LoL RL
1.0.0
Kami memperkenalkan algoritma RL offline baru untuk fine-tuning model bahasa yang dapat menggabungkan nilai nyata? Fungsi hadiah pada data bahasa yang sudah ada sebelumnya.
Asumsi? Menggunakan asumsi ini kami memperoleh estimasi nilai tingkat urutan dari kebijakan referensi dengan kinerja set validasinya. Kebijakan referensi dalam kasus kami hanyalah model SFT Finetuned dengan negatif log kemungkinan (NLL) yaitu kloning perilaku. Persamaan pembelajaran akhir untuk A-LOL terlihat seperti: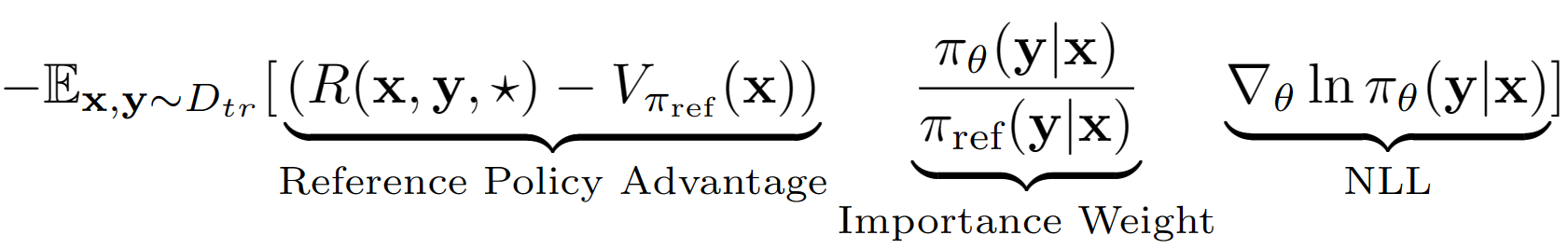
Dengan menggunakan estimasi nilai kebijakan referensi, kami menemukan subset dari set pelatihan yang masih memiliki keuntungan positif (yaitu makan siang sisa?) Dan hanya berlatih pada subset itu dengan pengambilan sampel yang diprioritaskan. Kami juga menguji tiga varian A-LOL dengan memodifikasi istilah berat badan yang penting- A-LOL Ref-Free, A-Lol SEQ, A-Lol KL (lebih detail dalam kertas). Secara keseluruhan, A-Lol sangat mudah diimplementasikan? Di atas finetuning NLL standar dan menghasilkan sampel yang stabil dan efisien? Algoritma RL offline yang dapat menggabungkan fungsi hadiah dan sumber data apa pun.
Karena fleksibilitas A-LOL untuk menggabungkan fungsi penghargaan sewenang-wenang dan sumber data?, Kami melatih model bahasa pada berbagai tugas model bahasa termasuk: (1) Asisten yang membantu dan tidak berbahaya (HHA), (2) Tugas Generasi Transformator (4) Generasi Generasi yang Berdasar dengan 4 Generasi. Dalam setiap percobaan, kami membandingkan A-LOL dengan metode gradien kebijakan offline lainnya seperti kloning perilaku tertimbang (WBC) dan hadiah emas (versi modifikasi dari metode emas sebelumnya). Dalam HHA, kami juga membandingkan dengan metode RL offline berbasis preferensi populer termasuk Pro, DPO dan implementasi PPO online standar. Secara keseluruhan, metode A-LOL sangat stabil dan mengungguli metode lain di sebagian besar percobaan di semua penghargaan.
Instal Paket: pip install -r requirements.txt
Tujuannya adalah untuk finetune llama 7b model pada dataset HHA untuk meningkatkan bantuan dan keamanan saat menanggapi pertanyaan pengguna yang sulit. Kami menggunakan kembali data dan menghargai model dari Pro.
Bagaimana cara mendapatkan dataset Asisten Tugas yang tidak berbahaya dan membantu?
wget https://ylab-mobile-prod.oss-cn-beijing.aliyuncs.com/yueli.ybw/data.zipdata/ folder. Folder hh_dev , hh_test , hh_train_len2 harus ada dalam data/ folder.python data_cleaning.py Bagaimana cara melatih model dengan imbalan dan keuntungan berdasarkan metode RL offline?
python lolrl_qlora_llama_hh.py
Parameter dan Opsi:
--algorithm : Opsi - ['nll', 'wbc', 'r_gold', 'r_lol', 'a_lol', 'a_lol_ref_free', 'a_lol_seq', 'a_lol_kl']--sampling_strategy : Default None . Opsi good_priority untuk digunakan dengan keuntungan atau hadiah berdasarkan RL Offline--ppo_clip : default 0.9 . Parameter klip PPO untuk R-LOL, A-LOL dan A-LOL SEQ--kl_beta : default 0.0 . Parameter beta KL untuk a-lol KL. Saat KL digunakan, pastikan untuk mengatur ppo_clip ke 0,0Bagaimana cara melatih model dengan metode RL offline berbasis preferensi?
python dpo_qlora_llama_hh.py --output_dir "./checkpoints/dpo_qlora_llama/" . Tambahkan --reference_free untuk menguji versi DPO yang bebas referensi.python pro_qlora_llama_hh.py --output_dir "./checkpoints/pro_qlora_llama/"Bagaimana cara melatih model dengan metode RL online?
python ppo_qlora_llama_hh.py --output_dir "checkpoints/ppo_timdettmers_qlora_llama_6e/" --cache_dir "cache/ppo_tim_cache" --total_steps 6000python ppo_hh_eval.py --model_name_or_path "reciprocate/ppo_hh_pythia-6B" --output_dir "checkpoints/ppo_hh_pythia_6B/" Bagaimana cara mengevaluasi model qlora pada set tes?
python qlora_llama_hh_eval.py --adapter_path [PATH_TO_ADAPTER] --output_dir [OUTPUT_DIR]
Diunggah adaptor pretrained untuk tugas asisten yang membantu dan tidak berbahaya dari metode terbaik untuk memeluk
Tujuannya adalah untuk meningkatkan penalaran akal sehat model komet pada data atom^10x dengan menggunakan classifier comet-critik sebagai fungsi hadiah.
data/symbolic_knowledge_distillation/python convert_keras_roberta_to_huggingface.pyMenyimpan classifer akhir sebagai Robertamodel, tokenizer dan kepala klasifikasi kustom dengan aktivasi spesifik di
saved_models/comet_critic_keras_to_pytorch.
Classifier disimpan di file "custom_roberta_classification_head.pt" di dalam folder
Inisialisasi Kepala Klasifikasi sebagai berikut: RobertacLasificationHead (1024, 512, 1)
python preprocess_comet_and_add_rewards.py -i data/symbolic_knowledge_distillation/downloaded -it data/symbolic_knowledge_distillation/atomic2020/atomic2020_data-feb2021/ -ccm saved_models/comet_critic_keras_to_pytorch -o data/comet_rewarded/ -bs 32 python train_generation_task_with_off_policy_PG.py -i data/comet_rewarded/ -tn COMET -m data/symbolic_knowledge_distillation/downloaded/comet-distill/ -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -mt data/symbolic_knowledge_distillation/downloaded/comet-distill-tokenizer/ -ccm saved_models/comet_critic_keras_to_pytorch -ml 30 -algo [ALGORITHM] -vf 16 -e 1 -bs 16 -as 1 -v_bs 32 -t -ev_b
Opsi algoritma: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'comet_distill': True}" -tn COMET -o final_results/comet_final_results.csv
Tujuannya adalah untuk melatih model dialog Reddit yang secara bersamaan meningkatkan 5 aspek: kefasihan, keamanan, keterlibatan, probabilitas Upvote dan keragaman. Kami menggunakan pengklasifikasi urutan yang sudah ada sebelumnya untuk setiap atribut dan jumlah semua skor menjadi hadiah skalar akhir. Untuk menguji kekokohan A-LOL terhadap data yang berisik, kami membuat dua pemisahan data pelatihan: (1) hanya komentar yang diinveksi dan (2) hanya komentar yang diturunkan.
Unduh Data: Unduh pasangan komentar Reddit yang upvoted dan downvoted dari: https://www.kaggle.com/code/danofer/reddit-comments-sores-nlp/input
Skor Komentar Positif 10 Persentil: [66.0, 72.0, 79.0, 88.0, 100.0, 116.0, 139.0, 174.0, 236.0, 385.0, 9582.0]
Skor Komentar Negatif 10 Persentil: [-2946.0, -25.0, -18.0, -14.0, -12.0, -10.0, -9.0, -8.0, -8.0, -7.0, -6.0]
Prediksi Hadiah: Unduh pengklasifikasi Toksichat dan simpan di saved_models
python preprocess_reddit_comment_scores_and_add_rewards.py -i data/reddit_comment_scores_kaggle/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -o data/reddit_comment_scores_kaggle/preprocessed
Kebijakan referensi NLL dialogpt-medium kereta pada reddit upvoted ( reddit_pos ) dan downvoted ( reddit_neg ) Komentar
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_pos -m microsoft/DialoGPT-medium -s saved_models/reddit_pos/dgpt_nll -o final_results/reddit_pos/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_neg -m microsoft/DialoGPT-medium -s saved_models/reddit_neg/dgpt_nll -o final_results/reddit_neg/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Opsi Tugas_name: ["reddit_pos", "reddit_neg"]
Opsi algoritma: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_pos -o final_results/reddit_pos_final_results.csv
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_neg -o final_results/reddit_neg_final_results.csvTujuannya adalah untuk melatih model dialog yang setia, yang secara bersamaan meningkatkan 4 aspek: kesetiaan, kelancaran, keterlibatan, dan keragaman. Kami menggunakan pengklasifikasi urutan yang sudah ada sebelumnya untuk setiap atribut dan jumlah semua skor menjadi hadiah skalar akhir. Kami sekali lagi menggunakan tiga pemisahan data yang berbeda: (1) Wizards of Wikipedia (wow) - berisik/berkualitas rendah, (2) FaithDial - Cleaner dan (3) Wow + FaithDial.
python preprocess_wow_and_add_rewards.py -i [TASK_NAME] -o data/[TASK_NAME]/preprocessed_and_rewarded/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -bs 32["wow", "faithdial", "faithdial_wow"]python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m microsoft/DialoGPT-medium -s saved_models/[TASK_NAME]/dgpt_nll -o final_results/[TASK_NAME]/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32["wow", "faithdial", "faithdial_wow"] python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Opsi Tugas_name: ["wow", "faithdial", "faithdial_wow"]
Opsi algoritma: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'dgpt_nll': True}" -tn [TASK_NAME] -o final_results/[TASK_NAME]_final_results.csv
Opsi Tugas_name: ["wow", "faithdial", "faithdial_wow"]
Kertas: https://openreview.net/pdf?id=zdgkpbf0vq
@inproceedings{
baheti2024improving,
title={Leftover-Lunch: Advantage-based Offline Reinforcement Learning for Language Models},
author={Ashutosh Baheti and Ximing Lu and Faeze Brahman and Ronan Le Bras and Maarten Sap and Mark Riedl},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=ZDGKPbF0VQ}
}


