LoL RL
1.0.0
Introduzimos um novo algoritmo RL offline para o ajuste fino do modelo de idioma que pode incorporar qualquer valor real? Função de recompensa em quaisquer dados de linguagem pré-existentes.
A suposição? Aste é tratar a sequência de saída inteira do LM como uma única ação na configuração do RL. Usando essa suposição, obtemos uma estimativa de valor de nível de sequência da política de referência com seu desempenho no conjunto de validação. A política de referência em nosso caso é simplesmente o modelo SFT FinetUned com a clonagem de comportamento negativo de verossimilhança de log (NLL), ou seja,. A equação final da aprendizagem para A-Lol se parece: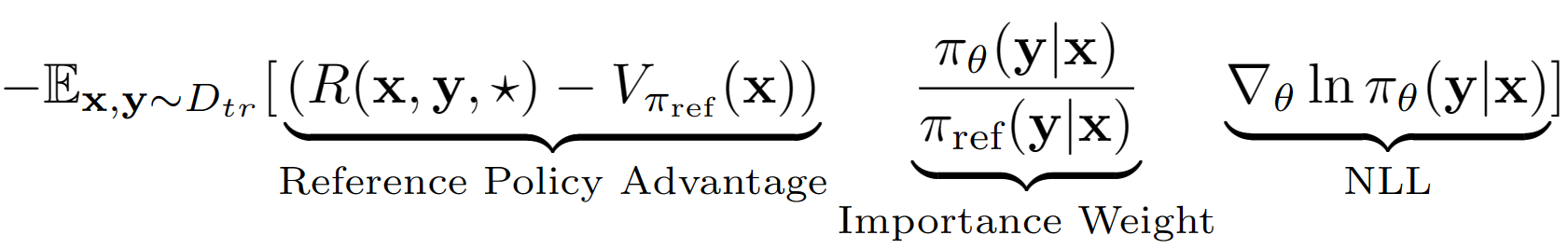
Usando a estimativa do valor da política de referência, encontramos o subconjunto de treinamento que ainda tem vantagem positiva (ou seja, o almoço restante?) E apenas treinamos nesse subconjunto com amostragem priorizada. Além disso, testamos três variantes de A-Lol modificando o termo de peso de importância- A-LOL sem ref, A-LOL seq, KL A-LOL (mais detalhes no papel). No geral, o A-Lol é muito fácil de implementar? Além da Finetuning NLL padrão e resulta em uma amostra estável e eficiente? Algoritmo RL offline que pode incorporar qualquer função de recompensa e fonte de dados.
Devido à flexibilidade do A-LOL para incorporar funções de recompensa arbitrária e fontes de dados?, Treinamos modelos de linguagem em uma variedade de modelos de idiomas, incluindo: (1) Assistente útil e inofensivo (HHA), (2) Transformador de senso comum. Em cada experimento, comparamos o A-LOL com outros métodos de gradiente de políticas offline, como clonagem de comportamento ponderado (WBC) e recompensar o ouro (uma versão modificada de um método anterior de ouro). No HHA, também comparamos com os métodos offline RL offline baseados em preferências, incluindo Pro, DPO e implementação padrão de PPO on-line. No geral, os métodos A-LOL são muito estáveis e superam outros métodos na maioria dos experimentos em todas as recompensas.
Instale pacotes: pip install -r requirements.txt
O objetivo é o modelo FineTune LLAMA 7B no conjunto de dados HHA para melhorar a utilidade e a segurança ao responder a consultas difíceis do usuário. Reutilizamos os modelos de dados e recompensa do Pro.
Como obter o conjunto de dados de tarefas de assistente inofensivo e útil?
wget https://ylab-mobile-prod.oss-cn-beijing.aliyuncs.com/yueli.ybw/data.zipdata/ pasta. As pastas hh_dev , hh_test , hh_train_len2 devem estar presentes na pasta data/ .python data_cleaning.py Como treinar modelos com recompensa e vantagem com base nos métodos Offline RL?
python lolrl_qlora_llama_hh.py
Parâmetros e opções:
--algorithm : opções - ['nll', 'wbc', 'r_gold', 'r_lol', 'a_lol', 'a_lol_ref_free', 'a_lol_seq', 'a_lol_kl']--sampling_strategy : padrão None . Opção good_priority a ser usada com vantagem ou recompensa com base em RL offline--ppo_clip : padrão 0.9 . Parâmetro de clipe PPO para R-Lol, A-Lol e A-Lol seq--kl_beta : padrão 0.0 . Parâmetro beta kl para a-lol kl. Quando o KL for usado, certifique -se de definir PPO_CLIP como 0.0Como treinar modelos com métodos offline baseados em preferências?
python dpo_qlora_llama_hh.py --output_dir "./checkpoints/dpo_qlora_llama/" . Adicionar --reference_free para testar a versão sem referência do DPO.python pro_qlora_llama_hh.py --output_dir "./checkpoints/pro_qlora_llama/"Como treinar modelos com métodos de RL online?
python ppo_qlora_llama_hh.py --output_dir "checkpoints/ppo_timdettmers_qlora_llama_6e/" --cache_dir "cache/ppo_tim_cache" --total_steps 6000python ppo_hh_eval.py --model_name_or_path "reciprocate/ppo_hh_pythia-6B" --output_dir "checkpoints/ppo_hh_pythia_6B/" Como avaliar algum modelo QLORA no conjunto de testes?
python qlora_llama_hh_eval.py --adapter_path [PATH_TO_ADAPTER] --output_dir [OUTPUT_DIR]
Carregou adaptadores pré -ridados para uma tarefa assistente útil e inofensiva, desde os melhores métodos até o Huggingface
O objetivo é melhorar o raciocínio de senso comum do modelo de cometa em dados atômicos^10x usando o classificador crítico do cometa como a função de recompensa.
data/symbolic_knowledge_distillation/python convert_keras_roberta_to_huggingface.pySalvou o classificador final como Robertamodel, tokenizer e Cabeça de Classificação Custom com ativações específicas em
saved_models/comet_critic_keras_to_pytorch.
O classificador é salvo no arquivo "Custom_roBerta_classification_head.pt" na pasta
Inicialize o chefe de classificação da seguinte forma: RobertacLassificationhead (1024, 512, 1)
python preprocess_comet_and_add_rewards.py -i data/symbolic_knowledge_distillation/downloaded -it data/symbolic_knowledge_distillation/atomic2020/atomic2020_data-feb2021/ -ccm saved_models/comet_critic_keras_to_pytorch -o data/comet_rewarded/ -bs 32 python train_generation_task_with_off_policy_PG.py -i data/comet_rewarded/ -tn COMET -m data/symbolic_knowledge_distillation/downloaded/comet-distill/ -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -mt data/symbolic_knowledge_distillation/downloaded/comet-distill-tokenizer/ -ccm saved_models/comet_critic_keras_to_pytorch -ml 30 -algo [ALGORITHM] -vf 16 -e 1 -bs 16 -as 1 -v_bs 32 -t -ev_b
Opções do algoritmo: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'comet_distill': True}" -tn COMET -o final_results/comet_final_results.csv
O objetivo é treinar um modelo de diálogo do Reddit que melhora simultaneamente 5 aspectos: fluência, segurança, engajamento, probabilidade e diversidade votos. Empregamos classificadores de sequência pré-existente para cada atributo e somamos todas as pontuações em uma recompensa escalar final. Para testar a robustez do A-Lol em direção a dados barulhentos, criamos duas divisões de dados de treinamento: (1) apenas comentários votados e (2) apenas comentários descendentes.
Download de dados: Faça o download dos pares de comentários do Reddit upvotted e descendente de: https://www.kaggle.com/code/danofer/reddit-commments-nlp/input
Comentários positivos Pontuação 10 percentil: [66,0, 72,0, 79,0, 88,0, 100,0, 116,0, 139,0, 174,0, 236,0, 385.0, 9582.0]
Comentários negativos pontuam 10 percentil: [-2946.0, -25.0, -18.0, -14.0, -12.0, -10.0, -9.0, -8,0, -8,0, -7,0, -6.0]
Previsão de recompensa: baixe os classificadores do Toxichat e salve -os em saved_models
python preprocess_reddit_comment_scores_and_add_rewards.py -i data/reddit_comment_scores_kaggle/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -o data/reddit_comment_scores_kaggle/preprocessed
Política de referência da NLL de diálogo de diálogo de trem em Reddit Upvotted ( reddit_pos ) e DOWNVET ( reddit_neg ) Comentários
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_pos -m microsoft/DialoGPT-medium -s saved_models/reddit_pos/dgpt_nll -o final_results/reddit_pos/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_neg -m microsoft/DialoGPT-medium -s saved_models/reddit_neg/dgpt_nll -o final_results/reddit_neg/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Opções Task_name: ["reddit_pos", "reddit_neg"]
Opções do algoritmo: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_pos -o final_results/reddit_pos_final_results.csv
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_neg -o final_results/reddit_neg_final_results.csvO objetivo é treinar um modelo de diálogo fundamentado no conhecimento fiel que melhora simultaneamente 4 aspectos: fidelidade, fluência, engajamento e diversidade. Empregamos classificadores de sequência pré-existente para cada atributo e somamos todas as pontuações em uma recompensa escalar final. Novamente, usamos três divisões de dados diferentes: (1) Wizards of Wikipedia (WOW) - Qualidade barulhenta/baixa, (2) FaithDial - mais limpa e (3) wow + FaithDial.
python preprocess_wow_and_add_rewards.py -i [TASK_NAME] -o data/[TASK_NAME]/preprocessed_and_rewarded/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -bs 32["wow", "faithdial", "faithdial_wow"]python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m microsoft/DialoGPT-medium -s saved_models/[TASK_NAME]/dgpt_nll -o final_results/[TASK_NAME]/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32["wow", "faithdial", "faithdial_wow"] python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Task_name Options: ["wow", "faithdial", "faithdial_wow"]
Opções do algoritmo: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'dgpt_nll': True}" -tn [TASK_NAME] -o final_results/[TASK_NAME]_final_results.csv
Task_name Options: ["wow", "faithdial", "faithdial_wow"]
Papel: https://openreview.net/pdf?id=zdgkpbf0vq
@inproceedings{
baheti2024improving,
title={Leftover-Lunch: Advantage-based Offline Reinforcement Learning for Language Models},
author={Ashutosh Baheti and Ximing Lu and Faeze Brahman and Ronan Le Bras and Maarten Sap and Mark Riedl},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=ZDGKPbF0VQ}
}


