OAG BERT
1.0.0

Perpustakaan | Kertas | Kendur
Kami merilis dua versi OAG-BERT dalam paket COGDL (karena kedaluwarsa pengunduhan Disk Cloud Tsinghua sebelumnya, silakan unduh model secara manual dari Modelscope). OAG-BERT adalah model bahasa akademik yang heterogen yang heterogen yang tidak hanya memahami teks-teks akademik tetapi juga pengetahuan entitas yang heterogen dalam OAG. Bergabunglah dengan Slack atau Google Group kami untuk setiap komentar dan permintaan! Makalah kami ada di sini.
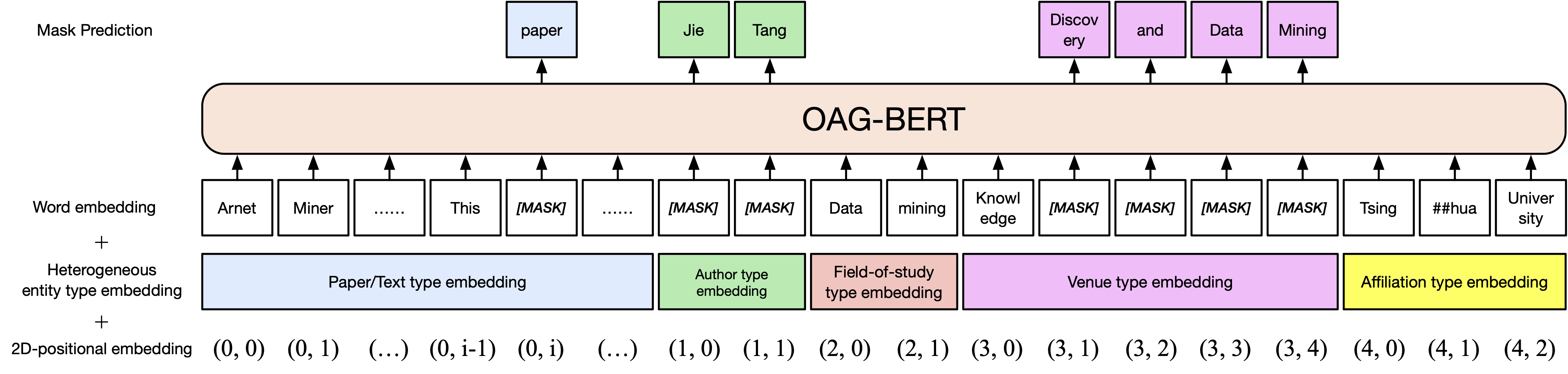
Versi dasar oag-eri. Mirip dengan scibert, kami melakukan pra-melatih model BerT pada corpus teks akademik dalam grafik akademik terbuka, termasuk judul kertas, abstrak dan badan.
Penggunaan OAG-Bert sama dengan Scibert atau Bert biasa. Misalnya, Anda dapat menggunakan kode berikut untuk menyandikan dua urutan teks dan mengambil outputnya
from cogdl . oag import oagbert
tokenizer , bert_model = oagbert ()
sequence = [ "CogDL is developed by KEG, Tsinghua." , "OAGBert is developed by KEG, Tsinghua." ]
tokens = tokenizer ( sequence , return_tensors = "pt" , padding = True )
outputs = bert_model ( ** tokens )Perpanjangan ke vanilla oag-eri. Kami memasukkan informasi entitas yang kaya dalam grafik akademik terbuka seperti penulis dan bidang studi . Dengan demikian, Anda dapat menyandikan berbagai jenis entitas di OAG-BERT V2. Misalnya, untuk menyandikan kertas Bert, Anda dapat menggunakan kode berikut
from cogdl . oag import oagbert
import torch
tokenizer , model = oagbert ( "oagbert-v2" )
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# build model inputs
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# run forward
sequence_output , pooled_output = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
) Anda juga dapat menggunakan beberapa fungsi terintegrasi untuk menggunakan OAG-BERT V2 secara langsung, seperti menggunakan decode_beamsearch untuk menghasilkan entitas berdasarkan konteks yang ada. Misalnya, untuk menghasilkan konsep dengan 2 token untuk kertas Bert, jalankan kode berikut
model . eval ()
candidates = model . decode_beamsearch (
title = title ,
abstract = abstract ,
venue = venue ,
authors = authors ,
affiliations = affiliations ,
decode_span_type = 'FOS' ,
decode_span_length = 2 ,
beam_width = 8 ,
force_forward = False
)OAG-BERT melampaui model bahasa akademik lainnya pada berbagai tugas sadar entitas sambil mempertahankan kinerjanya pada tugas NLP biasa.
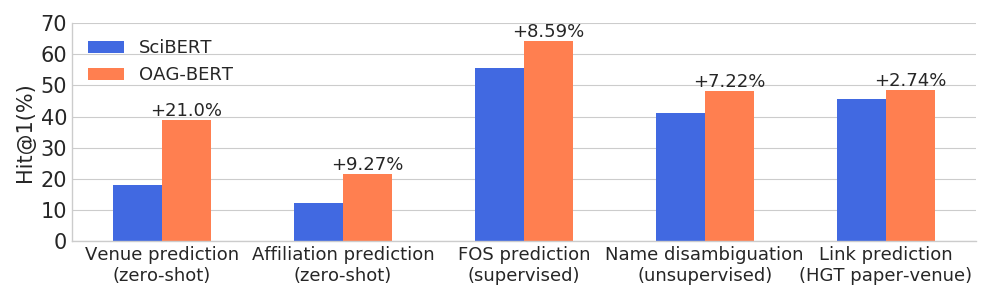
Kami juga merilis dua versi V2 lainnya untuk pengguna.
Salah satunya adalah versi berbasis generasi yang dapat digunakan untuk menghasilkan teks berdasarkan informasi lainnya. Misalnya, gunakan kode berikut untuk secara otomatis menghasilkan judul kertas dengan abstrak.
from cogdl . oag import oagbert
tokenizer , model = oagbert ( 'oagbert-v2-lm' )
model . eval ()
for seq , prob in model . generate_title ( abstract = "To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations for NSFC (National Nature Science Foundation of China) and paper tagging in the AMiner system. It is also available to the public through the CogDL package." ):
print ( 'Title: %s' % seq )
print ( 'Perplexity: %.4f' % prob )
# One of our generations: "pre-training oag-bert: an academic language model for enriching academic texts with domain knowledge"Selain itu, kami menyempurnakan OAG-BTT untuk menghitung kesamaan kertas berdasarkan nama tugas disambiguasi, yang dinamai sebagai kalimat-Oagbert mengikuti kalimat-Bert. Kode-kode berikut menunjukkan contoh menggunakan kalimat-Oagbert untuk menghitung kesamaan kertas.
import os
from cogdl . oag import oagbert
import torch
import torch . nn . functional as F
import numpy as np
# load time
tokenizer , model = oagbert ( "oagbert-v2-sim" )
model . eval ()
# Paper 1
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# encode first paper
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
_ , paper_embed_1 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Positive Paper 2
title = 'Attention Is All You Need'
abstract = 'We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely...'
authors = [ 'Ashish Vaswani' , 'Noam Shazeer' , 'Niki Parmar' , 'Jakob Uszkoreit' ]
venue = 'neural information processing systems'
affiliations = [ 'Google' ]
concepts = [ 'machine translation' , 'computation and language' , 'language model' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode second paper
_ , paper_embed_2 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Negative Paper 3
title = "Traceability and international comparison of ultraviolet irradiance"
abstract = "NIM took part in the CIPM Key Comparison of ″Spectral Irradiance 250 to 2500 nm″. In UV and NIR wavelength, the international comparison results showed that the consistency between Chinese value and the international reference one"
authors = [ 'Jing Yu' , 'Bo Huang' , 'Jia-Lin Yu' , 'Yan-Dong Lin' , 'Cai-Hong Dai' ]
veune = 'Jiliang Xuebao/Acta Metrologica Sinica'
affiliations = [ 'Department of Electronic Engineering' ]
concept = [ 'Optical Division' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode thrid paper
_ , paper_embed_3 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# calulate text similarity
# normalize
paper_embed_1 = F . normalize ( paper_embed_1 , p = 2 , dim = 1 )
paper_embed_2 = F . normalize ( paper_embed_2 , p = 2 , dim = 1 )
paper_embed_3 = F . normalize ( paper_embed_3 , p = 2 , dim = 1 )
# cosine sim.
sim12 = torch . mm ( paper_embed_1 , paper_embed_2 . transpose ( 0 , 1 ))
sim13 = torch . mm ( paper_embed_1 , paper_embed_3 . transpose ( 0 , 1 ))
print ( sim12 , sim13 )Penyesuaian ini dilakukan pada whoiswhe name Disambiguation Tasks. Makalah yang ditulis oleh penulis yang sama diperlakukan sebagai pasangan positif dan sisanya sebagai pasangan negatif. Kami mencicipi 0,4m pasangan positif dan 1,6m pasangan negatif dan menggunakan pembelajaran konstruktif untuk menyempurnakan OAG-Bert (versi 2). Untuk 50% instance kami hanya menggunakan judul kertas sementara 50% lainnya menggunakan semua informasi heterogen. Kami mengevaluasi kinerja menggunakan peringkat timbal balik rata -rata di mana nilai yang lebih tinggi menunjukkan hasil yang lebih baik. Kinerja pada set tes ditampilkan seperti di bawah ini.
| oagbert-v2 | Oagbert-V2-SIM | |
|---|---|---|
| Judul | 0.349 | 0.725 |
| Judul+Abstrak+Penulis+Aff+Tempat | 0.355 | 0.789 |
Untuk detail lebih lanjut, lihat contoh/oagbert_metainfo.py di cogdl.
Kami juga melatih Oagbert Cina untuk digunakan. Model ini dilatih sebelumnya pada corpus termasuk metadata kertas Cina 44m termasuk judul, abstrak, penulis, afiliasi, tempat, kata kunci dan dana . Dana entitas baru diperpanjang melampaui entitas yang digunakan dalam versi bahasa Inggris. Selain itu, Oagbert Cina dilatih dengan Tokenizer kalimat. Ini adalah dua perbedaan utama antara oagbert Inggris dan oagbert Cina.
Contoh menggunakan oagbert Cina asli dan kalimat-oagbert dapat ditemukan dalam contoh/oagbert/oagbert_metainfo_zh.py dan contoh/oagbert/oagbert_metainfo_zh_sim.py. Demikian pula dengan kalimat Inggris-Oagbert, kalimat Cina-Oagbert disesuaikan dengan nama tugas disambiguasi untuk menghitung kesamaan yang menanamkan kertas. Kinerja ditampilkan seperti di bawah ini. Kami menyarankan pengguna untuk secara langsung menggunakan versi ini jika tugas hilir tidak memiliki cukup data untuk fine-tuning.
| oagbert-v2-zh | oagbert-v2-zh-sim | |
|---|---|---|
| Judul | 0.337 | 0.619 |
| Judul+Abstrak | 0.314 | 0.682 |
Jika Anda merasa berguna, silakan mengutip kami dalam pekerjaan Anda:
@article{xiao2021oag,
title={OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Model},
author={Liu, Xiao and Yin, Da and Zhang, Xingjian and Su, Kai and Wu, Kan and Yang, Hongxia and Tang, Jie},
journal={arXiv preprint arXiv:2103.02410},
year={2021}
}
@inproceedings{zhang2019oag,
title={OAG: Toward Linking Large-scale Heterogeneous Entity Graphs.},
author={Zhang, Fanjin and Liu, Xiao and Tang, Jie and Dong, Yuxiao and Yao, Peiran and Zhang, Jie and Gu, Xiaotao and Wang, Yan and Shao, Bin and Li, Rui and Wang, Kuansan},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19)},
year={2019}
}
@article{chen2020conna,
title={CONNA: Addressing Name Disambiguation on The Fly},
author={Chen, Bo and Zhang, Jing and Tang, Jie and Cai, Lingfan and Wang, Zhaoyu and Zhao, Shu and Chen, Hong and Li, Cuiping},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2020},
publisher={IEEE}
}


