LoL RL
1.0.0
Wir stellen einen neuen Offline-RL-Algorithmus für die Feinabstimmung des Sprachmodells ein, die einen echten Wert enthalten kann? Belohnungsfunktion für bereits bestehende Sprachdaten.
Die Annahme des Keys ist, die gesamte Ausgangssequenz von LM als einzelne Aktion im RL -Setup zu behandeln. Unter Verwendung dieser Annahme erhalten wir eine Wertschätzung der Sequenzniveau der Referenzrichtlinie mit ihrer Validierungssatzleistung. Die Referenzrichtlinie in unserem Fall ist einfach das SFT -Modell, das mit negativer Log -Wahrscheinlichkeit (NLL), dh Verhaltenskloning, beendet ist. Die letzte Lerngleichung für A-LOL sieht aus wie: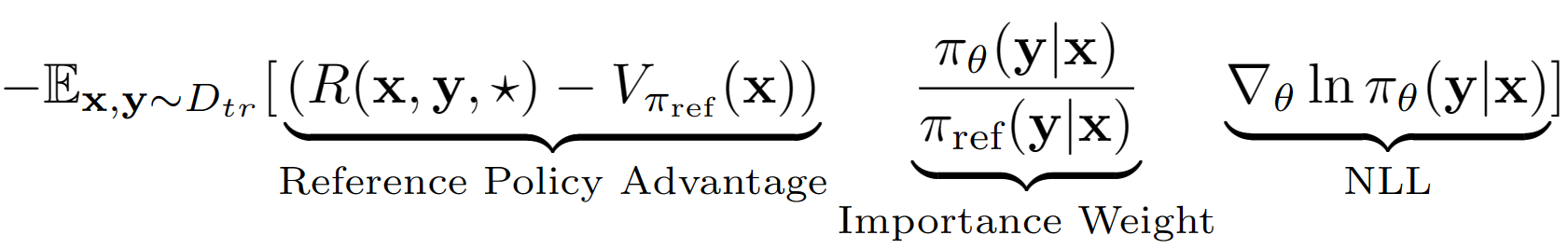
Unter Verwendung der Referenzpolitik -Wertschätzung finden wir die Teilmenge des Trainingssatzes, die noch positivem Vorteil (dh übrig gebliebenes Mittagessen?) Und nur mit priorisierter Stichproben auf dieser Teilmenge trainieren. Wir testen zusätzlich drei Varianten von A-LOL, indem wir den Wichtigkeitsgewichtsbegriff- A-Lol Ref-Free, A-LOL SEQ, A-LOL KL (weitere Details in der Arbeit) ändern. Insgesamt ist A-LOL sehr einfach zu implementieren? Über die Standard -NLL -Finetuning und führt zu einer stabilen und probeneffizienten Probe? Offline -RL -Algorithmus, der jede Belohnungsfunktion und Datenquelle enthalten kann.
Aufgrund der Flexibilität von A-LOL, willkürliche Belohnungsfunktionen und Datenquellen einzubeziehen, schulen wir Sprachmodelle zu einer Vielzahl von Aufgaben von Sprachmodellen, darunter: (1) hilfreiche und harmlose Assistent (HHA), (2) CommonSense-Transformator (Comet) -Gergeneration, (3) Aufgabe der Reddit-Reaktion mit 5 differenzierten Prämien, (4) Gläubige Wissensgenerierungsaufgaben mit 4-Wiederholungen mit 4-Rewardogs-Erzeugung. In jedem Experiment vergleichen wir A-LOL mit anderen Offline-Richtliniengradientenmethoden wie gewichteten Verhaltensklonen (WBC) und Belohnung Gold (eine modifizierte Version einer früheren Methode Gold). In HHA vergleichen wir uns auch mit beliebten Präferenz-Offline-RL-Methoden wie Pro, DPO und Standard-Online-PPO-Implementierung. Insgesamt sind A-LOL-Methoden sehr stabil und übertreffen andere Methoden in den meisten Experimenten über alle Belohnungen hinweg.
Pakete installieren: pip install -r requirements.txt
Ziel ist es, das Lama 7B -Modell des HHA -Datensatzes zu finanzieren, um die Hilfsmaßnahmen und Sicherheit zu verbessern, wenn sie auf schwierige Benutzeranfragen reagieren. Wir verwenden die Daten und belohnen Modelle von Pro.
Wie bekomme ich harmlose und hilfsbereite Assistant -Task -Datensatz?
wget https://ylab-mobile-prod.oss-cn-beijing.aliyuncs.com/yueli.ybw/data.zipdata/ Ordner. Die Ordner hh_dev , hh_test , hh_train_len2 sollten in data/ Ordner vorhanden sein.python data_cleaning.py Wie trainiere ich Modelle mit Belohnung und Vorteil basierend Offline -RL -Methoden?
python lolrl_qlora_llama_hh.py
Parameter und Optionen:
--algorithm : Optionen - ['nll', 'wbc', 'r_gold', 'r_lol', 'a_lol', 'a_lol_ref_free', 'a_lol_seq', 'a_lol_kl']--sampling_strategy : Standard None . Option good_priority , die mit Vorteil oder Belohnung basierend Offline RL verwendet werden muss--ppo_clip : Standard 0.9 . PPO-Clip-Parameter für R-LOL, A-LOL und A-LOL SEQ--kl_beta : Standard 0.0 . KL Beta-Parameter für a-lol KL. Wenn KL verwendet wirdWie trainiere ich Modelle mit Präferenz-basierten Offline-RL-Methoden?
python dpo_qlora_llama_hh.py --output_dir "./checkpoints/dpo_qlora_llama/" . Fügen Sie --reference_free hinzu, um die referenzfreie Version von DPO zu testen.python pro_qlora_llama_hh.py --output_dir "./checkpoints/pro_qlora_llama/"Wie trainiere ich Modelle mit Online -RL -Methoden?
python ppo_qlora_llama_hh.py --output_dir "checkpoints/ppo_timdettmers_qlora_llama_6e/" --cache_dir "cache/ppo_tim_cache" --total_steps 6000python ppo_hh_eval.py --model_name_or_path "reciprocate/ppo_hh_pythia-6B" --output_dir "checkpoints/ppo_hh_pythia_6B/" Wie bewerten Sie ein Qlora -Modell am Testsatz?
python qlora_llama_hh_eval.py --adapter_path [PATH_TO_ADAPTER] --output_dir [OUTPUT_DIR]
Hochgeladene vorgeladene Adapter für hilfreiche und harmlose Assistentenaufgaben von den besten Methoden bis hin zum Umarmungsface
Ziel ist es, vernünftige Argumentation des Kometenmodells auf Atomic^10x-Daten zu verbessern, indem Comet-Critic-Klassifikator als Belohnungsfunktion verwendet wird.
data/symbolic_knowledge_distillation/python convert_keras_roberta_to_huggingface.pySpeicherte den endgültigen Klassifer als Robertamodel, Tokenizer und benutzerdefinierte Klassifizierungskopf mit spezifischen Aktivierungen unter
saved_models/comet_critic_keras_to_pytorch.
Der Klassifizierer wird in der Datei "custom_roberta_classification_head.pt" im Ordner gespeichert
Initialisieren Sie den Klassifizierungskopf wie folgt: Robertaclassificationhead (1024, 512, 1)
python preprocess_comet_and_add_rewards.py -i data/symbolic_knowledge_distillation/downloaded -it data/symbolic_knowledge_distillation/atomic2020/atomic2020_data-feb2021/ -ccm saved_models/comet_critic_keras_to_pytorch -o data/comet_rewarded/ -bs 32 python train_generation_task_with_off_policy_PG.py -i data/comet_rewarded/ -tn COMET -m data/symbolic_knowledge_distillation/downloaded/comet-distill/ -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -mt data/symbolic_knowledge_distillation/downloaded/comet-distill-tokenizer/ -ccm saved_models/comet_critic_keras_to_pytorch -ml 30 -algo [ALGORITHM] -vf 16 -e 1 -bs 16 -as 1 -v_bs 32 -t -ev_b
Algorithmoptionen: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'comet_distill': True}" -tn COMET -o final_results/comet_final_results.csv
Ziel ist es, ein Reddit -Dialogmodell auszubilden, das gleichzeitig 5 Aspekte verbessert: Fließfähigkeit, Sicherheit, Engagement, Wahrscheinlichkeit und Vielfalt. Wir verwenden bereits vorhandene Sequenzklassifizierer für jedes Attribut und summieren alle Ergebnisse zu einer endgültigen skalaren Belohnung. Um die Robustheit von A-LOL gegenüber lauten Daten zu testen, erstellen wir zwei Trainingsdaten-Splits: (1) Nur aufgelagerte Kommentare und (2) nur heruntergekommene Kommentare.
Daten herunterladen: Laden Sie die upvoted und downvoted Reddit-Kommentarpaare herunter: https://www.kaggle.com/code/danofer/reddit-comments-scores-nlp/input
Positive Kommentare erzielen 10 Perzentil: [66,0, 72,0, 79,0, 88,0, 100,0, 116,0, 139,0, 174,0, 236,0, 385,0, 9582.0]
Negative Kommentare Punktzahl 10 Perzentil: [-2946.0, -25,0, -18.0, -14.0, -12.0, -10,0, -9.0, -8,0, -8,0, -7,0, -6,0]
Prämienvorhersage: Laden Sie die Toxichat -Klassifizierer herunter und speichern Sie sie in saved_models
python preprocess_reddit_comment_scores_and_add_rewards.py -i data/reddit_comment_scores_kaggle/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -o data/reddit_comment_scores_kaggle/preprocessed
Zug-Dialogpt-Medium-NLL-Referenzrichtlinie zu Reddit Upvoted ( reddit_pos ) und Downvoted ( reddit_neg ) Kommentaren
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_pos -m microsoft/DialoGPT-medium -s saved_models/reddit_pos/dgpt_nll -o final_results/reddit_pos/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn reddit_neg -m microsoft/DialoGPT-medium -s saved_models/reddit_neg/dgpt_nll -o final_results/reddit_neg/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32
python train_generation_task_with_off_policy_PG.py -i data/reddit_comment_scores_kaggle/preprocessed -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -ucm microsoft/DialogRPT-updown -dcm microsoft/DialogRPT-depth -om saved_models/DGPT_medium_OC_S_and_SBF_offensive_e2 -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Task_name -Optionen: ["reddit_pos", "reddit_neg"]
Algorithmoptionen: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_pos -o final_results/reddit_pos_final_results.csv
python aggregate_generation_task_results.py -bmps " {'dgpt_nll': True} " -tn reddit_neg -o final_results/reddit_neg_final_results.csvDas Ziel ist es, ein treu geerdetes Dialogmodell auszubilden, das gleichzeitig 4 Aspekte verbessert: Treue, Flüssigkeit, Engagement und Vielfalt. Wir verwenden bereits vorhandene Sequenzklassifizierer für jedes Attribut und summieren alle Ergebnisse zu einer endgültigen skalaren Belohnung. Wir verwenden erneut drei verschiedene Datenspaltungen: (1) Assistenten von Wikipedia (WOW) - Laut/geringer Qualität, (2) treue - sauberer und (3) WOW + Feuchtigkeit.
python preprocess_wow_and_add_rewards.py -i [TASK_NAME] -o data/[TASK_NAME]/preprocessed_and_rewarded/ -m microsoft/DialoGPT-medium -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -bs 32["wow", "faithdial", "faithdial_wow"]python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m microsoft/DialoGPT-medium -s saved_models/[TASK_NAME]/dgpt_nll -o final_results/[TASK_NAME]/dgpt_nll/train_log -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo nll -vf 2 -e 6 -t -bs 8 -as 2 -v_bs 32["wow", "faithdial", "faithdial_wow"] python train_generation_task_with_off_policy_PG.py -i data/[TASK_NAME]/preprocessed_and_rewarded/ -tn [TASK_NAME] -m saved_models/[TASK_NAME]/dgpt_nll -s [MODEL_SAVE_DIR] -o [OUTPUT_DIR] -cm textattack/roberta-base-CoLA -fcm McGill-NLP/roberta-large-faithcritic -dcm microsoft/DialogRPT-depth -algo [ALGORITHM] -vf 2 -e 3 -bs 8 -as 2 -v_bs 32 -t -ev_b
Task_Name Optionen: ["wow", "faithdial", "faithdial_wow"]
Algorithmoptionen: ["nll", "wbc", "r_gold", "r_lol", "a_lol", "a_lol_ref_free", "a_lol_seq", "a_lol_kl"]
python aggregate_generation_task_results.py -bmps "{'dgpt_nll': True}" -tn [TASK_NAME] -o final_results/[TASK_NAME]_final_results.csv
Task_Name Optionen: ["wow", "faithdial", "faithdial_wow"]
Papier: https://openreview.net/pdf?id=zdgkpbf0vq
@inproceedings{
baheti2024improving,
title={Leftover-Lunch: Advantage-based Offline Reinforcement Learning for Language Models},
author={Ashutosh Baheti and Ximing Lu and Faeze Brahman and Ronan Le Bras and Maarten Sap and Mark Riedl},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=ZDGKPbF0VQ}
}


