OAG BERT
1.0.0

مكتبة | ورقة | الركود
أصدرنا نسختين من OAG-Bert في حزمة COGDL (بسبب انتهاء تنزيل Disk Cloud Disk السابق Tsinghua ، يرجى الآن تنزيل النماذج يدويًا من ModelsCope). OAG-Bert هو نموذج لغوي أكاديمي غير متجانس غير متجانس لا يفهم النصوص الأكاديمية فحسب ، بل أيضًا معرفة كيان غير متجانسة في OAG. انضم إلى مجموعة Slack أو Google للحصول على أي تعليقات وطلبات! ورقةنا هنا.
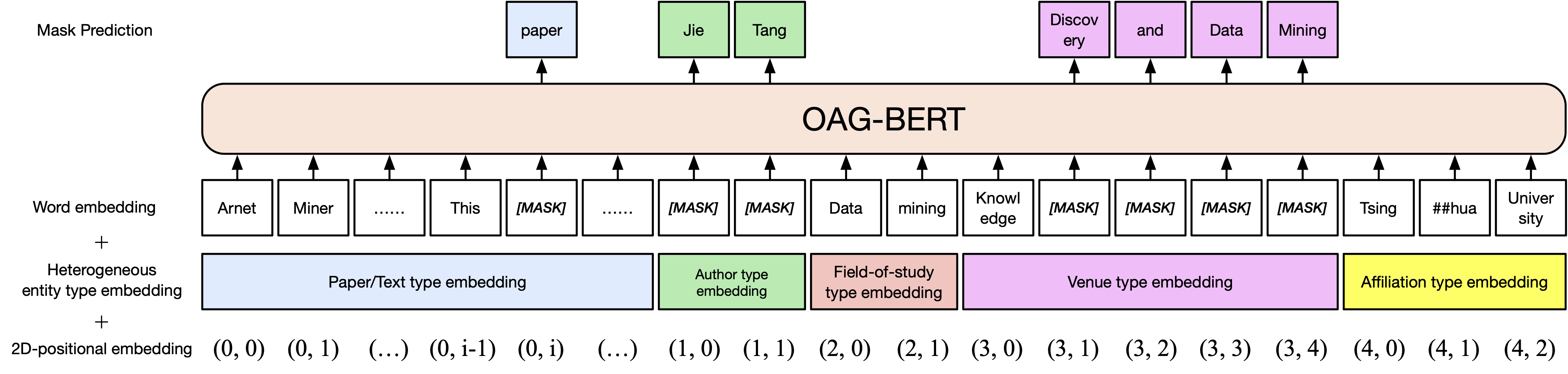
نسخة أساسية oag-bert. على غرار Scibert ، نقوم بتدريب نموذج Bert على مجموعة النص الأكاديمي في الرسم البياني الأكاديمي المفتوح ، بما في ذلك العناوين الورقية والملخصات والهيئات.
استخدام OAG-Bert هو نفسه من Scibert أو Bert العادي. على سبيل المثال ، يمكنك استخدام الكود التالي لترميز تسلسلات نصين واسترداد مخرجاتهما
from cogdl . oag import oagbert
tokenizer , bert_model = oagbert ()
sequence = [ "CogDL is developed by KEG, Tsinghua." , "OAGBert is developed by KEG, Tsinghua." ]
tokens = tokenizer ( sequence , return_tensors = "pt" , padding = True )
outputs = bert_model ( ** tokens )امتداد إلى الفانيليا oag-bert. ندمج معلومات الكيان الغنية في الرسم البياني الأكاديمي المفتوح مثل المؤلفين ومجال الدراسة . وبالتالي ، يمكنك تشفير أنواع مختلفة من الكيانات في OAG-Bert V2. على سبيل المثال ، لتشفير ورقة Bert ، يمكنك استخدام الكود التالي
from cogdl . oag import oagbert
import torch
tokenizer , model = oagbert ( "oagbert-v2" )
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# build model inputs
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# run forward
sequence_output , pooled_output = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
) يمكنك أيضًا استخدام بعض الوظائف المتكاملة لاستخدام OAG-Bert V2 مباشرةً ، مثل استخدام decode_beamsearch لإنشاء كيانات بناءً على السياق الحالي. على سبيل المثال ، لإنشاء مفاهيم مع 2 رمز لورق Bert ، قم بتشغيل الكود التالي
model . eval ()
candidates = model . decode_beamsearch (
title = title ,
abstract = abstract ,
venue = venue ,
authors = authors ,
affiliations = affiliations ,
decode_span_type = 'FOS' ,
decode_span_length = 2 ,
beam_width = 8 ,
force_forward = False
)يتفوق OAG-Bert على نماذج اللغة الأكاديمية الأخرى على مجموعة واسعة من مهام الوعاء الكيانات مع الحفاظ على أدائها في مهام NLP العادية.
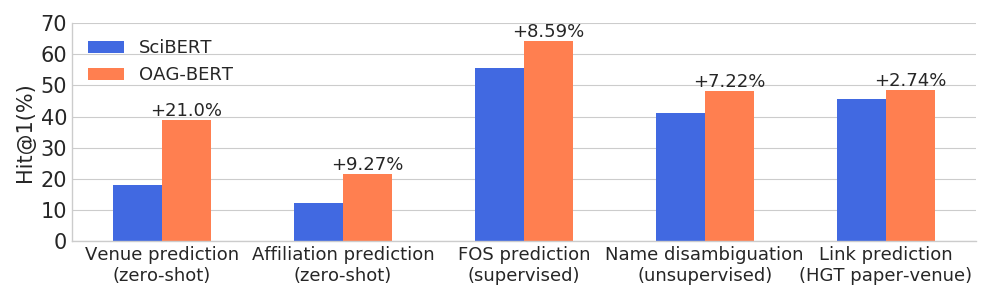
نقوم أيضًا بإصدار إصدارين آخرين V2 للمستخدمين.
إحداها هي نسخة قائمة على الأجيال والتي يمكن استخدامها لإنشاء النصوص على أساس معلومات أخرى. على سبيل المثال ، استخدم الكود التالي لإنشاء عناوين الورق تلقائيًا مع الملخصات.
from cogdl . oag import oagbert
tokenizer , model = oagbert ( 'oagbert-v2-lm' )
model . eval ()
for seq , prob in model . generate_title ( abstract = "To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations for NSFC (National Nature Science Foundation of China) and paper tagging in the AMiner system. It is also available to the public through the CogDL package." ):
print ( 'Title: %s' % seq )
print ( 'Perplexity: %.4f' % prob )
# One of our generations: "pre-training oag-bert: an academic language model for enriching academic texts with domain knowledge"بالإضافة إلى ذلك ، فإننا نتحمل OAG-Bert لحساب التشابه الورقي استنادًا إلى مهام عدم الغموض ، والتي تم تسميتها على أنها جملة-OAGBERT التالية. توضح الرموز التالية مثالًا على استخدام الجملة-Oagbert لحساب تشابه الورق.
import os
from cogdl . oag import oagbert
import torch
import torch . nn . functional as F
import numpy as np
# load time
tokenizer , model = oagbert ( "oagbert-v2-sim" )
model . eval ()
# Paper 1
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# encode first paper
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
_ , paper_embed_1 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Positive Paper 2
title = 'Attention Is All You Need'
abstract = 'We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely...'
authors = [ 'Ashish Vaswani' , 'Noam Shazeer' , 'Niki Parmar' , 'Jakob Uszkoreit' ]
venue = 'neural information processing systems'
affiliations = [ 'Google' ]
concepts = [ 'machine translation' , 'computation and language' , 'language model' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode second paper
_ , paper_embed_2 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Negative Paper 3
title = "Traceability and international comparison of ultraviolet irradiance"
abstract = "NIM took part in the CIPM Key Comparison of ″Spectral Irradiance 250 to 2500 nm″. In UV and NIR wavelength, the international comparison results showed that the consistency between Chinese value and the international reference one"
authors = [ 'Jing Yu' , 'Bo Huang' , 'Jia-Lin Yu' , 'Yan-Dong Lin' , 'Cai-Hong Dai' ]
veune = 'Jiliang Xuebao/Acta Metrologica Sinica'
affiliations = [ 'Department of Electronic Engineering' ]
concept = [ 'Optical Division' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode thrid paper
_ , paper_embed_3 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# calulate text similarity
# normalize
paper_embed_1 = F . normalize ( paper_embed_1 , p = 2 , dim = 1 )
paper_embed_2 = F . normalize ( paper_embed_2 , p = 2 , dim = 1 )
paper_embed_3 = F . normalize ( paper_embed_3 , p = 2 , dim = 1 )
# cosine sim.
sim12 = torch . mm ( paper_embed_1 , paper_embed_2 . transpose ( 0 , 1 ))
sim13 = torch . mm ( paper_embed_1 , paper_embed_3 . transpose ( 0 , 1 ))
print ( sim12 , sim13 )تم إجراء هذا الضبط على مهام عدم الغموض. يتم التعامل مع الأوراق التي كتبها نفس المؤلفين كأزواج إيجابية وتستند كأزواج سلبية. نأخذ عينات من 0.4 متر إيجابية و 1.6 متر سلبية وأزواج سلبية ونستخدم التعلم المركزي لضبط OAG-Bert (الإصدار 2). بالنسبة لحالات 50 ٪ ، نستخدم عنوان الورق فقط بينما يستخدم 50 ٪ الآخرون جميع المعلومات غير المتجانسة. نقوم بتقييم الأداء باستخدام متوسط الترتيب المتبادل حيث تشير القيم العليا إلى نتائج أفضل. يظهر الأداء في مجموعات الاختبار على النحو التالي.
| OAGBERT-V2 | OAGBERT-V2-SIM | |
|---|---|---|
| عنوان | 0.349 | 0.725 |
| العنوان+الملخص+المؤلف+AFF+مكان | 0.355 | 0.789 |
لمزيد من التفاصيل ، راجع الأمثلة/OAGBERT_METAINFO.py في COGDL.
قمنا أيضًا بتدريب Oagbert الصيني للاستخدام. تم تدريب النموذج مسبقًا على مجموعة من البيانات الأولية الصينية البالغة 44 مترًا بما في ذلك العنوان ، الملخص ، المؤلفون ، الانتماءات ، الأماكن ، الكلمات الرئيسية والصناديق . يمتد صندوق الكيان الجديد إلى ما وراء الكيانات المستخدمة في النسخة الإنجليزية. علاوة على ذلك ، يتم تدريب Oagbert الصيني مع Tokenizer الحكيم. هذان الاختلافان الرئيسيان بين الإنجليزيين أواجبرت وأوجبرت الصيني.
يمكن العثور على أمثلة على استخدام Oagbert الصيني الأصلي والجملة-OAGBERT في أمثلة/OAGBERT/OAGBERT_METAINFO_ZH.PY وأمثلة/OAGBERT/OAGBERT_METAINFO_ZH_SIM.PY. على غرار الجملة الإنجليزية-Oagbert ، يتم ضبط الجملة الصينية-Oagbert على مهام عدم الغموض في الاسم لحساب تشابه تضمين الورق. يظهر الأداء على النحو التالي. نوصي المستخدمين باستخدام هذا الإصدار بشكل مباشر إذا لم يكن لدى مهام المصب بيانات كافية للضبط.
| OAGBERT-V2-ZH | OAGBERT-V2-ZH-SIM | |
|---|---|---|
| عنوان | 0.337 | 0.619 |
| العنوان+الملخص | 0.314 | 0.682 |
إذا وجدت أنه مفيد ، فيرجى الاستشهاد بنا في عملك:
@article{xiao2021oag,
title={OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Model},
author={Liu, Xiao and Yin, Da and Zhang, Xingjian and Su, Kai and Wu, Kan and Yang, Hongxia and Tang, Jie},
journal={arXiv preprint arXiv:2103.02410},
year={2021}
}
@inproceedings{zhang2019oag,
title={OAG: Toward Linking Large-scale Heterogeneous Entity Graphs.},
author={Zhang, Fanjin and Liu, Xiao and Tang, Jie and Dong, Yuxiao and Yao, Peiran and Zhang, Jie and Gu, Xiaotao and Wang, Yan and Shao, Bin and Li, Rui and Wang, Kuansan},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19)},
year={2019}
}
@article{chen2020conna,
title={CONNA: Addressing Name Disambiguation on The Fly},
author={Chen, Bo and Zhang, Jing and Tang, Jie and Cai, Lingfan and Wang, Zhaoyu and Zhao, Shu and Chen, Hong and Li, Cuiping},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2020},
publisher={IEEE}
}


