PhoNLP
1.0.0

PhONLPは、エンティティ認識(NER)と依存関係解析という名前の共同部品のパーツ(POS)タグ付けのマルチタスク学習モデルです。ベトナムのベンチマークデータセットでの実験は、PhONLPが最先端の結果を生み出し、各タスクのベトナム語モデルモデルのPhobertを独立して微調整するシングルタスク学習アプローチを上回ることを示しています。
ベトナム語でPhONLPを評価しますが、以下の使用例は、POSタグ付け、NER、依存関係解析の3つのタスクで利用可能な金注釈付きコーパス、および変圧器から利用可能な事前に訓練されたBERTベースの言語モデルで利用できる他の言語で直接機能します(Bert、Mbert、Roberta、XLM-Roberta)。
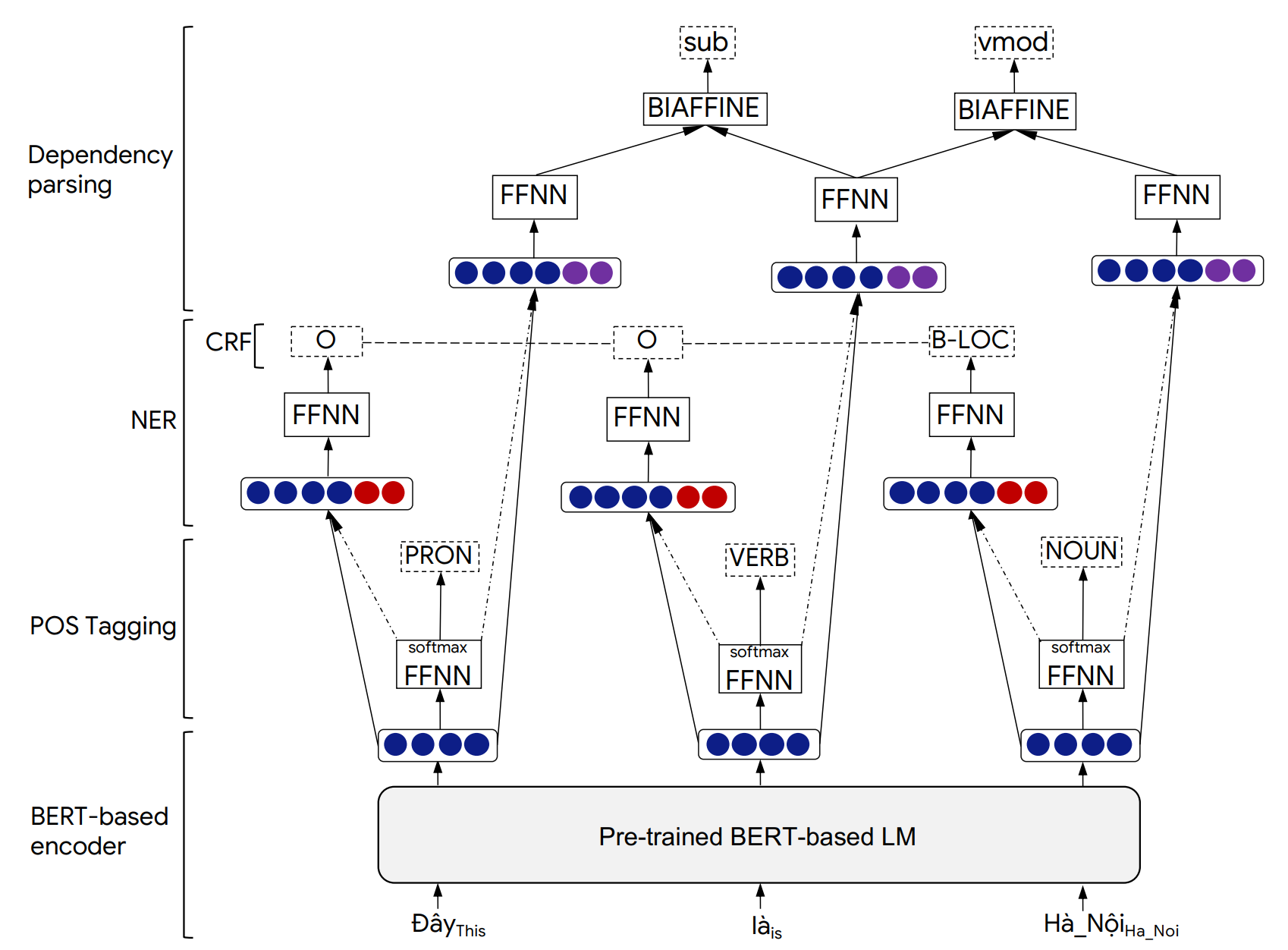
PhONLPモデルアーキテクチャと実験結果の詳細は、次の論文にあります。
@inproceedings{phonlp,
title = {{PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing}},
author = {Linh The Nguyen and Dat Quoc Nguyen},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations},
pages = {1--7},
year = {2021}
}
PhONLPが使用されて、公開された結果の作成を支援したり、他のソフトウェアに組み込まれたりする場合は、論文を引用してください。
pipを使用してインストールできます: pip3 install phonlp git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
コマンドラインを使用して例を使用するには、ソースからphonlpをインストールしてください。
git clone https://github.com/VinAIResearch/PhoNLP
cd PhoNLP
pip3 install -e .
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir <model_folder_path>
--pretrained_lm <transformers_pretrained_model>
--lr <float_value> --batch_size <int_value> --num_epoch <int_value>
--lambda_pos <float_value> --lambda_ner <float_value> --lambda_dep <float_value>
--train_file_pos <path_to_training_file_pos> --eval_file_pos <path_to_validation_file_pos>
--train_file_ner <path_to_training_file_ner> --eval_file_ner <path_to_validation_file_ner>
--train_file_dep <path_to_training_file_dep> --eval_file_dep <path_to_validation_file_dep>
--lambda_pos 、 --lambda_nerおよび--lambda_dep 、それぞれPOSタグ付け、nerおよび依存関係の解析損失に関連する混合重量を表し、 lambda_pos + lambda_ner + lambda_dep = 1 。
例:
cd phonlp/models
python3 run_phonlp.py --mode train --save_dir ./phonlp_tmp
--pretrained_lm "vinai/phobert-base"
--lr 1e-5 --batch_size 32 --num_epoch 40
--lambda_pos 0.4 --lambda_ner 0.2 --lambda_dep 0.4
--train_file_pos ../sample_data/pos_train.txt --eval_file_pos ../sample_data/pos_valid.txt
--train_file_ner ../sample_data/ner_train.txt --eval_file_ner ../sample_data/ner_valid.txt
--train_file_dep ../sample_data/dep_train.conll --eval_file_dep ../sample_data/dep_valid.conll
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir <model_folder_path>
--batch_size <int_value>
--eval_file_pos <path_to_test_file_pos>
--eval_file_ner <path_to_test_file_ner>
--eval_file_dep <path_to_test_file_dep>
例:
cd phonlp/models
python3 run_phonlp.py --mode eval --save_dir ./phonlp_tmp
--batch_size 8
--eval_file_pos ../sample_data/pos_test.txt
--eval_file_ner ../sample_data/ner_test.txt
--eval_file_dep ../sample_data/dep_test.conll
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir <model_folder_path>
--batch_size <int_value>
--input_file <path_to_input_file>
--output_file <path_to_output_file>
例:
cd phonlp/models
python3 run_phonlp.py --mode annotate --save_dir ./phonlp_tmp
--batch_size 8
--input_file ../sample_data/input.txt
--output_file ../sample_data/output.txt
import phonlp
# Load the trained PhoNLP model
model = phonlp . load ( save_dir = '/absolute/path/to/phonlp_tmp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))デフォルトでは、各入力文の出力は、単語インデックス、単語形式、POSタグ、nerラベル、現在の単語のヘッドインデックス、およびその依存関係タイプを表す6列でフォーマットされます。
1 Tôi P O 3 sub
2 đang R O 3 adv
3 làm_việc V O 0 root
4 tại E O 3 loc
5 VinAI Np B-ORG 4 prob
6 . CH O 3 punct
出力は、最後の列がNERの予測を表すために使用される10列のconll形式に従ってフォーマットできます。これはoutput_type='conll'をmodel.annotate()関数に追加することで実行できます。
また、 model.annotate()関数では、パラメーターbatch_sizeの値を調整して、デフォルトのメモリを1( batch_size=1 )を使用する代わりに、コンピューターのメモリに適合させることができます。ここでは、より大きなbatch_sizeがパフォーマンス速度を高速にします。
import phonlp
# Automatically download the pre-trained PhoNLP model for Vietnamese
# and save it in a local machine folder
phonlp . download ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Load the pre-trained PhoNLP model for Vietnamese
model = phonlp . load ( save_dir = '/absolute/path/to/pretrained_phonlp' )
# Annotate a corpus where each line represents a word-segmented sentence
model . annotate ( input_file = '/absolute/path/to/input.txt' , output_file = '/absolute/path/to/output.txt' )
# Annotate a word-segmented sentence
model . print_out ( model . annotate ( text = "Tôi đang làm_việc tại VinAI ." ))入力ベトナムのテキストがrawある場合、つまり単語と文のセグメンテーションのない場合、ベトナムの事前に訓練されたPhONLPモデルに供給する前に、単語セグメントターを適用するために単語セグメント文を作成する必要があります。ユーザーはVNCorenLPを使用して、単語と文のセグメンテーションを実行する必要があります(POSタグ付け、NER、依存関係の解析タスクのデータに適用されたのと同じベトナムのトーン正規化を生成するため)。
pip3 install py_vncorenlp
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local machine folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP for word and sentence segmentation
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
# Perform word and sentence segmentation
print ( rdrsegmenter . word_segment ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .']

