Vaaku2Vec
1.0.0
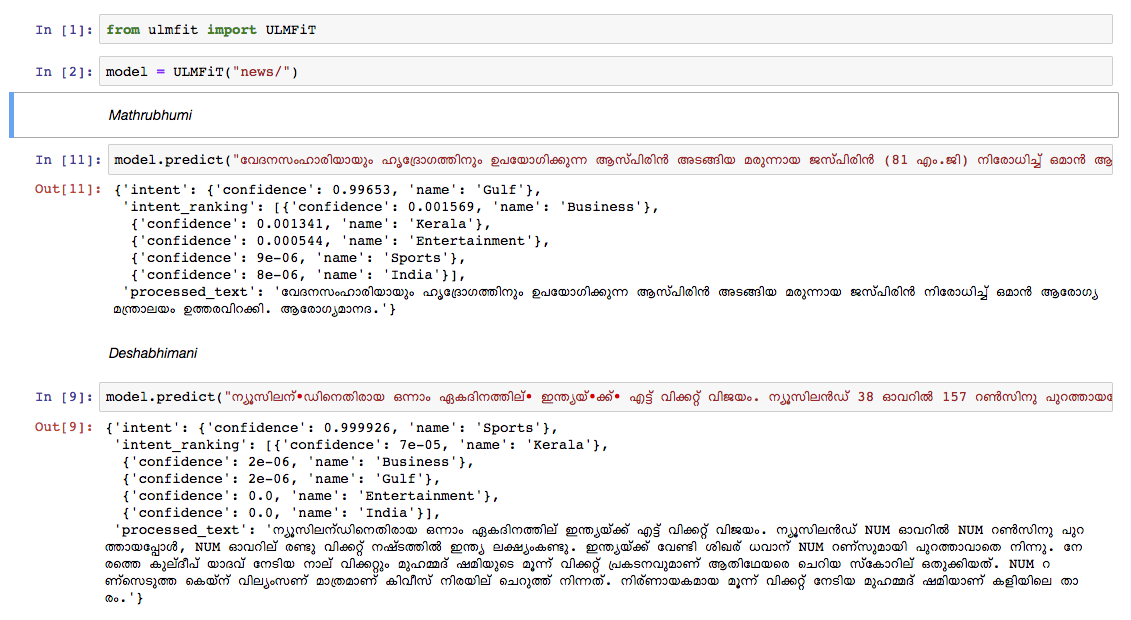
Мы обучили модель языка на малаялам на свалке статьи в Википедии с октября 2018 года. У дампы Википедии было 55 тыс.+ Статьи. Трудным обучением модели языка малаялам является текстовая токенизация , поскольку малаялам является высокофункциональным и агглютинативным языком. В текущей модели мы используем nltk tokenizer (в будущем попытаемся лучшей альтернативой), а размер слока составляет 30 тысяч. Языковая модель использовалась для обучения классификатора, который классифицирует новости по 5 категориям (Индия, Керала, спорт, бизнес, развлечения). Наш классификатор вышел с точностью 92% в задаче классификации.
Предварительно подготовленная модель языка малаялам
Предварительный малаяламский классификатор новостей - Чтобы запустить только прогноз, используйте это.
Необработанные данные малаялам Википедия Статьи: Малаяламские статьи
Python3.6> =
Если вы используете VirtualENVWrapper, используйте следующие шаги:
git clone https://github.com/adamshamsudeen/Vaaku2Vec.gitmkvirtualenv -p python3.6 venvworkon venvcd Vaaku2Vecpip install -r requirements.txt python lm/create_toks.py <path_to_processed_wiki_dump>python lm/create_toks.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/tok2id.py <path_to_processed_wiki_dump>python lm/tok2id.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/pretrain_lm.py <path_to_processed_wiki_dump> 0 --lr 1e-3 --cl 40eg: python lm/pretrain_lm.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/ 0 --lr 1e-3 --cl 40lr - это скорость обучения, а cl - это не эпохи.train_classifier.ipynb , чтобы обучить текстовый классификатор малаялам.Pretrained Malyalam Text Classifier упомянутый в загрузках.prediction.ipynb и проверьте свой вход. Мы вручную проверили модель в новостях из другой ведущей новостной бумаги, и модель показала довольно хорошо.