PhoNLP
1.0.0

PHONLP-это многозадачная модель обучения для совместной части речи (POS), названного распознавания сущности (NER) и анализа зависимостей. Эксперименты по вьетнамским наборам данных базовых данных показывают, что Phonlp дает современные результаты, опережая одно задача подход к обучению, который настраивает предварительно обученную модель вьетнамского языка Phobert для каждой задачи независимо.
Несмотря на то, что мы оцениваем Phonlp на вьетнамском языке, наши примеры использования, приведенные ниже, могут непосредственно работать для других языков, в которых есть золотые аннотированные корпорации, доступные для трех задач тегинга POS, анализа NER и зависимости, а также предварительно обученную языковую модель на основе BERT, доступные от Transformers (EG Bert, Mbert, Roberta, XLM-Roberta).
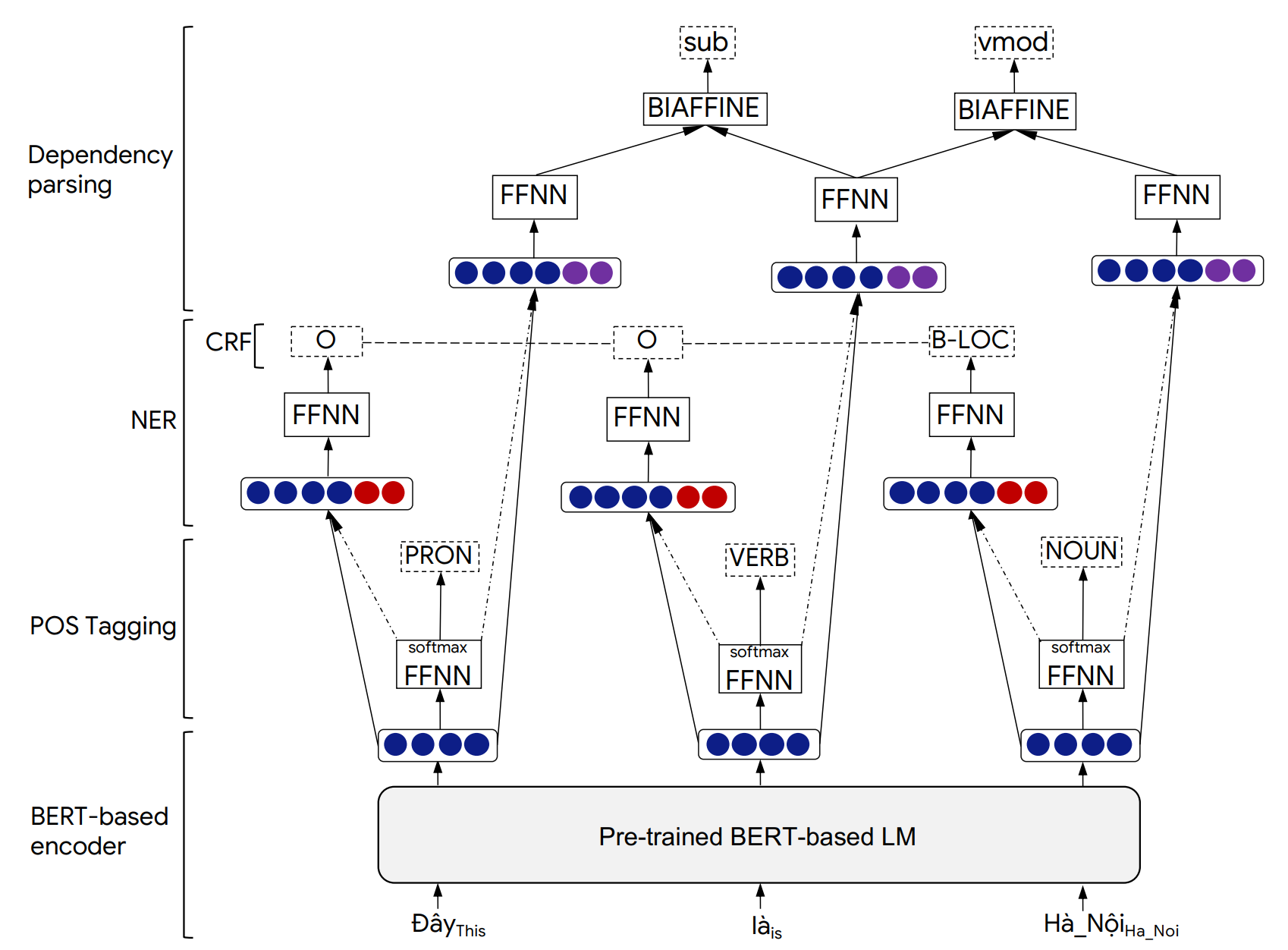
Подробности архитектуры модели Phonlp и экспериментальных результатов можно найти в нашей следующей статье:
@inproceedings{phonlp,
title = {{PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing}},
author = {Linh The Nguyen and Dat Quoc Nguyen},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations},
pages = {1--7},
year = {2021}
}
Пожалуйста, процитируйте нашу статью, когда Phonlp используется, чтобы помочь представить опубликованные результаты или включить в другое программное обеспечение.
pip следующим образом: pip3 install phonlp git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
Чтобы играть с примерами, используя командные строки, установите phonlp из источника:
git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir <model_folder_path>
--pretrained_lm <transformers_pretrained_model>
--lr <float_value> --batch_size <int_value> --num_epoch <int_value>
--lambda_pos <float_value> --lambda_ner <float_value> --lambda_dep <float_value>
--train_file_pos <path_to_training_file_pos> --eval_file_pos <path_to_validation_file_pos>
--train_file_ner <path_to_training_file_ner> --eval_file_ner <path_to_validation_file_ner>
--train_file_dep <path_to_training_file_dep> --eval_file_dep <path_to_validation_file_dep>
--lambda_pos , --lambda_ner и --lambda_dep представляют веса смеси, связанные с потерей POS, NER и потерь диапазона зависимости, соответственно, и lambda_pos + lambda_ner + lambda_dep = 1 .
Пример:
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir ./phonlp_tmp
--pretrained_lm "vinai/phobert-base"
--lr 1e-5 --batch_size 32 --num_epoch 40
--lambda_pos 0.4 --lambda_ner 0.2 --lambda_dep 0.4
--train_file_pos ../sample_data/pos_train.txt --eval_file_pos ../sample_data/pos_valid.txt
--train_file_ner ../sample_data/ner_train.txt --eval_file_ner ../sample_data/ner_valid.txt
--train_file_dep ../sample_data/dep_train.conll --eval_file_dep ../sample_data/dep_valid.conll
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir <model_folder_path>
--batch_size <int_value>
--eval_file_pos <path_to_test_file_pos>
--eval_file_ner <path_to_test_file_ner>
--eval_file_dep <path_to_test_file_dep>
Пример:
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir ./phonlp_tmp
--batch_size 8
--eval_file_pos ../sample_data/pos_test.txt
--eval_file_ner ../sample_data/ner_test.txt
--eval_file_dep ../sample_data/dep_test.conll
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir <model_folder_path>
--batch_size <int_value>
--input_file <path_to_input_file>
--output_file <path_to_output_file>
Пример:
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir ./phonlp_tmp
--batch_size 8
--input_file ../sample_data/input.txt
--output_file ../sample_data/output.txt
import phonlp
# Load the trained PhoNLP model
model = phonlp . load ( save_dir = '/absolute/path/to/phonlp_tmp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))По умолчанию выход для каждого входного предложения отформатируется с 6 столбцами, представляющими индекс слов, форму слова, тег POS, метка NER, индекс головки текущего слова и тип его зависимости:
1 Tôi P O 3 sub
2 đang R O 3 adv
3 làm_việc V O 0 root
4 tại E O 3 loc
5 VinAI Np B-ORG 4 prob
6 . CH O 3 punct
Выход может быть отформатирован после формата Conll из 10-колонны, где последний столбец используется для представления NER прогнозов. Это можно сделать, добавив output_type='conll' в функцию model.annotate() .
Кроме того, в функции model.annotate() значение параметра batch_size может быть настроено так, чтобы соответствовать памяти вашего компьютера вместо использования по умолчанию в 1 ( batch_size=1 ). Здесь более крупная batch_size приведет к более высокой скорости производительности.
import phonlp
# Automatically download the pre-trained PhoNLP model for Vietnamese
# and save it in a local machine folder
phonlp . download ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Load the pre-trained PhoNLP model for Vietnamese
model = phonlp . load ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." )) В случае, если входные вьетнамские тексты являются raw , т. Е. Без сегментации слов и предложений, сегмент слов должен применяться для создания предложений, сегментированных словом, перед тем, как питаться предварительно обученной моделью PHONLP для вьетнамцев. Пользователи должны использовать vncorenlp для выполнения сегментации слов и предложений (поскольку он создает ту же нормизацию вьетнамской тона, которая была применена к данным Tagging, NER и задач анализа зависимостей).
pip3 install py_vncorenlp
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local machine folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP for word and sentence segmentation
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
# Perform word and sentence segmentation
print ( rdrsegmenter . word_segment ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .']

