Vaaku2Vec
1.0.0
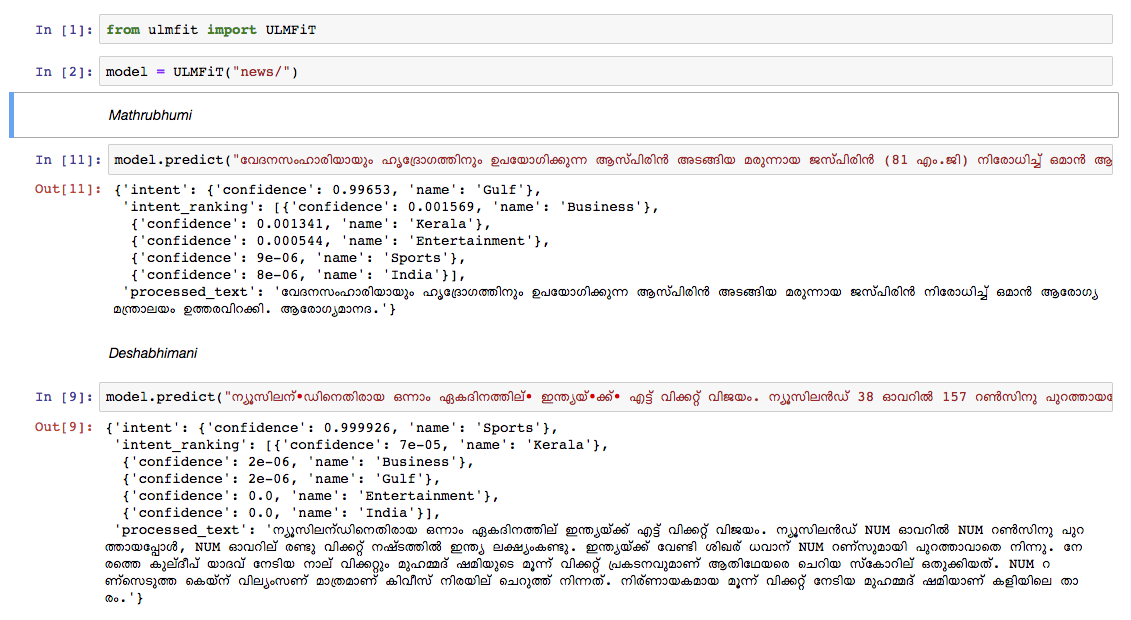
We trained a Malayalam language model on the Wikipedia article dump from Oct, 2018. The Wikipedia dump had 55k+ articles. The difficuly in training a Malayalam language model is text tokenization, since Malayalam is a highly inflectional and agglutinative language. In the current model, we are using nltk tokenizer (will try better alternative in the future) and the vocab size is 30k. The language model was used to train a classifier which classifies a news into 5 categories (India, Kerala, Sports, Business, Entertainment). Our classifier came out with a whooping 92% accuracy in the classification task.
Pretrained Malayalam Language Model
Pretrained Malayalam News Classifier - to run only the prediction, use this.
Raw Datadump of malayalam wikipedia articles : Malayalam Articles
python3.6>=
If you are using virtualenvwrapper use the following steps:
git clone https://github.com/adamshamsudeen/Vaaku2Vec.gitmkvirtualenv -p python3.6 venvworkon venvcd Vaaku2Vecpip install -r requirements.txtpython lm/create_toks.py <path_to_processed_wiki_dump>python lm/create_toks.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/tok2id.py <path_to_processed_wiki_dump>python lm/tok2id.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/pretrain_lm.py <path_to_processed_wiki_dump> 0 --lr 1e-3 --cl 40eg: python lm/pretrain_lm.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/ 0 --lr 1e-3 --cl 40lr is the learning rate and cl is the no of epochs.train_classifier.ipynb to train a malayalam text classifier.Pretrained Malyalam Text Classifier mentioned in the downloads.prediction.ipynb and test out your input.We manually tested the model on news from other leading news paper and the model performed pretty well.