Vaaku2Vec
1.0.0
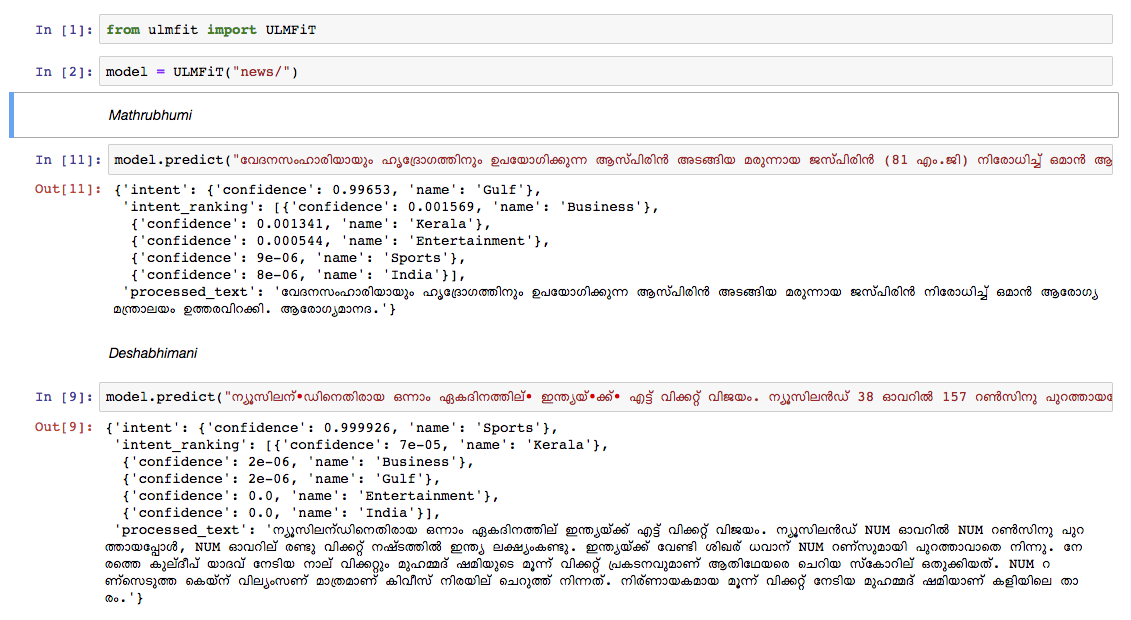
我們從2018年10月的Wikipedia文章轉儲中培訓了馬拉雅拉姆語的語言模型。 WikipediaDump有55K+文章。在訓練馬拉雅拉姆語的語言模型中,難度是文本像徵化,因為馬拉雅拉姆語是一種高度變化和凝結的語言。在當前模型中,我們正在使用nltk tokenizer (將來會嘗試更好的替代方案),而詞彙大小為30k。該語言模型用於培訓分類器,該分類器將新聞分為5個類別(印度,喀拉拉邦,體育,商業,娛樂)。我們的分類器在分類任務中以92%的高度準確性提出。
預審前的馬拉雅拉姆語模型
預算的馬拉雅拉姆語新聞分類器- 僅運行預測,請使用此。
Malayalam Wikipedia文章的RAW DATADUMP:Malayalam文章
Python3.6> =
如果您使用的是VirtualenvWrapper,請使用以下步驟:
git clone https://github.com/adamshamsudeen/Vaaku2Vec.gitmkvirtualenv -p python3.6 venvworkon venvcd Vaaku2Vecpip install -r requirements.txt python lm/create_toks.py <path_to_processed_wiki_dump>python lm/create_toks.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/tok2id.py <path_to_processed_wiki_dump>python lm/tok2id.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/pretrain_lm.py <path_to_processed_wiki_dump> 0 --lr 1e-3 --cl 40eg: python lm/pretrain_lm.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/ 0 --lr 1e-3 --cl 40lr是學習率, cl是時代的NO。train_classifier.ipynb訓練馬拉雅拉姆語文本分類器。Pretrained Malyalam Text Classifier 。prediction.ipynb並測試您的輸入。我們在其他領先的新聞報紙的新聞上手動測試了該模型,並且該模型的表現非常出色。