LoL RL
1.0.0
نقدم خوارزمية RL جديدة غير متصلة بالإنترنت لنماذج اللغة التي يمكن أن تتضمن أي قيمة حقيقية؟ وظيفة المكافأة على أي بيانات لغة موجودة مسبقًا.
الافتراض ️key هو معالجة تسلسل الإخراج بأكمله من LM كعمل واحد في إعداد RL. باستخدام هذا الافتراض ، نحصل على تقدير قيمة مستوى التسلسل للسياسة المرجعية مع أداء مجموعة التحقق من الصحة. السياسة المرجعية في حالتنا هي ببساطة نموذج SFT مع احتمال السجل السلبي (NLL) أي استنساخ السلوك. تشبه معادلة التعلم النهائية لـ A-LOL: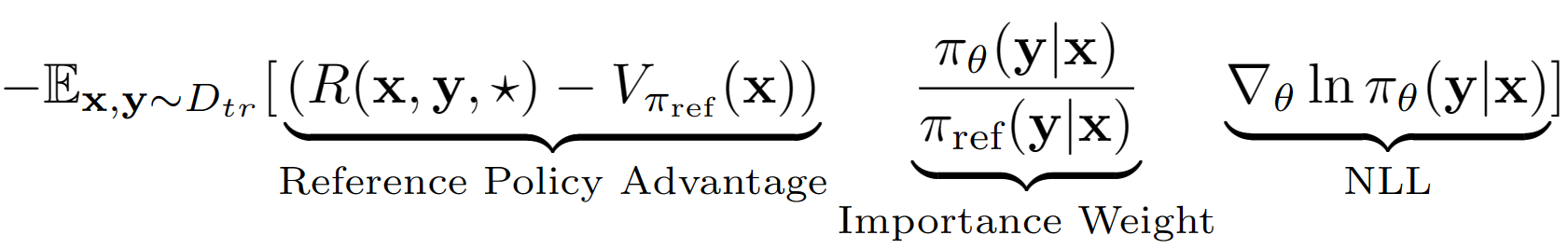
باستخدام تقدير قيمة السياسة المرجعية ، نجد مجموعة فرعية من مجموعة التدريب التي لا تزال تتمتع بميزة إيجابية (أي غداء بقايا؟) والتدريب فقط على هذه المجموعة الفرعية مع أخذ العينات ذات الأولوية. بالإضافة إلى ذلك ، نقوم باختبار ثلاثة متغيرات من A-LOL عن طريق تعديل مصطلح الوزن الأهمية- A-LOL REF-FRE ، A-LOL SEQ ، A-LOL KL (مزيد من التفاصيل في الورقة). بشكل عام ، من السهل جدًا تنفيذ A-LOL؟ على رأس NLL القياسي NLL وينتج عنه كفاءة مستقرة وعينة؟ خوارزمية RL غير متصلة بالإنترنت التي يمكن أن تتضمن أي وظيفة مكافأة ومصدر بيانات.
نظرًا لمرونة A-LOL لدمج وظائف المكافآت التعسفية ومصادر البيانات؟ ، نقوم بتدريب نماذج اللغة على مجموعة متنوعة من مهام النماذج اللغوية بما في ذلك: (1) مساعد مفيد وغير ضار (HHA) ، (2) مهام محول المشاركة (COMET) ، (3) جيل استجابة Reddit مع 5 مكافآت مختلفة ، (4) توليد حوار معروف من المعرفة 4). في كل تجربة ، نقوم بمقارنة A-LOL مع طرق التدرج السياسية غير المتصلة بالإنترنت مثل استنساخ السلوك الموزون (WBC) ومكافأة الذهب (نسخة معدلة من الطريقة السابقة للذهب). في HHA ، نقارن أيضًا مع أساليب RL غير المتصلة بالإنترنت الشائعة بما في ذلك Pro و DPO وتطبيق PPO عبر الإنترنت القياسي. بشكل عام ، تعتبر طرق A-LOL مستقرة للغاية وتتفوق على طرق أخرى في معظم التجارب عبر جميع المكافآت.
التثبيت الحزم: pip install -r requirements.txt
الهدف من ذلك هو Finetune Llama 7B على مجموعة بيانات HHA لتحسين المساعدة والسلامة عند الاستجابة لاستفسارات المستخدمين الصعبة. نعيد استخدام البيانات ومكافأة نماذج من Pro.
كيف تحصل على مجموعة بيانات المهام المساعدة غير الضارة والمفيدة؟
wget https://ylab-mobile-prod.oss-cn-beijing.aliyuncs.com/yueli.ybw/data.zipdata/ المجلد. يجب أن تكون المجلدات hh_dev ، hh_test ، hh_train_len2 موجودة في data/ المجلد.python data_cleaning.py كيفية تدريب النماذج بمكافأة وميزة على أساس طرق RL غير متصلة بالإنترنت؟
python lolrl_qlora_llama_hh.py
المعلمات والخيارات:
--algorithm : الخيارات - ['nll', 'wbc', 'r_gold', 'r_lol', 'a_lol', 'a_lol_ref_free', 'a_lol_seq', 'a_lol_kl']--sampling_strategy : الافتراضي None . خيار good_priority لاستخدامه مع ميزة أو مكافأة على أساس RLLOWEN RL--ppo_clip : افتراضي 0.9 . معلمة مقطع PPO لـ R-LOL و A-LOL و A-LOL SEQ--kl_beta : الافتراضي 0.0 . معلمة KL Beta لـ A-LOL KL. عند استخدام KL ، تأكد من تعيين PPO_CLIP على 0.0كيفية تدريب النماذج مع أساليب RL غير المتصلة بالإنترنت؟
python dpo_qlora_llama_hh.py --output_dir "./checkpoints/dpo_qlora_llama/" . إضافة- --reference_free لاختبار الإصدار المجاني المرجعي من DPO.python pro_qlora_llama_hh.py --output_dir "./checkpoints/pro_qlora_llama/"كيفية تدريب النماذج مع أساليب RL عبر الإنترنت؟
python ppo_qlora_llama_hh.py --output_dir "checkpoints/ppo_timdettmers_qlora_llama_6e/" --cache_dir "cache/ppo_tim_cache" --total_steps 6000python ppo_hh_eval.py --model_name_or_path "reciprocate/ppo_hh_pythia-6B" --output_dir "checkpoints/ppo_hh_pythia_6B/" كيفية تقييم أي نموذج Qlora على مجموعة الاختبار؟
python qlora_llama_hh_eval.py --adapter_path [PATH_TO_ADAPTER] --output_dir [OUTPUT_DIR]
محولات محملة محملة لمهمة مساعدة مفيدة وغير ضارة من أفضل الطرق إلى Luggingface
الهدف من ذلك هو تحسين التفكير المنطقي لنموذج المذنب على بيانات Atomic^10x باستخدام مصنف المذنب النحوي كدالة للمكافأة.
data/symbolic_knowledge_distillation/python convert_keras_roberta_to_huggingface.pyأنقذ المصنف النهائي مثل Robertamodel و Tokenizer ورئيس التصنيف المخصص مع تنشيطات محددة في
saved_models/comet_critic_keras_to_pytorch.
يتم حفظ المصنف في ملف "custom_roberta_classification_head.pt" داخل المجلد
تهيئة رأس التصنيف على النحو التالي: Robertaclassificationhead (1024 ، 512 ، 1)
python preprocess_comet_and_add_rewards.py -i data/symbolic_knowledge_distillation/downloaded -it data/symbolic_knowledge_distillation/atomic2020/atomic2020_data-feb2021/ -ccm saved_models/comet_critic_keras_to_pytorch -o data/comet_rewarded/ -bs 32 python train_generation_task_with_off_policy_PG.py -i data/comet_rewarded/ -tn COMET -m data/symbolic_knowledge_distillation/downloaded/comet-distill/ -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -mt data/symbolic_knowledge_distillation/downloaded/comet-distill-tokenizer/ -ccm saved_models/comet_critic_keras_to_pytorch -ml 30 -algo [ALGORITHM] -vf 16 -e 1 -bs 16 -as 1 -v_bs 32 -t -ev_b
خيارات الخوارزمية: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'comet_distill': True}" -tn COMET -o final_results/comet_final_results.csv
الهدف من ذلك هو تدريب نموذج حوار Reddit الذي يحسن في وقت واحد 5 جوانب: الطلاقة ، والسلامة ، والمشاركة ، والاحتمال الصوتي والتنوع. نحن نستخدم مصنفات تسلسل موجودة مسبقًا لكل سمة ونلخص جميع الدرجات في مكافأة العددية النهائية. لاختبار متانة A-LOL تجاه البيانات الصاخبة ، نقوم بإنشاء تقسيم بيانات التدريب: (1) التعليقات المصممة فقط و (2) التعليقات المنخفضة فقط.
تنزيل البيانات: قم بتنزيل أزواج تعليق Reddit Upvoted و Downvoted من: https://www.kaggle.com/code/danofer/reddit-comments-scores-nlp/inpt
التعليقات الإيجابية درجة 10 النسبة المئوية: [66.0 ، 72.0 ، 79.0 ، 88.0 ، 100.0 ، 116.0 ، 139.0 ، 174.0 ، 236.0 ، 385.0 ، 9582.0]
التعليقات السلبية النتيجة 10 النسبة المئوية: [-2946.0 ، -25.0 ، -18.0 ، -14.0 ، -12.0 ، -10.0 ، -9.0 ، -8.0 ، -8.0 ، -7.0 ، -6.0]
التنبؤ بالمكافأة: قم بتنزيل مصنفات Toxichat وحفظها في saved_models
python preprocess_reddit_comment_scores_and_add_rewards.py -i data/reddit_comment_scores_kaggle/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -o data/reddit_comment_scores_kaggle/preprocessed
سياسة مرجع حوار القطار Medium NLL على Reddit Upvoted ( reddit_pos ) و Sownvoted ( reddit_neg ) تعليقات
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_pos -m microsoft/DialoGPT-medium -s saved_models/reddit_pos/dgpt_nll -o final_results/reddit_pos/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_neg -m microsoft/DialoGPT-medium -s saved_models/reddit_neg/dgpt_nll -o final_results/reddit_neg/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
خيارات Task_Name: ["reddit_pos", "reddit_neg"]
خيارات الخوارزمية: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_pos -o final_results/reddit_pos_final_results.csv
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_neg -o final_results/reddit_neg_final_results.csvالهدف من ذلك هو تدريب نموذج مربع للحوار على المعرفة المؤمن الذي يحسن في وقت واحد 4 جوانب: الإخلاص ، والطلاقة ، والمشاركة والتنوع. نحن نستخدم مصنفات تسلسل موجودة مسبقًا لكل سمة ونلخص جميع الدرجات في مكافأة العددية النهائية. نستخدم مرة أخرى ثلاثة انشقاقات بيانات مختلفة: (1) معالجات ويكيبيديا (واو) - جودة صاخبة/منخفضة ، (2) Faithdial - أنظف و (3) Wow + Faithdial.
python preprocess_wow_and_add_rewards.py -i [TASK_NAME] -o data/[TASK_NAME]/preprocessed_and_rewarded/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -bs 32["wow", "faithdial", "faithdial_wow"]python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m microsoft/DialoGPT-medium -s saved_models/[TASK_NAME]/dgpt_nll -o final_results/[TASK_NAME]/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32["wow", "faithdial", "faithdial_wow"] python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
خيارات Task_Name: ["wow", "faithdial", "faithdial_wow"]
خيارات الخوارزمية: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'dgpt_nll': True}" -tn [TASK_NAME] -o final_results/[TASK_NAME]_final_results.csv
خيارات Task_Name: ["wow", "faithdial", "faithdial_wow"]
الورق: https://openreview.net/pdf؟id=ZDGKPBF0VQ
@inproceedings{
baheti2024improving,
title={Leftover-Lunch: Advantage-based Offline Reinforcement Learning for Language Models},
author={Ashutosh Baheti and Ximing Lu and Faeze Brahman and Ronan Le Bras and Maarten Sap and Mark Riedl},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=ZDGKPbF0VQ}
}


