Vaaku2Vec
1.0.0
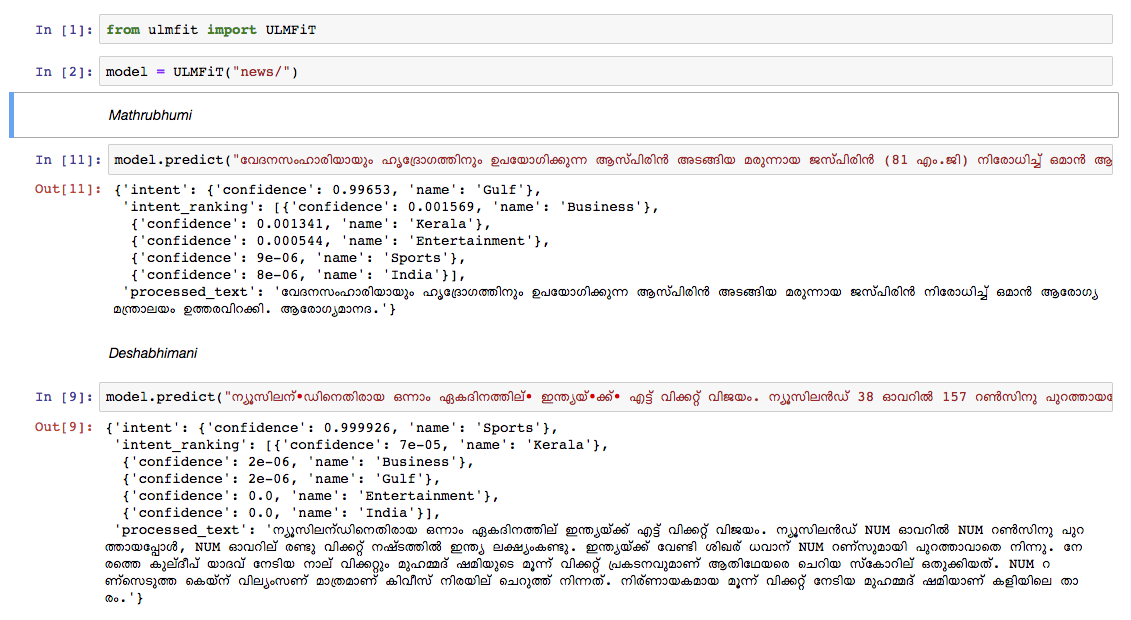
Wir haben ein Malayalam -Sprachmodell für den Wikipedia -Artikel -Dump von Oktober 2018 ausgebildet. Die Wikipedia -Dump hatte 55.000+ Artikel. Die schwierige Ausbildung eines Malayalam -Sprachmodells ist Text -Tokenisierung , da Malayalam eine stark wonbektrische und agglutinative Sprache ist. Im aktuellen Modell verwenden wir nltk tokenizer (werden in Zukunft eine bessere Alternative versuchen) und die Vokabellengröße beträgt 30.000. Das Sprachmodell wurde verwendet, um einen Klassifizierer auszubilden, der eine Nachricht in 5 Kategorien eingibt (Indien, Kerala, Sport, Geschäft, Unterhaltung). Unser Klassifizierer hat eine Genauigkeit von 92% in der Klassifizierungsaufgabe veröffentlicht.
Vorbereitete Malayalam -Sprachmodell
Vorbereitete Malayalam -Nachrichtenklassifizierin - Verwenden Sie dies nur die Vorhersage, um dies zu verwenden.
Rohdatadump von Malayalam Wikipedia Artikeln: Malayalam Artikel
python3.6> =
Wenn Sie virtualenvwrapper verwenden, verwenden Sie die folgenden Schritte:
git clone https://github.com/adamshamsudeen/Vaaku2Vec.gitmkvirtualenv -p python3.6 venvworkon venvcd Vaaku2Vecpip install -r requirements.txt python lm/create_toks.py <path_to_processed_wiki_dump>python lm/create_toks.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/tok2id.py <path_to_processed_wiki_dump>python lm/tok2id.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/pretrain_lm.py <path_to_processed_wiki_dump> 0 --lr 1e-3 --cl 40eg: python lm/pretrain_lm.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/ 0 --lr 1e-3 --cl 40lr ist die Lernrate und cl ist die Anzahl der Epochen.train_classifier.ipynb , um einen Malayalam -Textklassifizierer zu trainieren.Pretrained Malyalam Text Classifier herunter.prediction.ipynb und testen Sie Ihre Eingabe. Wir haben das Modell manuell in Nachrichten von anderen führenden Nachrichtenpapieren getestet, und das Modell hat ziemlich gut gespielt.