Vaaku2Vec
1.0.0
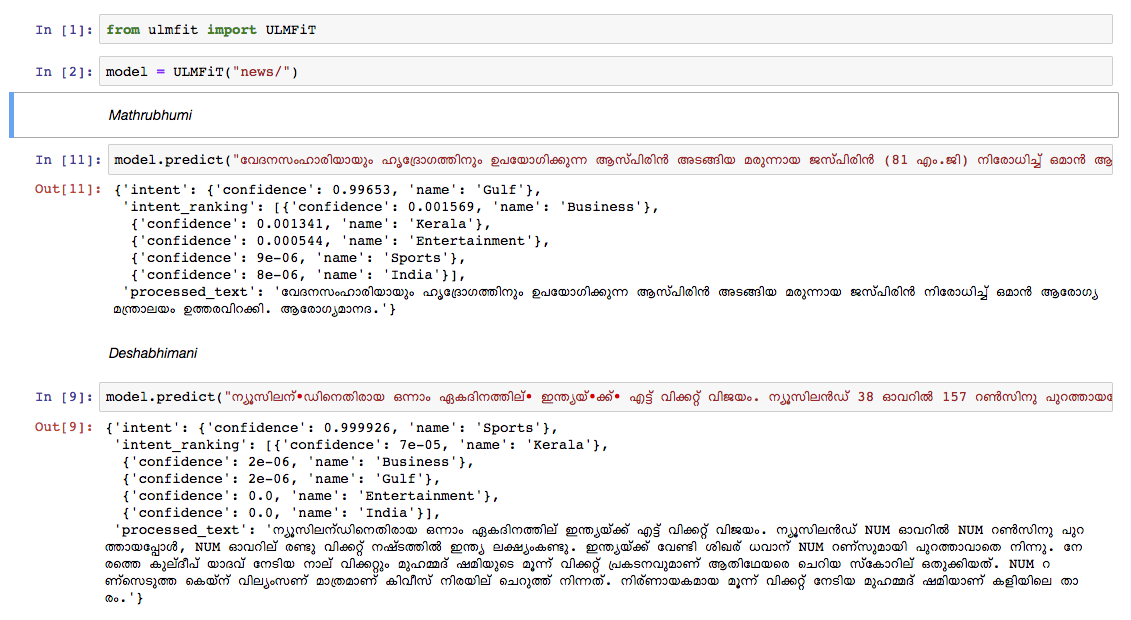
เราฝึกอบรมรูปแบบภาษามาลายาลัมในบทความ Wikipedia Dump จากตุลาคม 2018 การถ่ายโอนข้อมูลวิกิพีเดียมีบทความ 55K+ ความแตกต่างในการฝึกอบรมรูปแบบภาษามาลายาลัมคือ การทำให้เป็นโทเค็นข้อความ เนื่องจากมาลายาลัมเป็นภาษาที่มีความผันแปรและมีการรวมตัวกันอย่างมาก ในรุ่นปัจจุบันเราใช้ nltk tokenizer (จะพยายามทางเลือกที่ดีกว่าในอนาคต) และขนาดคำศัพท์คือ 30k รูปแบบภาษาถูกใช้เพื่อฝึกอบรมตัวจําแนกซึ่งจำแนกข่าวออกเป็น 5 หมวดหมู่ (อินเดีย, Kerala, กีฬา, ธุรกิจ, ความบันเทิง) ตัวจําแนกของเราออกมาพร้อมกับความแม่นยำ 92% ในงานการจำแนกประเภท
รูปแบบภาษามาลายาลัมก่อน
ตัวจําแนกข่าวมาลายาลัมก่อนหน้านี้ - เพื่อดำเนินการทำนายเท่านั้นใช้สิ่งนี้
บทความดิบดาต้าของมาลายาลัมวิกิพีเดีย: บทความมาลายาลัม
Python3.6> =
หากคุณใช้ VirtualEnVwrapper ให้ใช้ขั้นตอนต่อไปนี้:
git clone https://github.com/adamshamsudeen/Vaaku2Vec.gitmkvirtualenv -p python3.6 venvworkon venvcd Vaaku2Vecpip install -r requirements.txt python lm/create_toks.py <path_to_processed_wiki_dump>python lm/create_toks.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/tok2id.py <path_to_processed_wiki_dump>python lm/tok2id.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/python lm/pretrain_lm.py <path_to_processed_wiki_dump> 0 --lr 1e-3 --cl 40eg: python lm/pretrain_lm.py /home/adamshamsudeen/mal/Vaaku2Vec/wiki/ml/ 0 --lr 1e-3 --cl 40lr คืออัตราการเรียนรู้และ cl คือไม่มียุคtrain_classifier.ipynb เพื่อฝึกอบรมตัวจําแนกข้อความมาลายาลัมPretrained Malyalam Text Classifier ที่กล่าวถึงในการดาวน์โหลดprediction.ipynb และทดสอบอินพุตของคุณ เราทดสอบแบบจำลองข่าวจากกระดาษข่าวชั้นนำอื่น ๆ ด้วยตนเองและโมเดลทำงานได้ค่อนข้างดี