PhoNLP
1.0.0

PHONLP هو نموذج تعليمي متعدد المهام لعلامة الجزء المشترك لجزء من الكلام (POS) ، والتعرف على الكيان المسماة (NER) وحلية التبعية. تُظهر التجارب على مجموعات البيانات القياسية الفيتنامية أن PHONLP ينتج نتائج حديثة ، تتفوق على نهج تعليمي واحد في المهمة التي تقوم بتشويش نموذج اللغة الفيتنامية التي تم تدريبها قبل كل مهمة بشكل مستقل.
على الرغم من أننا قمنا بتقييم phonlp على الفيتناميين ، إلا أن أمثلة استخدامنا أدناه يمكن أن تعمل بشكل مباشر مع اللغات الأخرى التي تحتوي على شركة مروحة ذهبية متاحة للمهام الثلاث المتمثلة في وضع علامات POS و NER و TEPENCOLING ، ونموذج لغة قائم على BERT قبل التدريب المتاح من المحولات (مثل Bert ، Mbert ، Roberta ، XLM-Roberta).
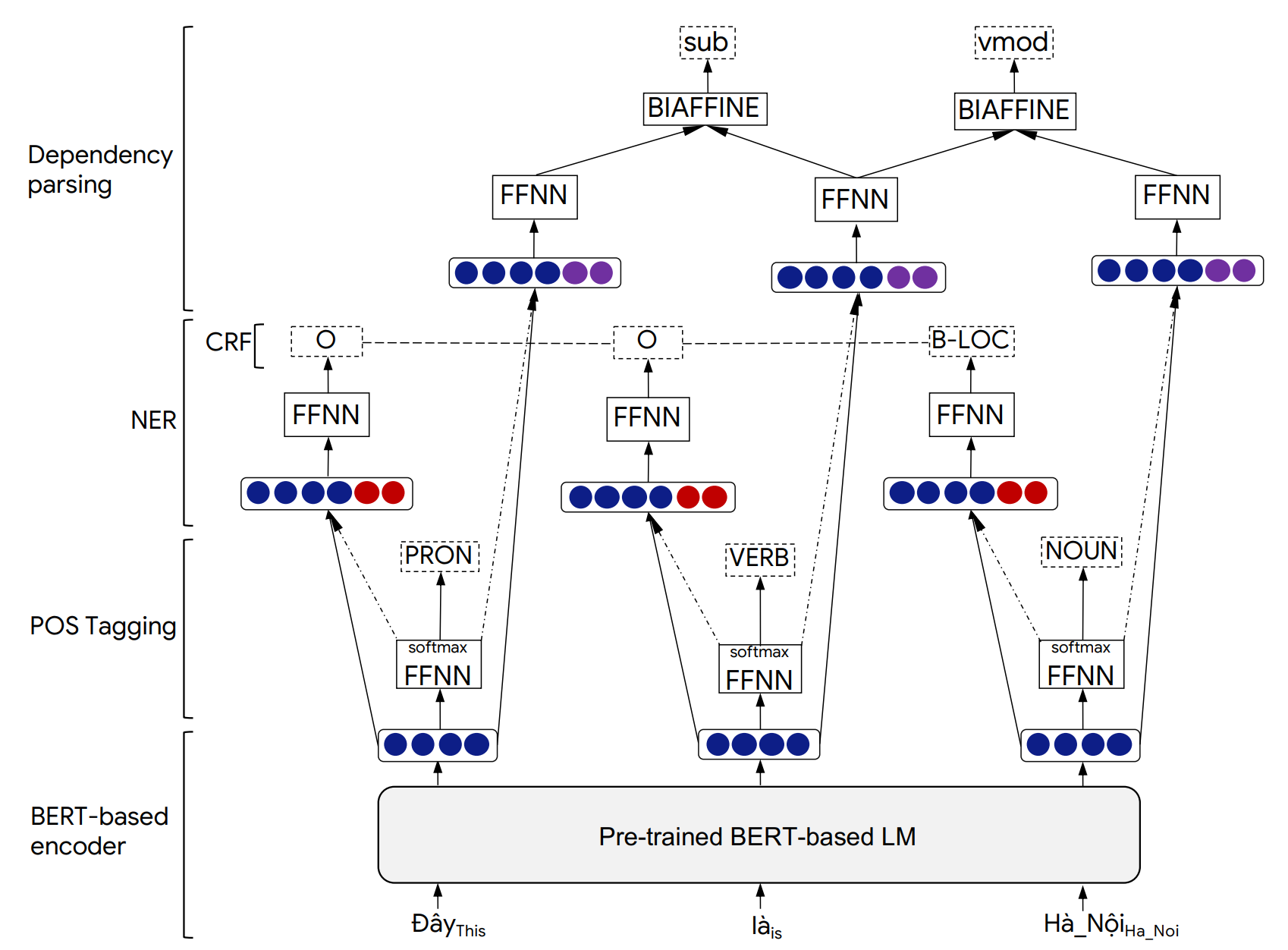
يمكن العثور على تفاصيل بنية نموذج PhonLP والنتائج التجريبية في الورقة التالية:
@inproceedings{phonlp,
title = {{PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing}},
author = {Linh The Nguyen and Dat Quoc Nguyen},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations},
pages = {1--7},
year = {2021}
}
يرجى الاستشهاد بورقنا عند استخدام PhonLP للمساعدة في إنتاج نتائج منشورة أو دمجها في برامج أخرى.
pip على النحو التالي: pip3 install phonlp git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
للعب مع الأمثلة باستخدام خطوط الأوامر ، يرجى تثبيت phonlp من المصدر:
git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir <model_folder_path>
--pretrained_lm <transformers_pretrained_model>
--lr <float_value> --batch_size <int_value> --num_epoch <int_value>
--lambda_pos <float_value> --lambda_ner <float_value> --lambda_dep <float_value>
--train_file_pos <path_to_training_file_pos> --eval_file_pos <path_to_validation_file_pos>
--train_file_ner <path_to_training_file_ner> --eval_file_ner <path_to_validation_file_ner>
--train_file_dep <path_to_training_file_dep> --eval_file_dep <path_to_validation_file_dep>
--lambda_pos ، --lambda_ner و-- --lambda_dep تمثل أوزان الخليط المرتبطة بعلامات نقاط البيع ، وخسائر تحليل التبعية ، على التوالي ، و lambda_pos + lambda_ner + lambda_dep = 1 .
مثال:
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir ./phonlp_tmp
--pretrained_lm "vinai/phobert-base"
--lr 1e-5 --batch_size 32 --num_epoch 40
--lambda_pos 0.4 --lambda_ner 0.2 --lambda_dep 0.4
--train_file_pos ../sample_data/pos_train.txt --eval_file_pos ../sample_data/pos_valid.txt
--train_file_ner ../sample_data/ner_train.txt --eval_file_ner ../sample_data/ner_valid.txt
--train_file_dep ../sample_data/dep_train.conll --eval_file_dep ../sample_data/dep_valid.conll
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir <model_folder_path>
--batch_size <int_value>
--eval_file_pos <path_to_test_file_pos>
--eval_file_ner <path_to_test_file_ner>
--eval_file_dep <path_to_test_file_dep>
مثال:
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir ./phonlp_tmp
--batch_size 8
--eval_file_pos ../sample_data/pos_test.txt
--eval_file_ner ../sample_data/ner_test.txt
--eval_file_dep ../sample_data/dep_test.conll
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir <model_folder_path>
--batch_size <int_value>
--input_file <path_to_input_file>
--output_file <path_to_output_file>
مثال:
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir ./phonlp_tmp
--batch_size 8
--input_file ../sample_data/input.txt
--output_file ../sample_data/output.txt
import phonlp
# Load the trained PhoNLP model
model = phonlp . load ( save_dir = '/absolute/path/to/phonlp_tmp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))بشكل افتراضي ، يتم تنسيق الإخراج لكل جملة إدخال مع 6 أعمدة تمثل فهرس الكلمات ، نموذج Word ، علامة POS ، تسمية ner ، فهرس الرأس للكلمة الحالية ونوع علاقة التبعية:
1 Tôi P O 3 sub
2 đang R O 3 adv
3 làm_việc V O 0 root
4 tại E O 3 loc
5 VinAI Np B-ORG 4 prob
6 . CH O 3 punct
يمكن تنسيق الإخراج بعد تنسيق CONLL 10 عمود حيث يتم استخدام العمود الأخير لتمثيل تنبؤات NER. يمكن القيام بذلك عن طريق إضافة output_type='conll' في وظيفة model.annotate() .
batch_size=1 ، batch_size دالة model.annotate() . هنا ، سيؤدي batch_size الأكبر إلى سرعة أداء أسرع.
import phonlp
# Automatically download the pre-trained PhoNLP model for Vietnamese
# and save it in a local machine folder
phonlp . download ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Load the pre-trained PhoNLP model for Vietnamese
model = phonlp . load ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." )) في حالة وجود النصوص الفيتنامية المدخلات raw ، أي بدون تجزئة كلمة وجملة ، يجب تطبيق مقطع الكلمات لإنتاج جمل مجزأة قبل التغذية لنموذج PhonLP المدربين مسبقًا للفيتناميين. يجب على المستخدمين استخدام VNCorEnLP لأداء تجزئة الكلمات والجمل (حيث ينتج نفس تطبيع النغمة الفيتنامية التي تم تطبيقها على بيانات علامات POS و NER و Opency Railsing).
pip3 install py_vncorenlp
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local machine folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP for word and sentence segmentation
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
# Perform word and sentence segmentation
print ( rdrsegmenter . word_segment ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .']

