PhoNLP
1.0.0

PhonLP est un modèle d'apprentissage multi-tâches pour le marquage conjoint de la partie de la disposition (POS), la reconnaissance d'entité nommée (NER) et l'analyse de dépendance. Des expériences sur les ensembles de données de référence vietnamiens montrent que PhonLP produit des résultats de pointe, surpassant une approche d'apprentissage à une seule tâche qui affine le modèle de langue vietnamienne pré-formée Phobert pour chaque tâche indépendamment.
Bien que nous évaluions PhonLP sur les vietnamiens, nos exemples d'utilisation ci-dessous peuvent fonctionner directement pour d'autres langues qui ont des corpus annotés en or disponibles pour les trois tâches de Tagging POS, NER et analyse de dépendance, et un modèle de langue basé sur Bert pré-formé disponible auprès de Transformers (par exemple Bert, Mbert, Roberta, XLM-Roberta).
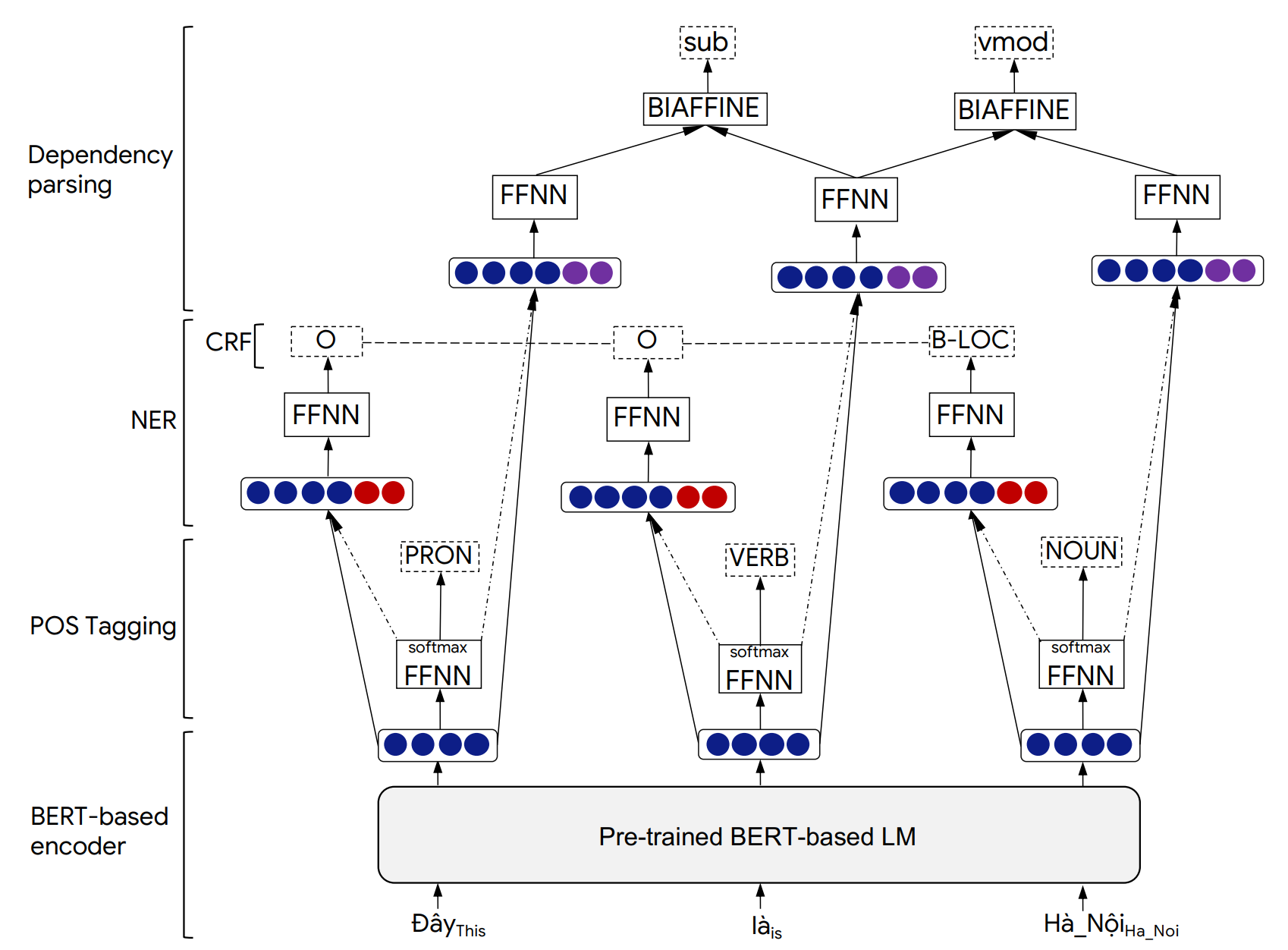
Les détails de l'architecture du modèle PhonLP et des résultats expérimentaux peuvent être trouvés dans notre article suivant:
@inproceedings{phonlp,
title = {{PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing}},
author = {Linh The Nguyen and Dat Quoc Nguyen},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations},
pages = {1--7},
year = {2021}
}
Veuillez citer notre article lorsque PhonLP est utilisé pour aider à produire des résultats publiés ou incorporés dans d'autres logiciels.
pip comme suit: pip3 install phonlp git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
Pour jouer avec les exemples à l'aide de lignes de commande, veuillez installer phonlp à partir de la source:
git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir <model_folder_path>
--pretrained_lm <transformers_pretrained_model>
--lr <float_value> --batch_size <int_value> --num_epoch <int_value>
--lambda_pos <float_value> --lambda_ner <float_value> --lambda_dep <float_value>
--train_file_pos <path_to_training_file_pos> --eval_file_pos <path_to_validation_file_pos>
--train_file_ner <path_to_training_file_ner> --eval_file_ner <path_to_validation_file_ner>
--train_file_dep <path_to_training_file_dep> --eval_file_dep <path_to_validation_file_dep>
--lambda_pos , --lambda_ner et --lambda_dep représente des poids de mélange associés au taggage de POS, aux pertes d'analyse de dépendance et de dépendance, respectivement, et lambda_pos + lambda_ner + lambda_dep = 1 .
Exemple:
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir ./phonlp_tmp
--pretrained_lm "vinai/phobert-base"
--lr 1e-5 --batch_size 32 --num_epoch 40
--lambda_pos 0.4 --lambda_ner 0.2 --lambda_dep 0.4
--train_file_pos ../sample_data/pos_train.txt --eval_file_pos ../sample_data/pos_valid.txt
--train_file_ner ../sample_data/ner_train.txt --eval_file_ner ../sample_data/ner_valid.txt
--train_file_dep ../sample_data/dep_train.conll --eval_file_dep ../sample_data/dep_valid.conll
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir <model_folder_path>
--batch_size <int_value>
--eval_file_pos <path_to_test_file_pos>
--eval_file_ner <path_to_test_file_ner>
--eval_file_dep <path_to_test_file_dep>
Exemple:
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir ./phonlp_tmp
--batch_size 8
--eval_file_pos ../sample_data/pos_test.txt
--eval_file_ner ../sample_data/ner_test.txt
--eval_file_dep ../sample_data/dep_test.conll
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir <model_folder_path>
--batch_size <int_value>
--input_file <path_to_input_file>
--output_file <path_to_output_file>
Exemple:
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir ./phonlp_tmp
--batch_size 8
--input_file ../sample_data/input.txt
--output_file ../sample_data/output.txt
import phonlp
# Load the trained PhoNLP model
model = phonlp . load ( save_dir = '/absolute/path/to/phonlp_tmp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))Par défaut, la sortie pour chaque phrase d'entrée est formatée avec 6 colonnes représentant l'index de mot, le formulaire de mot, la balise POS, l'étiquette NER, l'index de tête du mot actuel et son type de relation de dépendance:
1 Tôi P O 3 sub
2 đang R O 3 adv
3 làm_việc V O 0 root
4 tại E O 3 loc
5 VinAI Np B-ORG 4 prob
6 . CH O 3 punct
La sortie peut être formatée en suivant le format Conll à 10 colonnes où la dernière colonne est utilisée pour représenter les prédictions NER. Cela peut être fait en ajoutant output_type='conll' dans la fonction model.annotate() .
De plus, dans la fonction model.annotate() , la valeur du paramètre batch_size peut être ajustée pour s'adapter à la mémoire de votre ordinateur au lieu d'utiliser la par défaut à 1 ( batch_size=1 ). Ici, un batch_size plus grand conduirait à une vitesse de performance plus rapide.
import phonlp
# Automatically download the pre-trained PhoNLP model for Vietnamese
# and save it in a local machine folder
phonlp . download ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Load the pre-trained PhoNLP model for Vietnamese
model = phonlp . load ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." )) Dans le cas où les textes vietnamiens entrées sont raw , c'est-à-dire sans segmentation des mots et des phrases, un segmentateur de mots doit être appliqué pour produire des phrases à segment des mots avant de se nourrir au modèle PhonLP pré-formé pour le vietnamien. Les utilisateurs doivent utiliser VNCorenlp pour effectuer une segmentation des mots et des phrases (car il produit la même normalisation de tonalité vietnamienne qui a été appliquée aux données des tâches de marquage, NER et de dépendance à la dépendance).
pip3 install py_vncorenlp
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local machine folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP for word and sentence segmentation
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
# Perform word and sentence segmentation
print ( rdrsegmenter . word_segment ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .']

