LoL RL
1.0.0
Мы вводим новый автономный алгоритм RL для языковой модели, которая может включить какую-либо реальную ценность? Функция вознаграждения на любых ранее существовавших языковых данных.
Предполагается, что? Используя это предположение, мы получаем оценку значения уровня последовательности справочной политики с ее эффективностью набора валидации. Справочная политика в нашем случае - это просто модель SFT, созданная с отрицательной вероятностью журнала (NLL), т.е. клонирование поведения. Последнее уравнение обучения для A-LOL выглядит как: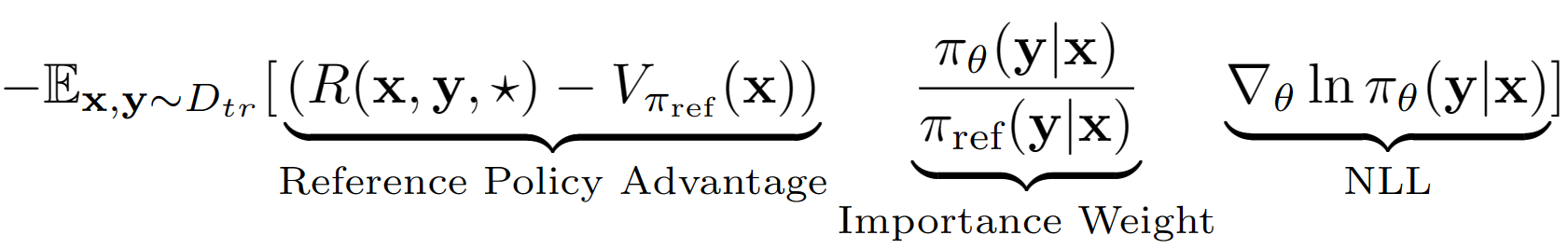
Используя оценку стоимости справочной политики, мы находим подмножество учебных наборов, которые все еще имеют положительное преимущество (т.е. оставшийся обед?) И только тренируемся в этом подмножестве с приоритетной выборкой. Кроме того, мы проверяем три варианта A-LOL, изменяя значение веса важности- A-LOL Ref-Free, A-LOL SEQ, A-LOL KL (подробнее в статье). В целом, A-LOL очень легко реализовать? Помимо стандартного NLL Manetuning и приводит к стабильному и эффективному образцу? Автономный алгоритм RL, который может включать любую функцию вознаграждения и источник данных.
Из-за гибкости A-LOL для включения произвольных функций и источников данных? В каждом эксперименте мы сравниваем A-LOL с другими методами градиента политики в автономном режиме, такими как взвешенное клонирование поведения (WBC) и вознаграждение Gold (модифицированная версия предыдущего метода Gold). В HHA мы также сравниваем с популярными методами RL, основанными на предпочтениях, включая Pro, DPO и стандартную реализацию онлайн-PPO. В целом, методы A-LOL очень стабильны и превосходят другие методы в большинстве экспериментов во всех вознаграждениях.
Установка пакетов: pip install -r requirements.txt
Цель состоит в том, чтобы наборе данных HHA, чтобы улучшить полезность и безопасность, чтобы улучшить полезность и безопасность при реагировании на трудные запросы пользователей. Мы повторно используем модели данных и вознаграждение от Pro.
Как получить безвредный и полезный набор данных помощника?
wget https://ylab-mobile-prod.oss-cn-beijing.aliyuncs.com/yueli.ybw/data.zipdata/ папке. Папки hh_dev , hh_test , hh_train_len2 должны присутствовать в data/ папке.python data_cleaning.py Как обучать модели с вознаграждением и преимуществами, основанными на офлайн -методах RL?
python lolrl_qlora_llama_hh.py
Параметры и параметры:
--algorithm : параметры - ['nll', 'wbc', 'r_gold', 'r_lol', 'a_lol', 'a_lol_ref_free', 'a_lol_seq', 'a_lol_kl']--sampling_strategy : по умолчанию None . Опция good_priority , которая будет использоваться с преимуществом или вознаграждением на основе Offline RL--ppo_clip : по умолчанию 0.9 . Параметр клипа PPO для R-LOL, A-LOL и A-LOL SEQ--kl_beta : по умолчанию 0.0 . КЛ Бета-параметр для a-lol kl. Когда используется KL, обязательно установите PPO_CLIP на 0,0Как обучать модели с методами офлайновых RL на основе предпочтений?
python dpo_qlora_llama_hh.py --output_dir "./checkpoints/dpo_qlora_llama/" . Добавить --reference_free , чтобы проверить бесплатную версию DPO.python pro_qlora_llama_hh.py --output_dir "./checkpoints/pro_qlora_llama/"Как обучать модели с помощью онлайн -методов RL?
python ppo_qlora_llama_hh.py --output_dir "checkpoints/ppo_timdettmers_qlora_llama_6e/" --cache_dir "cache/ppo_tim_cache" --total_steps 6000python ppo_hh_eval.py --model_name_or_path "reciprocate/ppo_hh_pythia-6B" --output_dir "checkpoints/ppo_hh_pythia_6B/" Как оценить какую -либо модель Qlora на наборе тестирования?
python qlora_llama_hh_eval.py --adapter_path [PATH_TO_ADAPTER] --output_dir [OUTPUT_DIR]
Загруженные адаптеры для полезных и безвредных помощников из лучших методов до huggingface
Цель состоит в том, чтобы улучшить обоснование модели COMET на Atomic^10X данных с использованием классификатора COMET-критического в качестве функции вознаграждения.
data/symbolic_knowledge_distillation/python convert_keras_roberta_to_huggingface.pyСохранил окончательный классификатор как Robertamodel, Tokenizer и Custom Classification Head с конкретными активациями на
saved_models/comet_critic_keras_to_pytorch.
Classififier сохраняется в файле "custom_roberta_classification_head.pt" в папке
Инициализируйте главу классификации следующим образом: RobertaclassificationHead (1024, 512, 1)
python preprocess_comet_and_add_rewards.py -i data/symbolic_knowledge_distillation/downloaded -it data/symbolic_knowledge_distillation/atomic2020/atomic2020_data-feb2021/ -ccm saved_models/comet_critic_keras_to_pytorch -o data/comet_rewarded/ -bs 32 python train_generation_task_with_off_policy_PG.py -i data/comet_rewarded/ -tn COMET -m data/symbolic_knowledge_distillation/downloaded/comet-distill/ -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -mt data/symbolic_knowledge_distillation/downloaded/comet-distill-tokenizer/ -ccm saved_models/comet_critic_keras_to_pytorch -ml 30 -algo [ALGORITHM] -vf 16 -e 1 -bs 16 -as 1 -v_bs 32 -t -ev_b
Параметры алгоритма: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'comet_distill': True}" -tn COMET -o final_results/comet_final_results.csv
Цель состоит в том, чтобы подготовить модель диалога Reddit, которая одновременно улучшает 5 аспектов: беглость, безопасность, взаимодействие, вероятность и разнообразие. Мы используем ранее существовавшие классификаторы последовательностей для каждого атрибута и суммируют все оценки в окончательную скалярную награду. Чтобы проверить надежность A-LOL в направлении шумных данных, мы создаем два расщепления обучающих данных: (1) Только выпущенные комментарии и (2) только пониженные комментарии.
Скачать данные: Загрузите пары комментариев Reddit с проведением и понижаемым голосом: https://www.kaggle.com/code/danofer/reddit-comments-cores-nlp/input
Положительные комментарии Оценка 10 процентиль: [66,0, 72,0, 79,0, 88,0, 100,0, 116,0, 139,0, 174,0, 236,0, 385,0, 9582,0]
Негативные комментарии Оценка 10 процентиль: [-2946,0, -25,0, -18,0, -14,0, -12,0, -10,0, -9,0, -8,0, -8,0, -7,0, -6,0]
Прогноз вознаграждения: загрузите классификаторы Toxichat и сохраните их в saved_models
python preprocess_reddit_comment_scores_and_add_rewards.py -i data/reddit_comment_scores_kaggle/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -o data/reddit_comment_scores_kaggle/preprocessed
Справочная политика Train Dialogpt-Medium NLL на reddit upvoted ( reddit_pos ) и приуманенные ( reddit_neg ) Комментарии
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_pos -m microsoft/DialoGPT-medium -s saved_models/reddit_pos/dgpt_nll -o final_results/reddit_pos/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_neg -m microsoft/DialoGPT-medium -s saved_models/reddit_neg/dgpt_nll -o final_results/reddit_neg/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Параметры task_name: ["reddit_pos", "reddit_neg"]
Параметры алгоритма: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_pos -o final_results/reddit_pos_final_results.csv
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_neg -o final_results/reddit_neg_final_results.csvЦель состоит в том, чтобы обучить верные знания, основанные на диалоге, которая одновременно улучшает 4 аспекта: верность, беглость, вовлечение и разнообразие. Мы используем ранее существовавшие классификаторы последовательностей для каждого атрибута и суммируют все оценки в окончательную скалярную награду. Мы снова используем три различных разрыва данных: (1) Wizards of Wikipedia (вау) - шумное/низкое качество, (2) Faithdial - Cleorer и (3) Wow + Faithdial.
python preprocess_wow_and_add_rewards.py -i [TASK_NAME] -o data/[TASK_NAME]/preprocessed_and_rewarded/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -bs 32["wow", "faithdial", "faithdial_wow"]python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m microsoft/DialoGPT-medium -s saved_models/[TASK_NAME]/dgpt_nll -o final_results/[TASK_NAME]/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32["wow", "faithdial", "faithdial_wow"] python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Параметры task_name: ["wow", "faithdial", "faithdial_wow"]
Параметры алгоритма: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'dgpt_nll': True}" -tn [TASK_NAME] -o final_results/[TASK_NAME]_final_results.csv
Параметры task_name: ["wow", "faithdial", "faithdial_wow"]
Бумага: https://openreview.net/pdf?id=zdgkpbf0vq
@inproceedings{
baheti2024improving,
title={Leftover-Lunch: Advantage-based Offline Reinforcement Learning for Language Models},
author={Ashutosh Baheti and Ximing Lu and Faeze Brahman and Ronan Le Bras and Maarten Sap and Mark Riedl},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=ZDGKPbF0VQ}
}


