LoL RL
1.0.0
실제 가치를 통합 할 수있는 언어 모델 미세 조정에 대한 새로운 오프라인 RL 알고리즘을 소개합니까? 기존 언어 데이터에 대한 보상 기능.
? kelky 가정은 LM의 전체 출력 시퀀스를 RL 설정에서 단일 동작으로 취급하는 것입니다. 이 가정을 사용하여 유효성 검사 세트 성능으로 참조 정책의 시퀀스 수준 값 추정치를 얻습니다. 우리의 경우 참조 정책은 단순히 부정적인 로그 가능성 (NLL) IE 동작 클로닝으로 미세한 SFT 모델입니다. A-Lol의 최종 학습 방정식은 다음과 같습니다.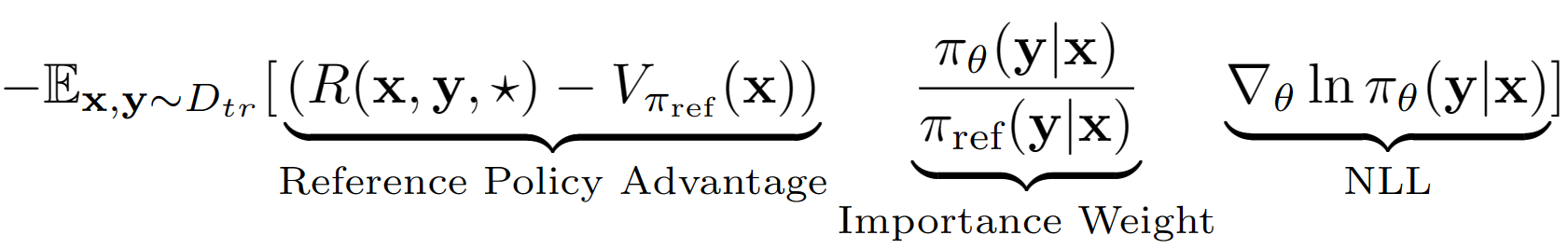
참조 정책 값 추정치를 사용하여 여전히 긍정적 인 이점 (즉 남은 점심?)을 갖는 교육 세트의 하위 집합을 발견하고 우선 순위가 좋은 샘플링으로 해당 서브 세트에서만 훈련합니다. 우리는 또한 중요성 중량 항 -A-Lol ref-free, A-Lol SEQ, A-Lol KL (논문의 자세한 내용)을 수정하여 A-Lol의 세 가지 변형을 추가로 테스트합니다. 전반적으로 A-Lol은 구현하기가 매우 쉽습니까? 표준 NLL Finetuning과 안정 및 샘플 효율성을 초래합니까? 보상 기능 및 데이터 소스를 통합 할 수있는 오프라인 RL 알고리즘.
A-Lol의 임의의 보상 기능 및 데이터 소스를 통합 할 수있는 A-Lol의 유연성으로 인해 다음과 같은 다양한 언어 모델 작업에 대해 언어 모델을 훈련시킵니다. 각 실험에서 우리는 A-LOL을 가중 동작 클로닝 (WBC) 및 보상 금 (이전 메소드 골드의 수정 된 버전)과 같은 다른 오프라인 정책 구배 방법과 비교합니다. HHA에서는 PRO, DPO 및 표준 온라인 PPO 구현을 포함한 대중적인 선호도 기반 오프라인 RL 방법과도 비교됩니다. 전반적으로, A-Lol 방법은 모든 보상에서 대부분의 실험에서 매우 안정적이며 다른 방법을 능가합니다.
패키지 설치 : pip install -r requirements.txt
목표는 어려운 사용자 쿼리에 응답 할 때 HHA 데이터 세트의 LLAMA 7B 모델을 HHA 데이터 세트에서 미세한 HHA 데이터 세트에서 미세한 상태로 유지하는 것입니다. Pro에서 데이터를 재사용하고 보상 모델을 재사용합니다.
무해하고 유용한 보조 작업 데이터 세트를 얻는 방법은 무엇입니까?
wget https://ylab-mobile-prod.oss-cn-beijing.aliyuncs.com/yueli.ybw/data.zipdata/ 폴더에 저장하십시오. 폴더 hh_dev , hh_test , hh_train_len2 는 data/ 폴더에 존재해야합니다.python data_cleaning.py 오프라인 RL 방법을 기반으로 보상과 장점으로 모델을 훈련시키는 방법?
python lolrl_qlora_llama_hh.py
매개 변수 및 옵션 :
--algorithm : 옵션 - ['nll', 'wbc', 'r_gold', 'r_lol', 'a_lol', 'a_lol_ref_free', 'a_lol_seq', 'a_lol_kl']--sampling_strategy : 기본값 None . 옵션 good_priority 오프라인 rl 기반 이점 또는 보상과 함께 사용할 수 있습니다.--ppo_clip : 기본 0.9 . R-Lol, A-Lol 및 A-Lol SEQ에 대한 PPO 클립 매개 변수--kl_beta : 기본 0.0 . A-Lol KL에 대한 KL 베타 매개 변수. KL을 사용하는 경우 ppo_clip을 0.0으로 설정하십시오.선호도 기반 오프라인 RL 방법으로 모델을 훈련시키는 방법은 무엇입니까?
python dpo_qlora_llama_hh.py --output_dir "./checkpoints/dpo_qlora_llama/" . --reference_free 추가하여 DPO의 참조 프리 버전을 테스트하십시오.python pro_qlora_llama_hh.py --output_dir "./checkpoints/pro_qlora_llama/"온라인 RL 방법으로 모델을 훈련시키는 방법?
python ppo_qlora_llama_hh.py --output_dir "checkpoints/ppo_timdettmers_qlora_llama_6e/" --cache_dir "cache/ppo_tim_cache" --total_steps 6000python ppo_hh_eval.py --model_name_or_path "reciprocate/ppo_hh_pythia-6B" --output_dir "checkpoints/ppo_hh_pythia_6B/" 테스트 세트에서 Qlora 모델을 평가하는 방법은 무엇입니까?
python qlora_llama_hh_eval.py --adapter_path [PATH_TO_ADAPTER] --output_dir [OUTPUT_DIR]
최상의 방법에서 포옹 페이스까지 도움이되고 무해한 조수 작업을 위해 사전 미리 처리 된 어댑터를 업로드했습니다.
목표는 Comet-Critic Classifier를 보상 기능으로 사용하여 Atomic^10x 데이터에 대한 Comet Model의 상식 추론을 개선하는 것입니다.
data/symbolic_knowledge_distillation/python convert_keras_roberta_to_huggingface.py최종 분류기
saved_models/comet_critic_keras_to_pytorchRobertamodel, Tokenizer 및 Custom Classification Head로 저장했습니다.
Classifier는 폴더 내의 "Custom_Roberta_Classification_head.pt"파일에 저장됩니다
분류 헤드를 다음과 같이 초기화하십시오 : Robertaclassificationhead (1024, 512, 1)
python preprocess_comet_and_add_rewards.py -i data/symbolic_knowledge_distillation/downloaded -it data/symbolic_knowledge_distillation/atomic2020/atomic2020_data-feb2021/ -ccm saved_models/comet_critic_keras_to_pytorch -o data/comet_rewarded/ -bs 32 python train_generation_task_with_off_policy_PG.py -i data/comet_rewarded/ -tn COMET -m data/symbolic_knowledge_distillation/downloaded/comet-distill/ -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -mt data/symbolic_knowledge_distillation/downloaded/comet-distill-tokenizer/ -ccm saved_models/comet_critic_keras_to_pytorch -ml 30 -algo [ALGORITHM] -vf 16 -e 1 -bs 16 -as 1 -v_bs 32 -t -ev_b
알고리즘 옵션 : ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'comet_distill': True}" -tn COMET -o final_results/comet_final_results.csv
목표는 유창함, 안전, 참여, 업 투베트 확률 및 다양성의 5 가지 측면을 동시에 개선하는 Reddit 대화 모델을 훈련시키는 것입니다. 우리는 각 속성에 대해 기존 시퀀스 분류기를 사용하고 모든 점수를 최종 스칼라 보상으로 합산합니다. 시끄러운 데이터에 대한 A-Lol의 견고성을 테스트하기 위해, 우리는 두 가지 훈련 데이터 분할을 만듭니다. (1) upvoted 댓글과 (2) 다운 투보 된 의견 만 있습니다.
데이터 다운로드 : https://www.kaggle.com/code/danofer/reddit-comments-scores-nlp/input의 Upvoted 및 Downvoted Reddit 댓글 쌍을 다운로드하십시오.
긍정적 인 주석 점수 10 백분위 수 : [66.0, 72.0, 79.0, 88.0, 100.0, 116.0, 139.0, 174.0, 236.0, 385.0, 9582.0]
부정적인 주석 점수 10 백분위 수 : [-2946.0, -25.0, -18.0, -14.0, -12.0, -10.0, -9.0, -8.0, -8.0, -7.0, -6.0]
보상 예측 : Toxichat 분류기를 다운로드하여 saved_models 에 저장하십시오.
python preprocess_reddit_comment_scores_and_add_rewards.py -i data/reddit_comment_scores_kaggle/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -o data/reddit_comment_scores_kaggle/preprocessed
Reddit Upvoted ( reddit_pos ) 및 Downvoted ( reddit_neg ) 주석에 대한 Train Dialogpt-Medium NLL 참조 정책
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_pos -m microsoft/DialoGPT-medium -s saved_models/reddit_pos/dgpt_nll -o final_results/reddit_pos/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_neg -m microsoft/DialoGPT-medium -s saved_models/reddit_neg/dgpt_nll -o final_results/reddit_neg/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
task_name 옵션 : ["reddit_pos", "reddit_neg"]
알고리즘 옵션 : ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_pos -o final_results/reddit_pos_final_results.csv
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_neg -o final_results/reddit_neg_final_results.csv목표는 충실한 지식 근거 대화 모델을 훈련시키는 것입니다. 우리는 각 속성에 대해 기존 시퀀스 분류기를 사용하고 모든 점수를 최종 스칼라 보상으로 합산합니다. 우리는 다시 세 가지 다른 데이터 스플릿을 사용합니다 : (1) Wikipedia의 마법사 (와우) - 노이즈/저 품질, (2) FaithDial- 클리너 및 (3) 와우 + FaithDial.
python preprocess_wow_and_add_rewards.py -i [TASK_NAME] -o data/[TASK_NAME]/preprocessed_and_rewarded/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -bs 32["wow", "faithdial", "faithdial_wow"]python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m microsoft/DialoGPT-medium -s saved_models/[TASK_NAME]/dgpt_nll -o final_results/[TASK_NAME]/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32["wow", "faithdial", "faithdial_wow"] python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
task_name 옵션 : ["wow", "faithdial", "faithdial_wow"]
알고리즘 옵션 : ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'dgpt_nll': True}" -tn [TASK_NAME] -o final_results/[TASK_NAME]_final_results.csv
task_name 옵션 : ["wow", "faithdial", "faithdial_wow"]
종이 : https://openreview.net/pdf?id=zdgkpbf0vq
@inproceedings{
baheti2024improving,
title={Leftover-Lunch: Advantage-based Offline Reinforcement Learning for Language Models},
author={Ashutosh Baheti and Ximing Lu and Faeze Brahman and Ronan Le Bras and Maarten Sap and Mark Riedl},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=ZDGKPbF0VQ}
}


