OAG BERT
1.0.0

Bibliothek | Papier | Locker
Wir haben zwei Versionen von Oag-Bert im COGDL-Paket veröffentlicht (aufgrund des Ablaufs des vorherigen Herunterladens des Tsinghua-Cloud-Festplattens laden Sie nun Modelle manuell von ModelsCope herunter). Oag-Bert ist ein heterogenes, von der Entität ausgestattete akademische Sprachmodell, das nicht nur akademische Texte, sondern auch heterogenes Unternehmen Wissen in OAG versteht. Treten Sie unserer Slack- oder Google -Gruppe für Kommentare und Anfragen bei! Unser Papier ist hier.
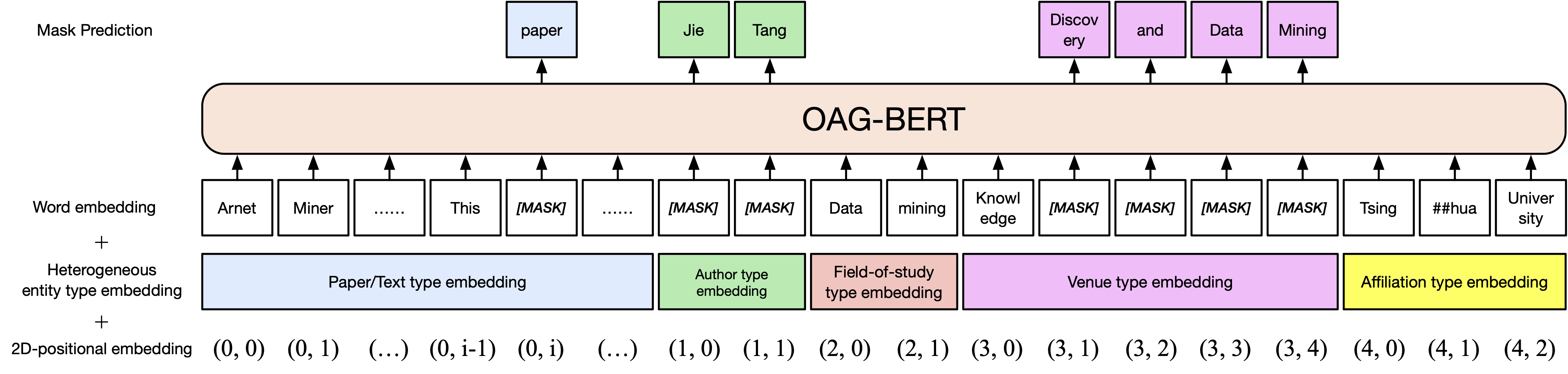
Eine grundlegende Version Oag-Bert. Ähnlich wie bei Scibert verarbeiten wir das Bert-Modell zum akademischen Textkorpus in offenen akademischen Graphen, einschließlich Papiertiteln, Abstracts und Körper.
Die Verwendung von Oag-Bert ist das gleiche von normalem Scibert oder Bert. Beispielsweise können Sie den folgenden Code verwenden, um zwei Textsequenzen zu codieren und deren Ausgänge abzurufen
from cogdl . oag import oagbert
tokenizer , bert_model = oagbert ()
sequence = [ "CogDL is developed by KEG, Tsinghua." , "OAGBert is developed by KEG, Tsinghua." ]
tokens = tokenizer ( sequence , return_tensors = "pt" , padding = True )
outputs = bert_model ( ** tokens )Eine Erweiterung des Vanille Oag-Bert. Wir umfassen Informationen über viele Unternehmen in offene akademische Graphen wie Autoren und Studienfeld . Somit können Sie verschiedene Art von Entitäten in Oag-Bert V2 codieren. Um das Papier von Bert zu codieren, können Sie den folgenden Code verwenden
from cogdl . oag import oagbert
import torch
tokenizer , model = oagbert ( "oagbert-v2" )
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# build model inputs
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# run forward
sequence_output , pooled_output = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
) Sie können auch einige integrierte Funktionen verwenden, um Oag-Bert V2 direkt zu verwenden, z decode_beamsearch Um beispielsweise Konzepte mit 2 Token für das Bert -Papier zu generieren, führen Sie den folgenden Code aus
model . eval ()
candidates = model . decode_beamsearch (
title = title ,
abstract = abstract ,
venue = venue ,
authors = authors ,
affiliations = affiliations ,
decode_span_type = 'FOS' ,
decode_span_length = 2 ,
beam_width = 8 ,
force_forward = False
)Oag-Bert übertrifft andere akademische Sprachmodelle in einer Vielzahl von entitätsbewussten Aufgaben und behält seine Leistung bei gewöhnlichen NLP-Aufgaben bei.
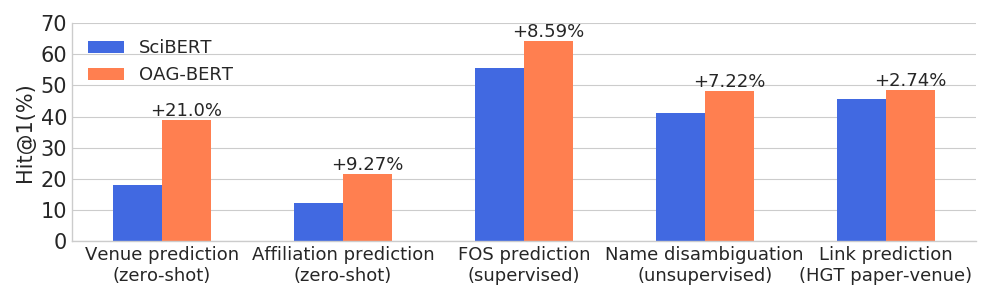
Wir veröffentlichen auch zwei weitere V2 -Versionen für Benutzer.
Eine ist eine generationsbasierte Version, die zum Generieren von Texten auf der Grundlage anderer Informationen verwendet werden kann. Verwenden Sie beispielsweise den folgenden Code, um automatisch Papiertitel mit Abstracts zu generieren.
from cogdl . oag import oagbert
tokenizer , model = oagbert ( 'oagbert-v2-lm' )
model . eval ()
for seq , prob in model . generate_title ( abstract = "To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations for NSFC (National Nature Science Foundation of China) and paper tagging in the AMiner system. It is also available to the public through the CogDL package." ):
print ( 'Title: %s' % seq )
print ( 'Perplexity: %.4f' % prob )
# One of our generations: "pre-training oag-bert: an academic language model for enriching academic texts with domain knowledge"Darüber hinaus stimmen wir den Oag-Bert für die Berechnung der Ähnlichkeit von Papier, basierend auf Namensambigierungsaufgaben, die als Satz-Oagbert nach dem Satzbericht bezeichnet werden. Die folgenden Codes zeigen ein Beispiel für die Verwendung von Satz-Oagbert zur Berechnung der Papierähnlichkeit.
import os
from cogdl . oag import oagbert
import torch
import torch . nn . functional as F
import numpy as np
# load time
tokenizer , model = oagbert ( "oagbert-v2-sim" )
model . eval ()
# Paper 1
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = [ 'Jacob Devlin' , 'Ming-Wei Chang' , 'Kenton Lee' , 'Kristina Toutanova' ]
venue = 'north american chapter of the association for computational linguistics'
affiliations = [ 'Google' ]
concepts = [ 'language model' , 'natural language inference' , 'question answering' ]
# encode first paper
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
_ , paper_embed_1 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Positive Paper 2
title = 'Attention Is All You Need'
abstract = 'We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely...'
authors = [ 'Ashish Vaswani' , 'Noam Shazeer' , 'Niki Parmar' , 'Jakob Uszkoreit' ]
venue = 'neural information processing systems'
affiliations = [ 'Google' ]
concepts = [ 'machine translation' , 'computation and language' , 'language model' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode second paper
_ , paper_embed_2 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# Negative Paper 3
title = "Traceability and international comparison of ultraviolet irradiance"
abstract = "NIM took part in the CIPM Key Comparison of ″Spectral Irradiance 250 to 2500 nm″. In UV and NIR wavelength, the international comparison results showed that the consistency between Chinese value and the international reference one"
authors = [ 'Jing Yu' , 'Bo Huang' , 'Jia-Lin Yu' , 'Yan-Dong Lin' , 'Cai-Hong Dai' ]
veune = 'Jiliang Xuebao/Acta Metrologica Sinica'
affiliations = [ 'Department of Electronic Engineering' ]
concept = [ 'Optical Division' ]
input_ids , input_masks , token_type_ids , masked_lm_labels , position_ids , position_ids_second , masked_positions , num_spans = model . build_inputs (
title = title , abstract = abstract , venue = venue , authors = authors , concepts = concepts , affiliations = affiliations
)
# encode thrid paper
_ , paper_embed_3 = model . bert . forward (
input_ids = torch . LongTensor ( input_ids ). unsqueeze ( 0 ),
token_type_ids = torch . LongTensor ( token_type_ids ). unsqueeze ( 0 ),
attention_mask = torch . LongTensor ( input_masks ). unsqueeze ( 0 ),
output_all_encoded_layers = False ,
checkpoint_activations = False ,
position_ids = torch . LongTensor ( position_ids ). unsqueeze ( 0 ),
position_ids_second = torch . LongTensor ( position_ids_second ). unsqueeze ( 0 )
)
# calulate text similarity
# normalize
paper_embed_1 = F . normalize ( paper_embed_1 , p = 2 , dim = 1 )
paper_embed_2 = F . normalize ( paper_embed_2 , p = 2 , dim = 1 )
paper_embed_3 = F . normalize ( paper_embed_3 , p = 2 , dim = 1 )
# cosine sim.
sim12 = torch . mm ( paper_embed_1 , paper_embed_2 . transpose ( 0 , 1 ))
sim13 = torch . mm ( paper_embed_1 , paper_embed_3 . transpose ( 0 , 1 ))
print ( sim12 , sim13 )Diese Feinabstimmung wurde bei WhoisWho-Namensambigierungsaufgaben durchgeführt. Die von denselben Autoren geschriebenen Papiere werden als positive Paare und die Ruhe als negative Paare behandelt. Wir probieren 0,4 m positive Paare und 1,6 m negative Paare aus und verwenden das konstative Lernen, um den Oag-Bert (Version 2) zu optimieren. Für 50% Fälle verwenden wir nur Papiertitel, während die anderen 50% alle heterogenen Informationen verwenden. Wir bewerten die Leistung anhand des mittleren wechselseitigen Ranges, bei dem höhere Werte bessere Ergebnisse anzeigen. Die Leistung in den Testsätzen wird unten angezeigt.
| Oagbert-V2 | Oagbert-V2-Sim | |
|---|---|---|
| Titel | 0,349 | 0,725 |
| Titel+Zusammenfassung+Autor+AFF+Veranstaltungsort | 0,355 | 0,789 |
Weitere Informationen finden Sie unter Beispiele/Oagbert_Metainfo.py in Cogdl.
Wir haben auch den chinesischen Oagbert für den Gebrauch ausgebildet. Das Modell wurde auf einem Korpus vorgebracht, darunter 44 m chinesische Papiermetadaten, einschließlich Titel, Zusammenfassung, Autoren, Zugehörigkeiten, Veranstaltungsorte, Schlüsselwörter und Fonds . Der neue Entitätsfonds wird über die in der englischen Version verwendeten Unternehmen hinaus erweitert. Außerdem wird der chinesische Oagbert mit dem Satzstück ausgebildet. Dies sind die beiden Hauptunterschiede zwischen dem englischen Oagbert und dem chinesischen Oagbert.
Die Beispiele für die Verwendung des ursprünglichen chinesischen Oagbert und des Satzes-Oagbert finden Sie in Beispielen/Oagbert/Oagbert_metainfo_zh.py und Beispiele/Oagbert/Oagbert_Metainfo_Zh_Sim.py. Ähnlich wie mit dem englischen Satz-Oagbert ist der chinesische Satz-Oagbert mit den Namensambigierungsaufgaben für die Berechnung von Papier-Einbetten der Ähnlichkeit fein abgestimmt. Die Leistung wird wie unten angezeigt. Wir empfehlen den Benutzern, diese Version direkt zu verwenden, wenn nachgeschaltete Aufgaben nicht genügend Daten zur Feinabstimmung haben.
| Oagbert-V2-Zh | Oagbert-V2-Zh-Sim | |
|---|---|---|
| Titel | 0,337 | 0,619 |
| Titel+Zusammenfassung | 0,314 | 0,682 |
Wenn Sie es nützlich finden, zitieren Sie uns bitte in Ihrer Arbeit:
@article{xiao2021oag,
title={OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Model},
author={Liu, Xiao and Yin, Da and Zhang, Xingjian and Su, Kai and Wu, Kan and Yang, Hongxia and Tang, Jie},
journal={arXiv preprint arXiv:2103.02410},
year={2021}
}
@inproceedings{zhang2019oag,
title={OAG: Toward Linking Large-scale Heterogeneous Entity Graphs.},
author={Zhang, Fanjin and Liu, Xiao and Tang, Jie and Dong, Yuxiao and Yao, Peiran and Zhang, Jie and Gu, Xiaotao and Wang, Yan and Shao, Bin and Li, Rui and Wang, Kuansan},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19)},
year={2019}
}
@article{chen2020conna,
title={CONNA: Addressing Name Disambiguation on The Fly},
author={Chen, Bo and Zhang, Jing and Tang, Jie and Cai, Lingfan and Wang, Zhaoyu and Zhao, Shu and Chen, Hong and Li, Cuiping},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2020},
publisher={IEEE}
}


