LoL RL
1.0.0
我們為語言模型微調介紹了一種新的脫機RL算法,該算法可以包含任何真實價值?任何先前存在的語言數據上的獎勵功能。
? chkey假設是將LM從LM視為RL設置中的單個動作。使用此假設,我們獲得了參考策略的序列級別值估算,並具有其驗證集績效。在我們案例中,參考策略僅僅是SFT模型,具有負log可能性(NLL)IE行為克隆。 A-lol的最終學習方程式看起來像: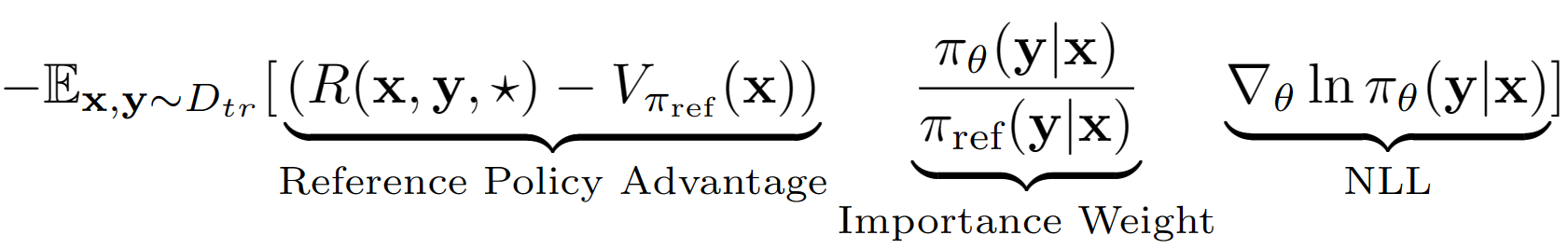
使用參考策略價值估計,我們發現培訓集的子集仍然具有積極的優勢(即剩餘的午餐?),並且僅在該子集上訓練優先採樣。我們還通過修改重要的權重項-A-LOL參考,A-lol SEQ,A-LOL KL (本文中的更多詳細信息)來測試A-lol的三種變體。總體而言,A-LOL非常容易實施?除了標準NLL登錄外,還可以效率穩定和样本效率嗎?脫機RL算法可以包含任何獎勵功能和數據源。
由於A-lol具有合併任意獎勵功能和數據源的靈活性?我們在各種語言模型任務上訓練語言模型,包括:(1)有用和無害的助手(HHA),(2)常識變壓器(Comet)生成任務,(3)具有5個不同的獎勵,(3)5個不同的獎勵,(4)忠實的知識對話,(4)忠實的知識對對話的生成4 Rewards 4 Rewards。在每個實驗中,我們將A-lol與其他離線策略梯度方法(例如加權行為克隆(WBC)和獎勵黃金(先前方法的修改版本)進行比較。在HHA中,我們還與流行的基於首選項的離線RL方法進行了比較,包括PRO,DPO和標准在線PPO實現。總體而言,在大多數獎勵的實驗中,A-LOL方法非常穩定,並且優於其他方法。
安裝軟件包: pip install -r requirements.txt
目的是在HHA數據集上的Finetune Llama 7b型號,以提高響應困難的用戶查詢時的幫助和安全性。我們重複使用Pro的數據和獎勵模型。
如何獲得無害和有用的助理任務數據集?
wget https://ylab-mobile-prod.oss-cn-beijing.aliyuncs.com/yueli.ybw/data.zipdata/文件夾中。 data/文件夾中應存在文件夾hh_dev , hh_test , hh_train_len2 。python data_cleaning.py如何以獎勵和優勢的離線RL方法來培訓模型?
python lolrl_qlora_llama_hh.py
參數和選項:
--algorithm :options- ['nll', 'wbc', 'r_gold', 'r_lol', 'a_lol', 'a_lol_ref_free', 'a_lol_seq', 'a_lol_kl']--sampling_strategy :默認None 。選項good_priority將以優勢或獎勵基於離線RL使用--ppo_clip :默認為0.9 。 R-lol,a-lol和a-lol Seq的PPO夾參數--kl_beta :默認值0.0 。 A-lol KL的KL Beta參數。使用KL時,請確保將PPO_CLIP設置為0.0如何使用基於首選項的離線RL方法培訓模型?
python dpo_qlora_llama_hh.py --output_dir "./checkpoints/dpo_qlora_llama/" 。添加--reference_free測試DPO的無參考版本。python pro_qlora_llama_hh.py --output_dir "./checkpoints/pro_qlora_llama/"如何使用在線RL方法培訓模型?
python ppo_qlora_llama_hh.py --output_dir "checkpoints/ppo_timdettmers_qlora_llama_6e/" --cache_dir "cache/ppo_tim_cache" --total_steps 6000python ppo_hh_eval.py --model_name_or_path "reciprocate/ppo_hh_pythia-6B" --output_dir "checkpoints/ppo_hh_pythia_6B/"如何評估測試集的任何Qlora模型?
python qlora_llama_hh_eval.py --adapter_path [PATH_TO_ADAPTER] --output_dir [OUTPUT_DIR]
上載了預審計的適配器,以實現有益而無害的助理任務,從最佳方法到擁抱面
目的是通過使用彗星 - 批判性分類器作為獎勵功能來改善原子^10x數據上的常識性推理。
data/symbolic_knowledge_distillation/python convert_keras_roberta_to_huggingface.py將最終分類器保存為Robertamodel,Tokenizer和自定義分類頭,並在
saved_models/comet_critic_keras_to_pytorch上保存了特定的激活。
分類器保存在文件夾中的“ custom_roberta_classification_head.pt”文件中
初始化分類頭如下:Robertacificationhead(1024,512,1)
python preprocess_comet_and_add_rewards.py -i data/symbolic_knowledge_distillation/downloaded -it data/symbolic_knowledge_distillation/atomic2020/atomic2020_data-feb2021/ -ccm saved_models/comet_critic_keras_to_pytorch -o data/comet_rewarded/ -bs 32 python train_generation_task_with_off_policy_PG.py -i data/comet_rewarded/ -tn COMET -m data/symbolic_knowledge_distillation/downloaded/comet-distill/ -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -mt data/symbolic_knowledge_distillation/downloaded/comet-distill-tokenizer/ -ccm saved_models/comet_critic_keras_to_pytorch -ml 30 -algo [ALGORITHM] -vf 16 -e 1 -bs 16 -as 1 -v_bs 32 -t -ev_b
算法選項: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'comet_distill': True}" -tn COMET -o final_results/comet_final_results.csv
目標是訓練一個Reddit對話框模型,該模型同時改善了5個方面:流利,安全性,參與度,投票概率和多樣性。我們對每個屬性使用先前存在的序列分類器,並將所有分數總和為最終的標量獎勵。為了測試A-lol對嘈雜數據的魯棒性,我們創建了兩個培訓數據拆分:(1)僅投票註釋,(2)僅投票註釋。
數據下載:從以下幾點下載upited和投票的reddit評論對:
陽性評論得分10%:[66.0,72.0,79.0,88.0,100.0,116.0,139.0,139.0,174.0,236.0,385.0,9582.0]
負註釋分數10%:[-2946.0,-25.0,-18.0,-14.0,-12.0,-12.0,-10.0,-9.0,-8.0,-8.0,-8.0,-7.0,-7.0,-6.0]
獎勵預測:下載toxichat分類器並將其保存在saved_models中
python preprocess_reddit_comment_scores_and_add_rewards.py -i data/reddit_comment_scores_kaggle/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -o data/reddit_comment_scores_kaggle/preprocessed
火車對話對話中nll參考策略reddit upvoted( reddit_pos )和傾斜( reddit_neg )註釋python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_pos -m microsoft/DialoGPT-medium -s saved_models/reddit_pos/dgpt_nll -o final_results/reddit_pos/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_neg -m microsoft/DialoGPT-medium -s saved_models/reddit_neg/dgpt_nll -o final_results/reddit_neg/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
task_name選項: ["reddit_pos", "reddit_neg"]
算法選項: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_pos -o final_results/reddit_pos_final_results.csv
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_neg -o final_results/reddit_neg_final_results.csv目標是訓練一個忠實的知識接地對話模型,該模型同時改善了4個方面:忠誠,流利,參與度和多樣性。我們對每個屬性使用先前存在的序列分類器,並將所有分數總和為最終的標量獎勵。我們再次使用三種不同的數據拆分:(1)Wikipedia(WOW)的嚮導 - 嘈雜/低質量,(2)FaithDial-清潔劑和(3)WOW + FAITHDIAL。
python preprocess_wow_and_add_rewards.py -i [TASK_NAME] -o data/[TASK_NAME]/preprocessed_and_rewarded/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -bs 32["wow", "faithdial", "faithdial_wow"]python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m microsoft/DialoGPT-medium -s saved_models/[TASK_NAME]/dgpt_nll -o final_results/[TASK_NAME]/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32["wow", "faithdial", "faithdial_wow"] python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
task_name選項: ["wow", "faithdial", "faithdial_wow"]
算法選項: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'dgpt_nll': True}" -tn [TASK_NAME] -o final_results/[TASK_NAME]_final_results.csv
task_name選項: ["wow", "faithdial", "faithdial_wow"]
論文:https://openreview.net/pdf?id=zdgkpbf0vq
@inproceedings{
baheti2024improving,
title={Leftover-Lunch: Advantage-based Offline Reinforcement Learning for Language Models},
author={Ashutosh Baheti and Ximing Lu and Faeze Brahman and Ronan Le Bras and Maarten Sap and Mark Riedl},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=ZDGKPbF0VQ}
}


