PhoNLP
1.0.0

O PHONLP é um modelo de aprendizado de várias tarefas para marcação de partida conjunta (POS), denominado reconhecimento de entidade (NER) e análise de dependência. Experimentos sobre conjuntos de dados de referência vietnamita mostram que a PHONLP produz resultados de última geração, superando uma abordagem de aprendizado de tarefa única que ajusta o modelo de idioma vietnamita pré-treinado para cada tarefa de forma independente.
Embora avaliemos o PHONLP em vietnamita, nossos exemplos de uso abaixo podem trabalhar diretamente para outros idiomas que possuem corpora anotada em ouro disponíveis para as três tarefas de marcação de POS, NER e análise de dependência e um modelo de linguagem baseado em Bert pré-treinado disponível em Transformers (EG Bert, Mbert, Roberta, XLM-Roberta).
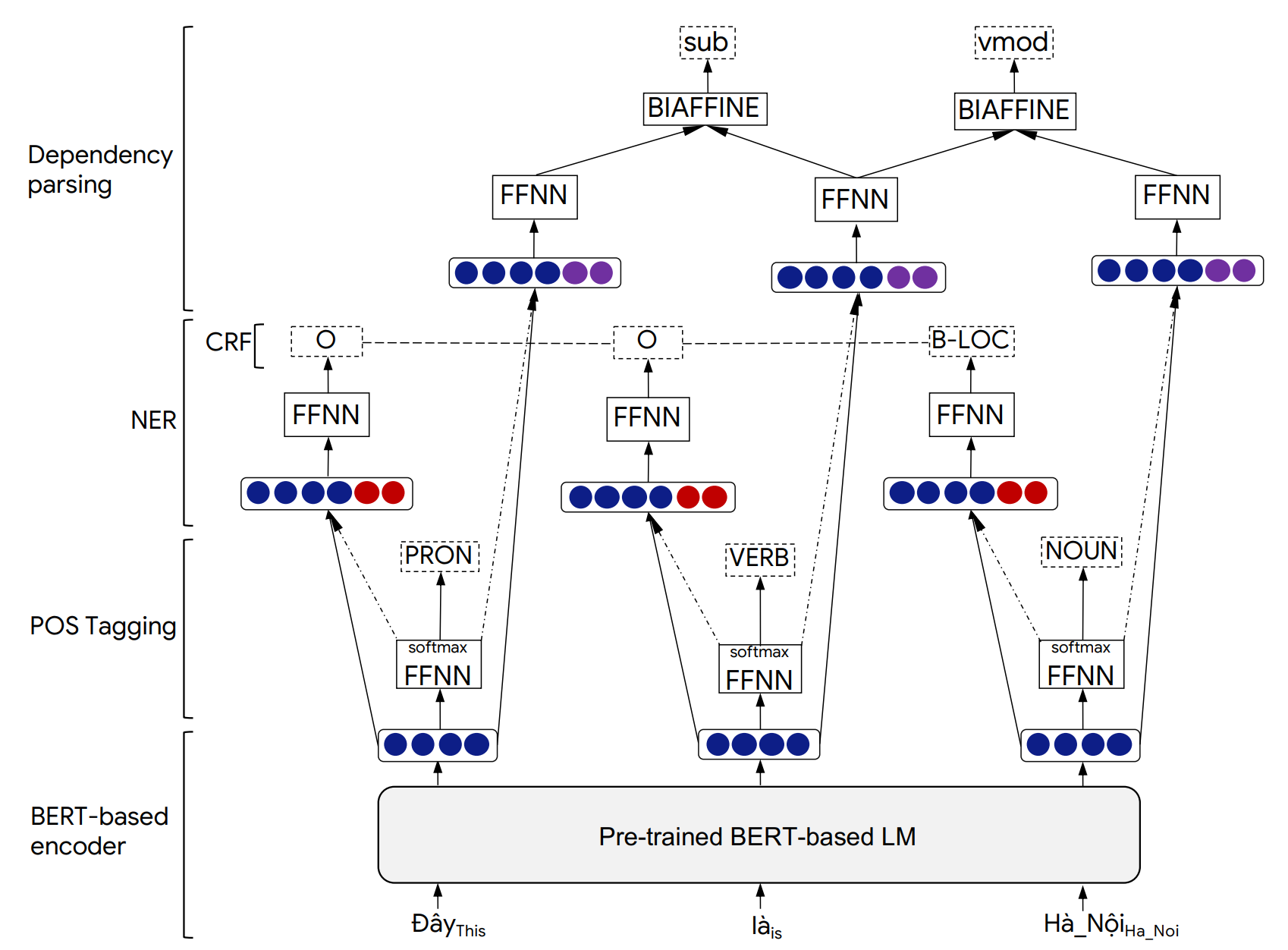
Detalhes da arquitetura do modelo PHONLP e resultados experimentais podem ser encontrados em nosso artigo a seguir:
@inproceedings{phonlp,
title = {{PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing}},
author = {Linh The Nguyen and Dat Quoc Nguyen},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations},
pages = {1--7},
year = {2021}
}
Cite nosso artigo quando o PHONLP for usado para ajudar a produzir resultados publicados ou incorporado a outro software.
pip da pip3 install phonlp git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
Para brincar com os exemplos usando linhas de comando, instale phonlp na fonte:
git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir <model_folder_path>
--pretrained_lm <transformers_pretrained_model>
--lr <float_value> --batch_size <int_value> --num_epoch <int_value>
--lambda_pos <float_value> --lambda_ner <float_value> --lambda_dep <float_value>
--train_file_pos <path_to_training_file_pos> --eval_file_pos <path_to_validation_file_pos>
--train_file_ner <path_to_training_file_ner> --eval_file_ner <path_to_validation_file_ner>
--train_file_dep <path_to_training_file_dep> --eval_file_dep <path_to_validation_file_dep>
--lambda_pos , --lambda_ner e --lambda_dep representam pesos de mistura associados à marcação de POS, NER e perdas de análise de dependência, respectivamente, e lambda_pos + lambda_ner + lambda_dep = 1 .
Exemplo:
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir ./phonlp_tmp
--pretrained_lm "vinai/phobert-base"
--lr 1e-5 --batch_size 32 --num_epoch 40
--lambda_pos 0.4 --lambda_ner 0.2 --lambda_dep 0.4
--train_file_pos ../sample_data/pos_train.txt --eval_file_pos ../sample_data/pos_valid.txt
--train_file_ner ../sample_data/ner_train.txt --eval_file_ner ../sample_data/ner_valid.txt
--train_file_dep ../sample_data/dep_train.conll --eval_file_dep ../sample_data/dep_valid.conll
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir <model_folder_path>
--batch_size <int_value>
--eval_file_pos <path_to_test_file_pos>
--eval_file_ner <path_to_test_file_ner>
--eval_file_dep <path_to_test_file_dep>
Exemplo:
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir ./phonlp_tmp
--batch_size 8
--eval_file_pos ../sample_data/pos_test.txt
--eval_file_ner ../sample_data/ner_test.txt
--eval_file_dep ../sample_data/dep_test.conll
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir <model_folder_path>
--batch_size <int_value>
--input_file <path_to_input_file>
--output_file <path_to_output_file>
Exemplo:
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir ./phonlp_tmp
--batch_size 8
--input_file ../sample_data/input.txt
--output_file ../sample_data/output.txt
import phonlp
# Load the trained PhoNLP model
model = phonlp . load ( save_dir = '/absolute/path/to/phonlp_tmp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))Por padrão, a saída para cada frase de entrada é formatada com 6 colunas representando o índice de palavras, formulário de palavras, tag POS, etiqueta ner, índice de cabeça da palavra atual e seu tipo de relação de dependência:
1 Tôi P O 3 sub
2 đang R O 3 adv
3 làm_việc V O 0 root
4 tại E O 3 loc
5 VinAI Np B-ORG 4 prob
6 . CH O 3 punct
A saída pode ser formatada após o formato Conll de 10 colunas, onde a última coluna é usada para representar as previsões do NER. Isso pode ser feito adicionando output_type='conll' na função model.annotate() .
Além disso, na função model.annotate() , o valor do parâmetro batch_size pode ser ajustado para se ajustar à memória do seu computador em vez de usar o padrão em 1 ( batch_size=1 ). Aqui, um batch_size maior levaria a uma velocidade de desempenho mais rápida.
import phonlp
# Automatically download the pre-trained PhoNLP model for Vietnamese
# and save it in a local machine folder
phonlp . download ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Load the pre-trained PhoNLP model for Vietnamese
model = phonlp . load ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." )) Caso os textos vietnamitas de entrada sejam raw , ou seja, sem segmentação de palavras e frases, um segmento de palavras deve ser aplicado para produzir frases segmentadas por palavras antes de se alimentar para o modelo de telefone pré-treinado para vietnamita. Os usuários devem usar o VncorenLP para executar a segmentação de palavras e frases (pois produz a mesma normalização do tom vietnamita que foi aplicada aos dados das tarefas de marcação de POS, NER e de análise de dependência).
pip3 install py_vncorenlp
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local machine folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP for word and sentence segmentation
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
# Perform word and sentence segmentation
print ( rdrsegmenter . word_segment ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .']

