PhoNLP
1.0.0

PhonLP ist ein Multi-Task-Lernmodell für das gemeinsame Tagging (POS) -Pos-Speech (POS), die genannte Entitätserkennung (NER) und die Abhängigkeitsanalyse. Experimente zu vietnamesischen Benchmark-Datensätzen zeigen, dass PHONLP hochmoderne Ergebnisse erzeugt und einen Lernansatz für Einzelaufgaben übertrifft, der das vorgebliebene vietnamesische Sprachmodell-Phobert für jede Aufgabe fein abstimmt.
Obwohl wir PhonLP auf Vietnamesisch bewerten, können unsere nachstehenden Nutzungsbeispiele direkt für andere Sprachen funktionieren, in denen goldene Korpora für die drei Aufgaben von POS-Tagging, NER- und Abhängigkeitsanalysen und einem vorgebildeten Bert-basierten Sprachmodell (z. B. Bert, Mbert, Roberta, XLM-Roberta) verfügbar sind.
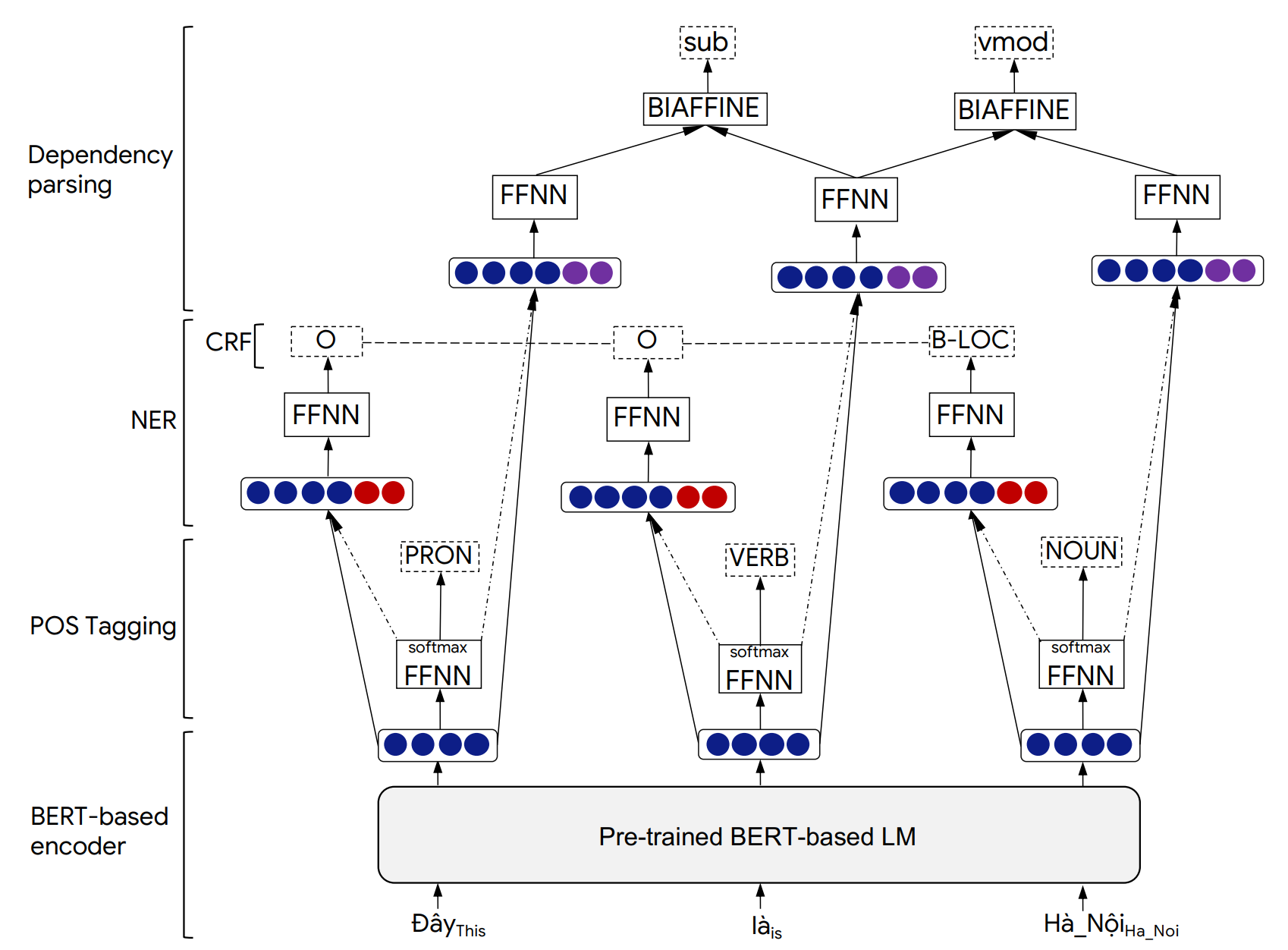
Details der PhonLP -Modellarchitektur und der experimentellen Ergebnisse finden Sie in unserem folgenden Artikel:
@inproceedings{phonlp,
title = {{PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing}},
author = {Linh The Nguyen and Dat Quoc Nguyen},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations},
pages = {1--7},
year = {2021}
}
Bitte zitieren Sie unser Papier, wenn PhonLP verwendet wird, um veröffentlichte Ergebnisse zu erstellen oder in andere Software integriert zu werden.
pip installiert werden: pip3 install phonlp git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
Um mit den Beispielleitungen mit den Beispielen zu spielen, installieren Sie bitte phonlp aus der Quelle:
git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir <model_folder_path>
--pretrained_lm <transformers_pretrained_model>
--lr <float_value> --batch_size <int_value> --num_epoch <int_value>
--lambda_pos <float_value> --lambda_ner <float_value> --lambda_dep <float_value>
--train_file_pos <path_to_training_file_pos> --eval_file_pos <path_to_validation_file_pos>
--train_file_ner <path_to_training_file_ner> --eval_file_ner <path_to_validation_file_ner>
--train_file_dep <path_to_training_file_dep> --eval_file_dep <path_to_validation_file_dep>
--lambda_pos , --lambda_ner und --lambda_dep repräsentieren Mischgewichte, die mit POS-Tagging, Ner- und Abhängigkeits-Parsen-Verlusten verbunden sind, und lambda_pos + lambda_ner + lambda_dep = 1 .
Beispiel:
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir ./phonlp_tmp
--pretrained_lm "vinai/phobert-base"
--lr 1e-5 --batch_size 32 --num_epoch 40
--lambda_pos 0.4 --lambda_ner 0.2 --lambda_dep 0.4
--train_file_pos ../sample_data/pos_train.txt --eval_file_pos ../sample_data/pos_valid.txt
--train_file_ner ../sample_data/ner_train.txt --eval_file_ner ../sample_data/ner_valid.txt
--train_file_dep ../sample_data/dep_train.conll --eval_file_dep ../sample_data/dep_valid.conll
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir <model_folder_path>
--batch_size <int_value>
--eval_file_pos <path_to_test_file_pos>
--eval_file_ner <path_to_test_file_ner>
--eval_file_dep <path_to_test_file_dep>
Beispiel:
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir ./phonlp_tmp
--batch_size 8
--eval_file_pos ../sample_data/pos_test.txt
--eval_file_ner ../sample_data/ner_test.txt
--eval_file_dep ../sample_data/dep_test.conll
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir <model_folder_path>
--batch_size <int_value>
--input_file <path_to_input_file>
--output_file <path_to_output_file>
Beispiel:
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir ./phonlp_tmp
--batch_size 8
--input_file ../sample_data/input.txt
--output_file ../sample_data/output.txt
import phonlp
# Load the trained PhoNLP model
model = phonlp . load ( save_dir = '/absolute/path/to/phonlp_tmp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))Standardmäßig ist die Ausgabe für jeden Eingangssatz mit 6 Spalten formatiert, die Word -Index, Wortform, POS -Tag, NER -Label, Kopfindex des aktuellen Wortes und dessen Abhängigkeitsbeziehungstyp darstellen:
1 Tôi P O 3 sub
2 đang R O 3 adv
3 làm_việc V O 0 root
4 tại E O 3 loc
5 VinAI Np B-ORG 4 prob
6 . CH O 3 punct
Der Ausgang kann nach dem 10-Spal-Conll-Format formatiert werden, wobei die letzte Spalte zur Darstellung von NER-Vorhersagen verwendet wird. Dies kann durch Hinzufügen von output_type='conll' in die Funktion model.annotate() erfolgen.
Außerdem kann der Wert des Parameters batch_size in der Funktion model.annotate() so eingestellt werden, dass sie den Speicher Ihres Computers entspricht, anstatt die Standardeinstellung bei 1 zu verwenden ( batch_size=1 ). Hier würde ein größerer batch_size zu einer schnelleren Leistungsgeschwindigkeit führen.
import phonlp
# Automatically download the pre-trained PhoNLP model for Vietnamese
# and save it in a local machine folder
phonlp . download ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Load the pre-trained PhoNLP model for Vietnamese
model = phonlp . load ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." )) Falls die vietnamesischen Eingaben raw sind, dh ohne Wort- und Satzsegmentierung muss ein Wortsegmentierer angewendet werden, um mit wortsegmentierten Sätzen zu erzeugen, bevor das vorgebrachte Phonlp-Modell für Vietnamesen füttert. Benutzer sollten VNCorenLP verwenden, um eine Wort- und Satzsegmentierung durchzuführen (da sie dieselbe vietnamesische Tonnormalisierung erzeugt, die auf die Daten des POS -Tagging-, NER- und Abhängigkeits -Parsing -Aufgaben angewendet wurde).
pip3 install py_vncorenlp
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local machine folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP for word and sentence segmentation
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
# Perform word and sentence segmentation
print ( rdrsegmenter . word_segment ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .']

