PhoNLP
1.0.0

PHONLP es un modelo de aprendizaje de tareas múltiples para etiquetado conjunto de piuta (POS), reconocimiento de entidad nombrado (NER) y análisis de dependencia. Los experimentos en los conjuntos de datos de referencia vietnamitas muestran que PhonLP produce resultados de última generación, superando un enfoque de aprendizaje de una sola tarea que ajusta el modelo de lenguaje vietnamita previamente entrenado para cada tarea de forma independiente.
Aunque evaluamos PHONLP en los vietnamitas, nuestros ejemplos de uso a continuación pueden funcionar directamente para otros idiomas que tienen corpus anotados con oro disponibles para las tres tareas de etiquetado POS, análisis de dependencia y dependencia, y un modelo de idioma basado en Bert previamente capacitado disponible de Transformers (por ejemplo, BERT, MBERT, ROBERTA, XLM-ROBERTA).
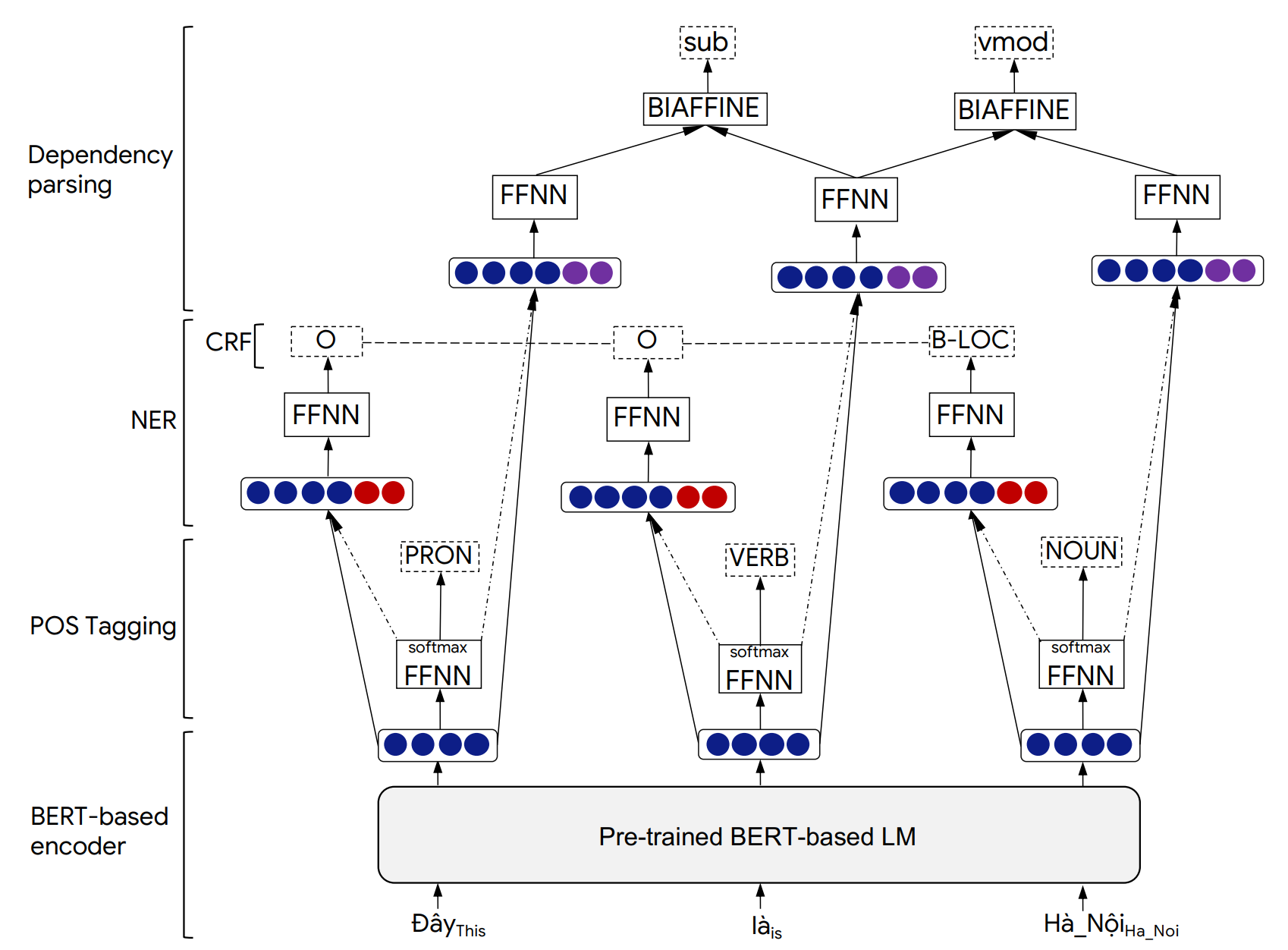
Los detalles de la arquitectura del modelo PHONLP y los resultados experimentales se pueden encontrar en nuestro siguiente documento:
@inproceedings{phonlp,
title = {{PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing}},
author = {Linh The Nguyen and Dat Quoc Nguyen},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations},
pages = {1--7},
year = {2021}
}
Cite nuestro documento cuando PhonLP se usa para ayudar a producir resultados publicados o incorporados en otro software.
pip de la siguiente manera: pip3 install phonlp git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
Para jugar con los ejemplos utilizando líneas de comando, instale phonlp desde la fuente:
git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir <model_folder_path>
--pretrained_lm <transformers_pretrained_model>
--lr <float_value> --batch_size <int_value> --num_epoch <int_value>
--lambda_pos <float_value> --lambda_ner <float_value> --lambda_dep <float_value>
--train_file_pos <path_to_training_file_pos> --eval_file_pos <path_to_validation_file_pos>
--train_file_ner <path_to_training_file_ner> --eval_file_ner <path_to_validation_file_ner>
--train_file_dep <path_to_training_file_dep> --eval_file_dep <path_to_validation_file_dep>
--lambda_pos , --lambda_ner y --lambda_dep representan pesos de mezcla asociados con el etiquetado POS, las pérdidas de análisis de dependencia y dependencia, respectivamente, y lambda_pos + lambda_ner + lambda_dep = 1 .
Ejemplo:
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir ./phonlp_tmp
--pretrained_lm "vinai/phobert-base"
--lr 1e-5 --batch_size 32 --num_epoch 40
--lambda_pos 0.4 --lambda_ner 0.2 --lambda_dep 0.4
--train_file_pos ../sample_data/pos_train.txt --eval_file_pos ../sample_data/pos_valid.txt
--train_file_ner ../sample_data/ner_train.txt --eval_file_ner ../sample_data/ner_valid.txt
--train_file_dep ../sample_data/dep_train.conll --eval_file_dep ../sample_data/dep_valid.conll
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir <model_folder_path>
--batch_size <int_value>
--eval_file_pos <path_to_test_file_pos>
--eval_file_ner <path_to_test_file_ner>
--eval_file_dep <path_to_test_file_dep>
Ejemplo:
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir ./phonlp_tmp
--batch_size 8
--eval_file_pos ../sample_data/pos_test.txt
--eval_file_ner ../sample_data/ner_test.txt
--eval_file_dep ../sample_data/dep_test.conll
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir <model_folder_path>
--batch_size <int_value>
--input_file <path_to_input_file>
--output_file <path_to_output_file>
Ejemplo:
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir ./phonlp_tmp
--batch_size 8
--input_file ../sample_data/input.txt
--output_file ../sample_data/output.txt
import phonlp
# Load the trained PhoNLP model
model = phonlp . load ( save_dir = '/absolute/path/to/phonlp_tmp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))De manera predeterminada, la salida para cada oración de entrada está formateada con 6 columnas que representan el índice de palabras, formulario de palabras, etiqueta POS, etiqueta ner, índice de cabeza de la palabra actual y su tipo de relación de dependencia:
1 Tôi P O 3 sub
2 đang R O 3 adv
3 làm_việc V O 0 root
4 tại E O 3 loc
5 VinAI Np B-ORG 4 prob
6 . CH O 3 punct
La salida se puede formatear después del formato Conll de 10 columnas donde se usa la última columna para representar predicciones NER. Esto se puede hacer agregando output_type='conll' en la función model.annotate() .
Además, en la función model.annotate() , el valor del parámetro batch_size se puede ajustar para que se ajuste a la memoria de su computadora en lugar de usar el predeterminado en 1 ( batch_size=1 ). Aquí, un batch_size más grande conduciría a una velocidad de rendimiento más rápida.
import phonlp
# Automatically download the pre-trained PhoNLP model for Vietnamese
# and save it in a local machine folder
phonlp . download ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Load the pre-trained PhoNLP model for Vietnamese
model = phonlp . load ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." )) En caso de que los textos vietnamitas de entrada sean raw , es decir, sin segmentación de palabras y oraciones, se debe aplicar un segmento de palabras para producir oraciones segmentadas por palabras antes de alimentarse al modelo PhonLP previamente capacitado para vietnamitas. Los usuarios deben usar VNCORENLP para realizar la segmentación de palabras y oraciones (ya que produce la misma normalización de tono vietnamita que se aplicó a los datos de las tareas de análisis de etiquetas, NER y dependencia).
pip3 install py_vncorenlp
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local machine folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP for word and sentence segmentation
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
# Perform word and sentence segmentation
print ( rdrsegmenter . word_segment ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .']

