PhoNLP
1.0.0

Phonlp เป็นรูปแบบการเรียนรู้แบบหลายงานสำหรับการติดแท็กส่วนร่วม (POS) ร่วมกันชื่อการรับรู้เอนทิตี (NER) และการแยกวิเคราะห์การพึ่งพา การทดลองเกี่ยวกับชุดข้อมูลมาตรฐานเวียดนามแสดงให้เห็นว่า Phonlp ให้ผลลัพธ์ที่ล้ำสมัยซึ่งมีประสิทธิภาพสูงกว่าวิธีการเรียนรู้แบบทำงานเดี่ยวที่ปรับแต่งรูปแบบภาษาเวียดนามที่ผ่านการฝึกอบรมมาแล้วสำหรับแต่ละงานอย่างอิสระ
แม้ว่าเราจะประเมิน Phonlp เกี่ยวกับเวียดนามตัวอย่างการใช้งานของเราด้านล่างสามารถทำงานได้โดยตรงกับภาษาอื่น ๆ ที่มี corpora ที่มีคำอธิบายประกอบทองคำสำหรับงานสามงานของการติดแท็ก POS, การแยกวิเคราะห์และการพึ่งพาอาศัยกันและแบบจำลองภาษาเบิร์ตที่ได้รับการฝึกฝนก่อน
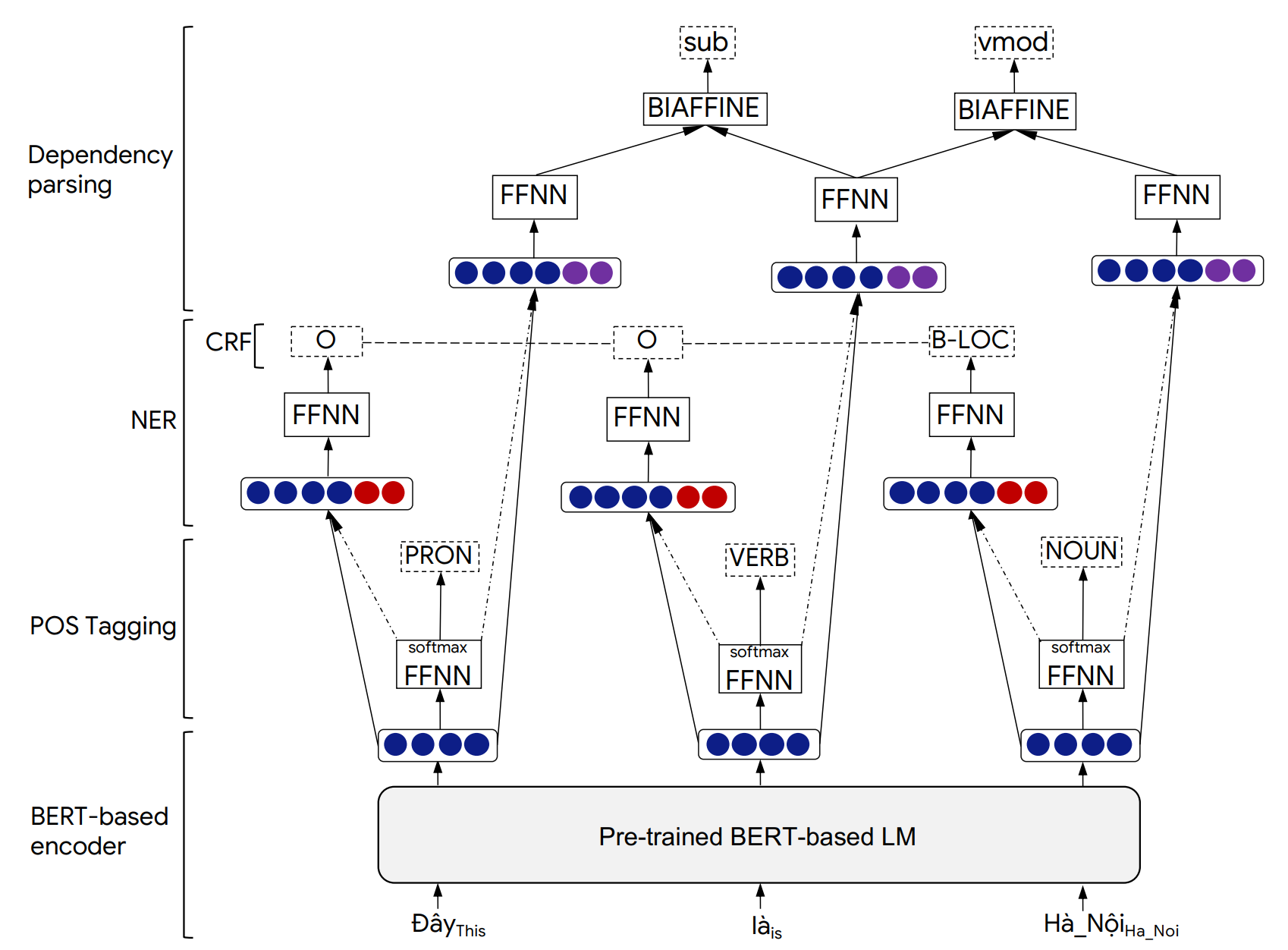
รายละเอียดของสถาปัตยกรรมโมเดล phonlp และผลการทดลองสามารถพบได้ในบทความต่อไปนี้ของเรา:
@inproceedings{phonlp,
title = {{PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing}},
author = {Linh The Nguyen and Dat Quoc Nguyen},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations},
pages = {1--7},
year = {2021}
}
โปรดอ้างอิง กระดาษของเราเมื่อใช้ Phonlp เพื่อช่วยสร้างผลลัพธ์ที่เผยแพร่หรือรวมอยู่ในซอฟต์แวร์อื่น ๆ
pip ดังนี้: pip3 install phonlp git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
หากต้องการเล่นกับตัวอย่างที่ใช้บรรทัดคำสั่งโปรดติดตั้ง phonlp จากแหล่งที่มา:
git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir <model_folder_path>
--pretrained_lm <transformers_pretrained_model>
--lr <float_value> --batch_size <int_value> --num_epoch <int_value>
--lambda_pos <float_value> --lambda_ner <float_value> --lambda_dep <float_value>
--train_file_pos <path_to_training_file_pos> --eval_file_pos <path_to_validation_file_pos>
--train_file_ner <path_to_training_file_ner> --eval_file_ner <path_to_validation_file_ner>
--train_file_dep <path_to_training_file_dep> --eval_file_dep <path_to_validation_file_dep>
--lambda_pos , --lambda_ner และ --lambda_dep แสดงถึงน้ำหนักผสมที่เกี่ยวข้องกับการติดแท็ก POS, NER และการสูญเสียการแยกวิเคราะห์การพึ่งพาอาศัยกันตามลำดับและ lambda_pos + lambda_ner + lambda_dep = 1
ตัวอย่าง:
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir ./phonlp_tmp
--pretrained_lm "vinai/phobert-base"
--lr 1e-5 --batch_size 32 --num_epoch 40
--lambda_pos 0.4 --lambda_ner 0.2 --lambda_dep 0.4
--train_file_pos ../sample_data/pos_train.txt --eval_file_pos ../sample_data/pos_valid.txt
--train_file_ner ../sample_data/ner_train.txt --eval_file_ner ../sample_data/ner_valid.txt
--train_file_dep ../sample_data/dep_train.conll --eval_file_dep ../sample_data/dep_valid.conll
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir <model_folder_path>
--batch_size <int_value>
--eval_file_pos <path_to_test_file_pos>
--eval_file_ner <path_to_test_file_ner>
--eval_file_dep <path_to_test_file_dep>
ตัวอย่าง:
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir ./phonlp_tmp
--batch_size 8
--eval_file_pos ../sample_data/pos_test.txt
--eval_file_ner ../sample_data/ner_test.txt
--eval_file_dep ../sample_data/dep_test.conll
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir <model_folder_path>
--batch_size <int_value>
--input_file <path_to_input_file>
--output_file <path_to_output_file>
ตัวอย่าง:
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir ./phonlp_tmp
--batch_size 8
--input_file ../sample_data/input.txt
--output_file ../sample_data/output.txt
import phonlp
# Load the trained PhoNLP model
model = phonlp . load ( save_dir = '/absolute/path/to/phonlp_tmp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))โดยค่าเริ่มต้นเอาต์พุตสำหรับแต่ละประโยคอินพุตจะถูกจัดรูปแบบด้วย 6 คอลัมน์ที่แสดงถึงดัชนีคำ, รูปแบบคำ, แท็ก POS, ฉลาก ner, ดัชนีส่วนหัวของคำปัจจุบันและประเภทความสัมพันธ์การพึ่งพา:
1 Tôi P O 3 sub
2 đang R O 3 adv
3 làm_việc V O 0 root
4 tại E O 3 loc
5 VinAI Np B-ORG 4 prob
6 . CH O 3 punct
เอาต์พุตสามารถจัดรูปแบบได้ตามรูปแบบ conll 10 คอลัมน์ที่คอลัมน์สุดท้ายใช้เพื่อแสดงการทำนาย NER สามารถทำได้โดยการเพิ่ม output_type='conll' ลงในฟังก์ชัน model.annotate()
นอกจากนี้ในฟังก์ชั่น model.annotate() ค่าของพารามิเตอร์ batch_size สามารถปรับได้เพื่อให้พอดีกับหน่วยความจำของคอมพิวเตอร์ของคุณแทนที่จะใช้ค่าเริ่มต้นที่ 1 ( batch_size=1 ) ที่นี่ batch_size ที่ใหญ่กว่าจะนำไปสู่ความเร็วประสิทธิภาพที่เร็วขึ้น
import phonlp
# Automatically download the pre-trained PhoNLP model for Vietnamese
# and save it in a local machine folder
phonlp . download ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Load the pre-trained PhoNLP model for Vietnamese
model = phonlp . load ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." )) ในกรณีที่ข้อความภาษาเวียดนามอินพุตเป็น raw เช่นไม่มีการแบ่งส่วนคำและประโยคคำศัพท์จะต้องใช้เพื่อสร้างประโยคที่มีการแบ่งคำก่อนที่จะให้อาหารกับโมเดล phonlp ที่ผ่านการฝึกอบรมมาก่อนสำหรับเวียดนาม ผู้ใช้ควรใช้ VNCORENLP เพื่อดำเนินการแบ่งส่วนคำและประโยค (เนื่องจากมันสร้างการปรับโทนเสียงเวียดนามเดียวกันที่ใช้กับข้อมูลของการติดแท็ก POS, NER และการแยกวิเคราะห์การพึ่งพา)
pip3 install py_vncorenlp
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local machine folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP for word and sentence segmentation
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
# Perform word and sentence segmentation
print ( rdrsegmenter . word_segment ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .']

