LoL RL
1.0.0
¿Introducimos un nuevo algoritmo RL fuera de línea para el modelo de lenguaje ajustado que puede incorporar algún valor real? Función de recompensa en cualquier datos de lenguaje preexistentes.
La suposición? ️Key es tratar toda la secuencia de salida de LM como una sola acción en la configuración de RL. Usando esta suposición, obtenemos una estimación del valor de nivel de secuencia de la Política de referencia con su rendimiento del conjunto de validación. La política de referencia en nuestro caso es simplemente el modelo SFT Finetuned con la clonación de comportamiento de la probabilidad de registro negativo (NLL). La ecuación de aprendizaje final para A-Lol parece: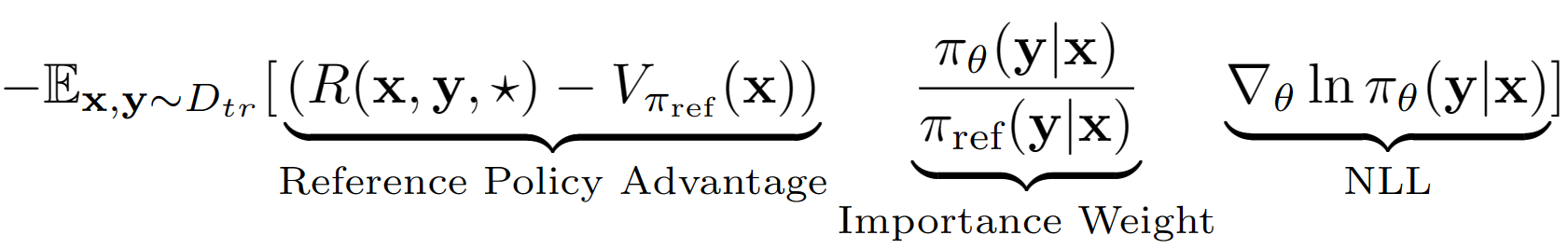
Utilizando la estimación del valor de la política de referencia, encontramos el subconjunto del conjunto de capacitación que todavía tiene una ventaja positiva (es decir, el almuerzo sobrante?) Y solo entrenar en ese subconjunto con muestreo priorizado. Además, probamos tres variantes de A-LOL modificando el término de peso de importancia: A-LOL REF-REF, A-LOL SEQ, A-LOL KL (más detalles en el documento). En general, ¿A-LOL es muy fácil de implementar? ¿Además de la fina NLL estándar y resulta en una muestra y una muestra eficiente? Algoritmo RL fuera de línea que puede incorporar cualquier función de recompensa y fuente de datos.
¿Debido a la flexibilidad de A-LOL para incorporar funciones de recompensa arbitrarias y fuentes de datos?, Capacitamos modelos de idiomas en una variedad de tareas de modelos de idiomas que incluyen: (1) Asistente útil e inofensivo (HHA), (2) Tarea de generación de transformador de sentido común (cometa), (3) generación de respuesta reddit con 5 recompensas diferentes, (4) generación de diálogo de influencia fiel con 4 recompensas. En cada experimento comparamos A-LOL con otros métodos de gradiente de políticas fuera de línea, como la clonación de comportamiento ponderado (WBC) y el oro de recompensa (una versión modificada de un método de oro anterior). En HHA, también comparamos con los métodos RL fuera de línea basados en preferencias populares que incluyen la implementación de PPO en línea PRO, DPO y estándar. En general, los métodos A-LOL son muy estables y superan a otros métodos en la mayoría de los experimentos en todas las recompensas.
Instalar paquetes: pip install -r requirements.txt
El objetivo es Finetune Llama 7B en el conjunto de datos HHA para mejorar la ayuda y la seguridad al responder a consultas de usuarios difíciles. Reutilizamos los modelos de datos y recompensas de Pro.
¿Cómo obtener un conjunto de datos de tareas de asistente inofensivo y útil?
wget https://ylab-mobile-prod.oss-cn-beijing.aliyuncs.com/yueli.ybw/data.zipdata/ carpeta. Las carpetas hh_dev , hh_test , hh_train_len2 deben estar presentes en data/ carpeta.python data_cleaning.py ¿Cómo entrenar modelos con recompensa y ventaja basada en métodos RL fuera de línea?
python lolrl_qlora_llama_hh.py
Parámetros y opciones:
--algorithm : opciones - ['nll', 'wbc', 'r_gold', 'r_lol', 'a_lol', 'a_lol_ref_free', 'a_lol_seq', 'a_lol_kl']--sampling_strategy : None predeterminado. Opción good_priority se utilizará con ventaja o recompensa basada en la línea fuera de línea RL--ppo_clip : predeterminado 0.9 . Parámetro de clip PPO para R-Lol, A-Lol y A-Lol SEQ--kl_beta : predeterminado 0.0 . Parámetro Beta KL para A-Lol KL. Cuando se usa KL, asegúrese de configurar PPO_CLIP en 0.0¿Cómo entrenar modelos con métodos RL fuera de línea basados en preferencias?
python dpo_qlora_llama_hh.py --output_dir "./checkpoints/dpo_qlora_llama/" . Agregar --reference_free para probar la versión sin referencia de DPO.python pro_qlora_llama_hh.py --output_dir "./checkpoints/pro_qlora_llama/"¿Cómo entrenar modelos con métodos RL en línea?
python ppo_qlora_llama_hh.py --output_dir "checkpoints/ppo_timdettmers_qlora_llama_6e/" --cache_dir "cache/ppo_tim_cache" --total_steps 6000python ppo_hh_eval.py --model_name_or_path "reciprocate/ppo_hh_pythia-6B" --output_dir "checkpoints/ppo_hh_pythia_6B/" ¿Cómo evaluar cualquier modelo de Qlora en el conjunto de pruebas?
python qlora_llama_hh_eval.py --adapter_path [PATH_TO_ADAPTER] --output_dir [OUTPUT_DIR]
Adaptadores previos al estado de carga para una tarea de asistente útil e inofensiva de los mejores métodos a Huggingface
El objetivo es mejorar el razonamiento de sentido común del modelo Comet en los datos Atomic^10x utilizando el clasificador de cometa-crítica como función de recompensa.
data/symbolic_knowledge_distillation/python convert_keras_roberta_to_huggingface.pyGuardó el clasificador final como RobertAmodel, Tokenizer y Head de clasificación personalizado con activaciones específicas en
saved_models/comet_critic_keras_to_pytorch.
El clasificador se guarda en el archivo "custom_roberta_classification_head.pt" dentro de la carpeta
Inicialice el cabezal de clasificación de la siguiente manera: RobertAclassificationhead (1024, 512, 1)
python preprocess_comet_and_add_rewards.py -i data/symbolic_knowledge_distillation/downloaded -it data/symbolic_knowledge_distillation/atomic2020/atomic2020_data-feb2021/ -ccm saved_models/comet_critic_keras_to_pytorch -o data/comet_rewarded/ -bs 32 python train_generation_task_with_off_policy_PG.py -i data/comet_rewarded/ -tn COMET -m data/symbolic_knowledge_distillation/downloaded/comet-distill/ -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -mt data/symbolic_knowledge_distillation/downloaded/comet-distill-tokenizer/ -ccm saved_models/comet_critic_keras_to_pytorch -ml 30 -algo [ALGORITHM] -vf 16 -e 1 -bs 16 -as 1 -v_bs 32 -t -ev_b
Opciones de algoritmo: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'comet_distill': True}" -tn COMET -o final_results/comet_final_results.csv
El objetivo es entrenar un modelo de diálogo Reddit que mejore simultáneamente 5 aspectos: fluidez, seguridad, compromiso, probabilidad de voto y diversidad. Empleamos clasificadores de secuencia preexistentes para cada atributo y sumamos todos los puntajes en una recompensa escalar final. Para probar la robustez de A-Lol hacia datos ruidosos, creamos dos divisiones de datos de entrenamiento: (1) solo comentarios votados y (2) solo comentarios votados.
Descarga de datos: Descargue los pares de comentarios Reddit votados y votados de: https://www.kaggle.com/code/danofer/reddit-comments-scores-nlp/input
Pango de comentarios de comentarios positivos 10: [66.0, 72.0, 79.0, 88.0, 100.0, 116.0, 139.0, 174.0, 236.0, 385.0, 9582.0]
Pango de puntaje de comentarios negativos 10: [-2946.0, -25.0, -18.0, -14.0, -12.0, -10.0, -9.0, -8.0, -8.0, -7.0, -6.0]
Predicción de recompensas: descargue los clasificadores Toxichat y guárdelos en saved_models
python preprocess_reddit_comment_scores_and_add_rewards.py -i data/reddit_comment_scores_kaggle/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -o data/reddit_comment_scores_kaggle/preprocessed
Política reddit_neg referencia de reddit_pos -Medium NLL de tren en comentarios Reddit
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_pos -m microsoft/DialoGPT-medium -s saved_models/reddit_pos/dgpt_nll -o final_results/reddit_pos/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_neg -m microsoft/DialoGPT-medium -s saved_models/reddit_neg/dgpt_nll -o final_results/reddit_neg/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Task_name Opciones: ["reddit_pos", "reddit_neg"]
Opciones de algoritmo: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_pos -o final_results/reddit_pos_final_results.csv
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_neg -o final_results/reddit_neg_final_results.csvEl objetivo es capacitar a un modelo de diálogo fundamental de conocimiento fiel que mejore simultáneamente 4 aspectos: fidelidad, fluidez, compromiso y diversidad. Empleamos clasificadores de secuencia preexistentes para cada atributo y sumamos todos los puntajes en una recompensa escalar final. Nuevamente usamos tres divisiones de datos diferentes: (1) Wizards of Wikipedia (wow) - ruidoso/de baja calidad, (2) Faithdial - Limpiador y (3) Wow + Faithdial.
python preprocess_wow_and_add_rewards.py -i [TASK_NAME] -o data/[TASK_NAME]/preprocessed_and_rewarded/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -bs 32["wow", "faithdial", "faithdial_wow"]python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m microsoft/DialoGPT-medium -s saved_models/[TASK_NAME]/dgpt_nll -o final_results/[TASK_NAME]/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32["wow", "faithdial", "faithdial_wow"] python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Task_name Opciones: ["wow", "faithdial", "faithdial_wow"]
Opciones de algoritmo: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'dgpt_nll': True}" -tn [TASK_NAME] -o final_results/[TASK_NAME]_final_results.csv
Task_name Opciones: ["wow", "faithdial", "faithdial_wow"]
Documento: https://openreview.net/pdf?id=zdgkpbf0vq
@inproceedings{
baheti2024improving,
title={Leftover-Lunch: Advantage-based Offline Reinforcement Learning for Language Models},
author={Ashutosh Baheti and Ximing Lu and Faeze Brahman and Ronan Le Bras and Maarten Sap and Mark Riedl},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=ZDGKPbF0VQ}
}


