Vaaku2Vec
1.0.0
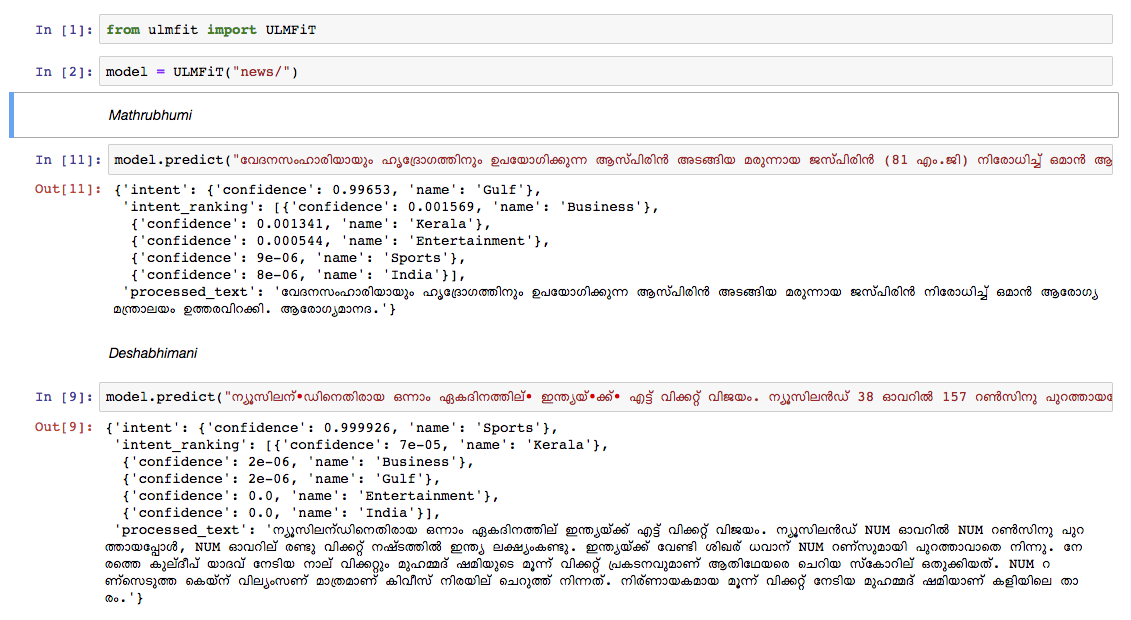
قمنا بتدريب نموذج لغة المالايالامية على تفريغ مقال ويكيبيديا من أكتوبر ، 2018. كان لدى Wikipedia Dump 55k+. صعوبة في تدريب نموذج لغة المالايالامية هو رمز النص ، لأن المالايالامية هي لغة للغاية وتجميلية. في النموذج الحالي ، نستخدم nltk tokenizer (سنحاول بديلًا أفضل في المستقبل) وحجم المفردات 30 كيلو. تم استخدام نموذج اللغة لتدريب مصنف يصنف الأخبار في 5 فئات (الهند ، كيرالا ، الرياضة ، الأعمال ، الترفيه). خرج المصنف لدينا بدقة 92 ٪ في مهمة التصنيف.
نموذج لغة المالايالامي المسبق
مصنف أخبار Malayalam Pretrained - لتشغيل التنبؤ فقط ، استخدم هذا.
Datadump الخام من Malayalam Wikipedia المقالات: مقالات المالايالامية
Python3.6> =
إذا كنت تستخدم VirtualEnvwrapper ، فاستخدم الخطوات التالية:
git clone https://github.com/adamshamsudeen/Vaaku2Vec.gitmkvirtualenv -p python3.6 venvworkon venvcd Vaaku2Vecpip install -r requirements.txt python lm/create_toks.py <path_to_processed_wiki_dump>python lm/create_toks.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/tok2id.py <path_to_processed_wiki_dump>python lm/tok2id.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/pretrain_lm.py <path_to_processed_wiki_dump> 0 --lr 1e-3 --cl 40eg: python lm/pretrain_lm.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/ 0 --lr 1e-3 --cl 40lr هو معدل التعلم و cl هو لا من الحقبة.train_classifier.ipynb لتدريب مصنف النص المالايالامي.Pretrained Malyalam Text Classifier المذكور المذكور في التنزيلات.prediction.ipynb . لقد اختبرنا النموذج يدويًا على الأخبار من ورقة الأخبار الرائدة الأخرى وأداء النموذج جيدًا.