PhoNLP
1.0.0

PHONLP是一個多任務學習模型,用於聯合言論(POS)標籤,命名為實體識別(NER)和依賴性解析。越南基準數據集的實驗表明,PHONLP會產生最新的結果,表現優於單任務學習方法,該方法可以獨立地對每個任務進行預培訓的越南語模型Phobert。
儘管我們在越南語上評估了PhonLP,但下面的使用示例可以直接用於具有可用於POS標記,NER和依賴性解析的三個任務的其他語言,以及可從Transformers提供的基於BERT的BERT語言模型(Eg Bert,Mert,Robert,Roberta,XLM-Roberta,XLM-Roberta)。
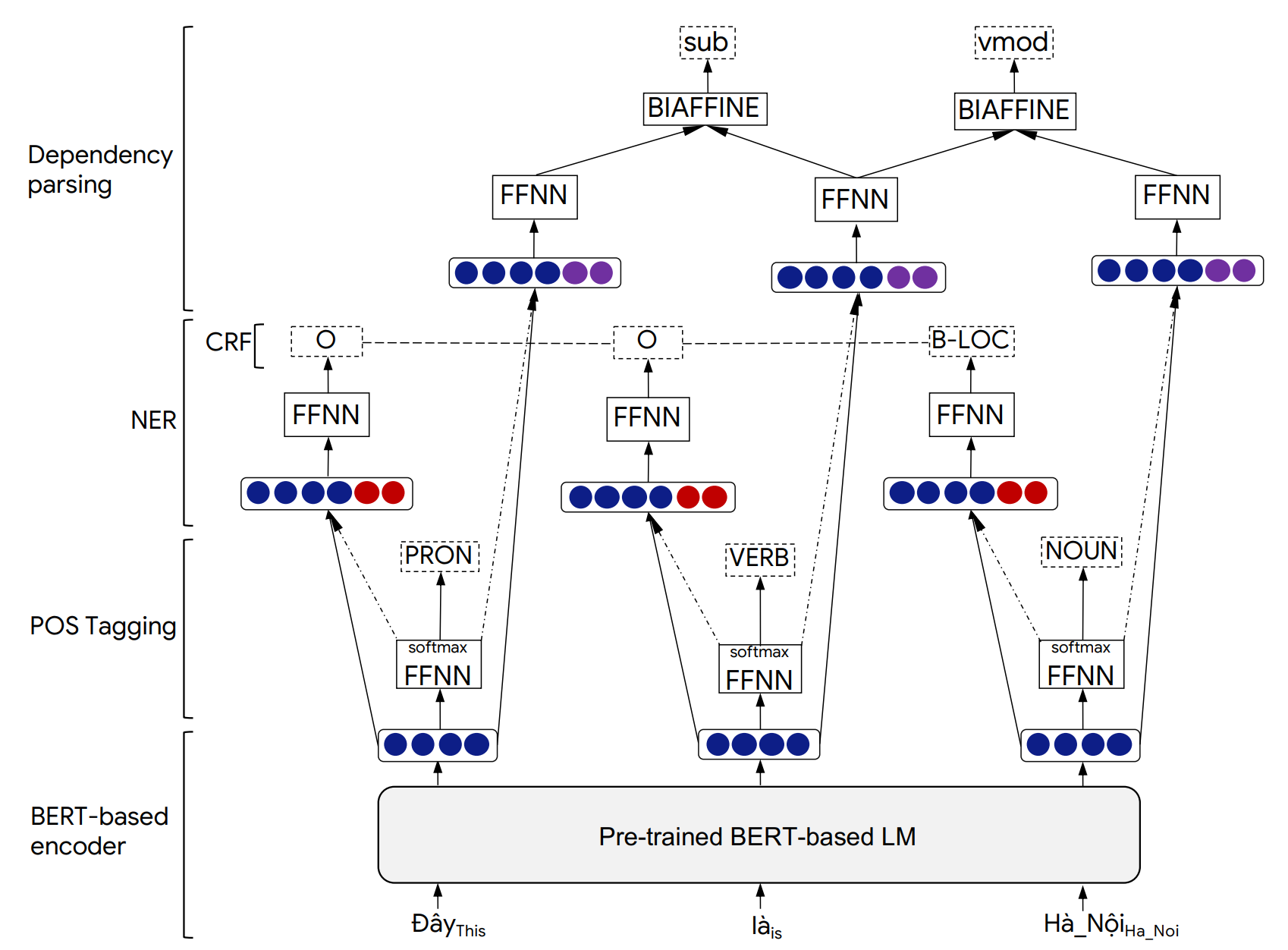
PHONLP模型體系結構的詳細信息和實驗結果可以在我們的下文中找到:
@inproceedings{phonlp,
title = {{PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing}},
author = {Linh The Nguyen and Dat Quoc Nguyen},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations},
pages = {1--7},
year = {2021}
}
當使用PhonLP用來幫助產生已發布的結果或合併到其他軟件中時,請引用我們的論文。
pip pip3 install phonlp install Phonlp git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
要使用命令行播放示例,請從源安裝phonlp :
git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir <model_folder_path>
--pretrained_lm <transformers_pretrained_model>
--lr <float_value> --batch_size <int_value> --num_epoch <int_value>
--lambda_pos <float_value> --lambda_ner <float_value> --lambda_dep <float_value>
--train_file_pos <path_to_training_file_pos> --eval_file_pos <path_to_validation_file_pos>
--train_file_ner <path_to_training_file_ner> --eval_file_ner <path_to_validation_file_ner>
--train_file_dep <path_to_training_file_dep> --eval_file_dep <path_to_validation_file_dep>
--lambda_pos , --lambda_ner和--lambda_dep分別代表與POS標記,NER和依賴關係解析損失相關的混合物權重,以及lambda_pos + lambda_ner + lambda_dep = 1 。
例子:
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir ./phonlp_tmp
--pretrained_lm "vinai/phobert-base"
--lr 1e-5 --batch_size 32 --num_epoch 40
--lambda_pos 0.4 --lambda_ner 0.2 --lambda_dep 0.4
--train_file_pos ../sample_data/pos_train.txt --eval_file_pos ../sample_data/pos_valid.txt
--train_file_ner ../sample_data/ner_train.txt --eval_file_ner ../sample_data/ner_valid.txt
--train_file_dep ../sample_data/dep_train.conll --eval_file_dep ../sample_data/dep_valid.conll
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir <model_folder_path>
--batch_size <int_value>
--eval_file_pos <path_to_test_file_pos>
--eval_file_ner <path_to_test_file_ner>
--eval_file_dep <path_to_test_file_dep>
例子:
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir ./phonlp_tmp
--batch_size 8
--eval_file_pos ../sample_data/pos_test.txt
--eval_file_ner ../sample_data/ner_test.txt
--eval_file_dep ../sample_data/dep_test.conll
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir <model_folder_path>
--batch_size <int_value>
--input_file <path_to_input_file>
--output_file <path_to_output_file>
例子:
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir ./phonlp_tmp
--batch_size 8
--input_file ../sample_data/input.txt
--output_file ../sample_data/output.txt
import phonlp
# Load the trained PhoNLP model
model = phonlp . load ( save_dir = '/absolute/path/to/phonlp_tmp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))默認情況下,每個輸入句子的輸出均使用6列的格式,代表單詞索引,單詞形式,pos tag,ner標籤,當前單詞的頭部索引及其依賴關係類型:
1 Tôi P O 3 sub
2 đang R O 3 adv
3 làm_việc V O 0 root
4 tại E O 3 loc
5 VinAI Np B-ORG 4 prob
6 . CH O 3 punct
可以按照10列孔格式將輸出格式化,其中最後一列用於表示NER預測。這可以通過將output_type='conll'添加到model.annotate()函數中來完成。
另外,在model.annotate()函數中,可以調整參數batch_size的值以適合計算機的內存,而不是在1處使用默認值( batch_size=1 )。在這裡,較大的batch_size會導致更快的性能速度。
import phonlp
# Automatically download the pre-trained PhoNLP model for Vietnamese
# and save it in a local machine folder
phonlp . download ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Load the pre-trained PhoNLP model for Vietnamese
model = phonlp . load ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))如果輸入越南文本是raw ,即沒有單詞和句子進行分割,則必須應用一個單詞分段器來產生單詞分段的句子,然後再送給越南人的預訓練的Phonlp模型。用戶應使用VNCORENLP執行單詞和句子細分(因為它會產生與POS標記,NER和依賴性解析任務的數據相同的越南語調歸一化)。
pip3 install py_vncorenlp
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local machine folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP for word and sentence segmentation
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
# Perform word and sentence segmentation
print ( rdrsegmenter . word_segment ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .']

