึงมีดังนี้:
สำหรับ DRAM คำอธิบายการเข้าถึงมีดังนี้:
GPUs ส่วนใหญ่ประกอบด้วย SMS ซึ่งรวมถึงหน่วยการทำงานการลงทะเบียนไฟล์และแคช NOCs และพาร์ติชันหน่วยความจำที่ธนาคาร DRAM และแคช L2 มีอยู่ สำหรับสถาปัตยกรรมที่กำหนดค่าจำนวนแคช L1D เท่ากับ SMS (กลุ่ม Core SIMT) จำนวนธนาคาร DRAM เท่ากับจำนวนพาร์ติชันหน่วยความจำและจำนวนแคช L2 เท่ากับสองเท่าของจำนวนพาร์ติชันหน่วยความจำ
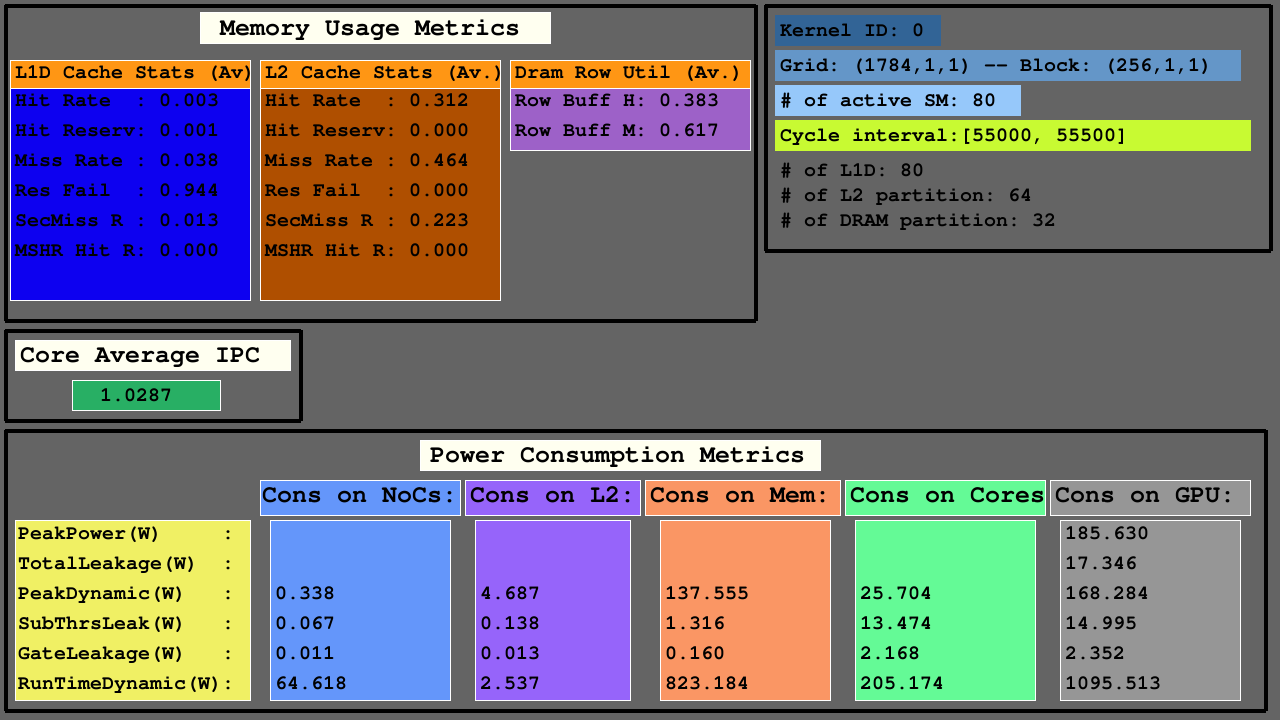
การสร้างภาพข้อมูลครั้งที่สามแสดงให้เห็นว่าแคช L1D, L2, และสถิติการเข้าถึง DRAM ในตัวชี้วัดการใช้หน่วยความจำ, IPC เฉลี่ยในหมู่ SMS ที่ใช้งานอยู่และตัวชี้วัดการใช้พลังงานของ NOCs, พาร์ติชันหน่วยความจำของแคช L2 และ MC+DRAM และ SMS
นอกเหนือจากตัวเลือกการสร้างภาพข้อมูลรันไทม์ข้างต้นเรายังมีตัวเลือกการแสดงผลสำหรับสถิติการเข้าถึงหน่วยความจำรันไทม์โดยเฉลี่ยและการกระจายพลังงาน IPC เทียบกับหน่วยด้านล่าง 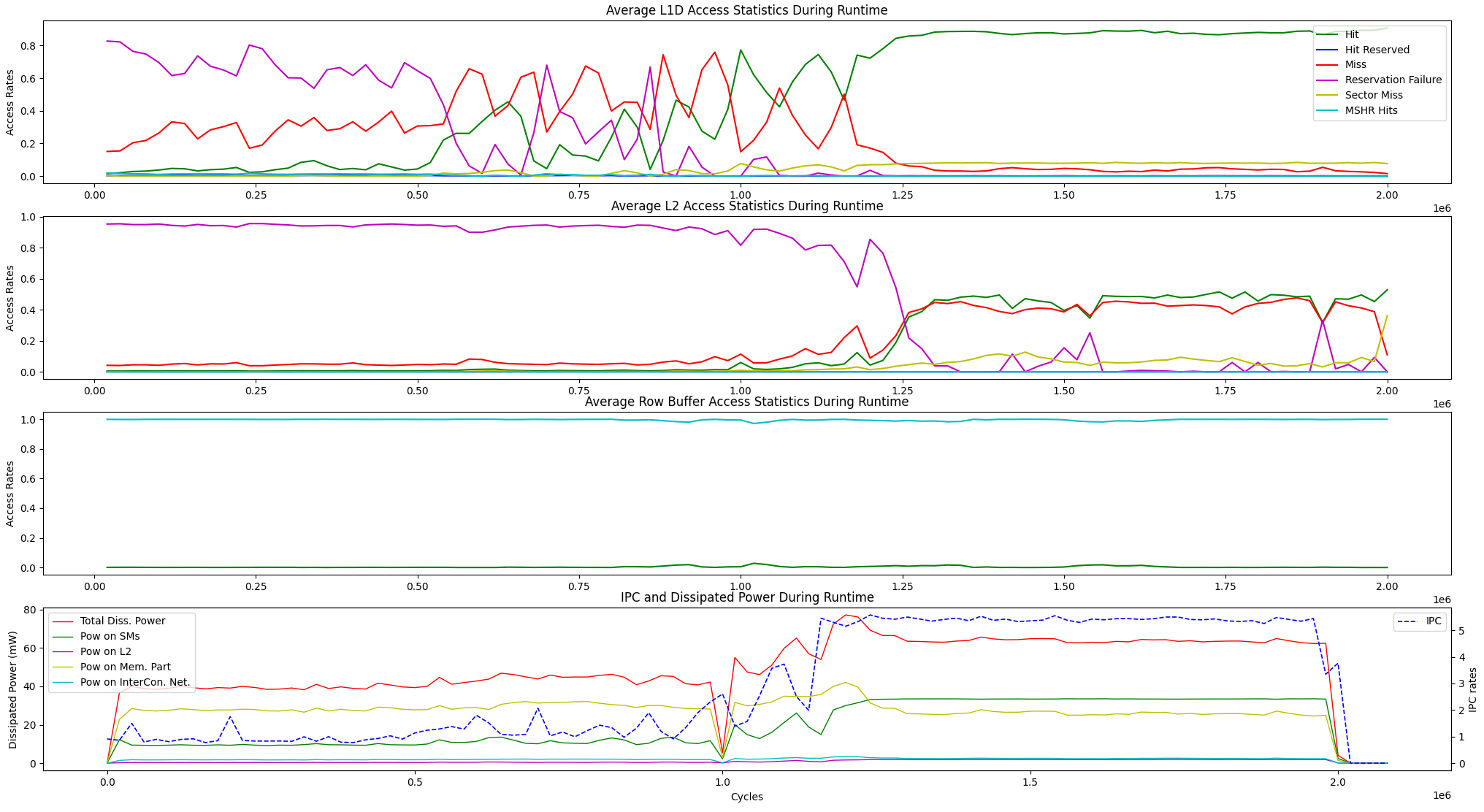
user@GPPRMon/runtime_visualizer:~ $ python3 average_disp.py param1 param2 param3 param4เราได้ทดลองใช้อัลกอริทึมการจัดอันดับหน้า (PR) บน GV100 และ RTX2060S นอกจากนี้เราได้กำหนดค่า GPU ของ Jetson AGX Xavier และ Xavier NX GPU และทดลองกับพวกเขาด้วยอัลกอริทึมการแปลงฟูริเยร์ที่รวดเร็ว การทำโปรไฟล์การทดลองและการแสดงผลลัพธ์มีขนาดใหญ่เกินกว่าที่จะอัปโหลดที่นี่ อย่างไรก็ตามเราถือพวกเขาไว้ในเซิร์ฟเวอร์ท้องถิ่นของเรา หากคุณต้องการเราสามารถส่งผลลัพธ์เหล่านั้นได้ อย่าลังเลที่จะติดต่อเราเพื่อขอความช่วยเหลือและผลลัพธ์ใด ๆ


