Vaaku2Vec
1.0.0
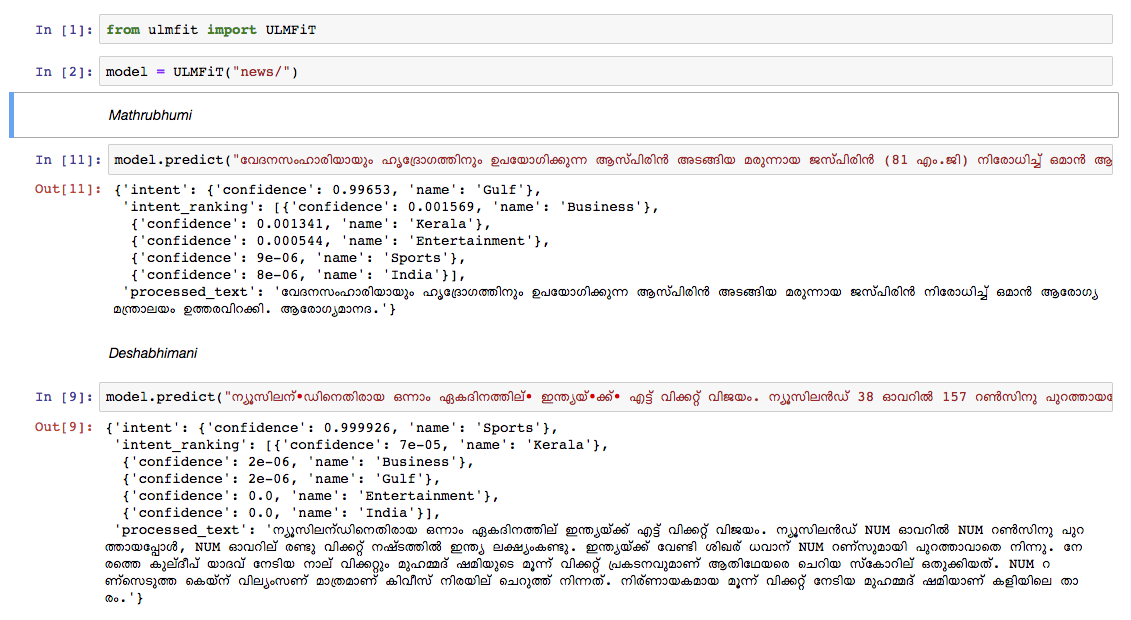
Treinamos um modelo de idioma malaiala no artigo do artigo da Wikipedia de outubro de 2018. O dump da Wikipedia tinha 55k+ artigos. O dificuldade em treinar um modelo de idioma malaiala é a tokenização de texto , uma vez que o malaiala é uma linguagem altamente inflexional e aglutinativa. No modelo atual, estamos usando nltk tokenizer (tentaremos melhor alternativa no futuro) e o tamanho do vocabulário é 30k. O modelo de idioma foi usado para treinar um classificador que classifica uma notícia em 5 categorias (Índia, Kerala, Esportes, Negócios, Entretenimento). Nosso classificador saiu com uma precisão de 92% na tarefa de classificação.
Modelo de linguagem malaiala pré -teria
Classificador de notícias Malayalam pré -treinado - para executar apenas a previsão, use isso.
Datadump de Malayalam Wikipedia Artigos: Artigos de Malayalam
python3.6> =
Se você estiver usando o VirtualEnvWrapper, use as seguintes etapas:
git clone https://github.com/adamshamsudeen/Vaaku2Vec.gitmkvirtualenv -p python3.6 venvworkon venvcd Vaaku2Vecpip install -r requirements.txt python lm/create_toks.py <path_to_processed_wiki_dump>python lm/create_toks.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/tok2id.py <path_to_processed_wiki_dump>python lm/tok2id.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/pretrain_lm.py <path_to_processed_wiki_dump> 0 --lr 1e-3 --cl 40eg: python lm/pretrain_lm.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/ 0 --lr 1e-3 --cl 40lr é a taxa de aprendizado e cl é o número de épocas.train_classifier.ipynb para treinar um classificador de texto malaiala.Pretrained Malyalam Text Classifier mencionado nos downloads.prediction.ipynb e teste sua entrada. Testamos manualmente o modelo de notícias de outro jornal líder e o modelo teve um desempenho muito bom.