LoL RL
1.0.0
Nous introduisons un nouvel algorithme RL hors ligne pour le réglage du modèle de langue qui peut incorporer n'importe quelle valeur réelle? Fonction de récompense sur toutes les données de langue préexistantes.
L'hypothèse? Ourdke consiste à traiter toute la séquence de sortie de LM comme une seule action dans la configuration RL. En utilisant cette hypothèse, nous obtenons une estimation de valeur de niveau de séquence de la politique de référence avec ses performances d'ensemble de validation. La politique de référence dans notre cas est simplement le modèle SFT finetuné avec un clonage de comportement de logarithme négatif (NLL) IE. L'équation d'apprentissage finale pour A-lol ressemble: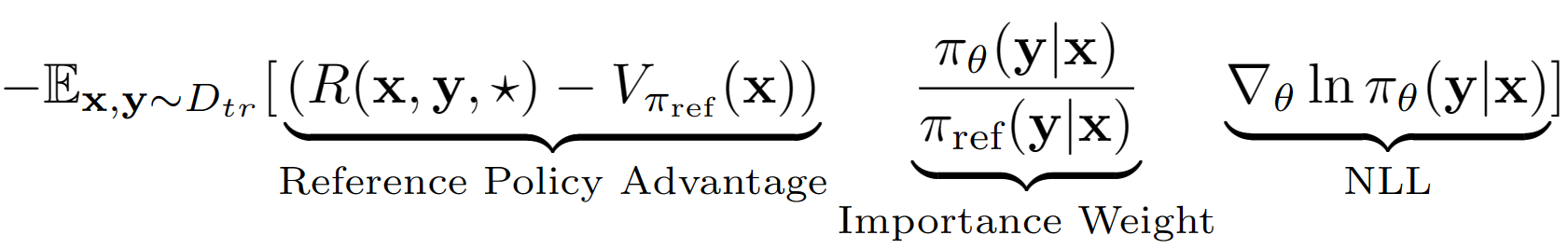
En utilisant l'estimation de la valeur de la politique de référence, nous trouvons le sous-ensemble de l'ensemble de formation qui a toujours un avantage positif (c'est-à-dire le déjeuner restant?) Et ne nous entraînant que sur ce sous-ensemble avec un échantillonnage prioritaire. Nous testons également trois variantes de A-LOL en modifiant le terme de poids d'importance - A-lol Ref-Free, A-LOL SEQ, A-LOL KL (plus de détails dans l'article). Dans l'ensemble, A-LOL est très facile à mettre en œuvre? En plus de la norme NLL standard et se traduit par un échantillon et un échantillon efficace? Algorithme RL hors ligne qui peut incorporer toute fonction de récompense et source de données.
En raison de la flexibilité de A-LOL pour incorporer des fonctions de récompense arbitraires et des sources de données ?, Nous formons des modèles de langage sur une variété de modèles de langage tâches, notamment: (1) Assistant utile et inoffensif (HHA), (2) Tâche de génération de transformateur de communes (COMET), (3) Génération de réponse Reddit avec 5 récompenses différentes, (4) Connaissances fidèles Génération de dialogue fondé avec 4 récompenses. Dans chaque expérience, nous comparons A-LOL avec d'autres méthodes de gradient de politique hors ligne telles que le clonage de comportement pondéré (WBC) et l'or de récompense (une version modifiée d'une méthode précédente Gold). Dans HHA, nous nous comparons également aux méthodes RL hors ligne populaires basées sur les préférences, notamment la mise en œuvre de Pro, DPO et standard en ligne PPO. Dans l'ensemble, les méthodes A-LOL sont très stables et surpassent d'autres méthodes dans la plupart des expériences de toutes les récompenses.
Installer les packages: pip install -r requirements.txt
L'objectif est de Finetune Llama 7B modèle sur l'ensemble de données HHA pour améliorer l'utilité et la sécurité lors de la réponse à des requêtes utilisateur difficiles. Nous réutilisons les modèles de données et de récompense de Pro.
Comment obtenir un ensemble de données de tâches d'assistant inoffensif et utile?
wget https://ylab-mobile-prod.oss-cn-beijing.aliyuncs.com/yueli.ybw/data.zipdata/ Folder. Les dossiers hh_dev , hh_test , hh_train_len2 doivent être présents dans data/ Folder.python data_cleaning.py Comment former des modèles avec des méthodes RL hors ligne de récompense et d'avantage?
python lolrl_qlora_llama_hh.py
Paramètres et options:
--algorithm : Options - ['nll', 'wbc', 'r_gold', 'r_lol', 'a_lol', 'a_lol_ref_free', 'a_lol_seq', 'a_lol_kl']--sampling_strategy : None par défaut. Option good_priority à utiliser avec avantage ou récompense basé sur RL hors ligne--ppo_clip : par défaut 0.9 . PPO Clip Paramètre pour R-LOL, A-LOL et A-LOL SEQ--kl_beta : par défaut 0.0 . Kl Beta Paramètre pour A-LOL KL. Lorsque KL est utilisé, assurez-vous de définir PPO_CLIP sur 0,0Comment former des modèles avec des méthodes RL hors ligne basées sur les préférences?
python dpo_qlora_llama_hh.py --output_dir "./checkpoints/dpo_qlora_llama/" . Ajouter --reference_free pour tester la version sans référence de DPO.python pro_qlora_llama_hh.py --output_dir "./checkpoints/pro_qlora_llama/"Comment former des modèles avec des méthodes RL en ligne?
python ppo_qlora_llama_hh.py --output_dir "checkpoints/ppo_timdettmers_qlora_llama_6e/" --cache_dir "cache/ppo_tim_cache" --total_steps 6000python ppo_hh_eval.py --model_name_or_path "reciprocate/ppo_hh_pythia-6B" --output_dir "checkpoints/ppo_hh_pythia_6B/" Comment évaluer un modèle QLORA sur les tests?
python qlora_llama_hh_eval.py --adapter_path [PATH_TO_ADAPTER] --output_dir [OUTPUT_DIR]
Adaptateurs pré-téléchargés pour une tâche d'assistant utile et inoffensive des meilleures méthodes à HuggingFace
L'objectif est d'améliorer le raisonnement de bon sens du modèle de comète sur les données atomiques ^ 10x en utilisant le classificateur COMET-Critique comme fonction de récompense.
data/symbolic_knowledge_distillation/python convert_keras_roberta_to_huggingface.pyEnregistré le classifer final comme Robertamodel, tokenizer et tête de classification personnalisée avec des activations spécifiques sur
saved_models/comet_critic_keras_to_pytorch.
Le classificateur est enregistré dans le fichier "Custom_roberta_classification_head.pt" dans le dossier
Initialisez la tête de classification comme suit: RobertAclassificationhead (1024, 512, 1)
python preprocess_comet_and_add_rewards.py -i data/symbolic_knowledge_distillation/downloaded -it data/symbolic_knowledge_distillation/atomic2020/atomic2020_data-feb2021/ -ccm saved_models/comet_critic_keras_to_pytorch -o data/comet_rewarded/ -bs 32 python train_generation_task_with_off_policy_PG.py -i data/comet_rewarded/ -tn COMET -m data/symbolic_knowledge_distillation/downloaded/comet-distill/ -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -mt data/symbolic_knowledge_distillation/downloaded/comet-distill-tokenizer/ -ccm saved_models/comet_critic_keras_to_pytorch -ml 30 -algo [ALGORITHM] -vf 16 -e 1 -bs 16 -as 1 -v_bs 32 -t -ev_b
Options d'algorithme: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'comet_distill': True}" -tn COMET -o final_results/comet_final_results.csv
L'objectif est de former un modèle de dialogue Reddit qui améliore simultanément 5 aspects: la maîtrise, la sécurité, l'engagement, la probabilité et la diversité de la vote de l'usine. Nous utilisons des classificateurs de séquences préexistants pour chaque attribut et adoptons tous les scores dans une récompense scalaire finale. Pour tester la robustesse de A-LOL vers des données bruyantes, nous créons deux divisions de données d'entraînement: (1) uniquement des commentaires votés et (2) uniquement des commentaires votés.
Téléchargement des données: Téléchargez les paires de commentaires reddit upvote et downvoted de: https://www.kaggle.com/code/danofer/reddit-comments-scores-nlp/input
Les commentaires positifs marquent 10 centile: [66,0, 72,0, 79,0, 88,0, 100,0, 116,0, 139,0, 174,0, 236,0, 385,0, 9582,0]
Les commentaires négatifs marquent 10 centile: [-2946.0, -25.0, -18.0, -14.0, -12.0, -10.0, -9.0, -8.0, -8.0, -7.0, -6.0]
Prédiction de récompense: Téléchargez les classificateurs Toxichat et enregistrez-les dans saved_models
python preprocess_reddit_comment_scores_and_add_rewards.py -i data/reddit_comment_scores_kaggle/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -o data/reddit_comment_scores_kaggle/preprocessed
Train Dialogpt-Medium NLL Reference Policy sur Reddit Upvoted ( reddit_pos ) et Downvoted ( reddit_neg ) Commentaires
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_pos -m microsoft/DialoGPT-medium -s saved_models/reddit_pos/dgpt_nll -o final_results/reddit_pos/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_neg -m microsoft/DialoGPT-medium -s saved_models/reddit_neg/dgpt_nll -o final_results/reddit_neg/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Options task_name: ["reddit_pos", "reddit_neg"]
Options d'algorithme: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_pos -o final_results/reddit_pos_final_results.csv
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_neg -o final_results/reddit_neg_final_results.csvL'objectif est de former un modèle de dialogue de connaissances fidèles qui améliore simultanément 4 aspects: fidélité, maîtrise, engagement et diversité. Nous utilisons des classificateurs de séquences préexistants pour chaque attribut et adoptons tous les scores dans une récompense scalaire finale. Nous utilisons à nouveau trois divisions de données différentes: (1) Wizards de Wikipedia (wow) - bruyant / de faible qualité, (2) foi - nettoyant et (3) wow + foi.
python preprocess_wow_and_add_rewards.py -i [TASK_NAME] -o data/[TASK_NAME]/preprocessed_and_rewarded/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -bs 32["wow", "faithdial", "faithdial_wow"]python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m microsoft/DialoGPT-medium -s saved_models/[TASK_NAME]/dgpt_nll -o final_results/[TASK_NAME]/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32["wow", "faithdial", "faithdial_wow"] python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Options task_name: ["wow", "faithdial", "faithdial_wow"]
Options d'algorithme: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'dgpt_nll': True}" -tn [TASK_NAME] -o final_results/[TASK_NAME]_final_results.csv
Options task_name: ["wow", "faithdial", "faithdial_wow"]
Papier: https://openreview.net/pdf?id=zdgkpbf0vq
@inproceedings{
baheti2024improving,
title={Leftover-Lunch: Advantage-based Offline Reinforcement Learning for Language Models},
author={Ashutosh Baheti and Ximing Lu and Faeze Brahman and Ronan Le Bras and Maarten Sap and Mark Riedl},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=ZDGKPbF0VQ}
}


