Vaaku2Vec
1.0.0
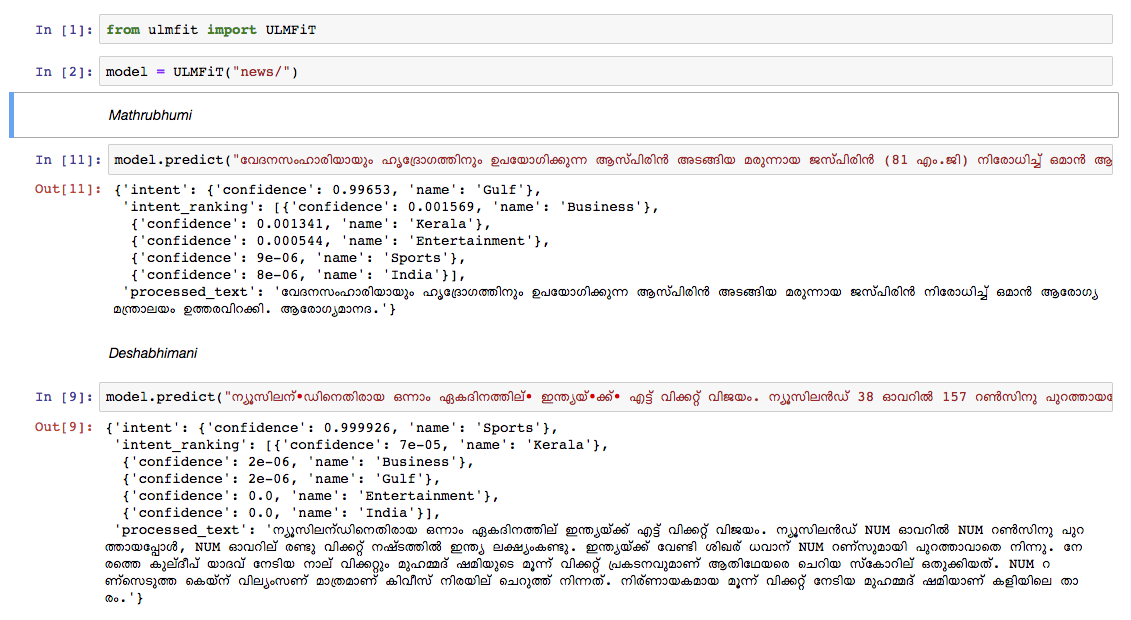
Nous avons formé un modèle de langue malayalam sur le dépotoir d'article de Wikipedia d'octobre 2018. Le Dumpedia Wikipedia avait 55k + articles. La difficulté à former un modèle de langue malayalam est la tokenisation textuelle , car le malayalam est un langage hautement inflexible et agglutinant. Dans le modèle actuel, nous utilisons nltk tokenizer (essaierons une meilleure alternative à l'avenir) et la taille du vocabulaire est de 30k. Le modèle de langue a été utilisé pour former un classificateur qui classe une nouvelle dans 5 catégories (Inde, Kerala, Sports, Business, Entertainment). Notre classificateur est sorti avec une précision de 92% dans la tâche de classification.
Modèle de langue malayalam pré-entraîné
Classificateur d'informations malayalam pré-entraîné - Pour exécuter uniquement la prédiction, utilisez-le.
Datadump brut de malayalam wikipedia Articles: Articles malayalam
Python3.6> =
Si vous utilisez VirtualEnvWrapper, utilisez les étapes suivantes:
git clone https://github.com/adamshamsudeen/Vaaku2Vec.gitmkvirtualenv -p python3.6 venvworkon venvcd Vaaku2Vecpip install -r requirements.txt python lm/create_toks.py <path_to_processed_wiki_dump>python lm/create_toks.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/tok2id.py <path_to_processed_wiki_dump>python lm/tok2id.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/pretrain_lm.py <path_to_processed_wiki_dump> 0 --lr 1e-3 --cl 40eg: python lm/pretrain_lm.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/ 0 --lr 1e-3 --cl 40lr est le taux d'apprentissage et cl est le NO des époques.train_classifier.ipynb pour entraîner un classificateur de texte malayalam.Pretrained Malyalam Text Classifier mentionné dans les téléchargements.prediction.ipynb et testez votre entrée. Nous avons testé manuellement le modèle sur les actualités des autres journaux de premier plan et le modèle a assez bien fonctionné.