OAG BERT
1.0.0

庫|紙|鬆弛
我們在COGDL軟件包中發布了兩個版本的Oag-Bert(由於先前的Tsinghua雲磁盤下載到期,請立即從ModelsCope手動下載模型)。 OAG-BERT是一種異質實體的學術語言模型,不僅了解OAG中的學術文本,而且了解異質的實體知識。加入我們的Slack或Google Group以獲取任何評論和請求!我們的論文在這裡。
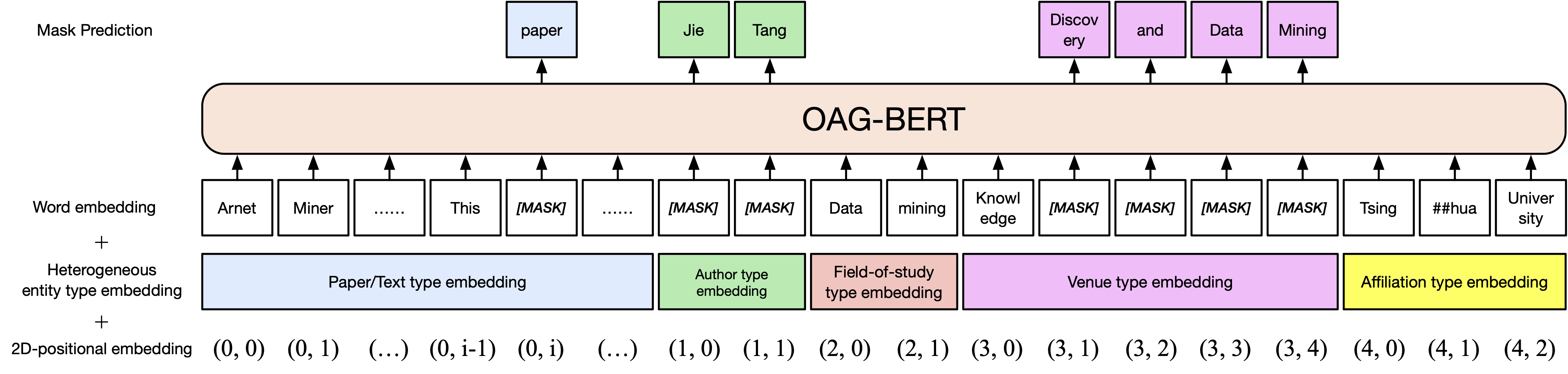
基本版本Oag-Bert。與Scibert類似,我們在開放學術圖中預先培訓BERT模型,包括紙張標題,摘要和身體。
Oag-Bert的使用是普通Scibert或Bert的。例如,您可以使用以下代碼編碼兩個文本序列並檢索其輸出
from cogdl . oag import oagbert
tokenizer , bert_model = oagbert ()
sequence = [ "CogDL is developed by KEG, Tsinghua." , "OAGBert is developed by KEG, Tsinghua." ]
tokens = tokenizer ( sequence , return_tensors = "pt" , padding = True )
outputs = bert_model ( ** tokens )香草Oag-Bert的擴展。我們將豐富的實體信息納入開放式學術圖中,例如作者和研究領域。因此,您可以在Oag-Bert V2中編碼各種類型的實體。例如,要編碼伯特的論文,您可以使用以下代碼
from cogdl . oag import oagbert
import torch
tokenizer , model = oagbert ( "oagbert-v2" )
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# build model inputs
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# run forward
sequence_output , pooled_output = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)您還可以使用一些集成功能直接使用OAG-BERT V2,例如使用decode_beamsearch基於現有上下文來生成實體。例如,要用2個令牌生成概念,請運行以下代碼
model . eval ()
candidates = model . decode_beamsearch (
title = title ,
abstract = abstract ,
venue = venue ,
authors = authors ,
affiliations = affiliations ,
decode_span_type = 'FOS' ,
decode_span_length = 2 ,
beam_width = 8 ,
force_forward = False
)Oag-Bert在廣泛的實體感知任務上超越了其他學術語言模型,同時保持其在普通NLP任務上的性能。
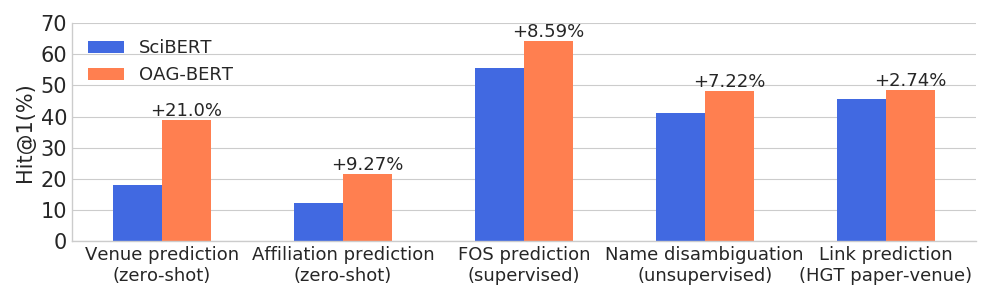
我們還為用戶發布了另外兩個V2版本。
一個是基於一代的版本,可用於基於其他信息生成文本。例如,使用以下代碼自動生成帶有摘要的紙質標題。
from cogdl . oag import oagbert
tokenizer , model = oagbert ( 'oagbert-v2-lm' )
model . eval ()
for seq , prob in model . generate_title ( abstract = "To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations for NSFC (National Nature Science Foundation of China) and paper tagging in the AMiner system. It is also available to the public through the CogDL package." ):
print ( 'Title: %s' % seq )
print ( 'Perplexity: %.4f' % prob )
# One of our generations: "pre-training oag-bert: an academic language model for enriching academic texts with domain knowledge"除此之外,我們還根據名稱歧義任務來計算紙張相似性,以計算Oag-Bert,該任務被稱為句子 - 奧格伯特之後。以下代碼展示了使用句子 - 奧格伯特計算紙張相似性的示例。
import os
from cogdl . oag import oagbert
import torch
import torch . nn . functional as F
import numpy as np
# load time
tokenizer , model = oagbert ( "oagbert-v2-sim" )
model . eval ()
# Paper 1
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# encode first paper
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
_ , paper_embed_1 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Positive Paper 2
title = 'Attention Is All You Need'
abstract = 'We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely...'
authors = [ 'Ashish Vaswani' , 'Noam Shazeer' , 'Niki Parmar' , 'Jakob Uszkoreit' ]
venue = 'neural information processing systems'
affiliations = [ 'Google' ]
concepts = [ 'machine translation' , 'computation and language' , 'language model' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode second paper
_ , paper_embed_2 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Negative Paper 3
title = "Traceability and international comparison of ultraviolet irradiance"
abstract = "NIM took part in the CIPM Key Comparison of ″Spectral Irradiance 250 to 2500 nm″. In UV and NIR wavelength, the international comparison results showed that the consistency between Chinese value and the international reference one"
authors = [ 'Jing Yu' , 'Bo Huang' , 'Jia-Lin Yu' , 'Yan-Dong Lin' , 'Cai-Hong Dai' ]
veune = 'Jiliang Xuebao/Acta Metrologica Sinica'
affiliations = [ 'Department of Electronic Engineering' ]
concept = [ 'Optical Division' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode thrid paper
_ , paper_embed_3 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# calulate text similarity
# normalize
paper_embed_1 = F . normalize ( paper_embed_1 , p = 2 , dim = 1 )
paper_embed_2 = F . normalize ( paper_embed_2 , p = 2 , dim = 1 )
paper_embed_3 = F . normalize ( paper_embed_3 , p = 2 , dim = 1 )
# cosine sim.
sim12 = torch . mm ( paper_embed_1 , paper_embed_2 . transpose ( 0 , 1 ))
sim13 = torch . mm ( paper_embed_1 , paper_embed_3 . transpose ( 0 , 1 ))
print ( sim12 , sim13 )這種微調是關於Whoisho Who Name Digammuation任務的。同一作者撰寫的論文被視為正面,其餘的是負對。我們採樣了0.4m的陽性對和1.6m負對,並使用約束學習來微調Oag-Bert(版本2)。對於50%的情況,我們僅使用紙質標題,而其他50%使用所有異質信息。我們使用平均互惠等級評估績效,其中較高的值表明結果更好。測試集的性能如下所示。
| Oagbert-V2 | Oagbert-V2-SIM | |
|---|---|---|
| 標題 | 0.349 | 0.725 |
| 標題+摘要+作者+AFF+場地 | 0.355 | 0.789 |
有關更多詳細信息,請參閱cogdl中的示例/oagbert_metainfo.py。
我們還培訓了中國的Oagbert供使用。該模型已在包括4400萬份紙元數據在內的語料庫中進行了預培訓,包括標題,摘要,作者,分支機構,場地,關鍵字和資金。新實體基金的擴展超出了英語版本中使用的實體。此外,中國奧格伯特接受了句子令牌訓練。這是英國Oagbert和中國Oagbert之間的兩個主要區別。
可以在示例/oagbert/oagbert_metainfo_zh.py和示例中找到使用原始中國oagbert和句子 - 奧格伯特的示例。與英語句子 - 奧格伯特類似,中文句子 - 奧格伯特的名稱歧義任務是微調的,用於計算紙張嵌入相似性。性能如下所示。如果下游任務沒有足夠的數據進行微調,我們建議用戶直接使用此版本。
| Oagbert-V2-ZH | OAGBERT-V2-ZH-SIM | |
|---|---|---|
| 標題 | 0.337 | 0.619 |
| 標題+摘要 | 0.314 | 0.682 |
如果您發現它有用,請在您的工作中引用我們:
@article{xiao2021oag,
title={OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Model},
author={Liu, Xiao and Yin, Da and Zhang, Xingjian and Su, Kai and Wu, Kan and Yang, Hongxia and Tang, Jie},
journal={arXiv preprint arXiv:2103.02410},
year={2021}
}
@inproceedings{zhang2019oag,
title={OAG: Toward Linking Large-scale Heterogeneous Entity Graphs.},
author={Zhang, Fanjin and Liu, Xiao and Tang, Jie and Dong, Yuxiao and Yao, Peiran and Zhang, Jie and Gu, Xiaotao and Wang, Yan and Shao, Bin and Li, Rui and Wang, Kuansan},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19)},
year={2019}
}
@article{chen2020conna,
title={CONNA: Addressing Name Disambiguation on The Fly},
author={Chen, Bo and Zhang, Jing and Tang, Jie and Cai, Lingfan and Wang, Zhaoyu and Zhao, Shu and Chen, Hong and Li, Cuiping},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2020},
publisher={IEEE}
}


