Vaaku2Vec
1.0.0
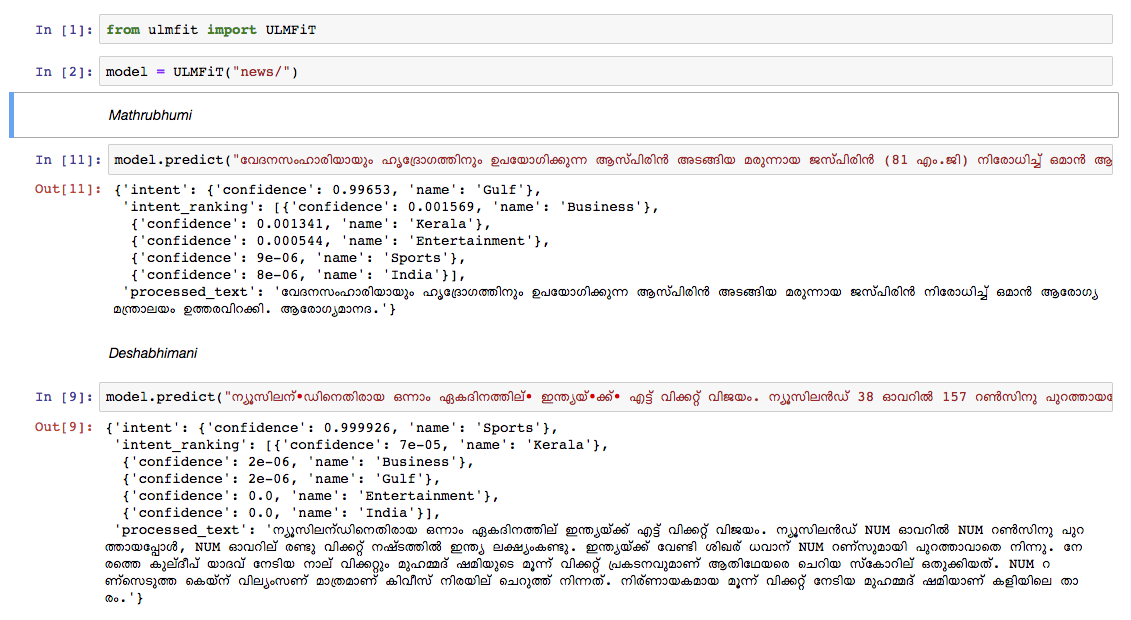
Entrenamos un modelo de idioma malayalam en el vertedero de artículos de Wikipedia de octubre de 2018. El vertedero de Wikipedia tenía 55k+ artículos. La dificultad en la capacitación de un modelo de lenguaje malayalam es la tokenización de texto , ya que el malayalam es un lenguaje altamente infeccional y aglutinativo. En el modelo actual, estamos utilizando nltk tokenizer (intentaremos una mejor alternativa en el futuro) y el tamaño de vocabulario es de 30k. El modelo de idioma se utilizó para capacitar a un clasificador que clasifica una noticia en 5 categorías (India, Kerala, Deportes, Negocios, Entretenimiento). Nuestro clasificador salió con una precisión del 92% en la tarea de clasificación.
Modelo de idioma malayalam previamente
Clasificador de noticias Malayalam previamente : para ejecutar solo la predicción, use esto.
Datadump en bruto de Malayalam Wikipedia Artículos: artículos de Malayalam
python3.6> =
Si está utilizando VirtualEnvWrapper, use los siguientes pasos:
git clone https://github.com/adamshamsudeen/Vaaku2Vec.gitmkvirtualenv -p python3.6 venvworkon venvcd Vaaku2Vecpip install -r requirements.txt python lm/create_toks.py <path_to_processed_wiki_dump>python lm/create_toks.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/tok2id.py <path_to_processed_wiki_dump>python lm/tok2id.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/pretrain_lm.py <path_to_processed_wiki_dump> 0 --lr 1e-3 --cl 40eg: python lm/pretrain_lm.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/ 0 --lr 1e-3 --cl 40lr es la tasa de aprendizaje y cl es el no de épocas.train_classifier.ipynb para entrenar un clasificador de texto Malayalam.Pretrained Malyalam Text Classifier previamente mencionado en las descargas.prediction.ipynb y pruebe su entrada. Probamos manualmente el modelo en noticias de otro documento de noticias líder y el modelo funcionó bastante bien.