OAG BERT
1.0.0

Biblioteca | Papel | Folga
Lançamos duas versões do pacote OAG-Bert no COGDL (devido à expiração do download anterior de disco em nuvem Tsinghua, agora faça o download dos modelos manualmente do ModelCope). Oag-Bert é um modelo de linguagem acadêmica com entidade heterogênea que não apenas entende textos acadêmicos, mas também o conhecimento heterogêneo da entidade em OAG. Participe do nosso Slack ou Google Group para obter comentários e solicitações! Nosso artigo está aqui.
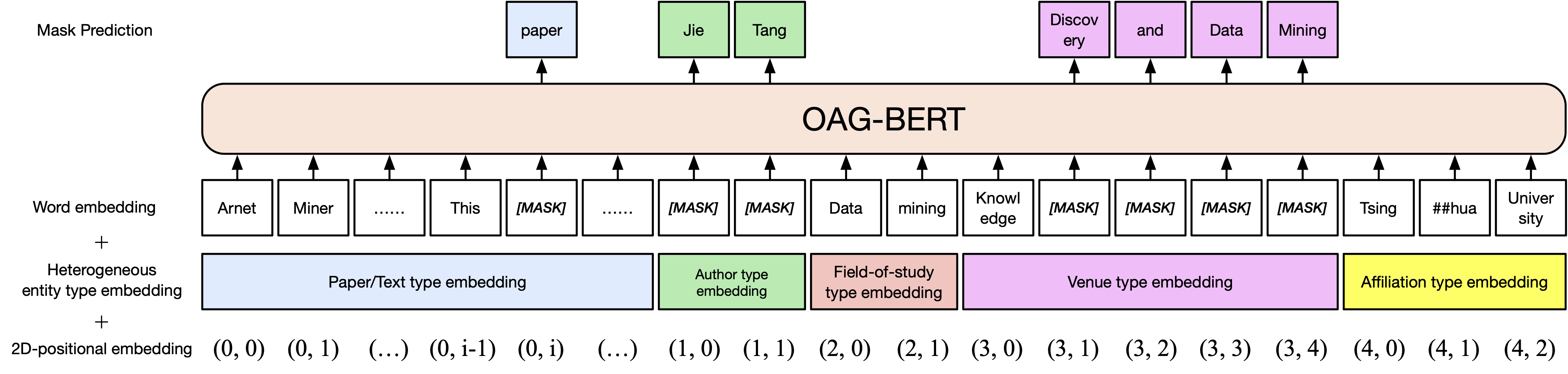
Uma versão básica Oag-Bert. Semelhante ao Scibert, pré-trepamos o modelo Bert no corpus de texto acadêmico em gráfico acadêmico aberto, incluindo títulos de papel, resumos e corpos.
O uso de Oag-Bert é o mesmo de Scibert ou Bert comum. Por exemplo, você pode usar o seguinte código para codificar duas sequências de texto e recuperar suas saídas
from cogdl . oag import oagbert
tokenizer , bert_model = oagbert ()
sequence = [ "CogDL is developed by KEG, Tsinghua." , "OAGBert is developed by KEG, Tsinghua." ]
tokens = tokenizer ( sequence , return_tensors = "pt" , padding = True )
outputs = bert_model ( ** tokens )Uma extensão da baunilha Oag-Bert. Incorporamos informações ricas em entidades em gráficos acadêmicos abertos, como autores e campo de estudo . Assim, você pode codificar vários tipos de entidades em Oag-Bert V2. Por exemplo, para codificar o papel de Bert, você pode usar o seguinte código
from cogdl . oag import oagbert
import torch
tokenizer , model = oagbert ( "oagbert-v2" )
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# build model inputs
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# run forward
sequence_output , pooled_output = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
) Você também pode usar algumas funções integradas para usar diretamente o OAG-Bert V2, como o uso decode_beamsearch para gerar entidades com base no contexto existente. Por exemplo, para gerar conceitos com 2 tokens para o papel Bert, execute o seguinte código
model . eval ()
candidates = model . decode_beamsearch (
title = title ,
abstract = abstract ,
venue = venue ,
authors = authors ,
affiliations = affiliations ,
decode_span_type = 'FOS' ,
decode_span_length = 2 ,
beam_width = 8 ,
force_forward = False
)OAG-Bert supera outros modelos de idiomas acadêmicos em uma ampla gama de tarefas conscientes da entidade, enquanto mantém seu desempenho nas tarefas comuns de PNL.
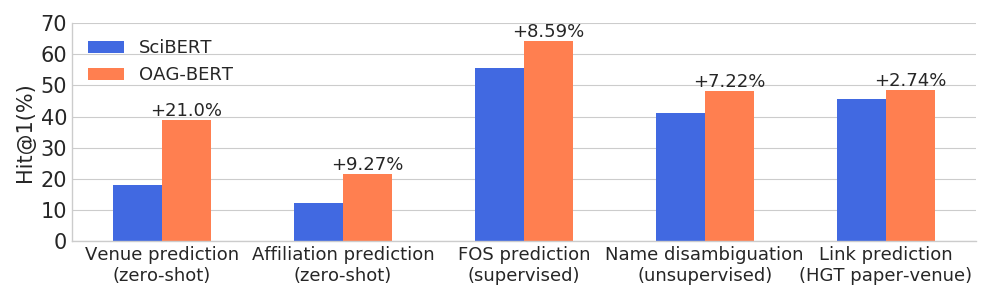
Também lançamos outra versão V2 para usuários.
Uma é uma versão baseada em geração que pode ser usada para gerar textos com base em outras informações. Por exemplo, use o código a seguir para gerar automaticamente títulos em papel com resumos.
from cogdl . oag import oagbert
tokenizer , model = oagbert ( 'oagbert-v2-lm' )
model . eval ()
for seq , prob in model . generate_title ( abstract = "To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations for NSFC (National Nature Science Foundation of China) and paper tagging in the AMiner system. It is also available to the public through the CogDL package." ):
print ( 'Title: %s' % seq )
print ( 'Perplexity: %.4f' % prob )
# One of our generations: "pre-training oag-bert: an academic language model for enriching academic texts with domain knowledge"Além disso, ajustamos o OAG-Bert para calcular a similaridade do papel com base nas tarefas de desambiguação de nomes, que são nomeadas como sentença-oagbert após a frase-balert. Os códigos a seguir demonstram um exemplo de uso da sentença-Oagbert para calcular a similaridade do papel.
import os
from cogdl . oag import oagbert
import torch
import torch . nn . functional as F
import numpy as np
# load time
tokenizer , model = oagbert ( "oagbert-v2-sim" )
model . eval ()
# Paper 1
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# encode first paper
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
_ , paper_embed_1 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Positive Paper 2
title = 'Attention Is All You Need'
abstract = 'We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely...'
authors = [ 'Ashish Vaswani' , 'Noam Shazeer' , 'Niki Parmar' , 'Jakob Uszkoreit' ]
venue = 'neural information processing systems'
affiliations = [ 'Google' ]
concepts = [ 'machine translation' , 'computation and language' , 'language model' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode second paper
_ , paper_embed_2 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Negative Paper 3
title = "Traceability and international comparison of ultraviolet irradiance"
abstract = "NIM took part in the CIPM Key Comparison of ″Spectral Irradiance 250 to 2500 nm″. In UV and NIR wavelength, the international comparison results showed that the consistency between Chinese value and the international reference one"
authors = [ 'Jing Yu' , 'Bo Huang' , 'Jia-Lin Yu' , 'Yan-Dong Lin' , 'Cai-Hong Dai' ]
veune = 'Jiliang Xuebao/Acta Metrologica Sinica'
affiliations = [ 'Department of Electronic Engineering' ]
concept = [ 'Optical Division' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode thrid paper
_ , paper_embed_3 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# calulate text similarity
# normalize
paper_embed_1 = F . normalize ( paper_embed_1 , p = 2 , dim = 1 )
paper_embed_2 = F . normalize ( paper_embed_2 , p = 2 , dim = 1 )
paper_embed_3 = F . normalize ( paper_embed_3 , p = 2 , dim = 1 )
# cosine sim.
sim12 = torch . mm ( paper_embed_1 , paper_embed_2 . transpose ( 0 , 1 ))
sim13 = torch . mm ( paper_embed_1 , paper_embed_3 . transpose ( 0 , 1 ))
print ( sim12 , sim13 )Esse ajuste fino foi realizado nas tarefas de desambiguação de nome. Os artigos escritos pelos mesmos autores são tratados como pares positivos e os restos como pares negativos. Amostramos pares positivos de 0,4m e pares negativos de 1,6M e usamos o aprendizado construtivo para ajustar o OAG-Bert (versão 2). Para instâncias de 50%, usamos apenas o título em papel enquanto os outros 50% usam todas as informações heterogêneas. Avaliamos o desempenho usando a classificação recíproca média, onde valores mais altos indicam melhores resultados. O desempenho nos conjuntos de testes é mostrado como abaixo.
| Oagbert-V2 | Oagbert-V2-sim | |
|---|---|---|
| Título | 0,349 | 0,725 |
| Título+Resumo+Autor+Aff+Local | 0,355 | 0,789 |
Para mais detalhes, consulte Exemplos/oagbert_metainfo.py em Cogdl.
Também treinamos o Oagbert chinês para uso. O modelo foi pré-treinado em um corpus, incluindo 44 milhões de metadados em papel chinês, incluindo título, abstrato, autores, afiliações, locais, palavras-chave e fundos . O novo fundo de entidade é estendido além das entidades usadas na versão em inglês. Além disso, o Oagbert chinês é treinado com o tokenizador da peça de sentença. Essas são as duas principais diferenças entre o Oagbert inglês e o chinês Oagbert.
Os exemplos de uso do Oagbert chinês original e da frase-oagbert podem ser encontrados em exemplos/oagbert/oagbert_metainfo_zh.py e exemplos/oagbert/oagbert_metainfo_zh_sim.py. Da mesma forma que a sentença inglesa-Oagbert, a frase chinesa-Oagbert é ajustada nas tarefas de desambiguação de nome para calcular o papel incorporando a similaridade. O desempenho é mostrado como abaixo. Recomendamos que os usuários usem diretamente esta versão se as tarefas a jusante não tiverem dados suficientes para ajuste fino.
| Oagbert-V2-Zh | Oagbert-V2-Zh-sim | |
|---|---|---|
| Título | 0,337 | 0,619 |
| Título+Resumo | 0,314 | 0,682 |
Se você achar útil, cite -nos em seu trabalho:
@article{xiao2021oag,
title={OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Model},
author={Liu, Xiao and Yin, Da and Zhang, Xingjian and Su, Kai and Wu, Kan and Yang, Hongxia and Tang, Jie},
journal={arXiv preprint arXiv:2103.02410},
year={2021}
}
@inproceedings{zhang2019oag,
title={OAG: Toward Linking Large-scale Heterogeneous Entity Graphs.},
author={Zhang, Fanjin and Liu, Xiao and Tang, Jie and Dong, Yuxiao and Yao, Peiran and Zhang, Jie and Gu, Xiaotao and Wang, Yan and Shao, Bin and Li, Rui and Wang, Kuansan},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19)},
year={2019}
}
@article{chen2020conna,
title={CONNA: Addressing Name Disambiguation on The Fly},
author={Chen, Bo and Zhang, Jing and Tang, Jie and Cai, Lingfan and Wang, Zhaoyu and Zhao, Shu and Chen, Hong and Li, Cuiping},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2020},
publisher={IEEE}
}


