LoL RL
1.0.0
実際の価値を組み込むことができる言語モデルの微調整のための新しいオフラインRLアルゴリズムを紹介しますか?既存の言語データの報酬機能。
?ショ和の仮定は、lmの出力シーケンス全体をRLセットアップでの単一のアクションとして扱うことです。この仮定を使用して、検証セットパフォーマンスを使用して、参照ポリシーのシーケンスレベル値推定値を取得します。私たちの場合の参照ポリシーは、単に負のログの尤度(NLL)の動作クローンを備えたSFTモデルが微調整されたものです。 A-LOLの最終学習方程式は次のように見えます。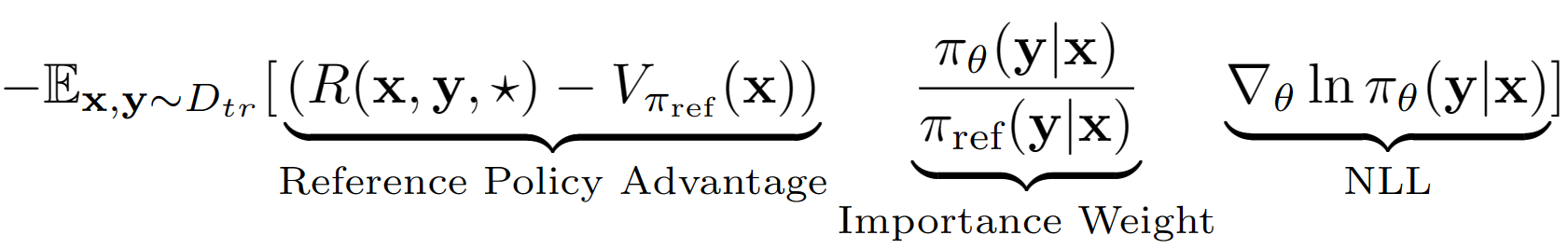
参照ポリシー値の推定値を使用して、トレーニングセットのサブセットがまだプラスの利点があり(つまり、残りの昼食?)、優先順位付けされたサンプリングを備えたサブセットでのみトレーニングします。さらに、重要な重量項-A-LOL Ref-Free、A-LOL SEQ、A-LOL KLを変更することにより、A-LOLの3つのバリアントをテストします(詳細の詳細)。全体として、A-LOLは非常に簡単に実装できますか?標準のNLL Finetuningに加えて、安定したサンプル効率をもたらしますか?報酬機能とデータソースを組み込むことができるオフラインRLアルゴリズム。
任意の報酬機能とデータソースを組み込むためのA-LOLの柔軟性により、次のようなさまざまな言語モデルのタスクで言語モデルをトレーニングします。各実験では、A-LOLを、加重動作クローニング(WBC)や報酬ゴールド(以前の方法の修正バージョン)などの他のオフラインポリシーグラデーションメソッドと比較します。 HHAでは、Pro、DPO、標準のオンラインPPO実装など、一般的な嗜好ベースのオフラインRLメソッドとも比較されます。全体として、A-LOLメソッドは非常に安定しており、すべての報酬にわたるほとんどの実験で他の方法よりも優れています。
パッケージのインストール: pip install -r requirements.txt
目標は、HHAデータセットのLlama 7BモデルをFintune Llama 7Bモデルで、難しいユーザークエリに対応するときに有用性と安全性を向上させることです。 Proのデータと報酬モデルを再利用します。
無害で役立つアシスタントタスクデータセットを取得するにはどうすればよいですか?
wget https://ylab-mobile-prod.oss-cn-beijing.aliyuncs.com/yueli.ybw/data.zipdata/フォルダーに保存します。フォルダーhh_dev 、 hh_test 、 hh_train_len2はdata/フォルダーに存在する必要があります。python data_cleaning.pyオフラインRLメソッドに基づいた報酬とアドバンテージでモデルをトレーニングする方法は?
python lolrl_qlora_llama_hh.py
パラメーターとオプション:
--algorithm :options- ['nll', 'wbc', 'r_gold', 'r_lol', 'a_lol', 'a_lol_ref_free', 'a_lol_seq', 'a_lol_kl']--sampling_strategy :デフォルトNone 。オプションgood_priorityは、アドバンテージまたは報酬ベースのオフラインRLで使用される--ppo_clip :デフォルト0.9 。 r-lol、a-lol、a-lol seqのPPOクリップパラメーター--kl_beta :デフォルト0.0 。 a-lol klのKLベータパラメーター。 KLを使用するときは、PPO_CLIPを0.0に設定してください優先ベースのオフラインRLメソッドでモデルをトレーニングする方法は?
python dpo_qlora_llama_hh.py --output_dir "./checkpoints/dpo_qlora_llama/" 。 dpoのリファレンスバージョンをテストするには、 --reference_freeを追加します。python pro_qlora_llama_hh.py --output_dir "./checkpoints/pro_qlora_llama/"オンラインRLメソッドでモデルをトレーニングする方法は?
python ppo_qlora_llama_hh.py --output_dir "checkpoints/ppo_timdettmers_qlora_llama_6e/" --cache_dir "cache/ppo_tim_cache" --total_steps 6000python ppo_hh_eval.py --model_name_or_path "reciprocate/ppo_hh_pythia-6B" --output_dir "checkpoints/ppo_hh_pythia_6B/"テストセットでQloraモデルを評価する方法は?
python qlora_llama_hh_eval.py --adapter_path [PATH_TO_ADAPTER] --output_dir [OUTPUT_DIR]
最良かつ無害なアシスタントタスクのためのアップロードされた前提型アダプターの最良の方法からハギングフェイスまで
目標は、comet-critic分類器を報酬関数として使用して、Atomic^10xデータのComet Modelの常識的な推論を改善することです。
data/symbolic_knowledge_distillation/python convert_keras_roberta_to_huggingface.py
saved_models/comet_critic_keras_to_pytorchで特定のアクティベーションを備えたロバートモデル、トークネイザー、カスタム分類ヘッドとして最終分類剤を保存しました。
分類器は、フォルダー内の「custom_roberta_classification_head.pt」ファイルに保存されます
次のように分類ヘッドを初期化します:RobertAclassificationhead(1024、512、1)
python preprocess_comet_and_add_rewards.py -i data/symbolic_knowledge_distillation/downloaded -it data/symbolic_knowledge_distillation/atomic2020/atomic2020_data-feb2021/ -ccm saved_models/comet_critic_keras_to_pytorch -o data/comet_rewarded/ -bs 32 python train_generation_task_with_off_policy_PG.py -i data/comet_rewarded/ -tn COMET -m data/symbolic_knowledge_distillation/downloaded/comet-distill/ -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -mt data/symbolic_knowledge_distillation/downloaded/comet-distill-tokenizer/ -ccm saved_models/comet_critic_keras_to_pytorch -ml 30 -algo [ALGORITHM] -vf 16 -e 1 -bs 16 -as 1 -v_bs 32 -t -ev_b
アルゴリズムオプション: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'comet_distill': True}" -tn COMET -o final_results/comet_final_results.csv
目標は、流ency性、安全性、エンゲージメント、支持確率、多様性の5つの側面を同時に改善するRedditダイアログモデルをトレーニングすることです。各属性に対して既存のシーケンス分類子を使用し、すべてのスコアを最終的なスカラー報酬に合計します。ノイズの多いデータに向けたA-LOLの堅牢性をテストするために、2つのトレーニングデータの分割を作成します。(1)上向きのコメントのみと(2)下向きのコメントのみ。
データのダウンロード:https://www.kaggle.com/code/danofer/reddit-comments-scores-nlp/inputからupvoted and downvoted redditコメントペアをダウンロードしてください。
肯定的なコメントスコア10パーセンタイル:[66.0、72.0、79.0、88.0、100.0、116.0、139.0、174.0、236.0、385.0、9582.0]
ネガティブコメントスコア10パーセンタイル:[-2946.0、-25.0、-18.0、-14.0、-12.0、-10.0、-9.0、-8.0、-8.0、-7.0、-6.0]
報酬の予測:Toxichat分類子をダウンロードして、 saved_modelsに保存します
python preprocess_reddit_comment_scores_and_add_rewards.py -i data/reddit_comment_scores_kaggle/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -o data/reddit_comment_scores_kaggle/preprocessed
dialogpt-medium nll reddit upvoted( reddit_pos )およびdownvoted( reddit_neg )コメントに関する列車の参照ポリシーpython train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_pos -m microsoft/DialoGPT-medium -s saved_models/reddit_pos/dgpt_nll -o final_results/reddit_pos/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_neg -m microsoft/DialoGPT-medium -s saved_models/reddit_neg/dgpt_nll -o final_results/reddit_neg/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
task_nameオプション: ["reddit_pos", "reddit_neg"]
アルゴリズムオプション: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_pos -o final_results/reddit_pos_final_results.csv
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_neg -o final_results/reddit_neg_final_results.csv目標は、忠実な知識に基づいたダイアログモデルを訓練することです。これは、忠実さ、流encyさ、エンゲージメント、多様性の4つの側面を同時に改善します。各属性に対して既存のシーケンス分類子を使用し、すべてのスコアを最終的なスカラー報酬に合計します。 (1)ウィキペディアのウィザード(WOW) - 騒音/低品質、(2)Faithdial-クリーナー、および(3)Wow + Faithdial。
python preprocess_wow_and_add_rewards.py -i [TASK_NAME] -o data/[TASK_NAME]/preprocessed_and_rewarded/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -bs 32["wow", "faithdial", "faithdial_wow"]python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m microsoft/DialoGPT-medium -s saved_models/[TASK_NAME]/dgpt_nll -o final_results/[TASK_NAME]/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32["wow", "faithdial", "faithdial_wow"] python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
task_nameオプション: ["wow", "faithdial", "faithdial_wow"]
アルゴリズムオプション: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'dgpt_nll': True}" -tn [TASK_NAME] -o final_results/[TASK_NAME]_final_results.csv
task_nameオプション: ["wow", "faithdial", "faithdial_wow"]
論文:https://openreview.net/pdf?id=zdgkpbf0vq
@inproceedings{
baheti2024improving,
title={Leftover-Lunch: Advantage-based Offline Reinforcement Learning for Language Models},
author={Ashutosh Baheti and Ximing Lu and Faeze Brahman and Ronan Le Bras and Maarten Sap and Mark Riedl},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=ZDGKPbF0VQ}
}


