PhoNLP
1.0.0

PHONLP는 공동 부품 (POS) 태그, 이름 지정된 엔티티 인식 (NER) 및 종속성 구문 분석을위한 멀티 태스킹 학습 모델입니다. 베트남어 벤치 마크 데이터 세트에 대한 실험에 따르면 Phonlp는 최첨단 결과를 생성하여 각 작업에 대해 미리 훈련 된 베트남어 모델 Phobert를 독립적으로 미세 조명하는 단일 작업 학습 접근 방식을 능가하는 것으로 나타났습니다.
우리는 베트남에서 Phonlp를 평가하지만 아래의 사용 예는 POS 태깅, NER 및 의존성 구문 분석의 세 가지 작업에 대해 금 주석이 달린 Corpora와 Transformers (EG Bert, Mbert, Roberta, XLM-Roberta)에서 이용할 수있는 미리 훈련 된 BERT 기반 언어 모델에 직접 작동 할 수 있습니다.
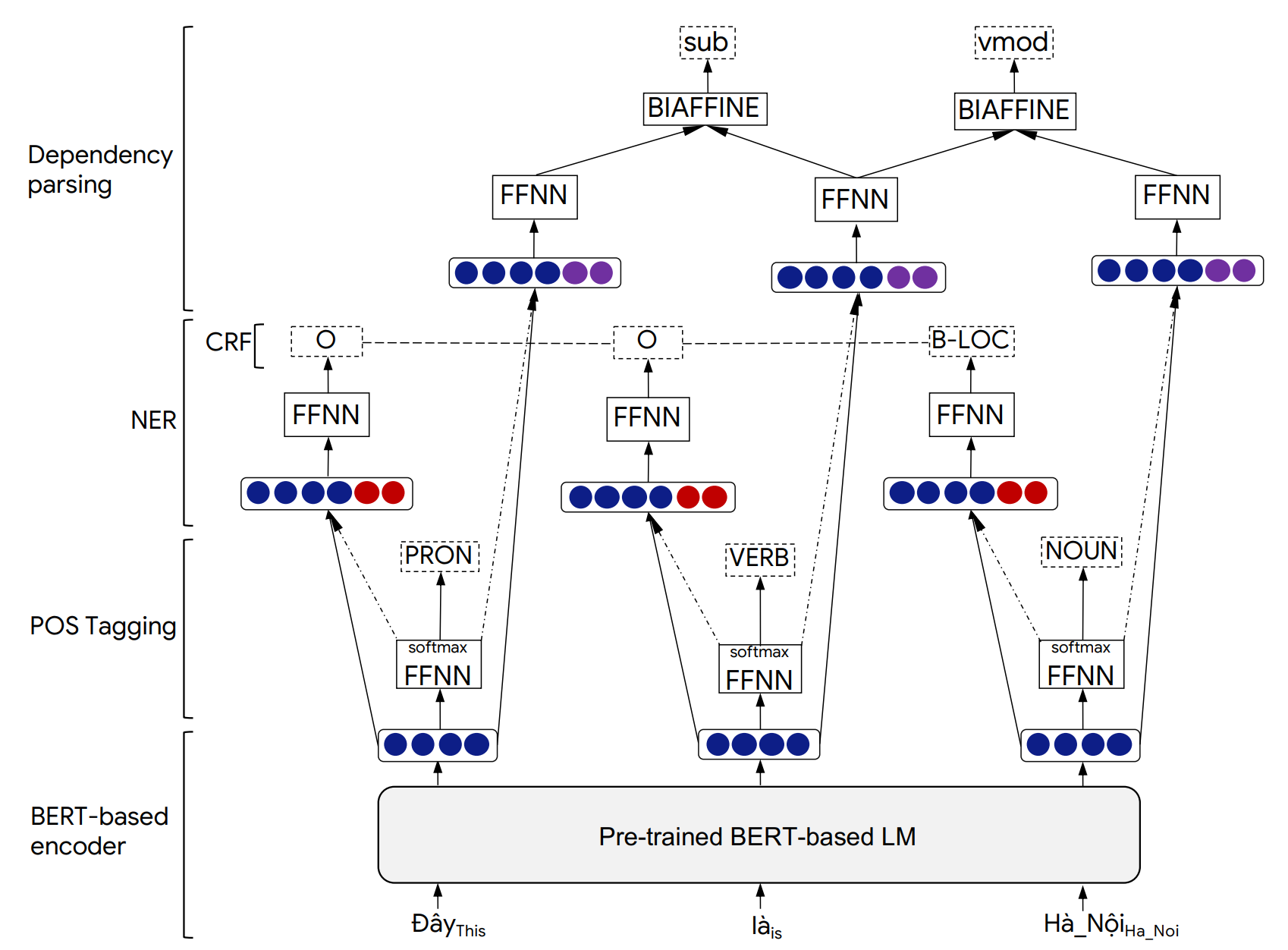
Phonlp 모델 아키텍처 및 실험 결과에 대한 자세한 내용은 다음 논문에서 찾을 수 있습니다.
@inproceedings{phonlp,
title = {{PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing}},
author = {Linh The Nguyen and Dat Quoc Nguyen},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations},
pages = {1--7},
year = {2021}
}
Phonlp가 게시 된 결과를 생성하거나 다른 소프트웨어에 통합하는 데 도움이되면 논문을 인용하십시오 .
pip 사용하여 설치할 수 있습니다 : pip3 install phonlp git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
명령 줄을 사용하여 예제를 사용하려면 소스에서 phonlp 설치하십시오.
git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir <model_folder_path>
--pretrained_lm <transformers_pretrained_model>
--lr <float_value> --batch_size <int_value> --num_epoch <int_value>
--lambda_pos <float_value> --lambda_ner <float_value> --lambda_dep <float_value>
--train_file_pos <path_to_training_file_pos> --eval_file_pos <path_to_validation_file_pos>
--train_file_ner <path_to_training_file_ner> --eval_file_ner <path_to_validation_file_ner>
--train_file_dep <path_to_training_file_dep> --eval_file_dep <path_to_validation_file_dep>
--lambda_pos , --lambda_ner 및 --lambda_dep 각각 pos 태깅, ner 및 종속성 구문 분석 손실, lambda_pos + lambda_ner + lambda_dep = 1 과 관련된 혼합 무게를 나타냅니다.
예:
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir ./phonlp_tmp
--pretrained_lm "vinai/phobert-base"
--lr 1e-5 --batch_size 32 --num_epoch 40
--lambda_pos 0.4 --lambda_ner 0.2 --lambda_dep 0.4
--train_file_pos ../sample_data/pos_train.txt --eval_file_pos ../sample_data/pos_valid.txt
--train_file_ner ../sample_data/ner_train.txt --eval_file_ner ../sample_data/ner_valid.txt
--train_file_dep ../sample_data/dep_train.conll --eval_file_dep ../sample_data/dep_valid.conll
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir <model_folder_path>
--batch_size <int_value>
--eval_file_pos <path_to_test_file_pos>
--eval_file_ner <path_to_test_file_ner>
--eval_file_dep <path_to_test_file_dep>
예:
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir ./phonlp_tmp
--batch_size 8
--eval_file_pos ../sample_data/pos_test.txt
--eval_file_ner ../sample_data/ner_test.txt
--eval_file_dep ../sample_data/dep_test.conll
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir <model_folder_path>
--batch_size <int_value>
--input_file <path_to_input_file>
--output_file <path_to_output_file>
예:
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir ./phonlp_tmp
--batch_size 8
--input_file ../sample_data/input.txt
--output_file ../sample_data/output.txt
import phonlp
# Load the trained PhoNLP model
model = phonlp . load ( save_dir = '/absolute/path/to/phonlp_tmp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))기본적으로 각 입력 문장의 출력은 단어 색인, 단어 양식, POS 태그, NER 레이블, 현재 단어의 헤드 인덱스 및 해당 의존성 관계 유형을 나타내는 6 개의 열로 형식화됩니다.
1 Tôi P O 3 sub
2 đang R O 3 adv
3 làm_việc V O 0 root
4 tại E O 3 loc
5 VinAI Np B-ORG 4 prob
6 . CH O 3 punct
마지막 열이 NER 예측을 나타내는 데 사용되는 10 열 conll 형식에 따라 출력이 형식화 될 수 있습니다. 이것은 model.annotate() 함수에 output_type='conll' 추가하여 수행 할 수 있습니다.
또한 model.annotate() 함수에서 1에서 기본값을 사용하는 대신 컴퓨터의 메모리에 맞게 매개 변수 batch_size 의 값을 조정할 수 있습니다 ( batch_size=1 ). 여기에서 batch_size 클수록 성능 속도가 빨라집니다.
import phonlp
# Automatically download the pre-trained PhoNLP model for Vietnamese
# and save it in a local machine folder
phonlp . download ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Load the pre-trained PhoNLP model for Vietnamese
model = phonlp . load ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." )) 입력 베트남어 텍스트가 raw 인 경우, 즉 단어와 문장 세분화가없는 경우, 베트남의 미리 훈련 된 Phonlp 모델에 공급하기 전에 단어 세그먼트 문장을 생성하기 위해 단어 세그먼터를 적용해야합니다. 사용자는 vncorenlp를 사용하여 단어 및 문장 분할을 수행해야합니다 (POS 태깅, NER 및 의존성 구문 분석 작업의 데이터에 적용된 동일한 베트남 톤 정규화를 생성하므로).
pip3 install py_vncorenlp
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local machine folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP for word and sentence segmentation
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
# Perform word and sentence segmentation
print ( rdrsegmenter . word_segment ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .']

